TKEでHPAを使用してサービスのAuto Scalingを実装します

最終更新日:2025-09-29 12:33:35
概要
Kubernetes Pod水平自動スケーリング(Horizontal Pod Autoscaler、以下HPAと略称)はCPU使用率、メモリ使用率およびその他のカスタマイズされたメトリック指標に基づいてPodのレプリカ数量を自動スケーリングし、それによってワークロードサービスのメトリック全体のレベルとユーザーが設定した目標値を一致させます。ここではTKEのHPA機能を使用してPodの自動水平スケーリングを実現する方法についてご紹介します。
シナリオ
HPA自動スケーリング機能はTKEに非常に柔軟な適応型機能を持たせ、ユーザーが設定内で複数のPodレプリカを迅速にスケーリングして業務負荷の急激な増加に対応できるようにします。業務負荷が小さくなった状況でも実際の状況に応じて適切にスケーリングすることによってその他のサービスへの計算リソースを節約し、プロセス全体の自動化に人手を介する必要がありません。eコマースサービス、オンライン教育、金融サービスなどのようにサービス変動が大きく、サービス数が多く、かつスケーリングを頻繁に行う必要がある業務シナリオに適しています。
原理の概要
Pod水平自動スケーリング機能は Kubernetes APIリソースおよびコントローラによって実現します。リソースの利用指標によってコントローラの行動を決定し、コントローラは定期的にPodリソースの利用状況に基づいてサービスPodのレプリカ数を調整し、それによってワークロードのメトリックレベルとユーザーが設定した目標値を一致させます。そのスケーリングフローは下図に示すとおりです。
注意
Pod自動水平スケーリングはDaemonSetリソースのようにスケーリングできないオブジェクトには適用されません。
