- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Development Guide
- Design of Data Table
- Importing Data
- Import Overview
- Import Methods
- Synchronizing Data with JDBC
- Synchronizing Data Through External Tables
- Real-time or Batch Writing of MySQL Data
- Importing Data from Kafka
- Importing with DataX
- Importing Doris from Logstash
- Data Transformation, Column Mapping and Filtering
- Importing Strict Mode
- Importing Data in JSON Format
- Exporting Data
- Basic Feature
- Query Optimization
- Ecological Expansion Feature
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Cluster Operation APIs
- ModifyClusterConfigs
- ModifyInstanceKeyValConfigs
- ModifyNodeStatus
- RestartClusterForConfigs
- RestartClusterForNode
- CreateInstanceNew
- DestroyInstance
- ModifySecurityGroups
- ReduceInstance
- ResizeDisk
- ScaleOutInstance
- ScaleUpInstance
- DescribeClusterConfigsHistory
- ModifyInstance
- DescribeCreateTablesDDL
- DescribeInstanceOperationHistory
- Database and Table APIs
- Cluster Information Viewing APIs
- Hot-Cold Data Layering APIs
- Database and Operation Audit APIs
- CancelBackupJob
- CreateBackUpSchedule
- DeleteBackUpData
- DescribeBackUpJob
- DescribeBackUpJobDetail
- DescribeBackUpTables
- DescribeBackUpTaskDetail
- DescribeRestoreTaskDetail
- DescribeBackUpSchedules
- RecoverBackUpJob
- DescribeInstanceOperations
- DescribeDatabaseAuditDownload
- DescribeDatabaseAuditRecords
- DescribeSlowQueryRecords
- DescribeSlowQueryRecordsDownload
- DescribeQueryAnalyse
- User and Permission APIs
- Resource Group Management APIs
- Data Types
- Error Codes
- Cloud Ecosystem
- Practical Tutorial
- Performance Testing
- FAQs
- Service Level Agreement
- Contact Us
- Glossary
- Product Policy
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Development Guide
- Design of Data Table
- Importing Data
- Import Overview
- Import Methods
- Synchronizing Data with JDBC
- Synchronizing Data Through External Tables
- Real-time or Batch Writing of MySQL Data
- Importing Data from Kafka
- Importing with DataX
- Importing Doris from Logstash
- Data Transformation, Column Mapping and Filtering
- Importing Strict Mode
- Importing Data in JSON Format
- Exporting Data
- Basic Feature
- Query Optimization
- Ecological Expansion Feature
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Cluster Operation APIs
- ModifyClusterConfigs
- ModifyInstanceKeyValConfigs
- ModifyNodeStatus
- RestartClusterForConfigs
- RestartClusterForNode
- CreateInstanceNew
- DestroyInstance
- ModifySecurityGroups
- ReduceInstance
- ResizeDisk
- ScaleOutInstance
- ScaleUpInstance
- DescribeClusterConfigsHistory
- ModifyInstance
- DescribeCreateTablesDDL
- DescribeInstanceOperationHistory
- Database and Table APIs
- Cluster Information Viewing APIs
- Hot-Cold Data Layering APIs
- Database and Operation Audit APIs
- CancelBackupJob
- CreateBackUpSchedule
- DeleteBackUpData
- DescribeBackUpJob
- DescribeBackUpJobDetail
- DescribeBackUpTables
- DescribeBackUpTaskDetail
- DescribeRestoreTaskDetail
- DescribeBackUpSchedules
- RecoverBackUpJob
- DescribeInstanceOperations
- DescribeDatabaseAuditDownload
- DescribeDatabaseAuditRecords
- DescribeSlowQueryRecords
- DescribeSlowQueryRecordsDownload
- DescribeQueryAnalyse
- User and Permission APIs
- Resource Group Management APIs
- Data Types
- Error Codes
- Cloud Ecosystem
- Practical Tutorial
- Performance Testing
- FAQs
- Service Level Agreement
- Contact Us
- Glossary
- Product Policy
Colocation Join aims to provide local optimization for some Join queries to reduce data transmission time between nodes and speed up queries. The original design, implementation and effect can be referred to ISSUE 245.
The Colocation Join function has undergone a revision, and its design and use are slightly different from the original design. This document mainly introduces the principles, implementation, usage and precautions of Colocation Join.
Definitions
FE: Frontend, the frontend node of Doris, responsible for Metadata management and request access.
