- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 准备工作
- 数据迁移
- 数据同步
- 数据订阅(Kafka 版)
- 前置校验不通过处理方法
- 割接说明
- 监控与告警
- 运维管理
- DTS-DBbridge 私有化部署
- 实践教程
- 常见问题
- 错误处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- (NewDTS) Data Migration APIs
- DescribeMigrationJobs
- DescribeMigrationDetail
- CreateMigrationService
- ModifyMigrationJob
- CreateMigrateCheckJob
- DescribeMigrationCheckJob
- SkipCheckItem
- StartMigrateJob
- StopMigrateJob
- ResumeMigrateJob
- RecoverMigrateJob
- ModifyMigrateName
- ModifyMigrateJobSpec
- IsolateMigrateJob
- DestroyMigrateJob
- DescribeMigrateDBInstances
- CompleteMigrateJob
- PauseMigrateJob
- ContinueMigrateJob
- Data Sync APIs
- ModifySyncJobConfig
- CreateModifyCheckSyncJob
- DescribeModifyCheckSyncJobResult
- StartModifySyncJob
- DescribeSyncJobs
- CreateSyncJob
- ConfigureSyncJob
- CreateCheckSyncJob
- SkipSyncCheckItem
- DescribeCheckSyncJobResult
- StartSyncJob
- StopSyncJob
- ResumeSyncJob
- ResizeSyncJob
- RecoverSyncJob
- IsolateSyncJob
- DestroySyncJob
- PauseSyncJob
- ContinueSyncJob
- Data Consistency Check APIs
- Data Types
- Error Codes
- DTS API 2018-03-30
- SDK 文档
- 相关协议
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 准备工作
- 数据迁移
- 数据同步
- 数据订阅(Kafka 版)
- 前置校验不通过处理方法
- 割接说明
- 监控与告警
- 运维管理
- DTS-DBbridge 私有化部署
- 实践教程
- 常见问题
- 错误处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- (NewDTS) Data Migration APIs
- DescribeMigrationJobs
- DescribeMigrationDetail
- CreateMigrationService
- ModifyMigrationJob
- CreateMigrateCheckJob
- DescribeMigrationCheckJob
- SkipCheckItem
- StartMigrateJob
- StopMigrateJob
- ResumeMigrateJob
- RecoverMigrateJob
- ModifyMigrateName
- ModifyMigrateJobSpec
- IsolateMigrateJob
- DestroyMigrateJob
- DescribeMigrateDBInstances
- CompleteMigrateJob