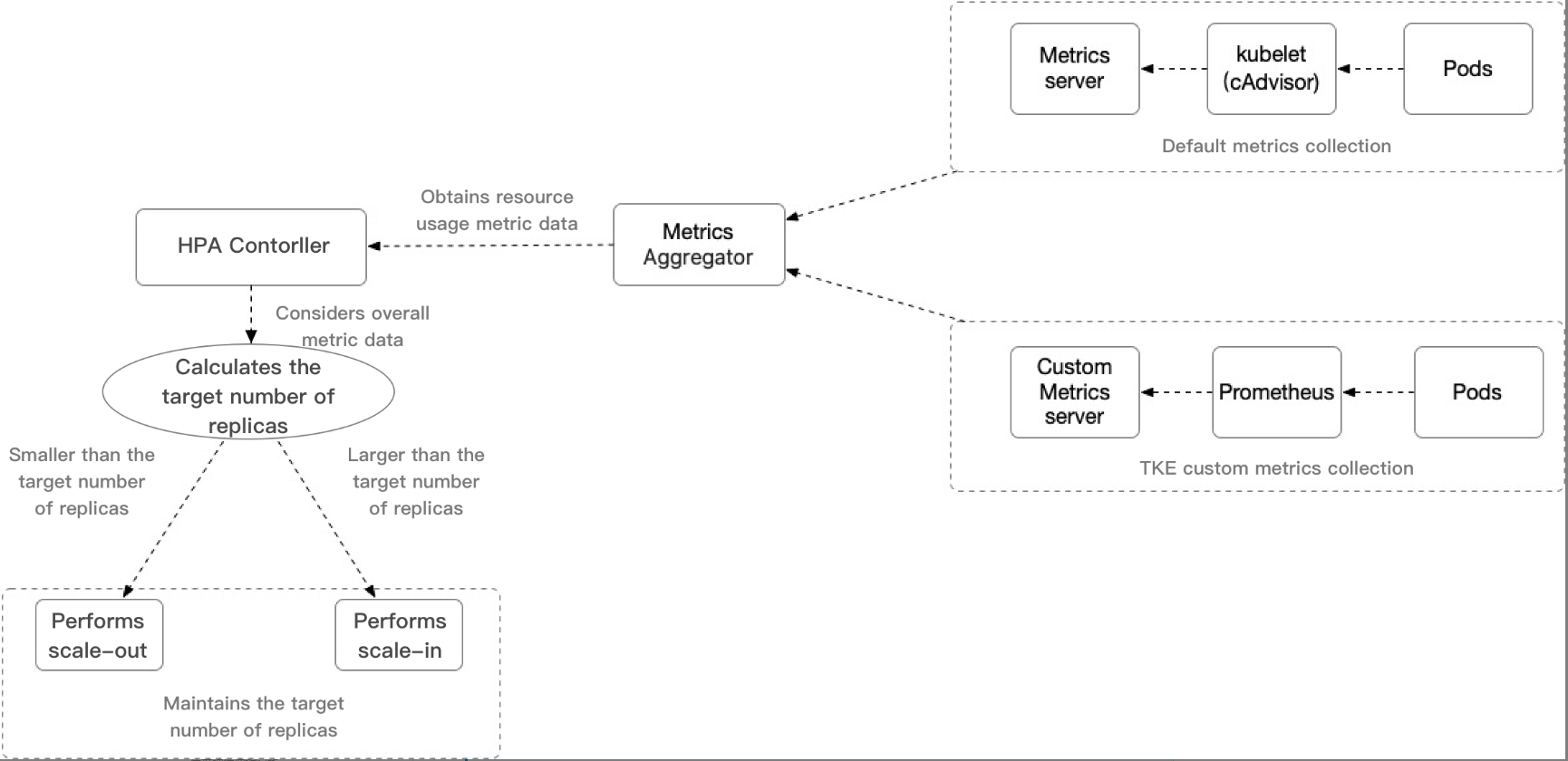
重要な内容の説明:
HPA Controller:HPA スケーリングロジックの制御コンポーネントを制御します。
Metrics Aggeregator:メトリック指標アグリゲーター。通常の状態で、コントローラは一連の集約API(
metrics.k8s.io、custom.metrics.k8s.ioおよびexternal.metrics.k8s.io)からメトリック値を取得します。metrics.k8s.ioAPIは通常Metricsサーバーによって提供され、コミュニティ版は基本的なCPU、メモリのメトリックタイプを提供することができます。コミュニティ版に比べ、TKEはカスタムMetrics Serverを使用して、より幅広いHPAをサポートすることができるメトリック指標トリガータイプを収集し、CPU、メモリ、ハードディスク、ネットワークおよびGPUを含む関連指標を提供することができます。より詳細な内容については、 TKE自動スケーリング指標の説明をご参照ください。説明
コントローラもHeapsterから指標を取得することができますが、Kubernetesバージョン1.11からは、Heapsterから指標特性を取得する方式は破棄されました。
前提条件
Tencent Cloudアカウントの登録済みであること。
Tencent CloudTKEコンソールにログインしていること。
TKEクラスターを作成済みであること。クラスターの作成に関して、詳細については、クラスターの作成をご参照ください。
操作手順
デプロイテストのワークロード
