
Resource Managed Mode Management

Last updated: 2024-12-02 20:11:42
Overview of Function Resource Managed Mode
The function resource managed mode determines the resource pool for the SCF runtime. By default, upon enabling the function service, the platform allocates a public cloud resource pool for each region. This resource pool, composed of underlying machines, manifests as a 128 GB function concurrency quota. You can also enhance the concurrency quota of a region or even a namespace by purchasing packages. The platform will automatically allocate matching machines based on the new concurrency limit, ensuring the smooth operation of functions.
To better cater to your needs in various service scenarios, we now support a custom resource managed mode for functions. This allows functions to run on your specified infrastructure, such as public cloud TKE clusters, hybrid clouds, and IDCs.
The platform has now launched the K8s resource managed mode to support the execution of functions in your own TKE clusters, thereby accelerating business development using functions on a unified cloud-native resource base. Gradually, we will iterate to support more cloud-native infrastructures such as hybrid clouds.
Types of Function Resource Managed Modes
SCF supports two types: the Default Resource Managed Mode and the K8s Resource Managed Mode.
In the Default Resource Managed Mode, functions run in the public cloud resource pools under each region of the function platform. The function platform fully controls the supply and scheduling of underlying machines. You only need to focus on the actual service scale requirements and ensure service operations by adjusting the concurrency quotas of the function.
In the K8s Resource Managed Mode, functions run in your specified K8s cluster. You manage the resource supply in the K8s cluster, while the function platform fully controls the request scheduling of the functions, intelligently calling them within the given resource pool to fully utilize resources.
K8s Resource Managed Mode
Overview
In the K8s resource managed mode, you can select a TKE cluster as the computing resource pool for the function. All function request calling will be scheduled to this resource pool, and no fees will be generated on the function side. Currently, TKE cluster native nodes and ordinary nodes are supported, while super nodes are not.
In terms of usage, you only need to configure the resource managed mode as K8s in the function namespace and bind a TKE cluster to enable this mode. All function requests in this namespace will be scheduled to the bound TKE cluster.
Operating Principle