- PauseMigrateJob
- ContinueMigrateJob
- Data Sync APIs
- ModifySyncJobConfig
- CreateModifyCheckSyncJob
- DescribeModifyCheckSyncJobResult
- StartModifySyncJob
- DescribeSyncJobs
- CreateSyncJob
- ConfigureSyncJob
- CreateCheckSyncJob
- SkipSyncCheckItem
- DescribeCheckSyncJobResult
- StartSyncJob
- StopSyncJob
- ResumeSyncJob
- ResizeSyncJob
- RecoverSyncJob
- IsolateSyncJob
- DestroySyncJob
- PauseSyncJob
- ContinueSyncJob
- Data Consistency Check APIs
- Data Types
- Error Codes
- DTS API 2018-03-30
- SDK 文档
- 相关协议
操作场景
本文为您提供使用 DTS 将本地 IDC 自建数据库业务同步到腾讯云上的操作指导。
在业务搬迁的场景中,本地数据库同步到云上后,要做割接,为防止业务割接后云上的数据库出现异常,推荐使用 DTS 数据同步模块配置反向逃生链路,这样在云上数据库同步异常时,可以将业务回切到本地数据库上。
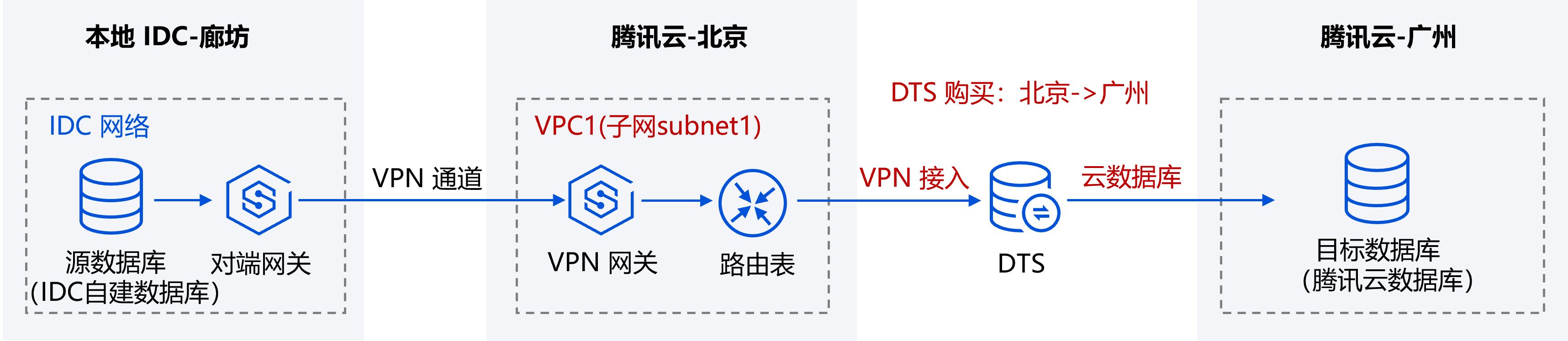
准备工作
1. 网路打通准备
使用 DTS 进行数据库的同步,需要分别将源/目标数据库与腾讯云私有网络打通,以便 DTS 可以连通源/目标数据库。
本示例中,源数据库为 IDC 自建数据库,DTS 可以通过公网/VPN 接入/专线接入/云联网方式进行接入,我们以“VPN 接入”方式为例。目标数据库为腾讯云数据库实例。
