
Kylin 简介

最后更新时间:2025-01-03 15:02:25
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Kylin 框架介绍
Kylin 能提供低延迟(sub-second latency)的秘诀就是预计算,即针对一个星型拓扑结构的数据立方体,预计算多个维度组合的度量,然后将结果保存在 hbase 中,对外提供 JDBC、ODBC、Rest API 的查询接口,即可实现实时查询。
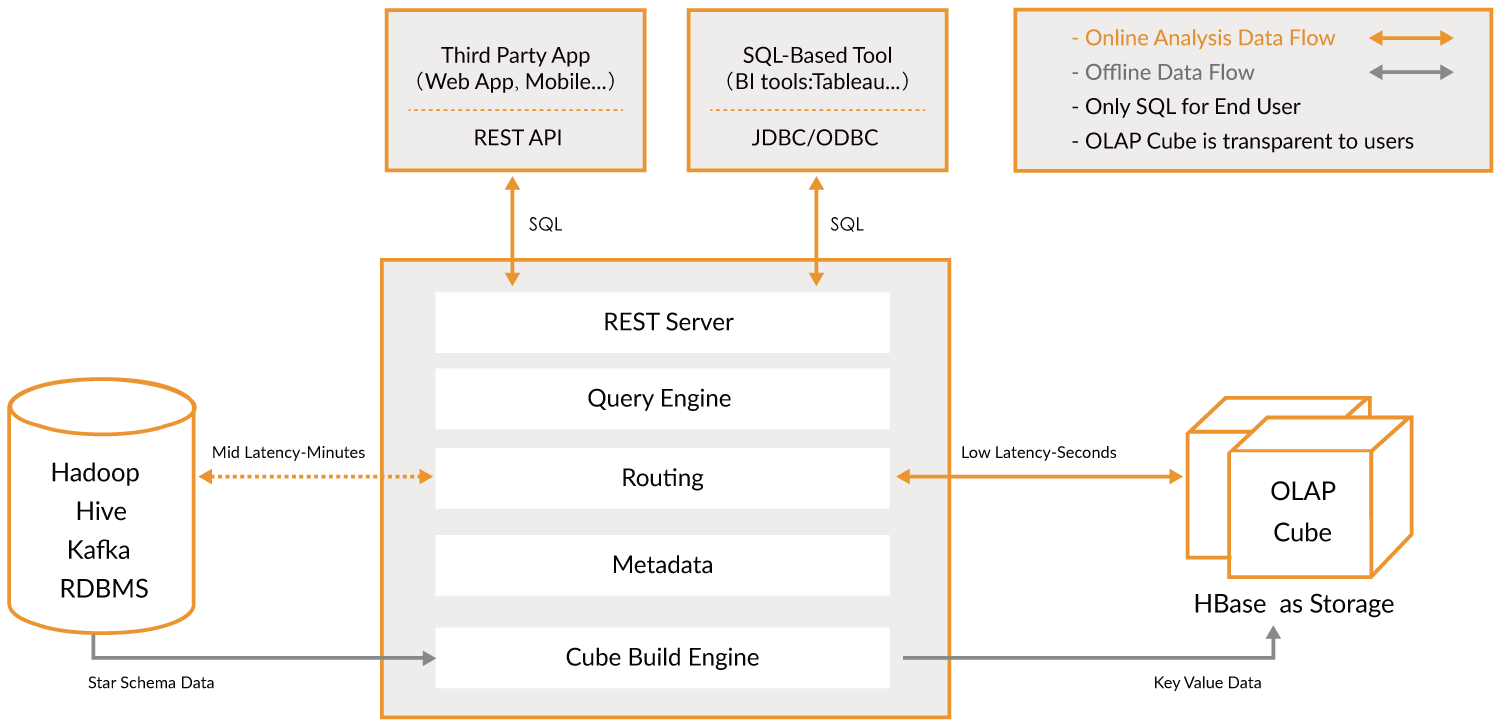
Kylin 核心概念
表(table):表定义在 hive 中,是数据立方体(Data cube)的数据源,在 build cube 之前,必须同步在 kylin 中。
模型(model):模型描述了一个星型模式的数据结构,它定义了一个事实表(Fact Table)和多个查找表(Lookup Table)的连接和过滤关系。
Cube 描述:描述一个 Cube 实例的定义和配置选项,包括使用了哪个数据模型、包含哪些维度和度量、如何将数据进行分区、如何处理自动合并等。
Cube 实例:通过 Cube 描述 Build 得到,包含一个或者多个 Cube Segment。
**分区(Partition)**:用户可以在 Cube 描述中使用一个 DATA/STRING 的列作为分区的列,从而将一个 Cube 按照日期分割成多个 segment。
立方体段(cube segment):它是立方体构建(build)后的数据载体,一个 segment 映射 hbase 中的一张表,立方体实例构建(build)后,会产生一个新的 segment,一旦某个已经构建的立方体的原始数据发生变化,只需刷新(fresh)变化的时间段所关联的 segment 即可。
聚合组:每一个聚合组是一个维度的子集,在内部通过组合构建 cuboid。
作业(job):对立方体实例发出构建(build)请求后,会产生一个作业。该作业记录了立方体实例 build 时的每一步任务信息。作业的状态信息反映构建立方体实例的结果信息。例如,作业执行的状态信息为 RUNNING 时,表明立方体实例正在被构建;作业状态信息为 FINISHED,表明立方体实例构建成功;作业状态信息为 ERROR,表明立方体实例构建失败。
DIMENSION & MEASURE 种类
Mandotary:强制维度,所有 cuboid 必须包含的维度。
Hierarchy:层次关系维度,维度之间具有层次关系性,只需要保留一定层次关系的 cuboid 即可。
Derived:衍生维度,在 lookup 表中,有一些维度可以通过它的主键衍生得到,所以这些维度将不参加 cuboid 的构建。
Count Distinct(HyperLogLog) :直接进行 count distinct 是很难去计算的,一个近似的算法 HyperLogLog 可以保持错误率在一个很低的范围内。