The scheduling principle of functions under the K8s resource managed mode is illustrated in the following diagram:
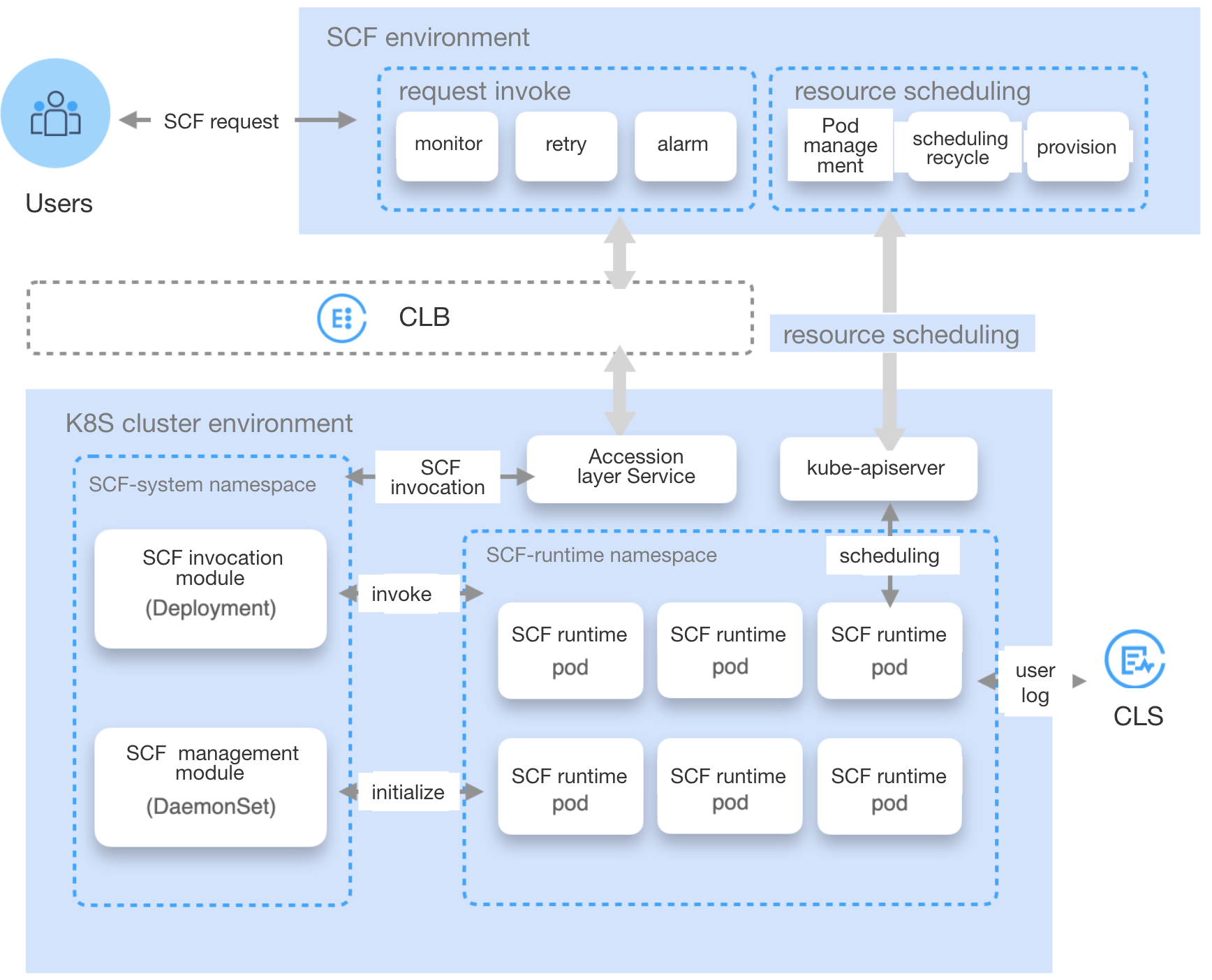
TKE Cluster Initialization
Once you have specified a TKE cluster and function runtime namespace for the function namespace, the platform will automatically create an scf-system namespace in the cluster, along with daemonset for deploying and managing function code metadata, request forwarding Pod, private CLB service components, and so on.
Function Request Scheduling Lifecycle
The function request sent by the user will first be directed to the request calling entry in the function environment. The function scheduling management module will then analyze whether there are idle function runtime Pod resources available for execution in the TKE cluster:
1. If there are no idle resources, a scheduling request will be issued to the TKE cluster via the resource scheduling module to prepare function runtime Pod resources. Once the Pod is ready, the function management module in the TKE cluster will prepare the function code and other metadata, and finally report the newly added runtime resources to the scheduling management module in the function environment.
2. If there are idle resources, the request will be forwarded to the access layer Service in the TKE cluster via the private CLB. Then, the function calling module in the cluster will send the request to the function runtime Pod, entering the function execution phase. During the function execution, logs will be reported in real time to the user's CLS log system. After the function execution ends, the execution results, monitoring metrics, and other information will be sent back to the request calling module in the function environment.
Advantages
Compared to the default resource managed mode, the K8s resource managed mode offers the following advantages:
Functions can run in your specified K8s cluster, offering greater flexibility and control, and enabling better cost management and stronger infrastructure resource management.
The proactive scheduling mechanism of the function can significantly enhance the resource utilization of your K8s cluster. It not only improves R&D efficiency through the function development experience, but also reduces the resource waste, truly achieving the cost reduction and efficiency enhancement.
After functions are integrated with the K8s ecosystem, a full-stack cloud-native research and development system and service governance mechanism can be achieved. This brings advanced development experiences to service developers and higher availability guarantees for online services.