1. 将本地 IDC 就近接入腾讯云 VPC。
2. 后续 DTS 购买任务时,源实例地域需要选择源库接入的腾讯云 VPC 所属地域,即 VPC1 所属地域北京。目标实例地域需要选择目标数据库所属地域,即广州。
3. 后续 DTS 任务配置时,源库设置中,接入类型选择“VPN 接入”,私有网络和子网,选择 VPC1,并选择其中的一个子网 subnet1;目标库设置中,接入类型选择“云数据库”。
2. 账号和权限准备
创建执行 DTS 任务的账号并授权。如下以 MySQL 为例进行介绍。
源数据库授权如下:
#创建执行任务账号CREATE USER '账号'@'%' IDENTIFIED BY '密码';#授予权限GRANT RELOAD,LOCK TABLES,REPLICATION CLIENT,REPLICATION SLAVE,SHOW VIEW,PROCESS,SELECT ON *.* TO '账号'@'%' IDENTIFIED BY '密码';GRANT ALL PRIVILEGES ON `__tencentdb__`.* TO '账号'@'%';FLUSH PRIVILEGES;
目标数据库授权如下:
#创建执行任务账号CREATE USER '账号'@'%' IDENTIFIED BY '密码';#授予权限GRANT ALTER, ALTER ROUTINE, CREATE,CREATE ROUTINE, CREATE TEMPORARY TABLES, CREATE USER, CREATE VIEW, DELETE, DROP, EVENT, EXECUTE, INDEX, INSERT, LOCK TABLES, PROCESS, REFERENCES, RELOAD, SELECT, SHOW DATABASES, SHOW VIEW, TRIGGER, UPDATE ON *.* TO '账号'@'%' IDENTIFIED BY '密码';FLUSH PRIVILEGES;
注意事项