BE: Backend, the backend node of Doris, responsible for query execution and data storage.
Colocation Group (CG): A CG may contain one or more Tables. Tables in the same Group have the same Colocation Group Schema and the same data tablet distribution.
Colocation Group Schema (CGS): Used to describe table in a CG and general Schema information related to Colocation, including bucket column type, number of buckets, copy number, etc.
Principles
The function of Colocation Join is to make a CG of a set of Tables with the same CGS. Ensure that the corresponding data tablets of these Tables will fall on the same BE node. When tables in CG perform Join operations on bucket columns, local data Join can be directly performed to reduce data transmission time between nodes.
The data of a table will eventually fall into a certain bucket according to the Hash value of the bucket column. Assuming that the number of buckets in a table is 8, there are
[0, 1, 2, 3, 4, 5, 6, 7] 8 buckets (Bucket). We call such a sequence a BucketsSequence. Each Bucket has one or more tablets. When a table is a single partition table, there is only one Tablet within a Bucket. If it is a multi-partition table, there will be more than one.
In order for a Table to have the same data distribution, the Table in the same CG must ensure the following attributes are the same:1. Bucket column and number of buckets.
Bucket column, that is, the column specified in
DISTRIBUTED BY HASH(col1, col2, ...)in the table building statement. Bucket columns determine which column values a table's data will be Hash divided into different Tablets. Tables in the same CG must ensure that the type and number of bucket columns are identical, and the number of buckets is identical, so that the data tablets of multiple tables can be controlled one by one.2. Number of replicas.
The number of replicas of all partitions (Partition) of all tables in the same CG must be the same. If inconsistent, there may be a replica of a Tablet, and there is no corresponding replicas of other tablets on the same BE.
Tables in the same CG do not require consistency in the number, scope, and type of partition columns.
After fixing the bucket column and the number of buckets, tables in the same CG will have the same BucketsSequence. And the number of replicas determines which BEs the multiple replicas of Tablets in each bucket are stored on. Suppose BucketsSequence is
[0, 1, 2, 3, 4, 5, 6, 7], and there are [A, B, C, D] 4 BE nodes. Then a possible data distribution is as follows:+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+| 0 | | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 |+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+| A | | B | | C | | D | | A | | B | | C | | D || | | | | | | | | | | | | | | || B | | C | | D | | A | | B | | C | | D | | A || | | | | | | | | | | | | | | || C | | D | | A | | B | | C | | D | | A | | B |+---+ +---+ +---+ +---+ +---+ +---+ +---+ +---+
The data of all tables in the CG will be uniformly distributed according to the above rules, which ensures that data with the same bucket column value are on the same BE node, and local data Join can be carried out.
Use Method
Creating Tables
When creating a table, you can specify the attribute in
PROPERTIES "colocate_with" = "group_name", which means that this table is a Colocation Join table, and belongs to a specified Colocation Group.
Examples:CREATE TABLE tbl (k1 int, v1 int sum)DISTRIBUTED BY HASH(k1)BUCKETS 8PROPERTIES ("colocate_with" = "group1");
If the specified Group does not exist, Doris automatically creates a Group that contains only the current table. If the Group already exists, Doris checks whether the current table satisfies the Colocation Group Schema. If satisfied, the table is created and added to the Group. At the same time, tables create tablets and replicas based on existing data distribution rules in the Groups.
Group belongs to a Database, and its name is unique in a Database. Internal Storage is the full name of Group
dbId_groupName, but the users only perceive groupName.Deleting Table
When the last table in Group is deleted completely (deleting completely means deleting from the recycle bin). Generally, when a table is deleted by the
DROP TABLE command, and it will be deleted after the default one-day stay in the recycle bin, and the Group will be deleted automatically.View Group
The following command allows you to view the existing Group information in the cluster.
SHOW PROC '/colocation_group';+-------------+--------------+--------------+------------+----------------+----------+----------+| GroupId | GroupName | TableIds | BucketsNum | ReplicationNum | DistCols | IsStable |+-------------+--------------+--------------+------------+----------------+----------+----------+| 10005.10008 | 10005_group1 | 10007, 10040 | 10 | 3 | int(11) | true |+-------------+--------------+--------------+------------+----------------+----------+----------+
GroupId: The unique identity of a Group's entire cluster, with db id in the first half and group id in the second half.
GroupName: The full name of Group.
