
Viewing Monitoring Metric

Last updated: 2024-10-18 17:29:39
Overview
TCOP products provide monitoring features to all users by default, with no need for manual activation. The platform starts collecting monitoring data only after the user starts using a specific Tencent Cloud product.
TDMQ for RabbitMQ supports monitoring the resources you create under your account, including clusters, nodes, Vhosts, queues, and exchanges, helping you stay informed about resource status in real-time. You can configure alarm rules for monitoring metrics, and when a metric reaches the specified threshold, TCOP can notify you via email, SMS, WeChat, or phone, enabling you to respond to exceptions promptly.
Configuring Alarm Rules
Creating Alarm Rules
You can configure alarm rules for monitoring metrics, and when a metric reaches the specified threshold, TCOP can notify you via email, SMS, WeChat, or phone, helping you promptly address any abnormal situations.
1. On the monitoring page of the cluster, click the alarm button shown below to jump to the TCOP console to configure alarm policies.

2. On the alarm policy page, select the policy type and the instance for which you want to set alarms, configure the alarm rules, and set the notification template.
Monitoring Type: Select Cloud Product Monitoring.
Policy Type: Select TDMQ / RabbitMQ Exclusive Edition.
Alarm Object: Select the RabbitMQ resource for which you want to configure the alarm policy.
