
Viewing Event Records

Last updated: 2025-09-19 16:04:28
The Event Center capability of TDMQ for CKafka (CKafka) supports centralized management, storage, analysis, and visualized display of various operational events, diagnostic events, and Broker change events that occur while the instance is running, making it easy for later inquiry, audit, and traceability. It also supports event alarms. You can configure alarm rules for key events (such as node decommissioning and automatic disk capacity expansion) and send event details to target objects, enabling O&M personnel to promptly deal with them.
Supported Event Types and Handling Suggestions for CKafka
The CKafka Event Center provides monitoring capabilities for three types of events: instance events, diagnostic events, and Broker change events. Its alarm support policy is implemented through the Tencent Cloud Observability Platform (TCOP): some event types support configurable alarm policies, while others only offer observation capability. The specific support scope is listed in the table below:
Instance Events
Event Chinese Name | Event English Name | Event Description | Handling Method and Suggestions |
Automatic disk capacity expansion | Disk auto-extension | High disk occupancy rate triggered automatic scaling | Assess the need to upgrade the disk specification. |
Dynamic message retention policy for disks | Dynamic Message Retention Policy | High disk occupancy rate triggered the dynamic retention policy | Assess the need to upgrade the disk specification. |
Dynamic message retention time change | Dynamic change of message retention time | High disk occupancy rate triggered dynamic message retention time change | Assess the need to upgrade the disk specification. |
Kafka version upgrade | Kafka version upgrade | Upgrading Instance Version | Check whether the Upgrade Version Interface is called via TencentCloud API or console invocation. |
modify AZ | Availability zone changed | Instance changed availability zone | Check whether the available zone change interface is called via TencentCloud API or console invocation. |
Event Chinese Name | Event English Name | Event Description | Handling Method and Suggestions |
automated partition balancing | Auto Partition Rebalance | An instance automatically triggers partition migration to balance loads | Focus on migration process latency and avoid execution during peak business hours. |
manual partition balancing | Manual Partition Rebalance | Manual initiation of partition Leader reassignment | Post-operation verification of traffic balance. |
Kernel minor version upgrade | Minor Version Upgrade | Emergency update to fix security vulnerabilities or functional defects | Check version compatibility and view whether the upgrade is passed via TencentCloud API call. |
Upgrade | Specification Upgrade | Upgrade instance disk/bandwidth/partition configuration specifications | Suggest following up to confirm fee adjustment. |
Downgrade | Specification Downgrade | Reduce instance configuration specifications to lower costs | Recommend following up to monitor the impact on business after downgrade and further assess. |
Public network bandwidth adjustment | Public Bandwidth Adjustment | Modify the public network access bandwidth cap | Check whether the bandwidth change API is called via TencentCloud API. If an error occurs, corresponding troubleshooting is recommended. |
Routing policy change | Routing Policy Modification | Adjust access routing rules within VPC | If an error occurs, verify production/consumer end connectivity. |
ACL policy change | ACL Policy Update | Add or remove Topic or IP access control rules | If an error occurs, suggest checking the client log. |
User addition and deletion | User Management | Create/Delete a SASL authenticated account | It is advisable to perform a synchronous update of the authentication credentials on the production and consumption side. |
enable elastic bandwidth | Bandwidth Elasticity Enabled | Automatically scale bandwidth based on traffic peak | It is advisable to synchronize and follow up on cost changes. |