Directions
Creating Function Namespace and Binding it to the TKE Cluster
1. Log in to the Serverless Console and click Functions in the left sidebar.
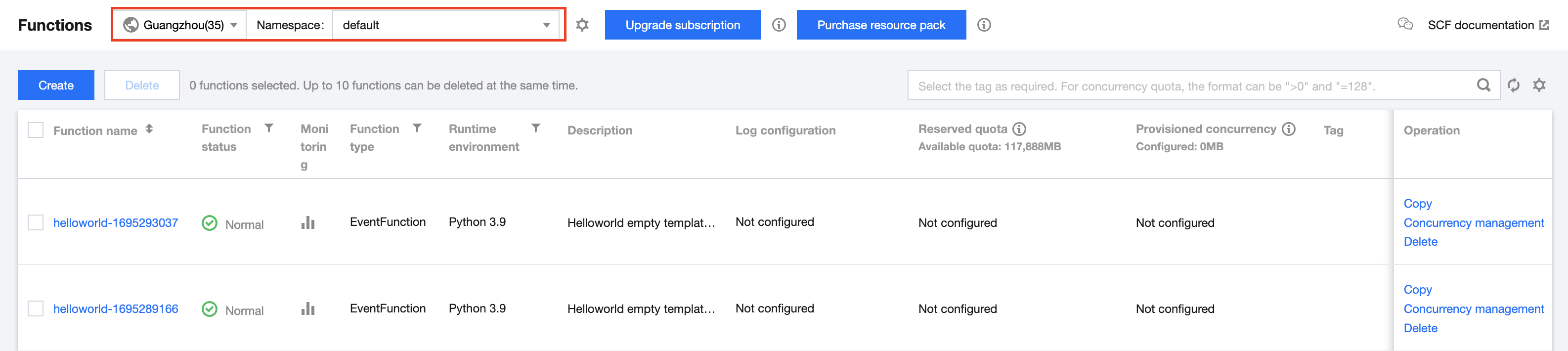
2. At the top of the Function Service page, select the region where you wish to create the function, and click on the ⚙️ next to the namespace to enter Namespace Management, as shown in the figure below:
3. In the Namespace pop-up window, click Create a Namespace to navigate to the namespace creation page, as shown in the figure below:
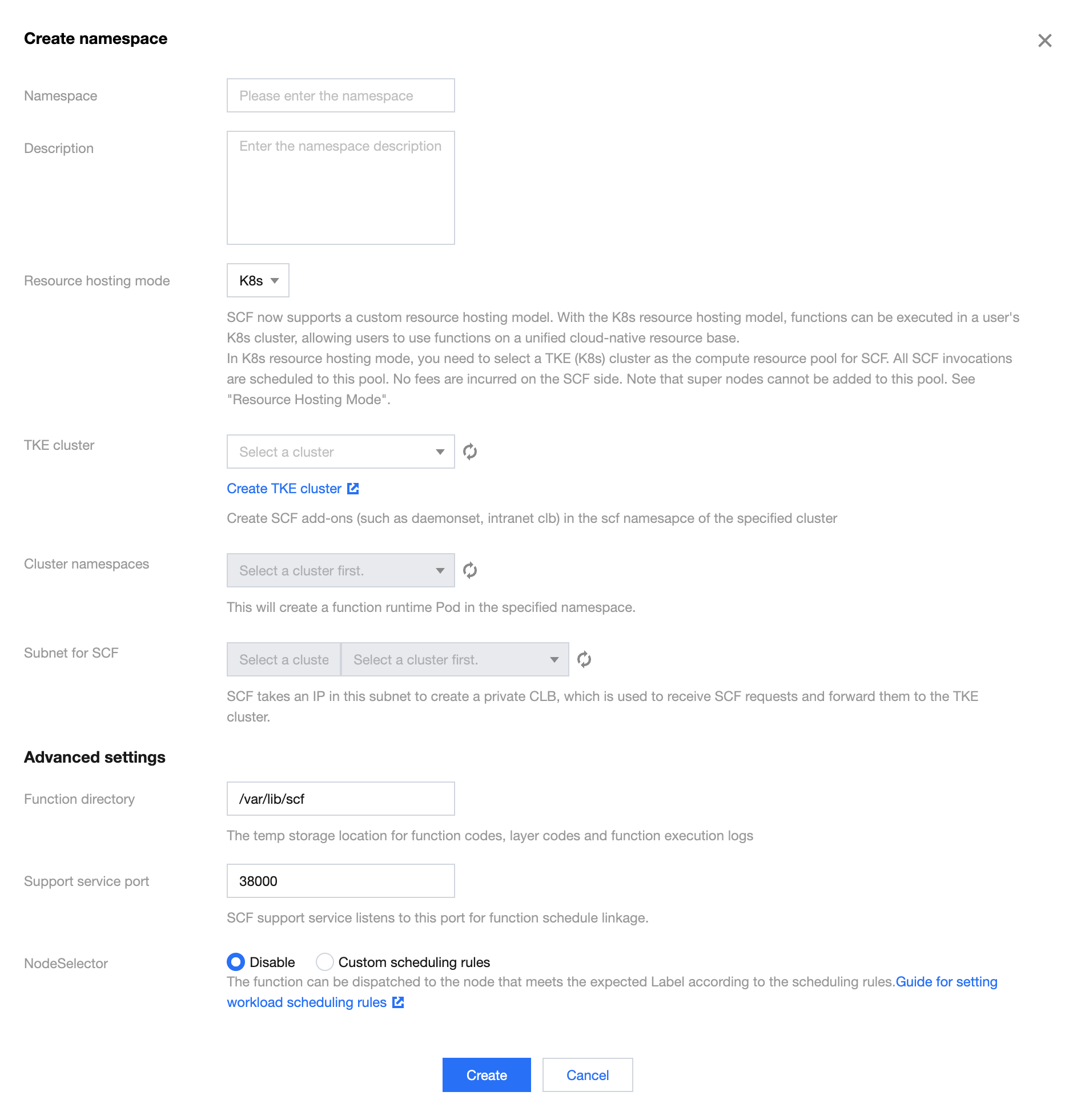
4. In Resource Managed Mode, select K8s. If this is your first time, a pop-up window for TKE role authorization will appear. Follow the instructions to complete the authorization before proceeding to the next step.