TabletIds: The id list of the Table contained in the Group.
BucketsNum: Number of buckets.
ReplicationNum: Number of replicas.
DistCols: Distribution columns, i.e., types of bucket columns.
IsStable: Is the Group stable (for the definition of stable, see section Colocation Replica Rebalancing and Repair).
You can further view the data distribution of a Group by following commands:
SHOW PROC '/colocation_group/10005.10008';+-------------+---------------------+| BucketIndex | BackendIds |+-------------+---------------------+| 0 | 10004, 10002, 10001 || 1 | 10003, 10002, 10004 || 2 | 10002, 10004, 10001 || 3 | 10003, 10002, 10004 || 4 | 10002, 10004, 10003 || 5 | 10003, 10002, 10001 || 6 | 10003, 10004, 10001 || 7 | 10003, 10004, 10002 |+-------------+---------------------+
BucketIndex: Subscript to the bucket sequence.
BackendIds: A list of BE node IDs where data tablets are located in bucket.
Note
The above commands require ADMIN privileges. Normal user view is not supported at this time.
Use Limits
To use colocation join, following conditions must be met:
For tables involved in colocation join, the Colocation Group attribute must be enabled in the configuration, and they must belong to the same Colocation Group.
Tables within the same CG must ensure the following attributes are the same:
Bucket column and number of buckets
Number of replicas
Modifying the Colocate Group attribute of a table
You can modify the Colocation Group attribute of a table that has already been created. Example:
ALTER TABLE tbl SET ("colocate_with" = "group2");.If the table has not previously indicated a Group, this command checks the Schema and adds the table to the Group (the Group will be created if there is no existing Group).
If the table has previously indicated another Group, this command will first remove the table from the original Group and add it to the new Group (the Group will be created if there is no existing Group).
The following command can also be used to remove the Colocation property from a table:
ALTER TABLE tbl SET ("colocate_with" = "");.Other related operations
When adding a partition (ADD PARTITION) or modifying the number of replicas to a table with the Colocation property, Doris checks whether the modification will violate the Colocation Group Schema and refuses if it does.
Colocation Replica Balancing and Repair
The distribution of replicas of a Colocation table needs to follow the distribution specified in the Group, so there are differences from regular tablets in terms of replica repair and balance.
A Group has a Stable attribute. When Stable is true, it means that all tablets in all tables in the current Group are not being modified, and the Colocation feature can be used normally. When Stable is false (Unstable), it means that some tables in the current Group are having their tablets repaired or moved. At this time, the Colocation Join of the related tables will degrade to a regular Join.
Replica Repair
The replicas can only be stored on the specified BE node. Therefore, when a BE is unavailable (e.g., due to downtime or decommissioning), it’s necessary to find a replacement BE. Doris will prioritize finding a BE with lower load for substitution. Once they are replaced, all data tablets on the old BE in the Bucket need to be repaired. During this migration process, the Group is tagged as Unstable.
Replica Balancing
Doris strives to uniformly distribute the tablets of Colocation tables across all BE nodes. For normal table replica balancing, the granularity is single replica, i.e., just finding an available BE node with lower load for each replica. However, for Colocation tables, the balance is at the Bucket level, i.e., all the replicas in the same Bucket will be migrated together. A simple balancing algorithm is adopted that does not consider the actual size of the replica, but simply evenly distributes the BucketsSequence based on the number of replicas across all BEs. The specific algorithm can be referred to in the code comments of
ColocateTableBalancer.java.Note
The current Colocation replica balancing and repair algorithm may not work well for heterogeneously deployed Doris cluster. The heterogeneous deployment means the BE nodes have inconsistent disk capacity, quantity, and disk types (SSD and HDD). In heterogeneous deployment scenarios, BE nodes with smaller and larger capacities may store the same number of replicas.
When a Group is in an Unstable state, the Join of tables in the Group will degrade to a regular Join. This can significantly reduce the cluster's query performance. If you do not want the system to automatically balance, you can disable the automatic balance by setting the FE's configuration item
disable_colocate_balance. You can turn it on again at appropriate time (see section Advanced Operations for details).Query
The query of Colocation tables is the same as that on normal tables, and users do not need to be aware of the Colocation attributes. If the Colocation table's Group is in an Unstable state, it will automatically degrade to a regular Join.
