Automatic Speech Recognition
Tencent Cloud Automatic Speech Recognition (ASR) provides highly cost-effective speech recognition services. It has been widely used by many Tencent businesses such as WeChat, Honor of Kings, and Tencent Video and has implemented multiple use cases, including recording quality inspection, real-time meeting transcription, and voice input method.

BENEFITS
Why choose Automatic Speech Recognition

Low Prices
Tencent Cloud ASR offers a competitive pricing system.
Low Prices
Tencent Cloud ASR offers a competitive pricing system.

More Languages Supported
ASR currently supports speech recognition in Mandarin and English, with more languages to come in the future.
More Languages Supported
ASR currently supports speech recognition in Mandarin and English, with more languages to come in the future.
Good Effect
ASR uses the same set of services adopted by the speech-to-text conversion features in WeChat and Honor of Kings, which deliver an industry-leading word recognition accuracy rate of 97%.
Good Effect
ASR uses the same set of services adopted by the speech-to-text conversion features in WeChat and Honor of Kings, which deliver an industry-leading word recognition accuracy rate of 97%.

Powerful Algorithms
Based on the innovative network structure TLC-BLSTM, ASR leverages the attention mechanism to effectively model speech signals and improves the system robustness through the teacher-student approach, delivering an industry-leading recognition accuracy and efficiency in diverse scenarios in general and vertical fields.
Powerful Algorithms
Based on the innovative network structure TLC-BLSTM, ASR leverages the attention mechanism to effectively model speech signals and improves the system robustness through the teacher-student approach, delivering an industry-leading recognition accuracy and efficiency in diverse scenarios in general and vertical fields.

Self-Service Accuracy Improvement
ASR allows you to upload a list of words or sentences in vertical fields to automatically optimize the language models. With the aid of the self adaptive learning platform, you can easily customize models to further increase the recognition accuracy even if you don't know anything about algorithms.
Self-Service Accuracy Improvement
ASR allows you to upload a list of words or sentences in vertical fields to automatically optimize the language models. With the aid of the self adaptive learning platform, you can easily customize models to further increase the recognition accuracy even if you don't know anything about algorithms.

Wide Scenario Support
ASR has been fully verified by Tencent's internal high-traffic products such as WeChat, Tencent Video, and Honor of Kings and well optimized for diversified scenarios in the internet, finance, and education sectors based on massive amounts of data, with best practices accumulated and output for many industries.
Wide Scenario Support
ASR has been fully verified by Tencent's internal high-traffic products such as WeChat, Tencent Video, and Honor of Kings and well optimized for diversified scenarios in the internet, finance, and education sectors based on massive amounts of data, with best practices accumulated and output for many industries.
SCENARIO
How it works in various businesses scenarios
Call quality inspection at call centers is traditionally conducted through random spot checks due to labor efficiency and costs, making it difficult to assess the performance of customer service reps. ASR can recognize call recordings, convert them to text, and then analyze the text in real time to identify non-compliant calls. This greatly enhances the performance management of call centers, completes large-scale call recording quality inspection that cannot be accomplished by human, and eventually improves the service quality of call center staff.

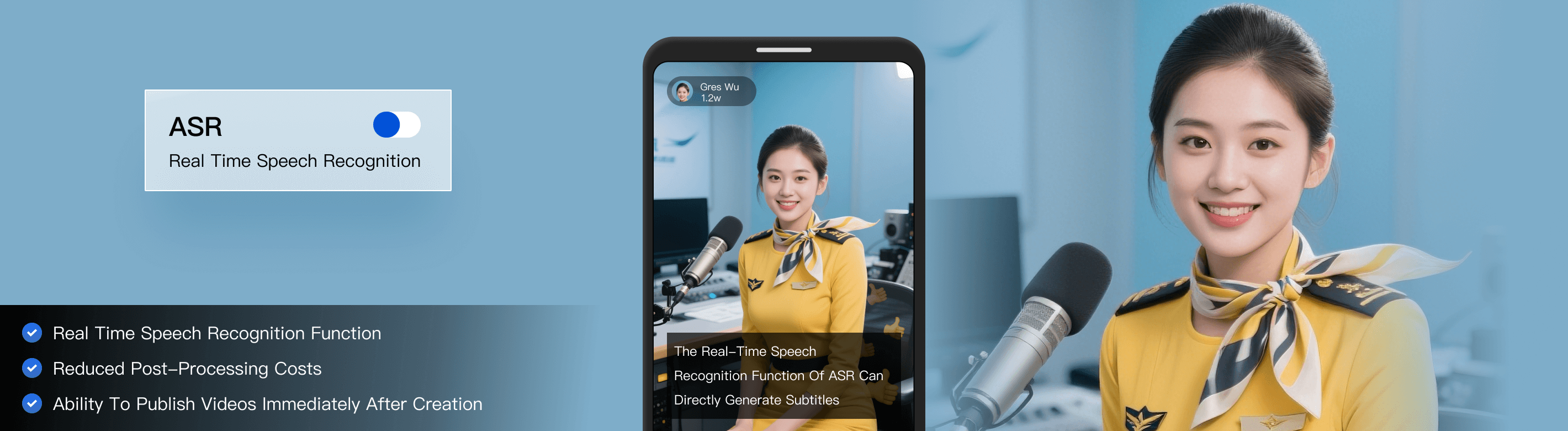
In UGSV scenarios, users talk while shooting videos and generally need to edit the videos and manually add subtitles before posting them. The real-time speech recognition feature of ASR can directly generate subtitles when users are talking, which significantly reduces the post-processing costs and enables users to post videos immediately after creating them.
Live streaming and audio sharing platforms have high numbers of audios/videos that need to be understood for quality inspection, tagging, and recommendation purposes, which is difficult to be achieved by human. The real-time speech recognition feature of ASR can transcribe audios and audio streams in videos based on the audio/video transcription model. It well satisfies the different latency requirements of different input sources and helps platform staff quickly understand high numbers of audios/videos, which remarkably reduces the labor costs and quickly implement quality inspection, tagging, and recommendation.