正向同步、反向同步,是两个独立的单向同步任务,每个独立任务的约束、操作限制等要求都需要满足同步任务基本要求,请参考 “数据同步”章节下的对应同步链路。
DBbridge 在执行全量数据同步时,会占用一定源数据库资源,可能会导致源数据库负载上升,增加数据库自身压力。如果您数据库配置过低,建议您在业务低峰期进行。
操作步骤概要
使用 DTS 进行数据库搬迁的场景中,为防止割接后目标库出现数据异常,推荐使用数据同步配置反向逃生链路,这样在目标库发生异常时,可以将业务回切到源库上。
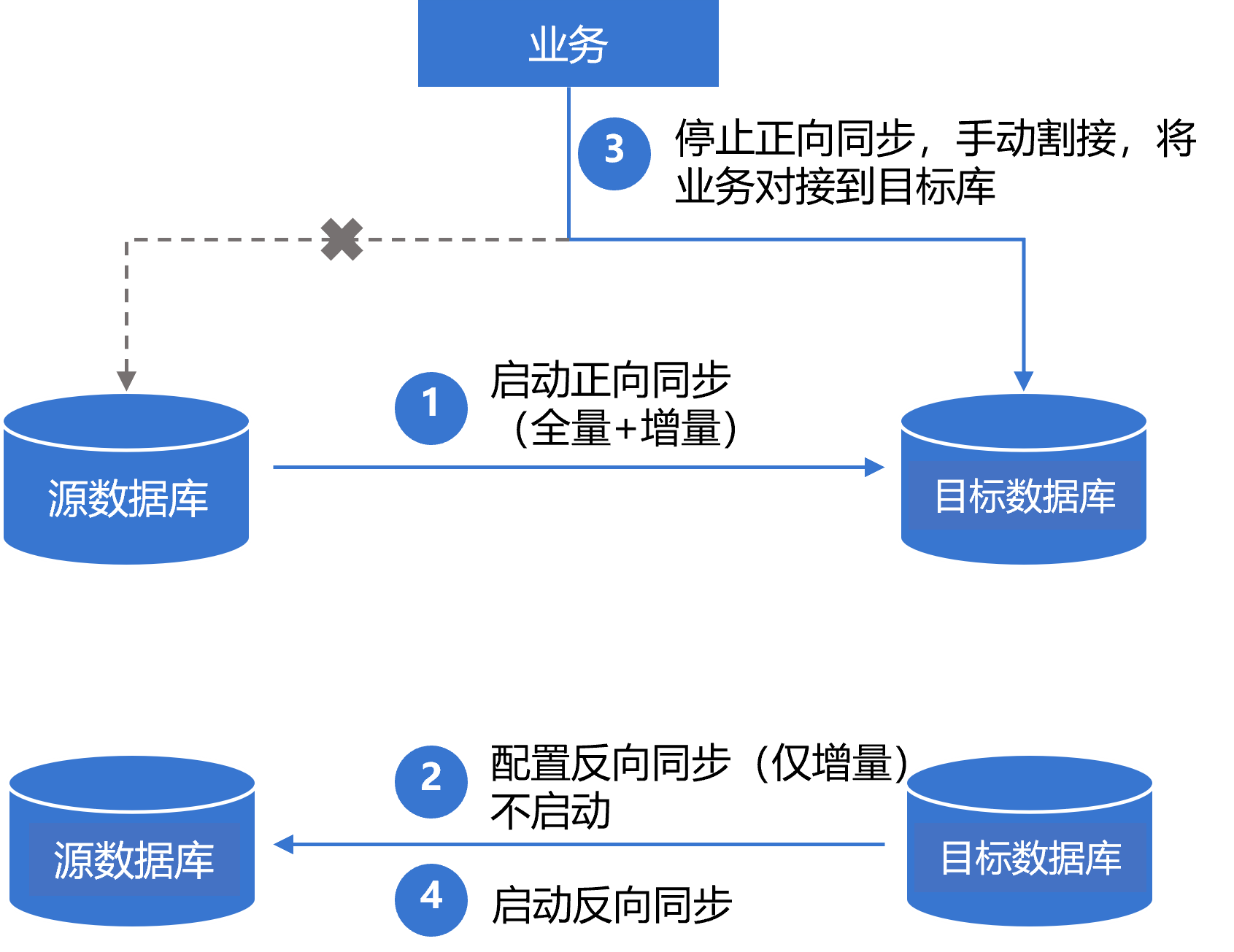
1. 配置并启动正向同步任务,选择全量 + 增量同步。
正向任务中的关键配置:初始化类型选择“结构初始化 + 全量数据初始化”,已存在同名表选择“前置校验并报错”。
2. 配置好反向任务,仅增量同步。配置完后先不启动。
反向任务中的关键配置:初始化类型都不勾选,已存在同名表选择“忽略并继续执行”。
3. 正向数据同步完成,停止正向任务,手动进行割接,将业务对接到目标库。
4. 启动反向同步任务,将目标库的增量数据同步到源库。
5. (可选)如果割接后目标库数据异常,停止反向同步,将业务切回到源库上。
详细操作详情
说明:
步骤一:购买 DTS
登录 数据同步购买页,选择相应配置,单击立即购买。
1. 正向任务。
源实例地域选择源库接入的腾讯云 VPC 所属地域,即 VPC1 所属地域北京。目标实例地域选择目标数据库所属地域,即广州。
2. 反向任务。
源实例、目标实例的数据库类型和地域选择相反。
步骤二:创建并启动正向同步
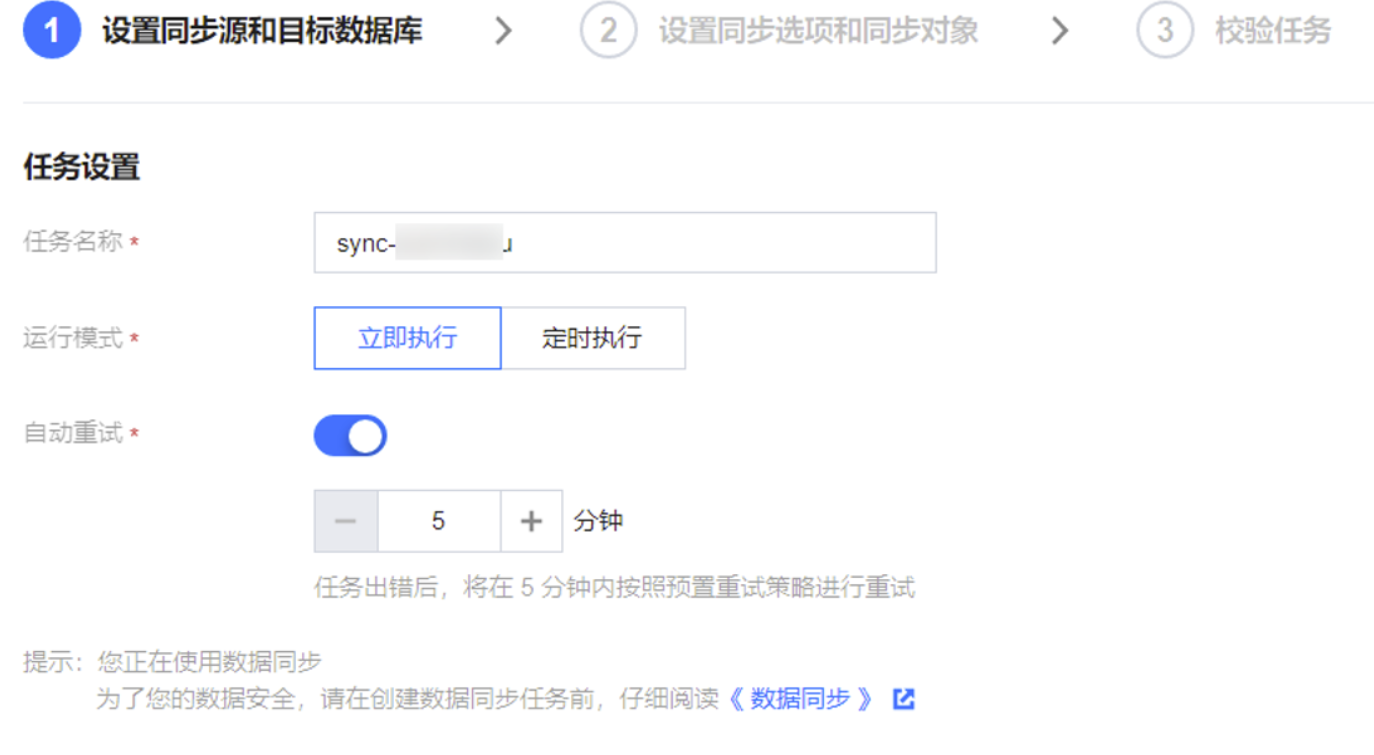
1. 购买完成后,返回 数据同步列表,可看到刚创建的数据同步任务,单击操作列的配置,进入配置同步任务页面。

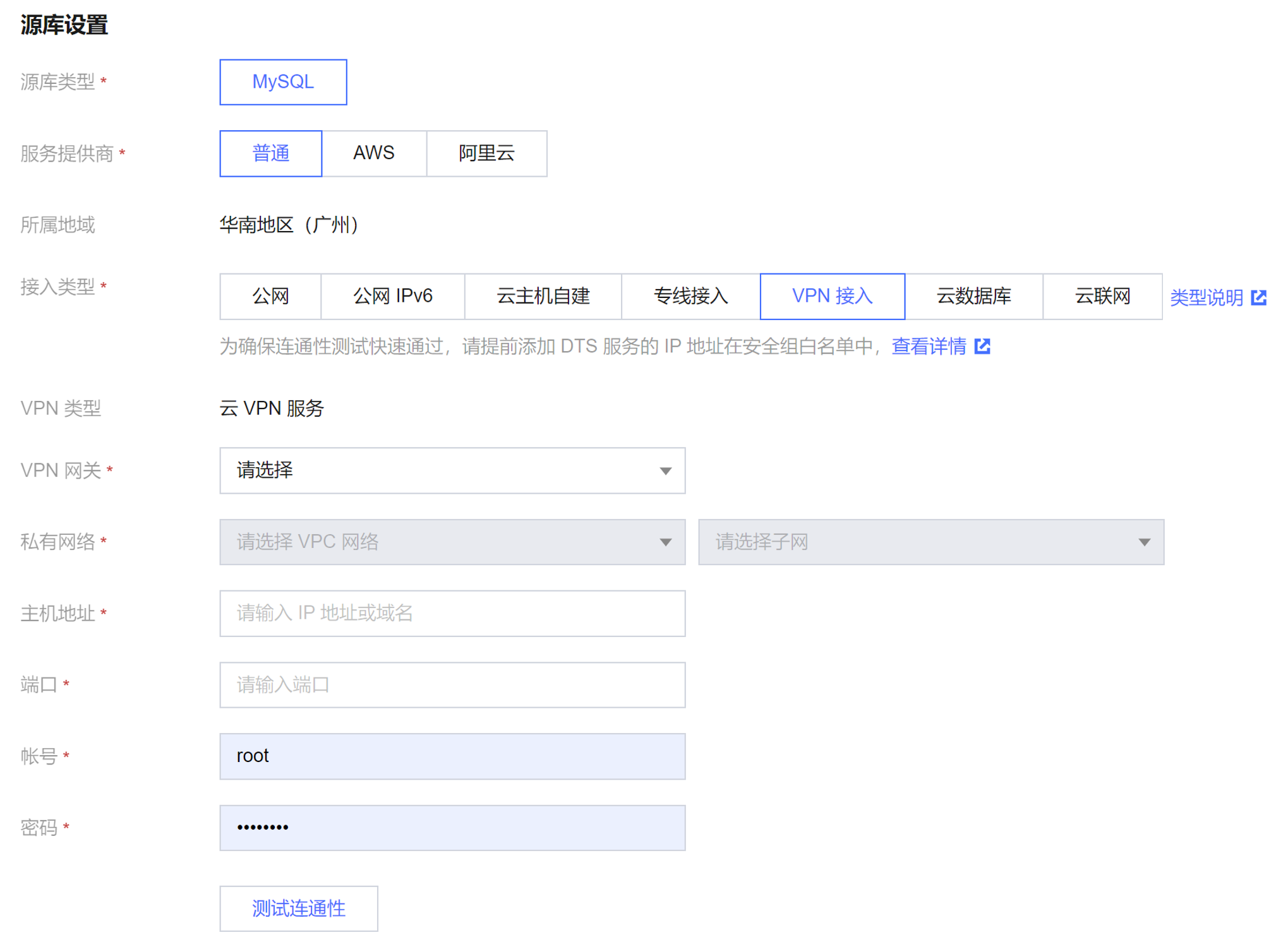
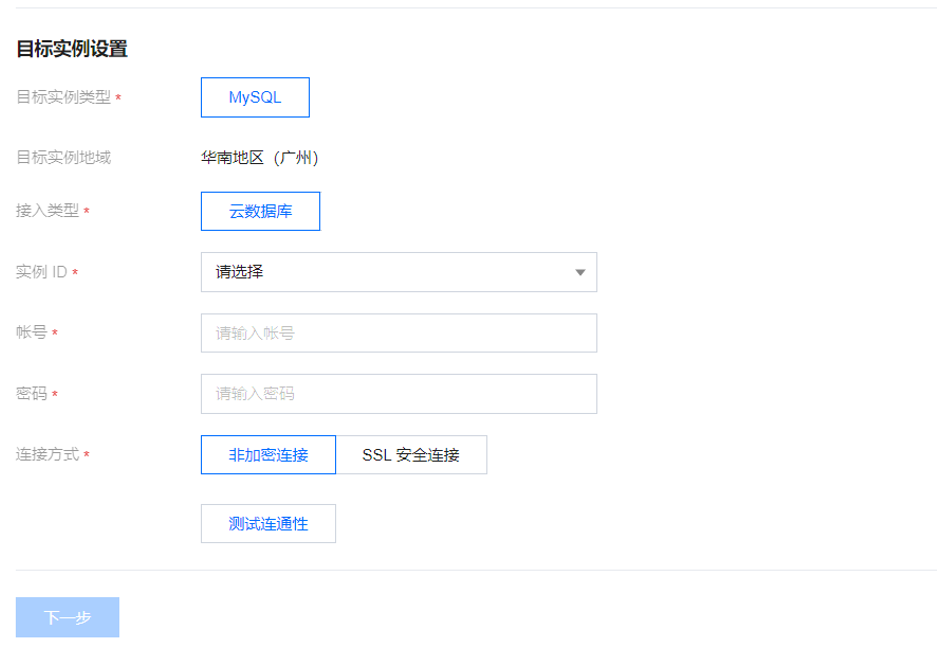