Deploymentリソースタイプのワークロードを例にとり、単一レプリカ数で、サービスタイプがWebサービスの「hpa-test」というワークロードを作成します。TKEコンソールでDeploymentタイプのワークロードを作成する方法はDeployment管理をご参照ください。本事例の作成結果は下図に示すとおりです(このドキュメントのスクリーンキャプチャ情報はコンソールの実際のインターフェースより遅れている可能性があるため、コンソールの実際の表示に準じます)。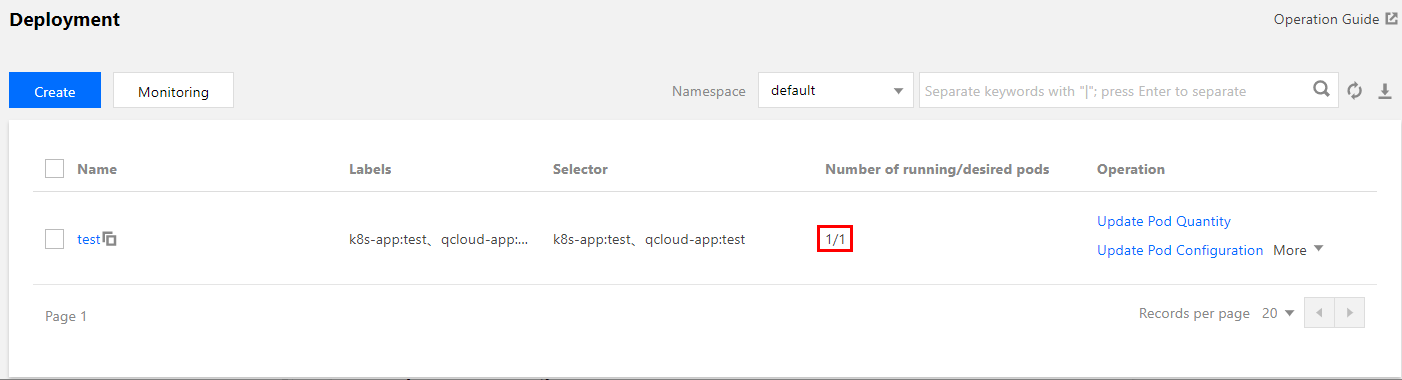
HPAの設定
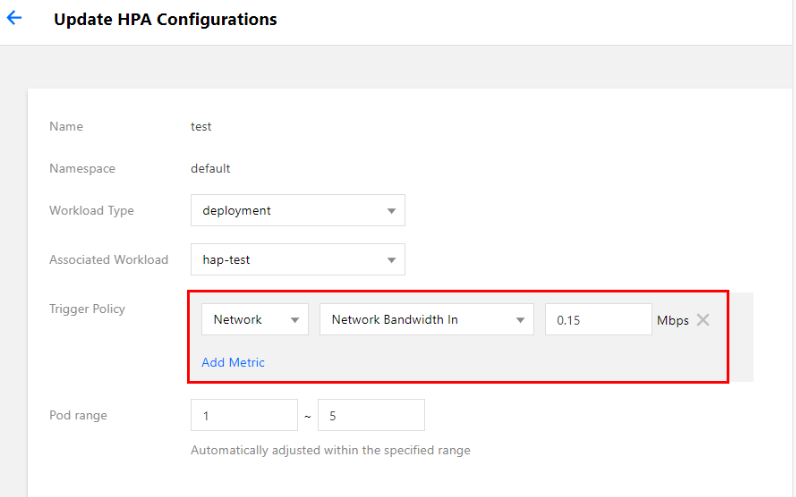
TKEコンソールでテストワークロードにHPA設定をバインドします。バインドの方法およびHPAの設定については、HPA操作ステップをご参照ください。このドキュメントではネットワークのアウトバンド帯域幅が0.15Mbps(150Kbps)に達した時にスケールアウトをトリガーするポリシーの設定を例にとります。下図に示すとおりです。
機能の検証
スケールアウトプロセスのシミュレーション
以下のコマンドを実行して、クラスター内で一時的にPodを起動して設定されたHPA機能にテストを行います(クライアントのシミュレーション)。
kubectl run -it --image alpine hpa-test --restart=Never --rm /bin/sh
一時的にPod内で以下のコマンドを実行して、短時間内に大量のリクエストで「hpa-test」というサービスにアクセスすることによってアウトバウンドトラフィックの帯域幅の増加をシミュレートします。
# hpa-test.default.svc.cluster.localはサービスのクラスター内でのドメイン名です。