Example:
Table 1:
CREATE TABLEtbl1(k1date NOT NULL COMMENT "",k2int(11) NOT NULL COMMENT "",v1int(11) SUM NOT NULL COMMENT "") ENGINE=OLAPAGGREGATE KEY(k1,k2)PARTITION BY RANGE(k1)(PARTITION p1 VALUES LESS THAN ('2019-05-31'),PARTITION p2 VALUES LESS THAN ('2019-06-30'))DISTRIBUTED BY HASH(k2) BUCKETS 8PROPERTIES ("colocate_with" = "group1");
Table 2:
CREATE TABLEtbl2(k1datetime NOT NULL COMMENT "",k2int(11) NOT NULL COMMENT "",v1double SUM NOT NULL COMMENT "") ENGINE=OLAPAGGREGATE KEY(k1,k2)DISTRIBUTED BY HASH(k2) BUCKETS 8PROPERTIES ("colocate_with" = "group1");
View query plan:
DESC SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);+----------------------------------------------------+| Explain String |+----------------------------------------------------+| PLAN FRAGMENT 0 || OUTPUT EXPRS:tbl1.k1| || PARTITION: RANDOM || || RESULT SINK || || 2:HASH JOIN || | join op: INNER JOIN || | hash predicates: || | colocate: true || |tbl1.k2=tbl2.k2|| | tuple ids: 0 1 || | || |----1:OlapScanNode || | TABLE: tbl2 || | PREAGGREGATION: OFF. Reason: null || | partitions=0/1 || | rollup: null || | buckets=0/0 || | cardinality=-1 || | avgRowSize=0.0 || | numNodes=0 || | tuple ids: 1 || | || 0:OlapScanNode || TABLE: tbl1 || PREAGGREGATION: OFF. Reason: No AggregateInfo || partitions=0/2 || rollup: null || buckets=0/0 || cardinality=-1 || avgRowSize=0.0 || numNodes=0 || tuple ids: 0 |+----------------------------------------------------+
If Colocation Join takes effect, the Hash Join node will display
colocate: true.If it does not take effect, the query plan is as follows:
+----------------------------------------------------+| Explain String |+----------------------------------------------------+| PLAN FRAGMENT 0 || OUTPUT EXPRS:tbl1.k1| || PARTITION: RANDOM || || RESULT SINK || || 2:HASH JOIN || | join op: INNER JOIN (BROADCAST) || | hash predicates: || | colocate: false, reason: group is not stable || |tbl1.k2=tbl2.k2|| | tuple ids: 0 1 || | || |----3:EXCHANGE || | tuple ids: 1 || | || 0:OlapScanNode || TABLE: tbl1 || PREAGGREGATION: OFF. Reason: No AggregateInfo || partitions=0/2 || rollup: null || buckets=0/0 || cardinality=-1 || avgRowSize=0.0 || numNodes=0 || tuple ids: 0 || || PLAN FRAGMENT 1 || OUTPUT EXPRS: || PARTITION: RANDOM || || STREAM DATA SINK || EXCHANGE ID: 03 || UNPARTITIONED || || 1:OlapScanNode || TABLE: tbl2 || PREAGGREGATION: OFF. Reason: null || partitions=0/1 || rollup: null || buckets=0/0 || cardinality=-1 || avgRowSize=0.0 || numNodes=0 || tuple ids: 1 |+----------------------------------------------------+
HASH JOIN node displays the corresponding reason:
colocate: false, reason: group is not stable. An EXCHANGE node will also be generated.Advanced Operations
FE Configuration Item
disable_colocate_relocate
Whether to disable Doris's automatic colocation replica repair. The default is false, which means not to disable it. This parameter only affects the repair of colocation table replicas and does not affect ordinary tables.
disable_colocate_balance
Whether to disable Doris's automatic Colocation replica balance. The default is false, which means not to disable it. This parameter only affects the balance of Colocation table replicas and does not affect ordinary tables.
The above parameters can be dynamically modified. For the method of setting, please refer to
HELP ADMIN SHOW CONFIG; and HELP ADMIN SET CONFIG;.disable_colocate_join
Whether to disable the Colocation Join feature. In version 0.10 and earlier, the default is true, which means to disable. In later versions, it will default to false, which means to enable.
use_new_tablet_scheduler
In version 0.10 and earlier, the new replica scheduling logic is incompatible with the Colocation Join feature. Therefore, in version 0.10 and earlier, if
disable_colocate_join = false, then you need to set use_new_tablet_scheduler = false, which means to disable the new replica scheduler. In later versions, the use_new_tablet_scheduler will be balanced to true.HTTP Restful API
Doris provides several HTTP Restful APIs related to Colocation Join for viewing and modifying the Colocation Group.