5. In TKE Cluster, select the TKE cluster and the namespace under that cluster. The platform will create function service support components such as daemonset and private CLB under the scf-system namespace of the specified cluster, and will create function runtime Pods under the specified namespace. Please ensure that there are nodes in the selected TKE cluster, and that the node types are normal and native nodes, to ensure that the initialization process is completed smoothly.
6. In Function VPC Subnet, specify the subnet. The platform will consume an IP address under this subnet to create a private CLB as the function request entry, enabling function request forwarding to the TKE cluster. Please note that the subnet does not support the 9.x.x.x IP range.
7. In addition to the basic configuration items above, you can also configure the following items as needed:
Function Directory: Specify a path on a TKE cluster node for temporary storage of function codes, layer codes, and logs generated during the function execution process.
Support Service Port: Specify an available port number. The function support service will listen on this port to implement the function scheduling link.
NodeSelector: Function instances can be scheduled to nodes with expected labels based on the scheduling rules. For more details, see the following section Setting the Scheduling Policy for Function Instances in the TKE Cluster.
Taints and Tolerations Scheduling: Function instances can be scheduled to nodes with expected taints based on the scheduling rules. For more details, see the following section Setting the Scheduling Policy for Function Instances in the TKE Cluster.
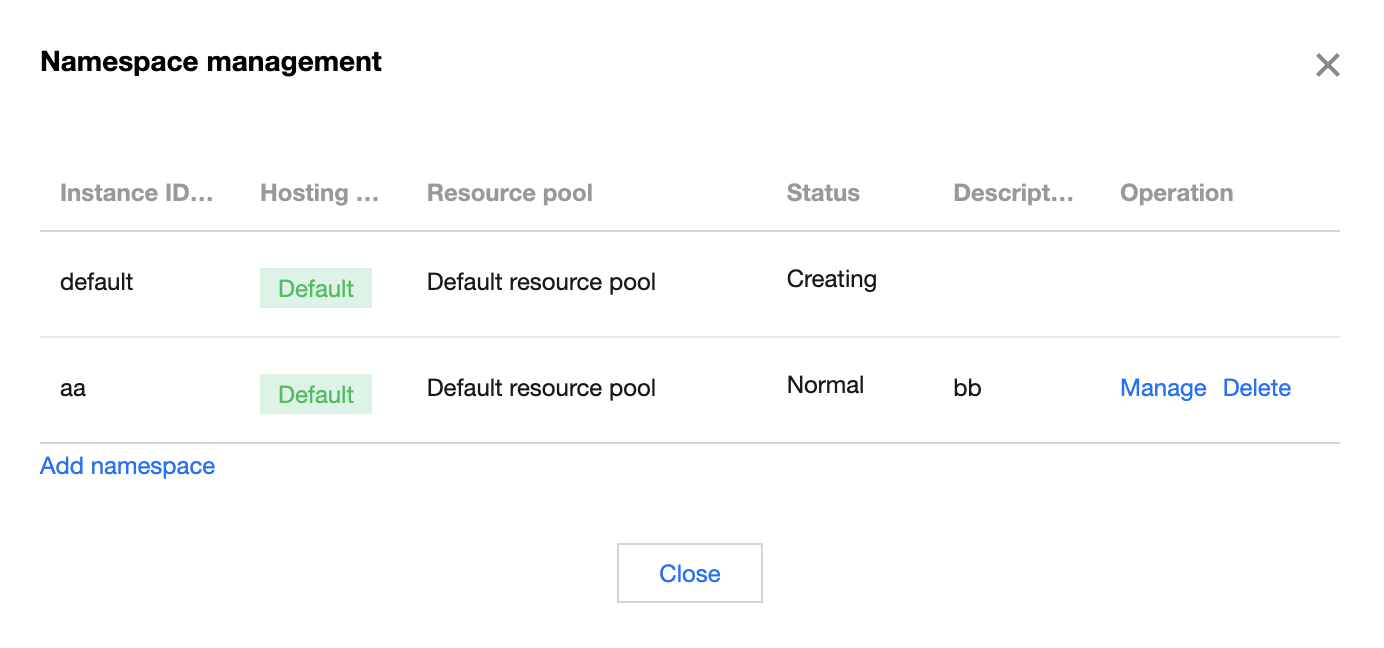
8. Click Create, and then in the pop-up confirmation window, click Continue. This will initiate the function support component initialization process in the TKE cluster, which will take approximately 20 seconds. Upon completion, you will see the status updated to Normal in the Namespace Management page, as shown below:
9. Switch to the created function namespace to creat and use functions.
Setting the Scheduling Policy for Function Instances in the TKE Cluster
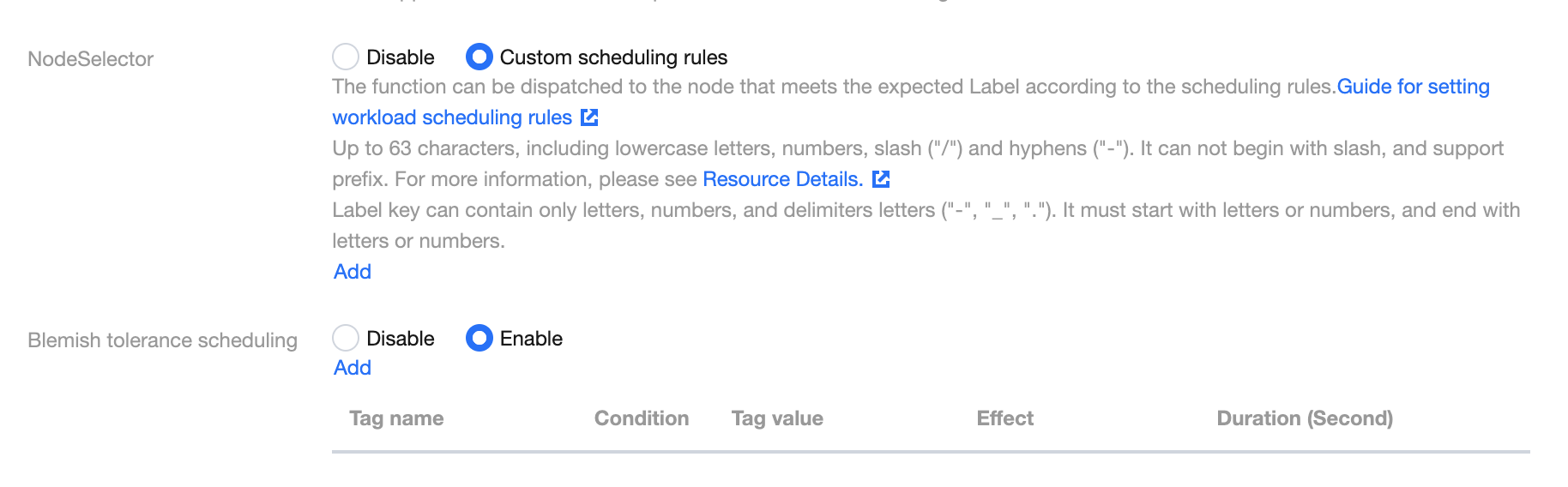
By setting the NodeSelector and taints and tolerations scheduling policies, you can specify the scheduling of function instances within the TKE cluster. This allows for more effective utilization of resources within the cluster. For more details, see Container Service - Proper Resource Allocation. The following application scenarios exist:
Run function instances on specified nodes.
Run function instances on nodes within a specific scope (the scope can be attributes such as availability zones, and machine types).
Prerequisites
The scheduling rule is set in the advanced settings of the workload, and the Kubernetes version of the cluster is 1.7 or higher.
To ensure that your Pods can be scheduled successfully, please make sure that the node has resources available for container scheduling after the scheduling rule is set.
When using the custom scheduling feature, it is necessary to set corresponding labels or taints for the nodes. For more details, please refer to Setting a Node Label and Setting a Node Taint.
Setting the Scheduling Rule
NodeSelector
Custom scheduling rules can be used to match node labels and schedule function instances to specified nodes. If an affinity condition is met during scheduling, it is scheduled to the corresponding node. If no node satisfies the condition, the scheduling fails.
Taints and Tolerations Scheduling
Through custom scheduling rules, node taints can be tolerated, allowing function instances to be scheduled onto specified nodes.
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No
Feedback