2. 在配置同步任务页面,配置源端实例、账号密码,配置目标端实例、账号和密码,测试连通性后,单击下一步。
设置项 | 参数 | 描述 |
任务设置 | 任务名称 | DTS 会自动生成一个任务名称,用户可以根据实际情况进行设置。 |
| 运行模式 | 支持立即执行和定时执行两种模式。 |
源实例设置 | 源实例类型 | 购买时所选择的源实例类型,不可修改。 |
| 源实例地域 | 购买时选择的源实例所在地域,不可修改。 |
| 服务提供商 | 自建数据库(包括云服务器上的自建)或者腾讯云数据库,请选择“普通”;第三方云厂商数据库,请选择对应的服务商。
本场景选择“普通”。 |
| 接入类型 | 公网:源数据库可以通过公网 IP 访问。 云主机自建:源数据库部署在 腾讯云服务器 CVM 上。 专线接入:源数据库可以通过 专线接入 方式与腾讯云私有网络打通。 VPN接入:源数据库可以通过 VPN 连接 方式与腾讯云私有网络打通。 云数据库:源数据库属于腾讯云数据库实例。 云联网:源数据库可以通过 云联网 与腾讯云私有网络打通。 |
| 私有网络专线网关/VPN 网关 | 专线接入时只支持私有网络专线网关,请确认网关关联网络类型。
VPN 网关,请选择通过 VPN 网关接入的 VPN 网关实例。 |
| 私有网络 | 选择私有网络专线网关和 VPN 网关关联的私有网络和子网。 |
| 主机地址 | 源实例 MySQL 访问 IP 地址或域名。 |
| 端口 | 源实例 MySQL 访问端口。 |
| 账号 | 源实例账号,账号权限需要满足要求。 |
| 密码 | 源实例账号的密码。 |
目标实例设置 | 目标实例类型 | 购买时选择的目标实例类型,不可修改。 |
| 目标实例地域 | 购买时选择的目标实例地域,不可修改。 |
| 接入类型 | 根据您的场景选择,本场景选择“云数据库”。 |
| 实例 ID | 选择目标实例 ID。 |
| 账号 | 目标实例账号,账号权限需要满足要求。 |
| 密码 | 目标实例账号的密码。 |