This API is implemented on the FE side and is accessed using
fe_host:fe_http_port. ADMIN privileges are required.1. View all the Colocation information of the cluster.
GET /api/colocateReturn the internal Colocation information in Json format.{"msg": "success","code": 0,"data": {"infos": [["10003.12002", "10003_group1", "10037, 10043", "1", "1", "int(11)", "true"]],"unstableGroupIds": [],"allGroupIds": [{"dbId": 10003,"grpId": 12002}]},"count": 0}
2. Mark the Group as Stable or Unstable.
Mark as Stable:
POST /api/colocate/group_stable?db_id=10005&group_id=10008Return: 200
Mark as Unstable:
DELETE /api/colocate/group_stable?db_id=10005&group_id=10008Return: 200
3. Setting the data distribution of a Group.
This API can forcefully set the data distribution of a particular Group.
POST /api/colocate/bucketseq?db_id=10005&group_id=10008Body:[[10004,10002],[10003,10002],[10002,10004],[10003,10002],[10002,10004],[10003,10002],[10003,10004],[10003,10004],[10003,10004],[10002,10004]]Return 200
The Body is a BucketsSequence represented by nested arrays and the id of the BE where each tablet in the Bucket is located.
Note
When using this command, you may need to set the
disable_colocate_relocate and disable_colocate_balance in FE configuration to true. That is, disable the system's automatic colocation backup repair and balance. Otherwise, it may be automatically reset by the system after modifications.Best Practice
Based on the TPC-H 100G dataset as a case, business simulation is carried out here with the following SQL, which takes 5s and join optimization is expected to be performed.
select * from lineitem inner join orders on l_orderkey = o_orderkey where l_orderkey >500000000 limit 10;
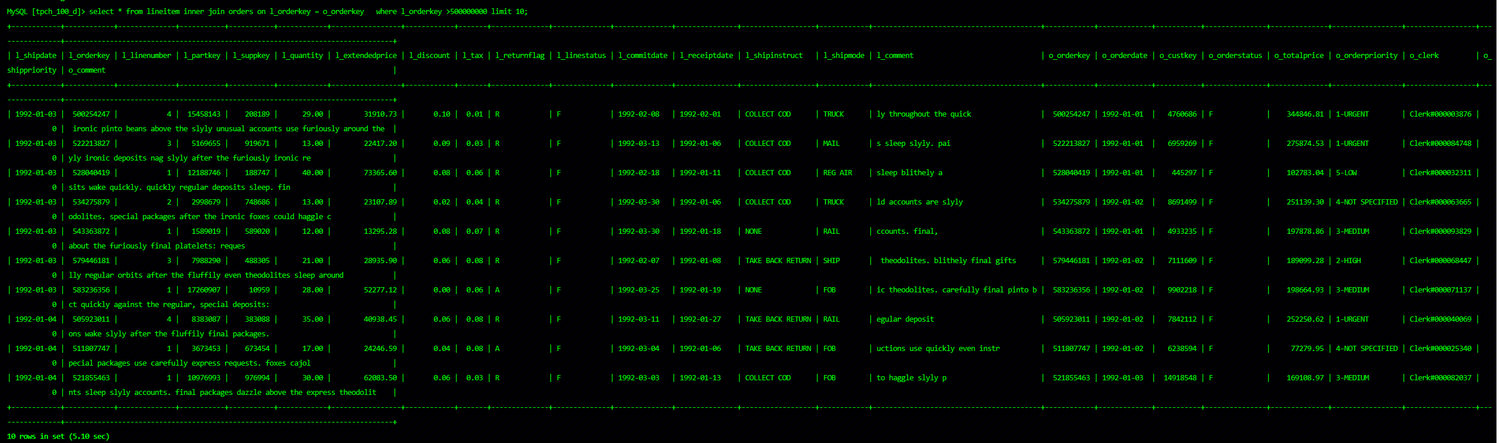
The involved table structure is as follows:
lineitem table:
CREATE TABLE lineitem ( l_shipdate date NOT NULL, l_orderkey bigint(20) NOT NULL, l_linenumber int(11) NOT NULL, l_partkey int(11) NOT NULL, l_suppkey int(11) NOT NULL, l_quantity decimalv3(15, 2) NOT NULL, l_extendedprice decimalv3(15, 2) NOT NULL, l_discount decimalv3(15, 2) NOT NULL, l_tax decimalv3(15, 2) NOT NULL, l_returnflag varchar(1) NOT NULL, l_linestatus varchar(1) NOT NULL, l_commitdate date NOT NULL, l_receiptdate date NOT NULL, l_shipinstruct varchar(25) NOT NULL, l_shipmode varchar(10) NOT NULL, l_comment varchar(44) NOT NULL ) ENGINE=OLAP DUPLICATE