- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Practical Tutorial
- Message Queue Model
- Message Topic Model
- Migration Description
- Solutions and Cases
- API Documentation
- SDK
- Service Level Agreement
- Glossary
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Practical Tutorial
- Message Queue Model
- Message Topic Model
- Migration Description
- Solutions and Cases
- API Documentation
- SDK
- Service Level Agreement
- Glossary
Comparative Analysis of Cloud CMQ and RabbitMQ
Last updated: 2020-07-20 16:23:52
RabbitMQ is a typical open-source messaging middleware program. It is popular among enterprise systems and suitable for scenarios with high requirements for data consistency, stability, and reliability.
Based on the high reliability of RabbitMQ/AMQP and by leveraging the Raft protocol in redesign and reimplementation, Tencent Cloud CMQ greatly improves the reliability, throughput, and performance.
This document describes RabbitMQ's reliability principle, improvement made by CMQ, and performance comparison between them.
Reliable Message Delivery of RabbitMQ
ACK mechanism
A business may lose messages due to various issues such as network, server, or program exceptions. The message ACK mechanism can solve the problem of message loss. If a message is successfully acknowledged, it means that the message has been verified and correctly processed.
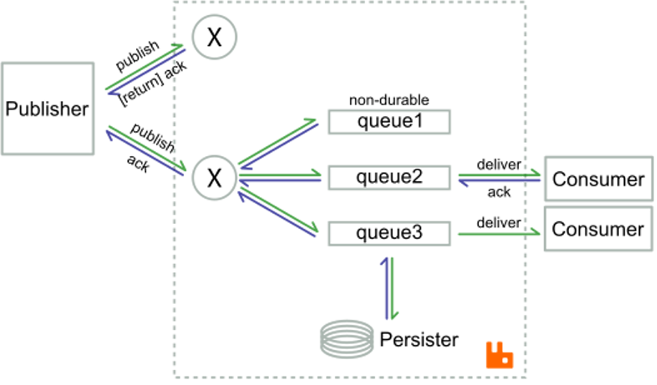
RabbitMQ uses the mechanism of produced and consumed message ACK to ensure reliable delivery.
Produced message ACK: after the producer sends a message to the message queue, it will wait for the return of an ACK of success; otherwise, the producer will resend the message to the message queue. This process can be async, that is, the producer continuously sends messages, and the message queue can return ACKs after processing them in batches. The producer can identify the message IDs in the returned ACKs to determine which messages have been successfully processed.
Consumed message ACK: after the message queue delivers a message to the consumer, it will wait for the return of an ACK of success; otherwise, the message queue will resend the message to the consumer. This process can also be async, that is, the message queue continuously delivers messages, and the consumer can return ACKs after processing them in batches.
You can see that RabbitMQ/AMQP provides "at-least-once delivery". When exceptions occur, messages will be repeatedly delivered or consumed.
Message storage
To improve message reliability and ensure that received messages can be persistently written into the disk when the service is unavailable during RabbitMQ restart, RabbitMQ will write received messages to a file and store it in the disk when the number of written messages reaches a certain value or after a certain period of time.
Produced message ACK is performed after message storage, and the message queue will return the ID of the stored message to the producer.
Comparison Between CMQ and RabbitMQ
CMQ has a lot of similarities with RabbitMQ in underlying principles and implementation methods; however, it is greatly upgraded and improved compared with RabbitMQ:
Feature upgrade
In addition to produced and consumed message ACK mechanisms, CMQ provides the message rewind feature.
You can specify the number of days during which CMQ stores produced messages. Then, the messages can be rewound back to a time point in this period for consumption again starting from the time point. The message rewind feature is very useful in business restoration when the business logic is exceptional.
Performance optimization
| Performance Metric | Description |
|---|---|
| Network IO | CMQ can produce/consume messages in batches, while RabbitMQ does not support batch production. In scenarios where there are high numbers of small-sized messages, CMQ can process them with fewer requests at a smaller average latency. |
| File IO | CMQ writes single messages in sequence during message production/consumption and regularly stores them in the disk, making full use of the file system for caching. In the persistent message mechanism of RabbitMQ, messages are sent to the in-memory queue for status conversion, then written into log cache, and finally written into message and index files (the index file is written sequentially, while the message file is written randomly), which involves three IO operations and has relatively low performance. |
| CPU performance | Computing for RabbitMQ log caching and status conversion is complicated and needs a lot of CPU resources, therefore compromising the performance. |
Improved availability
Both CMQ and RabbitMQ support hot backup with multiple servers to improve availability. CMQ implements this feature based on the Raft algorithm which is simple and easy to maintain, while RabbitMQ uses its proprietary Guaranteed Multicast (GM) algorithm which is difficult to learn.
In the Raft protocol, logs can be replicated as long as most nodes return a success to the leader, and the leader can implement the request and return a success to the client.
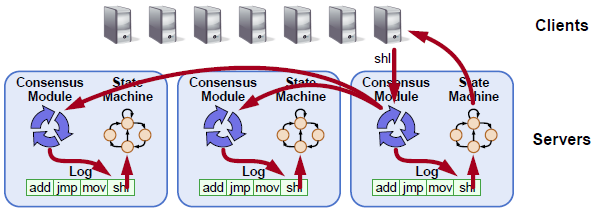
In GM, all nodes in the cluster are organized as a ring. A log replication request will be sent to subsequent nodes one by one after the leader. The leader will send an ACK message to the ring after it receives the request again. Only after the ACK is received by the leader again can the log be fully synced among all nodes in the ring.

The GM algorithm requires that success be returned only after logs have been synced among all nodes in the cluster, while the Raft algorithm requires sync only among most nodes, which reduces the waiting time in sync route by almost a half.
Performance comparison between CMQ and RabbitMQ
The testing scenario is as follows: three servers with the same configuration form a cluster, CMQ and RabbitMQ are both configured as image queues, and all data is synced on the three servers. CMQ and RabbitMQ both have the produced and consumed message ACK mechanisms enabled, and the size of produced messages is about 1 KB each.
| Test Environment | Description |
|---|---|
| CPU | 24-core Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40 GHz |
| Memory | 64 GB |
| Disk | 12 * 2 TB SATAs RAID 0 of 12 SATAs |
| ENI | 10-Gigabit |
| Linux version | 2.6.32.43 |
| RabbitMQ version | 3.6.2 |
| Erlang version | 18.3 |
The testing data is as follows:
| QPS Comparison | Production Only | Consumption Only | Simultaneous Production/Consumption |
|---|---|---|---|
| CMQ | Production: 68,000 messages/sec | Consumption: 90,000 messages/sec | Production: 36,000 messages/sec Consumption: 36,000 messages/sec |
| RabbitMQ | Production: 12,500 messages/sec | Consumption: 26,000 messages/sec | Production: 8,500 messages/sec Consumption: 8,500 messages/sec |
In high-reliability scenarios, the throughput of CMQ is four times higher than that of RabbitMQ.

 Yes
Yes
 No
No
Was this page helpful?