Count Distinct(Precise):将基于 RoaringBitMap 进行计算,目前只支持 int 和 BigInt。
Cube Action 种类
BUILD:给定一个分区列指定的时间间隔,对 Cube 进行 Build,创建一个新的 cube Segment。
REFRESH:这个操作,将在一些分期周期内对 cube Segment 进行重新 build。
MERGE:这个操作将合并多个 cube segments。这个操作可以在构建 cube 时,设置为自动完成。
PURGE:清理一个 Cube 实例下的 segment,但是不会删除 HBase 表中的 Tables。
Job 状态
NEW:表示一个 job 已经被创建。
PENDING:表示一个 job 已经被 job Scheduler 提交,等待执行资源。
RUNNING:表示一个 job 正在运行。
FINISHED:表示一个 job 成功完成。
ERROR:表示一个 job 因为错误退出。
DISCARDED:表示一个 job 被用户取消。
Job 执行
RESUME:这个操作将从失败的 Job 的最后一个成功点继续执行该 Job。
DISCARD:无论工作的状态,用户可以结束它和释放资源。
Cube 快速入门示例
运行脚本,重启 Kylin 服务器刷新缓存。
/usr/local/service/kylin/bin/sample.sh
使用默认用户名和密码 ADMIN/KYLIN 登录 Kylin 网站,在左上角项目下拉框中选择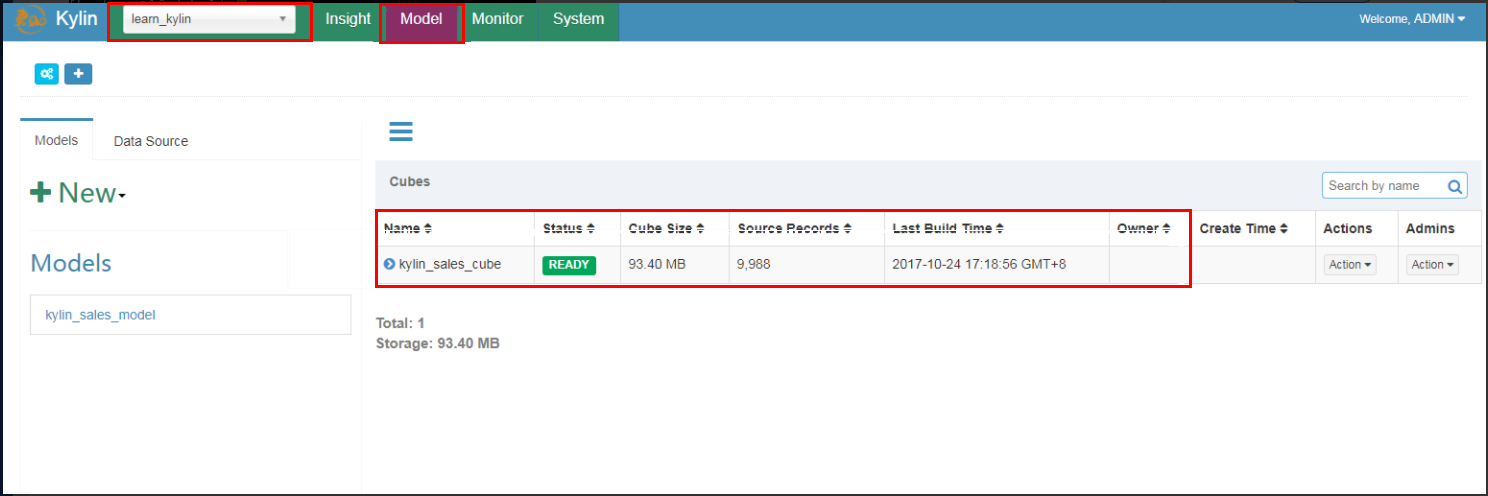
learn_kylin工程,然后选择名为kylin_sales_cube的样例 Cube,选择Actions>Build,选择一个在2014-01-01之后的日期(覆盖所有的10000样例记录)。
select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
用 Spark 构建 Cube
1. 在
kylin.properties中设置kylin.env.hadoop-conf-dir属性。kylin.env.hadoop-conf-dir=/usr/local/service/hadoop/etc/hadoop
2. 检查 Spark 配置
Kylin 在
$KYLIN_HOME/spark中嵌入一个 Spark binary (v2.1.2),所有使用kylin.engine.spark-conf.作为前缀的 Spark 配置属性都能在$KYLIN_HOME/conf/kylin.properties中进行管理。这些属性当运行提交 Spark job 时会被提取并应用。例如,如果您配置kylin.engine.spark-conf.spark.executor.memory=4G,Kylin 将会在执行spark-submit操作时使用–conf spark.executor.memory=4G作为参数。 运行 Spark cubing 前,建议查看一下这些配置并根据您集群的情况进行自定义。下面是建议配置,开启了 Spark 动态资源分配:
kylin.engine.spark-conf.spark.master=yarnkylin.engine.spark-conf.spark.submit.deployMode=clusterkylin.engine.spark-conf.spark.dynamicAllocation.enabled=truekylin.engine.spark-conf.spark.dynamicAllocation.minExecutors=1kylin.engine.spark-conf.spark.dynamicAllocation.maxExecutors=1000kylin.engine.spark-conf.spark.dynamicAllocation.executorIdleTimeout=300kylin.engine.spark-conf.spark.yarn.queue=defaultkylin.engine.spark-conf.spark.driver.memory=2Gkylin.engine.spark-conf.spark.executor.memory=4Gkylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024kylin.engine.spark-conf.spark.executor.cores=1kylin.engine.spark-conf.spark.network.timeout=600kylin.engine.spark-conf.spark.shuffle.service.enabled=true#kylin.engine.spark-conf.spark.executor.instances=1kylin.engine.spark-conf.spark.eventLog.enabled=truekylin.engine.spark-conf.spark.hadoop.dfs.replication=2kylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress=truekylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodeckylin.engine.spark-conf.spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodeckylin.engine.spark-conf.spark.eventLog.dir=hdfs\\:///kylin/spark-historykylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs\\:///kylin/spark-history## uncomment for HDP#kylin.engine.spark-conf.spark.driver.extraJavaOptions=-Dhdp.version=current#kylin.engine.spark-conf.spark.yarn.am.extraJavaOptions=-Dhdp.version=current#kylin.engine.spark-conf.spark.executor.extraJavaOptions=-Dhdp.version=current
为了在 Hortonworks 平台上运行,需要将
hdp.version指定为 Yarn 容器的 Java 选项,因此需取消kylin.properties中最后三行的注释。 除此之外,为了避免重复上传 Spark jar 包到 Yarn,您可以手动上传一次,然后配置 jar 包的 HDFS 路径。HDFS 路径必须是全路径名。
jar cv0f spark-libs.jar -C $KYLIN_HOME/spark/jars/ .hadoop fs -mkdir -p /kylin/spark/hadoop fs -put spark-libs.jar /kylin/spark/
然后,要在
kylin.properties中进行如下配置:kylin.engine.spark-conf.spark.yarn.archive=hdfs://sandbox.hortonworks.com:8020/kylin/spark/spark-libs.jar
所有
kylin.engine.spark-conf.*参数都可以在 Cube 或 Project 级别进行重写,这为用户提供了灵活性。
3. 创建和修改样例 cube
运行sample.sh创建样例 cube,然后启动 Kylin 服务器:/usr/local/service/kylin/bin/sample.sh/usr/local/service/kylin/bin/kylin.sh start
Kylin 启动后,访问 Kylin 网站,在“Advanced Setting”页,编辑名为

kylin_sales的 cube,将Cube Engine由MapReduce修改为Spark(Beta):
kylin.engine.spark.rdd-partition-cut-mb其值为500。
说明
对于没有 COUNT DISTINCT 和 TOPN 的 cube,请保留默认配置。
3. 用 Spark 构建 Cube
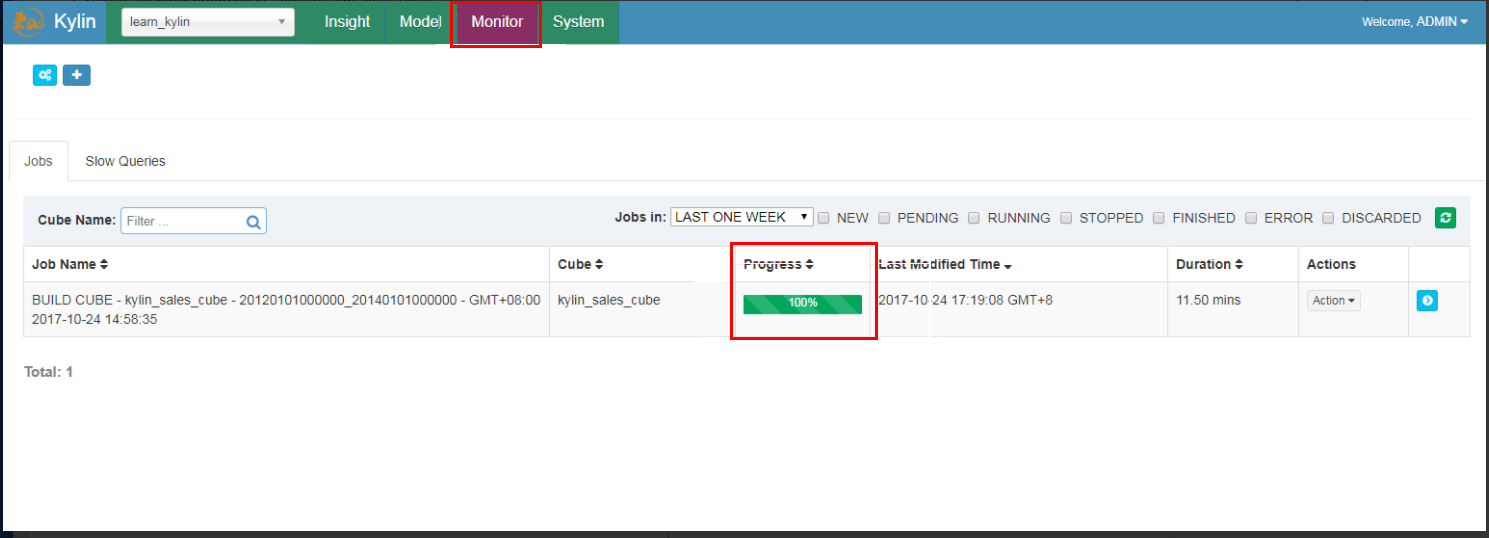
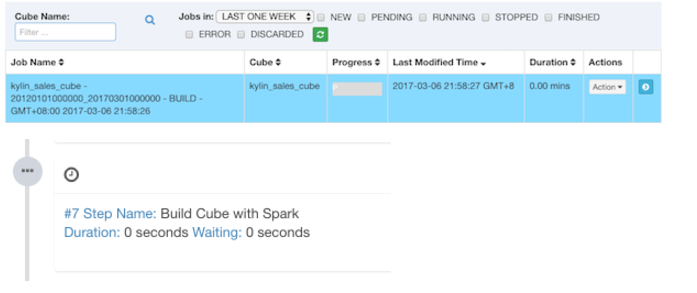
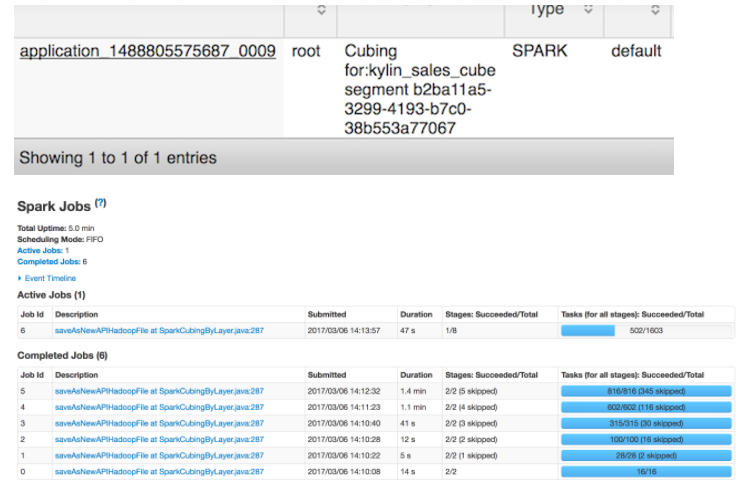
单击Build,选择当前日期为 end date。Kylin 会在“Monitor”页生成一个构建 job,第7步是 Spark cubing。Job engine 开始按照顺序执行每一步。
文档反馈