KEY(l_shipdate, l_orderkey) COMMENT 'OLAP' DISTRIBUTED BY HASH(l_orderkey) BUCKETS 96 PROPERTIES ( "replication_allocation" = "tag.location.default: 3", "in_memory" = "false", "storage_format" = "V2", "disable_auto_compaction" = "false" );
orders table:
CREATE TABLE orders ( o_orderkey bigint(20) NOT NULL, o_orderdate date NOT NULL, o_custkey int(11) NOT NULL, o_orderstatus varchar(1) NOT NULL, o_totalprice decimalv3(15, 2) NOT NULL, o_orderpriority varchar(15) NOT NULL, o_clerk varchar(15) NOT NULL, o_shippriority int(11) NOT NULL, o_comment varchar(79) NOT NULL ) ENGINE=OLAP DUPLICATE KEY(o_orderkey, o_orderdate) COMMENT 'OLAP' DISTRIBUTED BY HASH(o_orderkey) BUCKETS 96 PROPERTIES ( "replication_allocation" = "tag.location.default: 3", "in_memory" = "false", "storage_format" = "V2", "disable_auto_compaction" = "false" );
View the execution plan by explain, and analyze the current join method
explain select * from lineitem inner join orders on l_orderkey = o_orderkey where l_orderkey >500000000 limit 10;
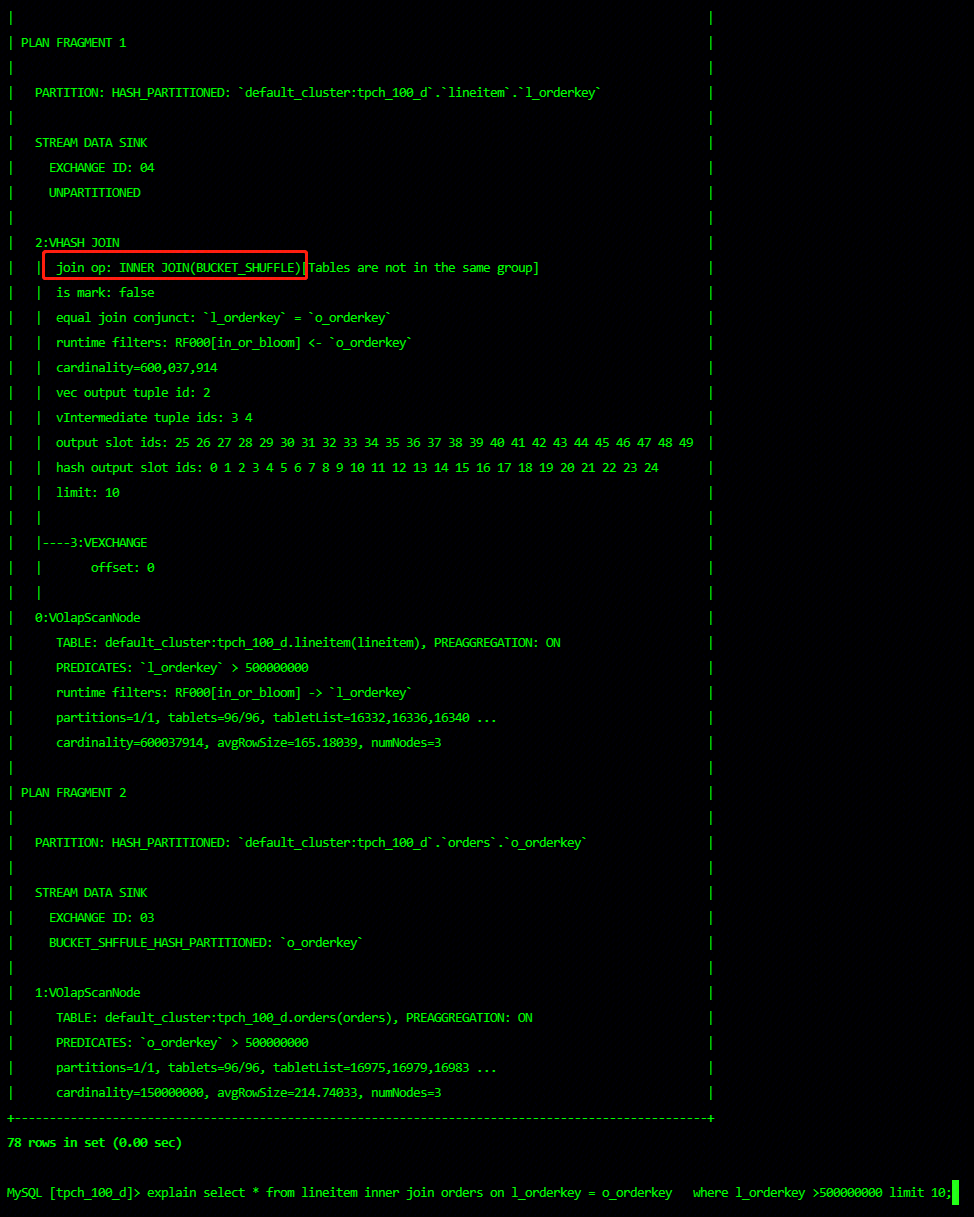
In the hash join node, you can see that the join used is bucket shuffle join.
Analyze whether the left and right tables meet the colocation join conditions