Trigger Condition: Support Select template and Manual configuration. By default, manual configuration is selected. For manual configuration instructions, see the following guidelines. To create a template, see Create trigger condition template.
You can directly use the pre-configured alarm templates for TDMQ for RabbitMQ. Follow these steps:
Step 1: For Policy Type, select TDMQ / RabbitMQ Exclusive Edition / Cloud Data Disks.
Step 2: For Alert Object, select the RabbitMQ resource for which you want to configure the alarm policy.
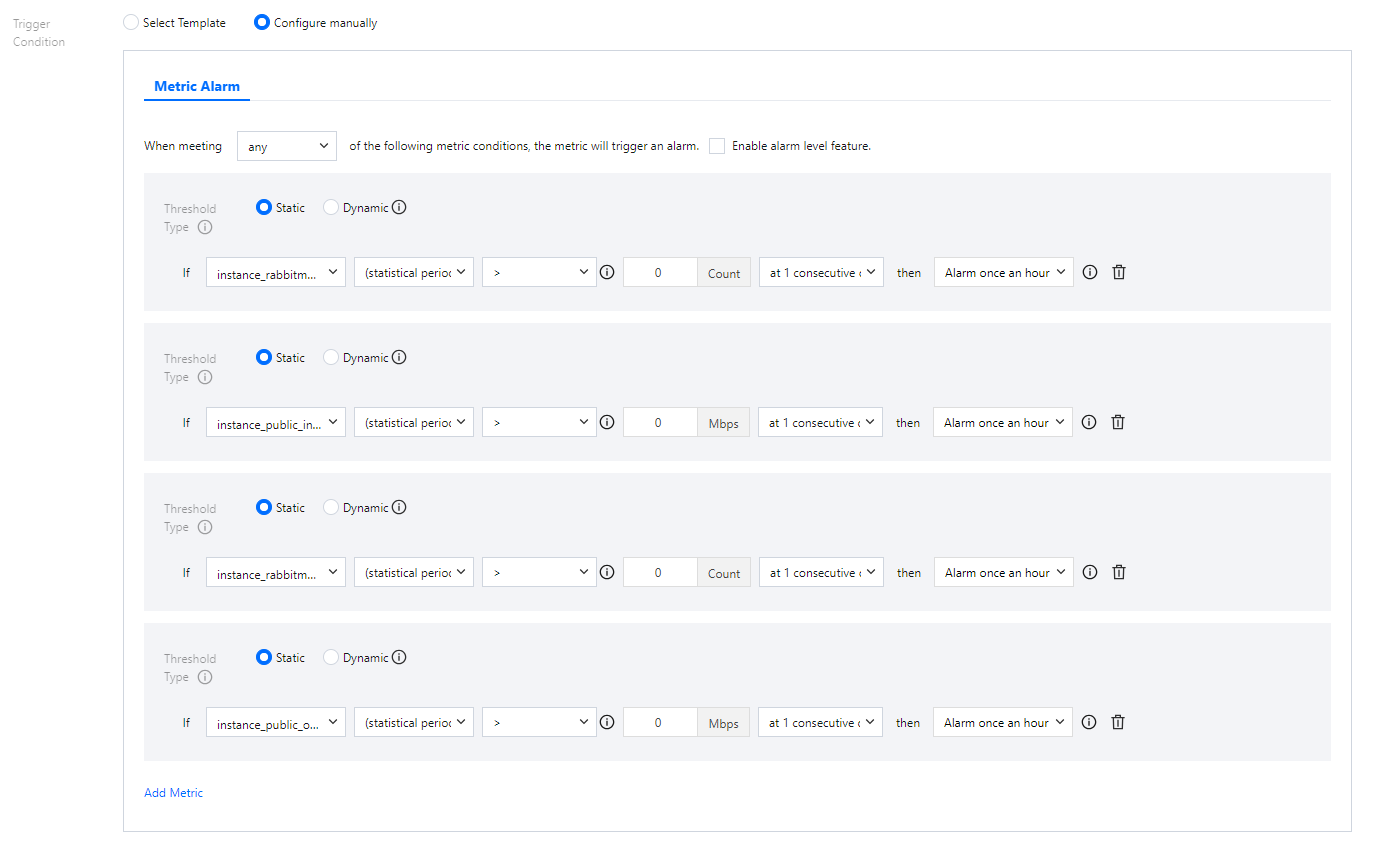
Step 3: For Trigger Conditions, check Use predefined trigger conditions. The predefined alearm trigger conditions will appear as shown below:
Step 4: Adjust the specific trigger conditions according to your business needs.
3. Click Next: Configure alarm notification. In the notification template section, click Select template to choose a template. You can also click Create new template to create a notification template, setting the alarm recipients and notification channels.
Note:
4. Click Complete to finish the configuration.
Creating Trigger Condition Template
1. Log in to the TCOP console.
2. In the left sidebar, click Alarm Configuration to enter the alarm configuration list page , and then click Trigger Condition Template.
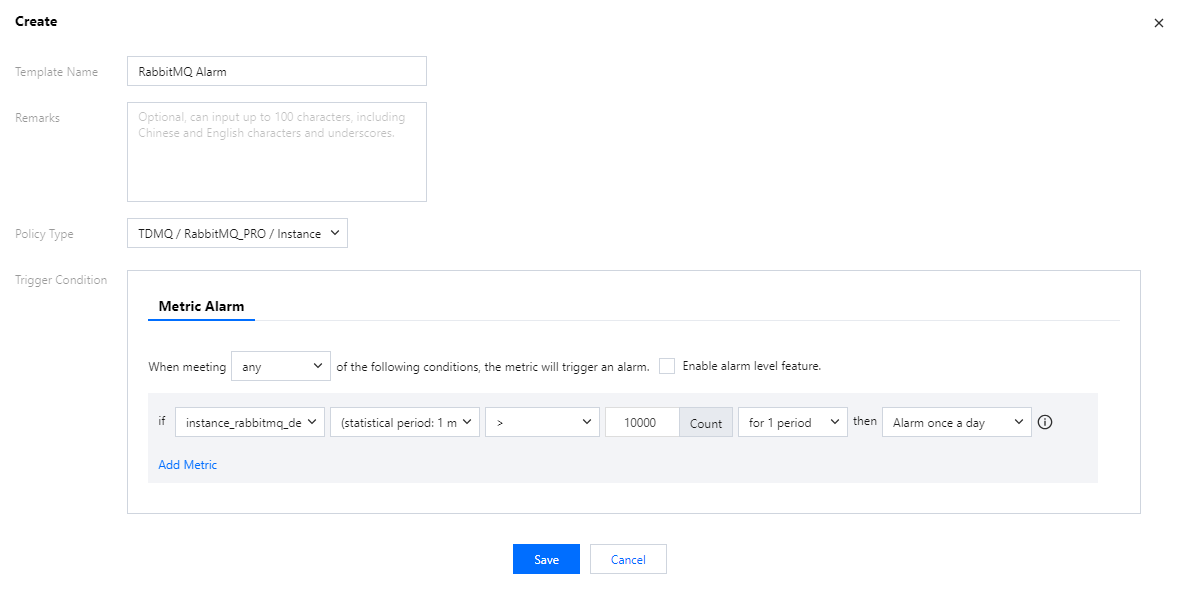
3. In the Trigger Condition Template tab, click Create Trigger Condition Template.
4. On the template creation page, configure the policy type.
Policy Type: Select the policy type under TDMQ / RabbitMQ Exclusive Edition category.
Use Preset Trigger Conditions: Check this option to display the system-recommended alarm policies.