スクリプトを停止する必要がある場合はCtrl+Cを押しますwhile true; do wget -q -O - hpa-test.default.svc.cluster.local; done
テストPod内でシミュレーションリクエストコマンドを実行した後、ワークロードのPod数を観察することによって監視したところ、16:21にワークロードはレプリカ数が2個にスケールアウトされていることがわかり、これによってHPAのスケールアウトイベントがトリガーされたことが推測できます。下図のように表示されます(このドキュメントのスクリーンキャプチャ情報はコンソール実際のインターフェースより遅れている可能性があるため、コンソールの実際の表示に準じます)。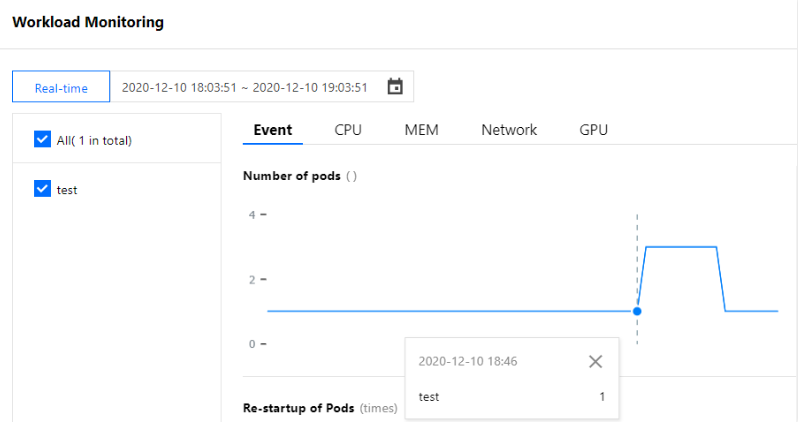
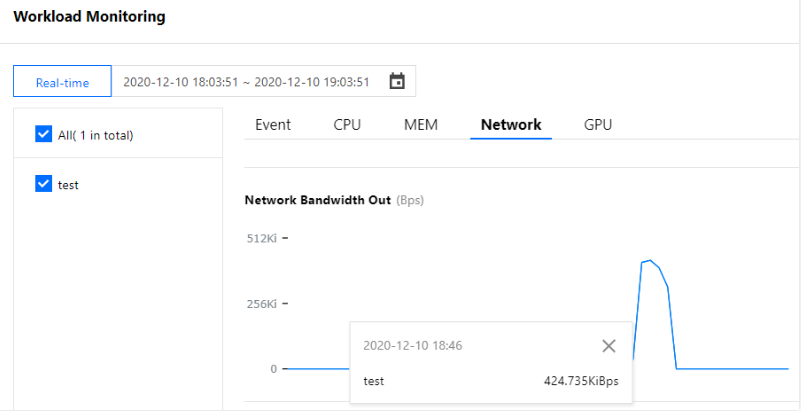
さらにワークロードのネットワーク送信帯域幅の監視によって16:21にネットワーク送信帯域幅がおよそ196Kbpsに増加していることが観察でき、HPAによって設定されたネットワーク送信帯域幅目標値を超え、さらにこのときHPAスケーリングアルゴリズムがトリガーされたことを証明でき、1つのレプリカ数をスケールアウトすることによって設定された目標値を満たすため、ワークロードのレプリカ数は2個になります。下図のように表示されます(このドキュメントのスクリーンキャプチャ情報はコンソール実際のインターフェースより遅れている可能性があるため、コンソールの実際の表示に準じます)。
注意
HPAスケーリングアルゴリズムは公式でディメンションを計算してスケーリングロジックを制御するだけでなく、複数のディメンションでスケールアウトまたはスケーリングが必要かどうかを判断するため、実際の状況において予想からわずかにずれる可能性があります。詳細については、アルゴリズム詳細をご参照ください。
スケーリングプロセスのシミュレーション