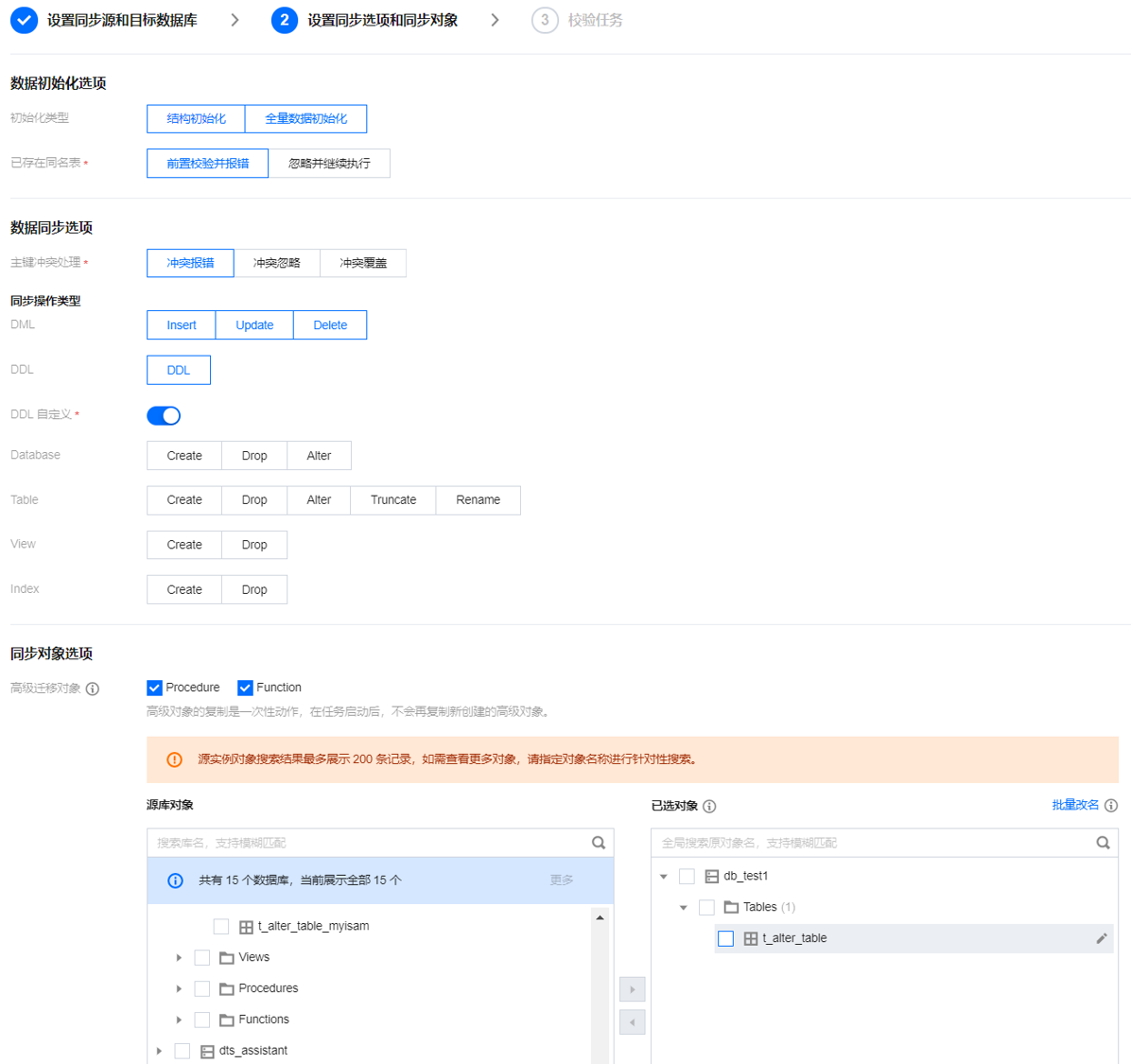
3. 在设置同步选项和同步对象页面,将对数据初始化选项、数据同步选项、同步对象选项进行设置,在设置完成后单击保存并下一步。
说明:
当初始化类型仅选择全量数据初始化,系统默认用户在目标库已经创建了表结构,不会进行表结构同步,也不会校验源库和目标库是否有同名表,所以当用户同时在已存在同名表项选择前置校验并报错,则校验并报错功能不生效。
如果用户在同步过程中确定会对某张表使用 rename 操作(例如将 table A rename 为 table B),则同步对象需要选择 table A 所在的整个库(或者整个实例),不能仅选择 table A,否则系统会报错。
设置项 | 参数 | 描述 |
数据初始化选项 | 初始化类型 | 结构初始化:同步任务执行时会先将源实例中表结构初始化到目标实例中。 全量数据初始化:同步任务执行时会先将源实例中数据初始化到目标实例中。默认两者都勾上,可根据实际情况取消。 |
| 已存在同名表 | 前置校验并报错:存在同名表则报错,流程不再继续。 忽略并继续执行:全量数据和增量数据直接追加目标实例的表中。 |
数据同步选项 | 冲突处理机制 | 冲突报错:在同步时发现表主键冲突,报错并暂停数据同步任务。 冲突忽略:在同步时发现表主键冲突,保留目标库主键记录。 冲突覆盖:在同步时发现表主键冲突,用源库主键记录覆盖目标库主键记录。 |
| 同步操作类型 | |
同步对象选项 | 源实例库表对象 | 选择待同步的对象,支持基础库表、视图、存储过程和函数。高级对象的同步是一次性动作,仅支持同步在任务启动前源库中已有的高级对象,在任务启动后,新增的高级对象不会同步到目标库中。更多详情,请参考 同步高级对象。 |
| 已选对象 | 支持库表映射(库表重命名),将鼠标悬浮在库名、表名上即显示编辑按钮,单击后可在弹窗中填写新的名称。 选择高级对象进行同步时,建议不要进行库表重命名操作,否则可能会导致高级对象同步失败。 支持同步 Online DDL 临时表(使用 gh-ost、 pt-online-schema-change 工具),单击表的编辑按钮,在弹窗中即可选择临时表名。更多详情请参考 同步 Online DDL 临时表。 |