5. After confirmation, click Save.
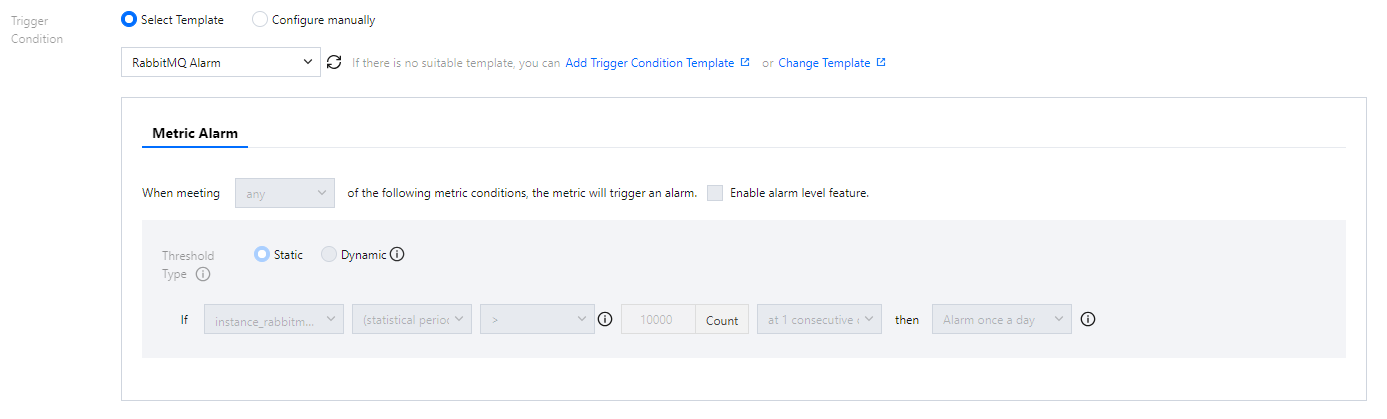
6. Return to the alarm policy creation page, click Refresh, and the newly configured alarm policy template will appear.
Alarm Configuration Recommendations
This section introduces key metrics you should focus on during the use of TDMQ for RabbitMQ and provides recommendations for configuring alarms accordingly:
Metric | Dimension | Recommended Alarm Configuration | Detailed Description |
Disk utilization (%) | Node | Set a calculation granularity of 1 minute, trigger the alarm when the disk utilization exceeds 80% for 5 consecutive data points, and raise the alarm once every 30 minutes. | High disk utilization can result in insufficient disk space on the node to store the messages assigned to it, preventing messages from being written to disk. It is recommended to clear data or scale out the cluster when the average disk utilization exceeds 80%. |
Memory utilization (%) | Node | Set a calculation granularity of 1 minute, trigger the alarm when the memory utilization exceeds 50% for 5 consecutive data points, and raise the alarm once every 30 minutes. | High memory utilization can block message production. It is recommended to speed up consumption, apply flow control to production, or scale out the cluster when memory utilization exceeds 50%. |
CPU utilization (%) | Node | Set a calculation granularity of 1 minute, trigger the alarm when the CPU utilization exceeds 70% for 5 consecutive data points, and raise the alarm once every 30 minutes. | High CPU utilization can affect the message production speed. It is recommended to scale out promptly when CPU utilization exceeds 70%. |
Number of heaped messages | Node | Set a calculation granularity of 5 minutes, trigger the alarm when the number of heaped messages exceeds the expected business threshold for 5 consecutive data points, and raise the alarm once every 30 minutes. | Too many heaped messages will cause the disk usage of the Broker node to rise rapidly, preventing it from receiving more messages. Scale-out is required. |
Node availability (%) | Node | Set a calculation granularity of 1 minute, trigger the alarm when the node availability value equals to 1 for 3 consecutive data points, and raise the alarm once every 15 minutes. | Node availability issues or downtime can lead to message loss, especially when persistence or image queues are not enabled. This will also increase the load on other nodes, potentially reducing overall cluster performance. It is recommended to check the cause in combination with other metrics and alarm information. |
Note:
Metric: For example, number of connections. If the calculation granularity is set to 1 minute, an alarm will be triggered if the average production latency exceeds the threshold for N consecutive data points within 1 minute.
Alarm frequency: For example, alarm once every 30 minutes means that within a 30-minute period, even if the metric exceeds the threshold during multiple consecutive calculation cycles, only one alarm will be triggered. No further alarms will be triggered during that 30-minute window. If the metric continues to exceed the threshold after the 30-minute period, a new alarm will be triggered.
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No