スケーリングプロセスのシミュレーション時、16:24前後に手動でシミュレーションリクエストを実行するコマンドを停止し、監視からこのときまでのネットワーク送信帯域幅値がスケールアウト前の位置に下降していることが観察できます。HPAのロジックによると、このときワークロードスケーリングの条件を満たしています。下図のように表示されます(このドキュメントのスクリーンキャプチャ情報はコンソール実際のインターフェースより遅れている可能性があるため、コンソールの実際の表示に準じます)。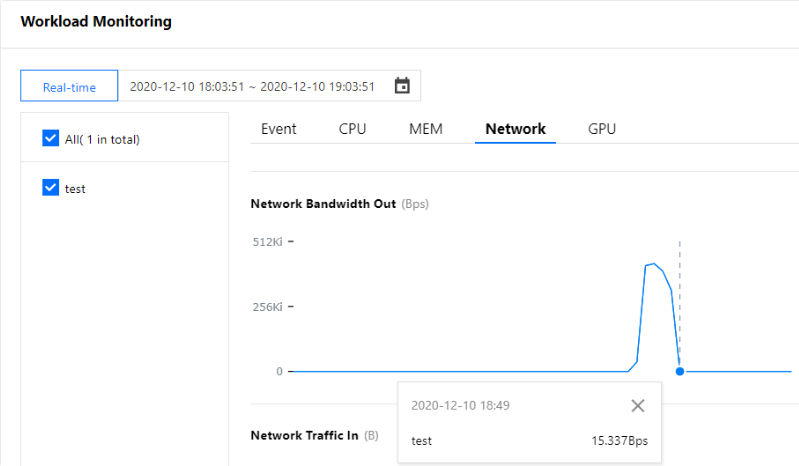
しかし下図のワークロードのPod数の監視からわかるように、ワークロードは16:30にHPAのスケーリングをトリガーします。原因はHPAスケーリングをトリガーした後デフォルトで5分間容認する時間アルゴリズムです。それによってメトリック指標が短時間で変動することによって引き起こされる頻繁なスケーリングを防止します。詳細については、クールダウン/遅延のサポートをご参照ください。下図からワークロードレプリカ数は停止コマンドの5分後にHPA スケーリングアルゴリズムによって最初に設定したレプリカ数にスケーリングされることがわかります。下図のように表示されます(このドキュメントのスクリーンキャプチャ情報はコンソール実際のインターフェースより遅れている可能性があるため、コンソールの実際の表示に準じます)。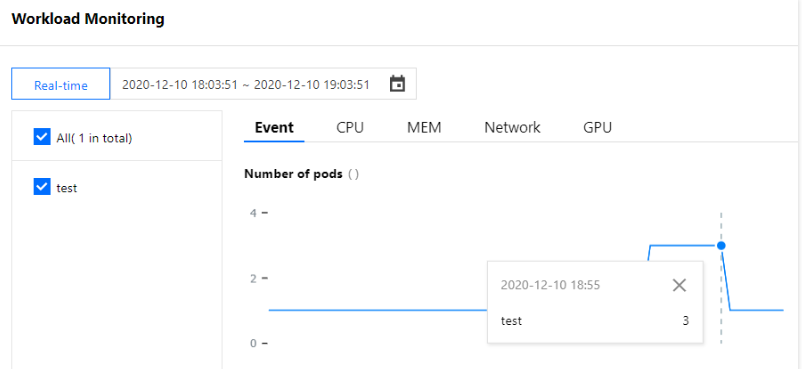
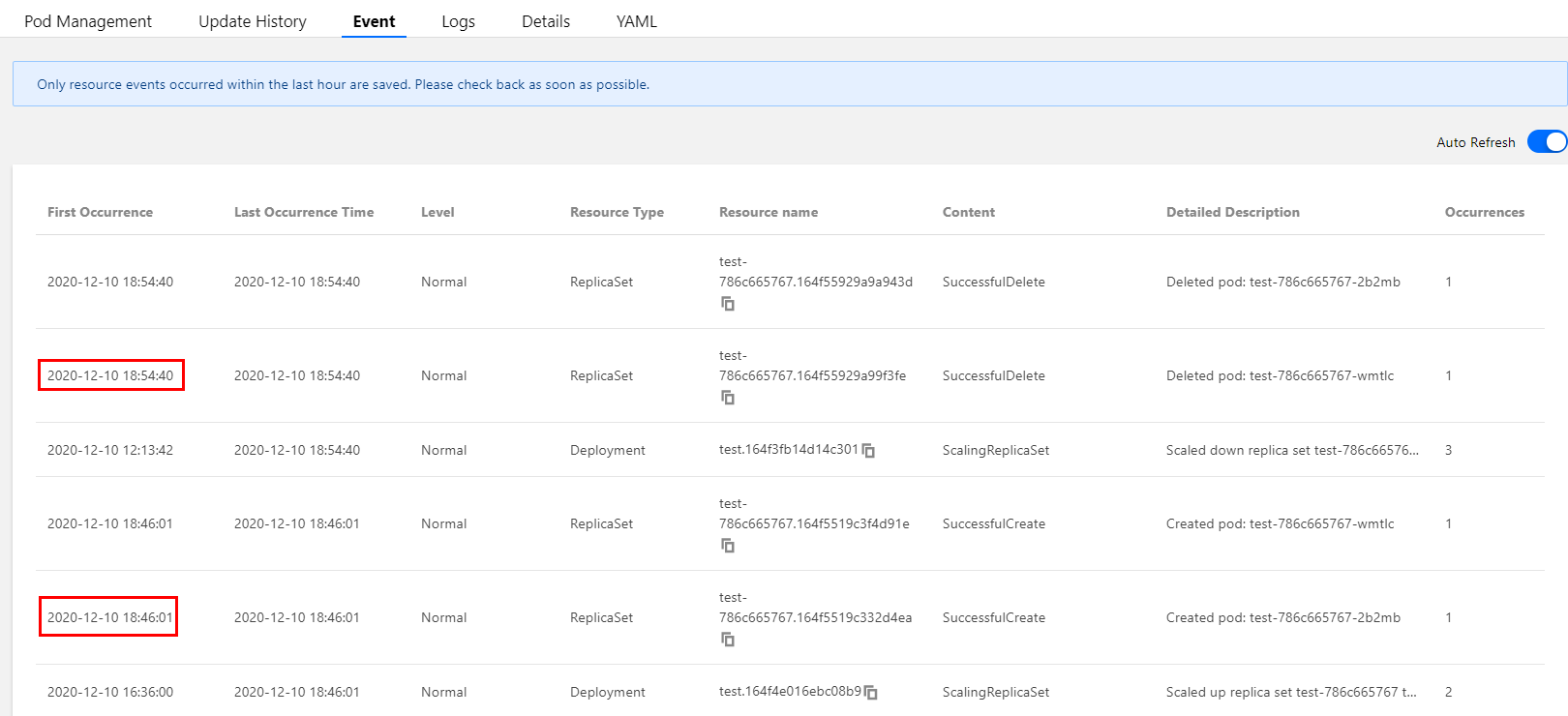
TKEにHPAスケーリングイベントが発生した時、対応するHPAインスタンスのイベントリストに表示されます。イベント通知リストの時間はそれぞれ「初回の発生時間」および「最後の発生時間」であることにご注意ください。