disable elastic bandwidth | Bandwidth Elasticity Disabled | Disable the automatic bandwidth scaling mechanism | It is recommended to refer to the peak traffic in the most recent 7 days and set the bandwidth upper limit manually. |
Diagnostic Event
Observe Events
Event Chinese Name | Event English Name | Event Description | Handling Method and Suggestions |
Scheduled Instance Diagnosis | Scheduled Instance Diagnosis | The system periodically executes instance health checks, covering network, Disk, and Broker status. | View the diagnostic report when a detection exception occurs and handle it specifically. |
Instant Instance Diagnosis | On-Demand Instance Diagnosis | User manually triggers real-time health check | View the diagnostic report when a detection exception occurs and handle it specifically. |
Broker Change Event
Event Chinese Name | Event English Name | Event Description | Handling Method and Suggestions |
Consumer group members heartbeat timeout | Consumer group member heartbeat timed out | Consumer heartbeat timeout | Suggest checking whether the consumer is normal. Occasional heartbeat timeout might be due to group members fluctuation. If heartbeat timeout occurs frequently, troubleshoot message processing for blockage based on business logic. If any, adjust the downstream blockage. or try adjusting instance configuration |
Consumer group member refresh | Consumer group member update metadata | Consumer group member update | Check for changes in consumer group membership, such as whether there is a publish or join. |
Consumer group rebalance | Consumer group rebalance | Consumer group rebalance occurred | Occasional consumer group rebalance may be due to normal fluctuations. If Rebalance persists or occurs frequently, further investigation is advisable to prevent impact on consumption. Troubleshoot whether there is a heartbeat timeout in the consumer group and address it. Check for frequent creation/termination of consumers. Troubleshoot other consumer group events. |
Cluster node goes live | Cluster node online | Cluster node launch | Check whether a configuration change event occurs in the event center. When a configuration change occurs, cluster nodes going online or offline is normal. At this point, no special attention is needed. Occasional node on/off line may be caused by underlying machine fluctuation. No special attention is needed. If a cluster node launch event occurs, with continuous impact on production or consumption, and prolonged unrecovery, please contact us. |
Cluster node decommission | Cluster node offline | Cluster node decommissioning | Check whether a configuration change event occurs in the event center. When a configuration change occurs, cluster nodes going online or offline is normal. At this point, no special attention is needed. Occasional node on/off line may be caused by underlying machine fluctuation. No special attention is needed. If a cluster node decommission event occurs, with continuous impact on production or consumption, and prolonged unrecovery, please contact us. |
Event Chinese Name | Event English Name | Event Description | Handling Method and Suggestions |
Leader switchover | Leader Election | The partition Leader replica is transferred (may trigger due to reconfiguration, replica balance, DR switch, planned maintenance, or Broker downtime). | Occasional leader switchover is normal, no need for special attention. If leader switching events continue to occur, production consumption remains affected, and prolonged unrecovery persists, try restarting the client. |
Viewing Event Records
1. Log in to the CKafka console.
2. Click Instance Management on the left sidebar and click the ID of the target instance to enter the instance details page.
3. Select the Event Center tab at the top of the page, set the time range (last 6 hours, last 7 days, last 30 days, or a custom time range), select the target event type,and filter out the corresponding event records.
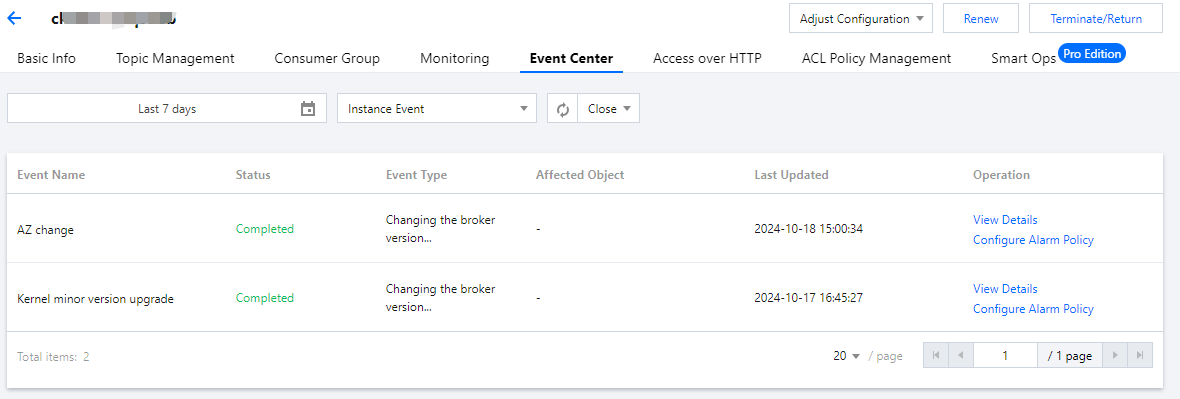
4. On the Event Details page, click View Details in the Operation column of the target event. You can view the event record in detail in the right panel.