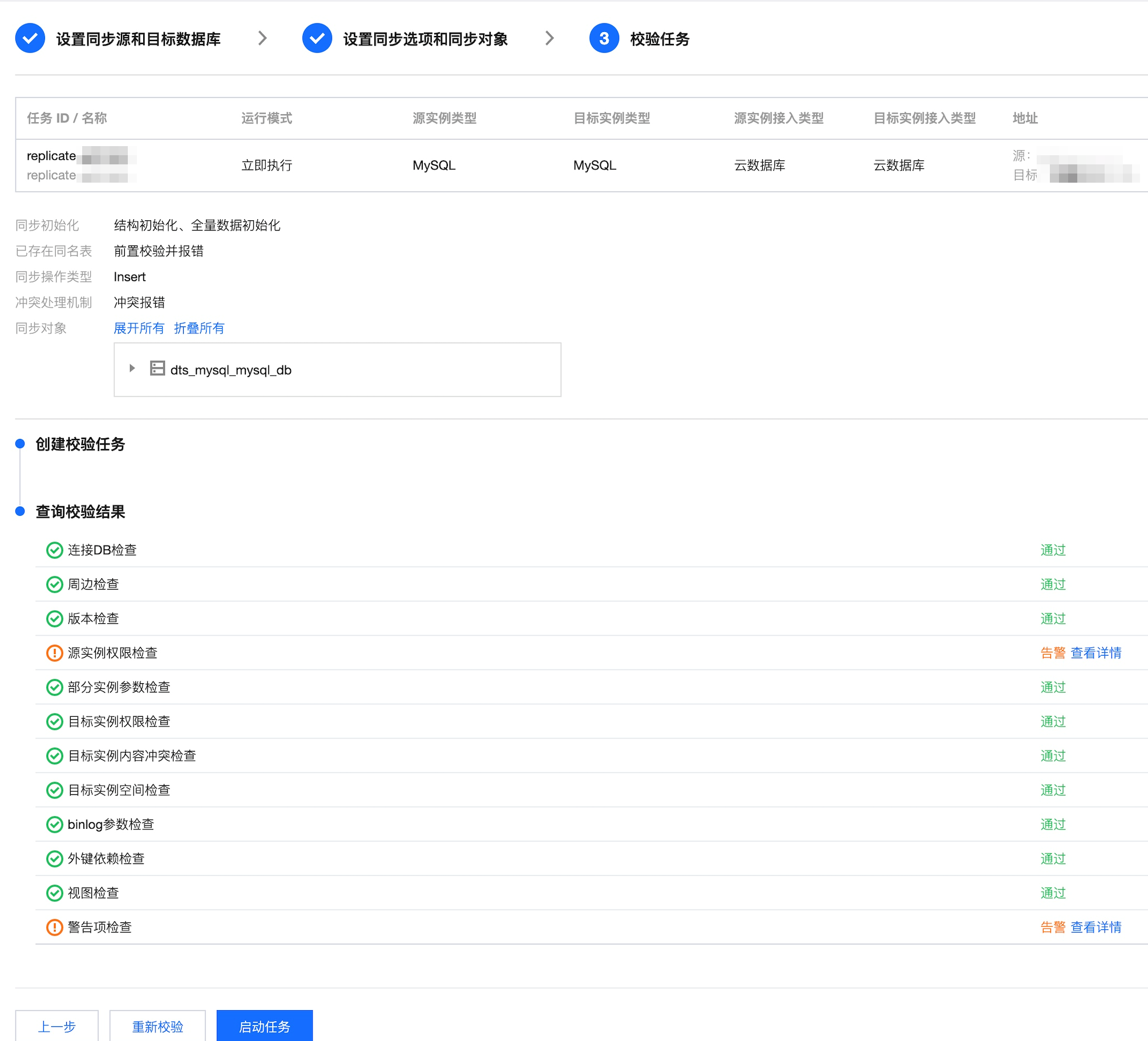
4. 在校验任务页面,完成校验并全部校验项通过后,单击启动任务。
如果校验任务不通过,可以参考 校验不通过处理方法 修复问题后重新发起校验任务。
失败:表示校验项检查未通过,任务阻断,需要修复问题后重新执行校验任务。
警告:表示检验项检查不完全符合要求,可以继续任务,但对业务有一定的影响,用户需要根据提示自行评估是忽略警告项还是修复问题再继续。
5. 返回数据同步任务列表,任务开始进入运行中状态。
说明:
选择操作列的更多 > 结束可关闭同步任务,请您确保数据同步完成后再关闭任务。
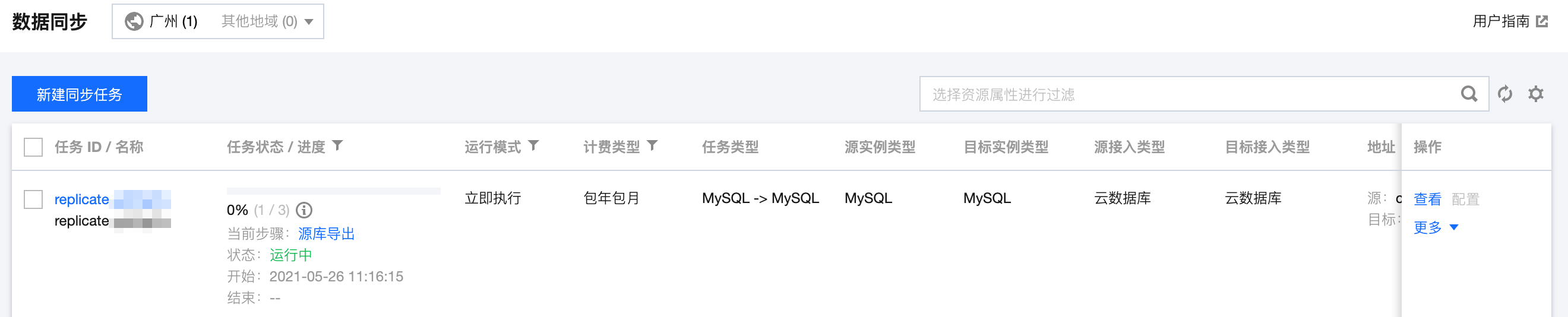
6. (可选)您可以单击任务名,进入任务详情页,查看任务初始化状态和监控数据。
步骤三:配置反向同步
反向同步和正向同步操作基本一致,以下仅对差异点进行说明。
1. 设置同步源和目标数据库。
本步骤中的源和目标数据库与正向任务中的数据库进行互换。
2. 设置同步选项和同步对象。
初始化类型:都不勾选。
已存在同名表:选择“忽略并继续执行”。
主键冲突处理机制:根据业务情况自行选择。
同步操作类型:与正向任务保持一致。
3. 在校验任务页面,进行校验,校验通过后启动任务。
步骤四:业务割接
待正向同步任务中,数据差距和时延差距都为0,即可启动割接。

1. 数据验证无误后进行业务割接。这里的数据验证,可使用 创建数据一致性校验(MySQL 系)进行辅助校验。
2. 结束正向同步任务。
3. 手动将源库业务对接到目标库。
步骤五:启动反向同步
启动反向任务。
步骤六(可选):反向割接
如果发现目标库数据异常,停止反向同步,将业务切回到源库上。

 是
是
 否
否
本页内容是否解决了您的问题?