The relevant conditions of the 2 tables can be seen:
Condition | lineitem table | order table | Whether the colocation join conditions are met |
Bucket column | l_orderkey (type bigint 20) | o_orderkey (type bigint 20) | Met |
Number of Buckets | 96 | 96 | Met |
Number of replicas | 3 | 3 | Met |
If the table of business does not meet the requirements, you can adapt it by recreating the table and then migrate the data using the select into select method.
Modify the table attributes to meet the same colocation group conditions
ALTER TABLE lineitem SET ("colocate_with" = "tpch_group");ALTER TABLE orders SET ("colocate_with" = "tpch_group");
Analyze whether colocation join is effective by explain
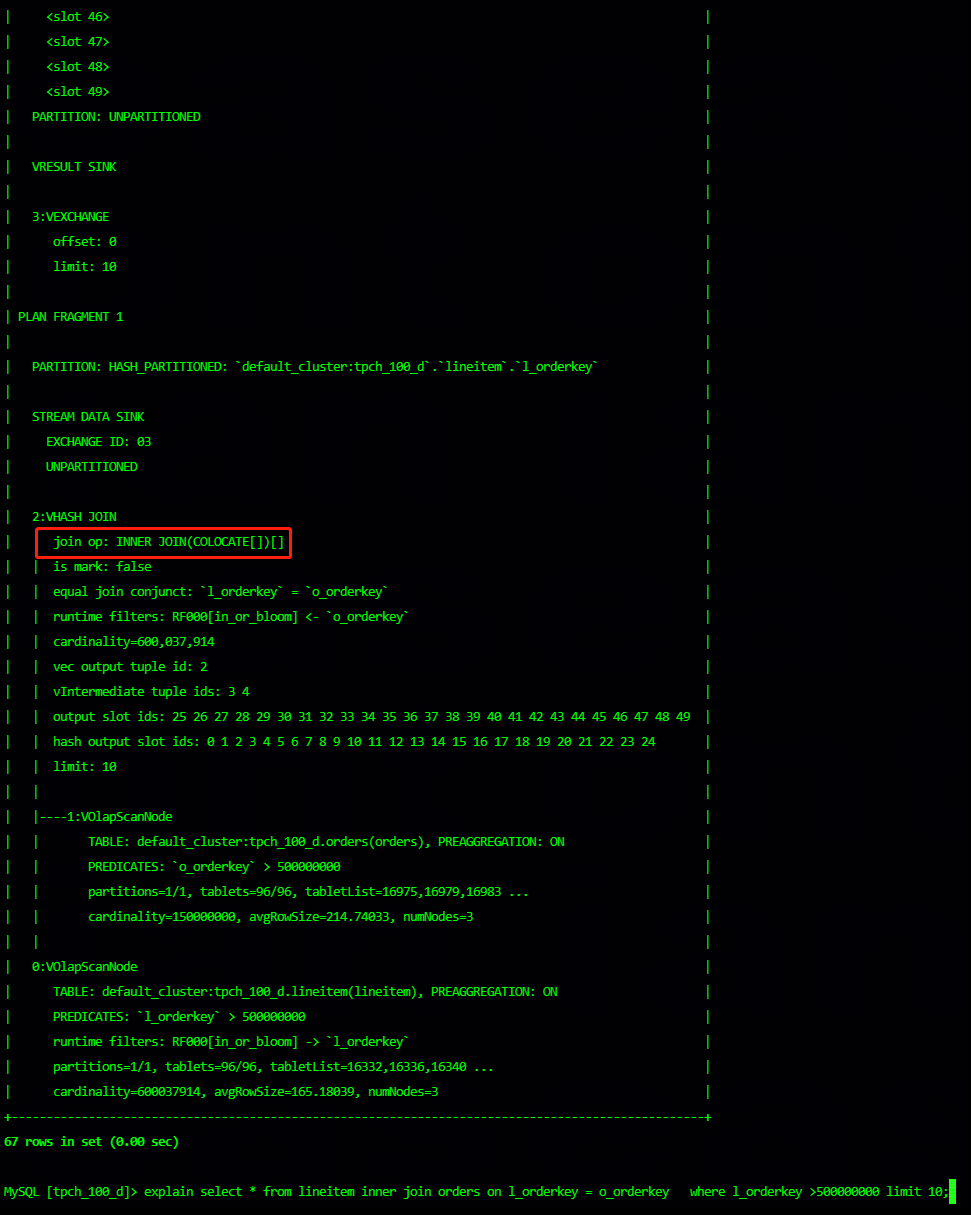
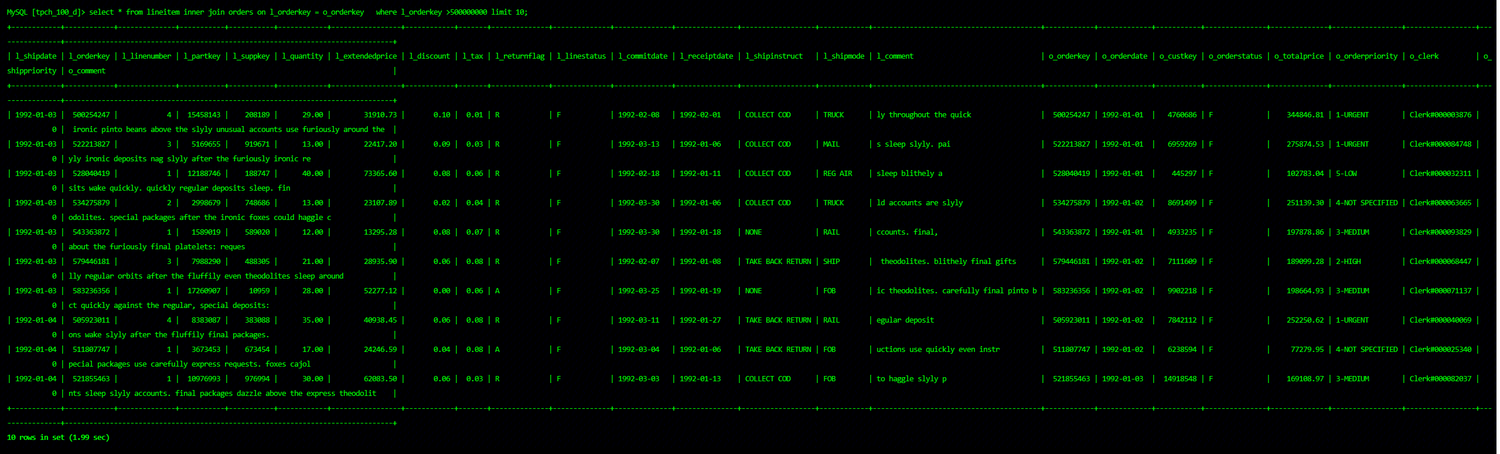
Whether the actual execution of SQL viewing efficiency has improved
Comparing with the consumed time before colocation join optimization (5s+), the time becomes 2s after colocation join optimization. The efficiency is improved by more than double. In scenarios where large tables join large tables, the efficiency improvement will be greater.

 Yes
Yes
 No
No
Was this page helpful?