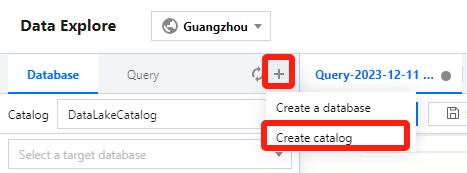
2. Select Data Explore on the left sidebar, click + in the Database & table column, and select Create data catalog.
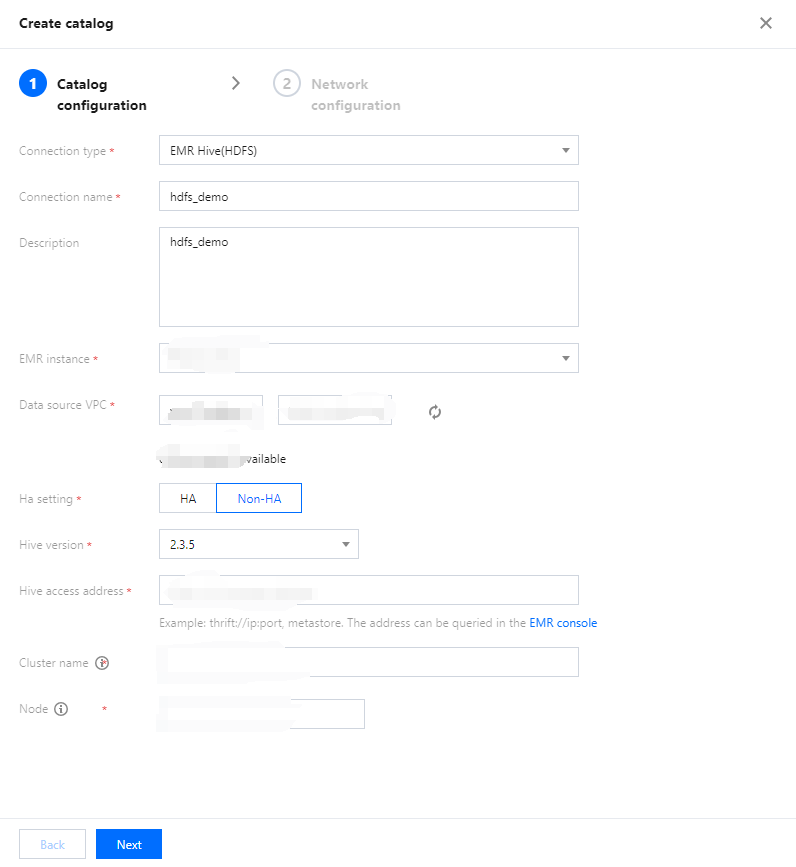
3. Select EMR Hive (HDFS) for Connection type and select the target EMR instance. The VPC information will be populated by default after the instance is selected. EMR versions supported by EMR Hive are 2.3.5, 2.3.7, 3.1.1, and 3.1.2.
Note:
Relevant permissions are required for you to select the EMR Hive instance.
4. Select the Run cluster. Currently, you can only select a private data engine of Presto. If there is no engine, create one on the Data engine page. For more information on the purchase process, see Purchasing Private Data Engine.
Note:
The IP range of the selected data engine cannot be the same as that of the EMR instance; otherwise, a network conflict will occur, and you cannot query or analyze data.
5. Click Confirm.
Querying the EMR Hive data
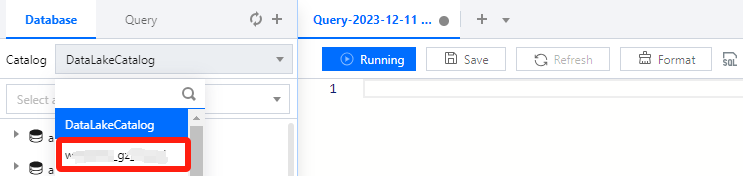
After the data catalog is created, you can switch to it from the Data catalog menu on the Data Explore page.
At this point, you can query and analyze the data catalog with SQL statements.
Select the data engine bound when the data catalog is created and click Run to get the query result.
Note:
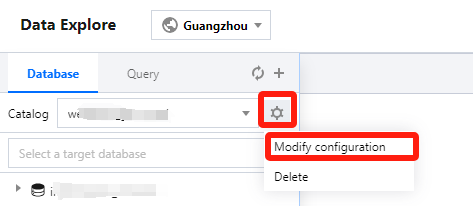
You can only query the data catalog with its bound data engine. To change the bound engine, click the set icon next to the data catalog.