「初回の発生時間」は同じイベントが初めて発生した時間を表し、「最後の発生時間」は同じイベントが発生した最新の時間を表すため、下図のイベントリストの「最後の発生時間」フィールドからこの事例のスケールアウトイベント時点は16:21:03であることがわかります。スケーリングイベント時間は16.29:42で、時点とワークロードの監視で確認した時点と一致します。下図に示すとおりです。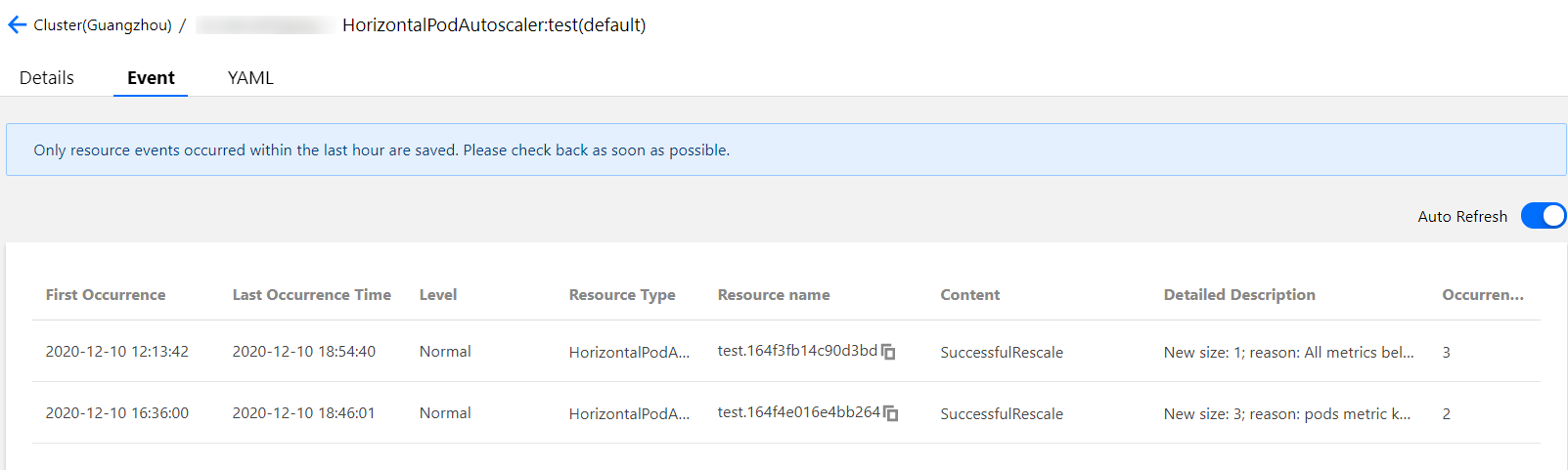
また、ワークロードイベントリストもHPA発生時のワークロードのレプリカ数追加イベントを記録します。下図からワークロードスケーリング時点とHPAイベントリストの時点も一致し、レプリカ数が増加した時点が16:21:03、レプリカ数が減少した時点が16:29:42であることがわかります。
まとめ
この例では主にTKEのHPA機能をデモンストレーションし、TKEを使用してカスタマイズされたネットワーク送信帯域幅メトリックタイプをワークロードHPAのスケーリングメトリック指標とします。
ワークロードの実際のメトリック値がHPAによって設定されたメトリック目標値を超えた場合、HPAはスケールアウトアルゴリズムに基づいて適切なレプリカ数を計算して水平スケールアウトを実現し、ワークロードのメトリック指標が予測を満たすことおよびワークロードの健全で安定した動作を保証します。
実際のメトリック値がHPAによって設定されたメトリック目標値より大幅に低い場合、HPAは許容時間後に最適なレプリカ数を計算して水平スケーリングを実現し、アイドル状態のリソースを適切に解放し、リソース使用率を向上させるという目的を達成し、かつプロセス全体はHPAおよびワークロードのイベントリストにいずれも対応するイベント記録があり、それによってワークロードの水平スケーリングのプロセス全体を追跡可能にします。
フィードバック