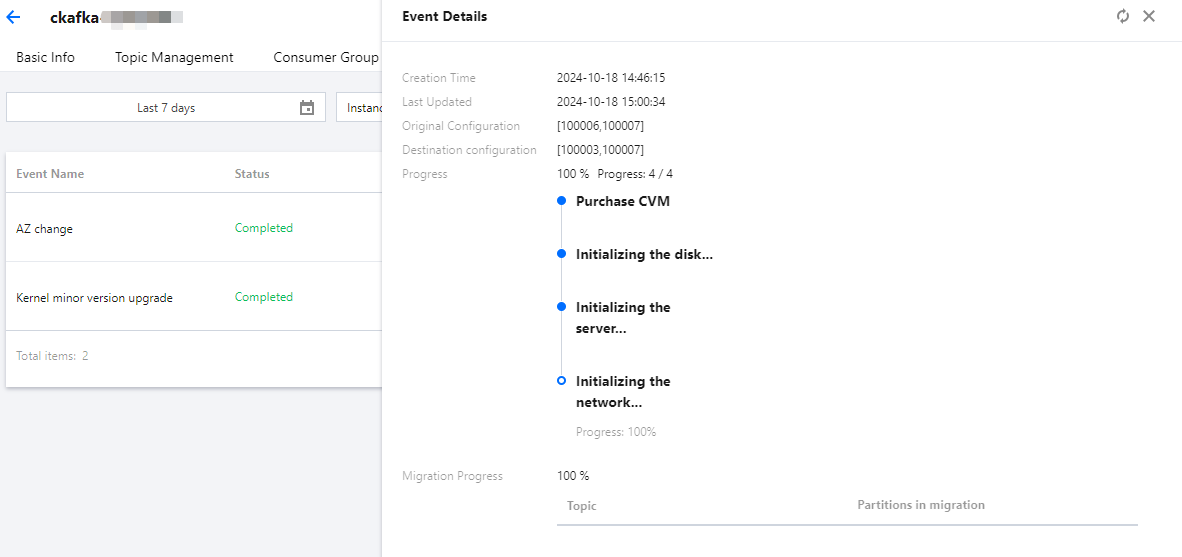
Click Configure Alarm Policy in the Operation column to configure a notification template for the event and send event details to the target object.
Configuring Event Alarm Rules
1. Log in to the TCOP console.
2. Select Alarm Management > Alarm Configuration in the left sidebar, click Create Policy in the top-left corner, then set alarm rules after entering the Policy Name.
Monitoring type: Cloud Monitor
Policy type: Select message service CKafka.
Alarm object: Select the CKafka instance to configure the alarm policy.
Trigger condition: Supports template selection and manual configuration, with manual configuration by default. Select event alarm and add the event to configure alarms.
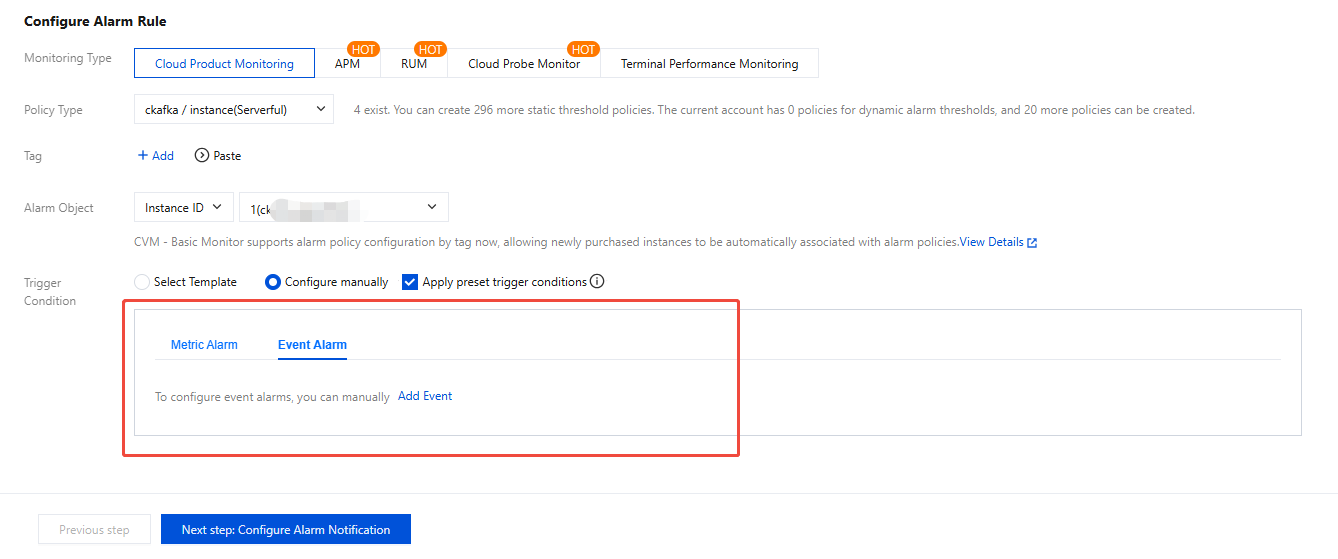
3. Click Next: Configure Alarm Notification, select a notification template, or create a notification template, set alarm recipients and notification channels.
4. Click Complete to finish the alarm rule configuration.
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No
Feedback