
无缝融合腾讯云数据生态,可以直接读取云存储服务数据。同时具备良好的跨平台兼容性,支持各类上层数据应用。

简介
特性

按使用量付费

多源联合查询

支持标准 SQL

资源极致弹性

云端无缝融合

安全可靠
应用场景
敏捷实时数据湖分析
敏捷搭建数据中台
敏捷数据湖联邦分析
丰富多元数据湖科学
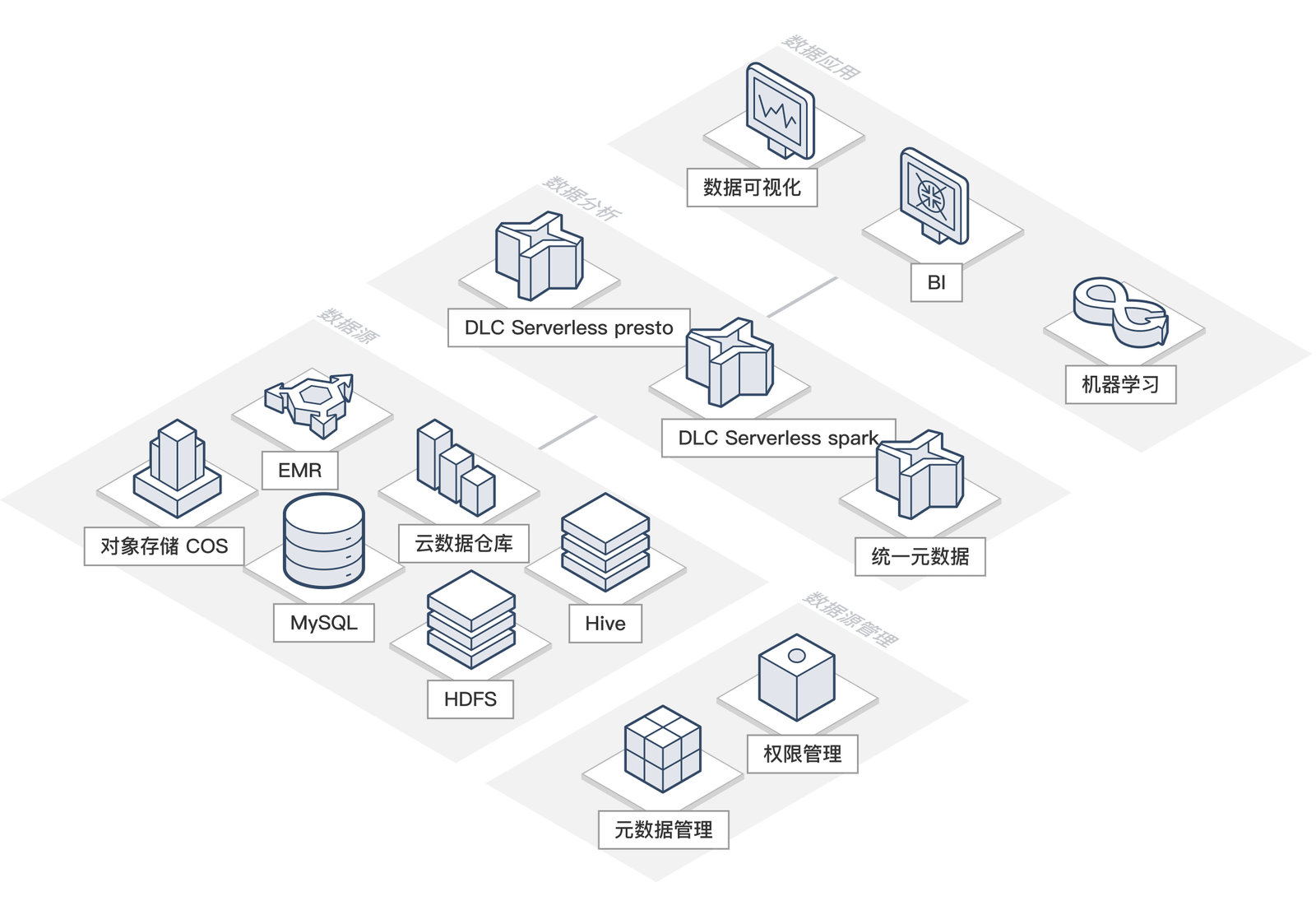
数据湖计算采用存算分离的海量大数据分析架构,基于大数据组件容器化实现快速灵活部署,基于云原生对象存储的方式实现无限拓展,结合数据湖计算先进的云原生弹性模型,充分贴合业务真实使用曲线,真正为您节省成本。数据湖计算以低成本、高弹性的云原生数据湖解决方案,助力企业建立统一数据资产,最大化发挥性能优势,赋能业务应用敏捷创新。
典型场景
企业日志批量查询
企业日志数据通常以json、文本文件等格式进行存储,用户可以将日志数据存储到COS中,直接使用标准SQL快捷地对COS中的海量数据进行批量分析,并将查询结果快速生成数据报表,轻松实现数据可视化,大幅提升工作效率。同时产品只需要几步简单的配置,既可以将云上日志服务的数据导入到数据湖中,快速上手加速分析。
服务价值
- 成本优化:存算分离云原生数据湖架构,按使用量付费,精准控制成本投入
- 强大易用:统一SQL语法,上手使用简单,更快的查询速度
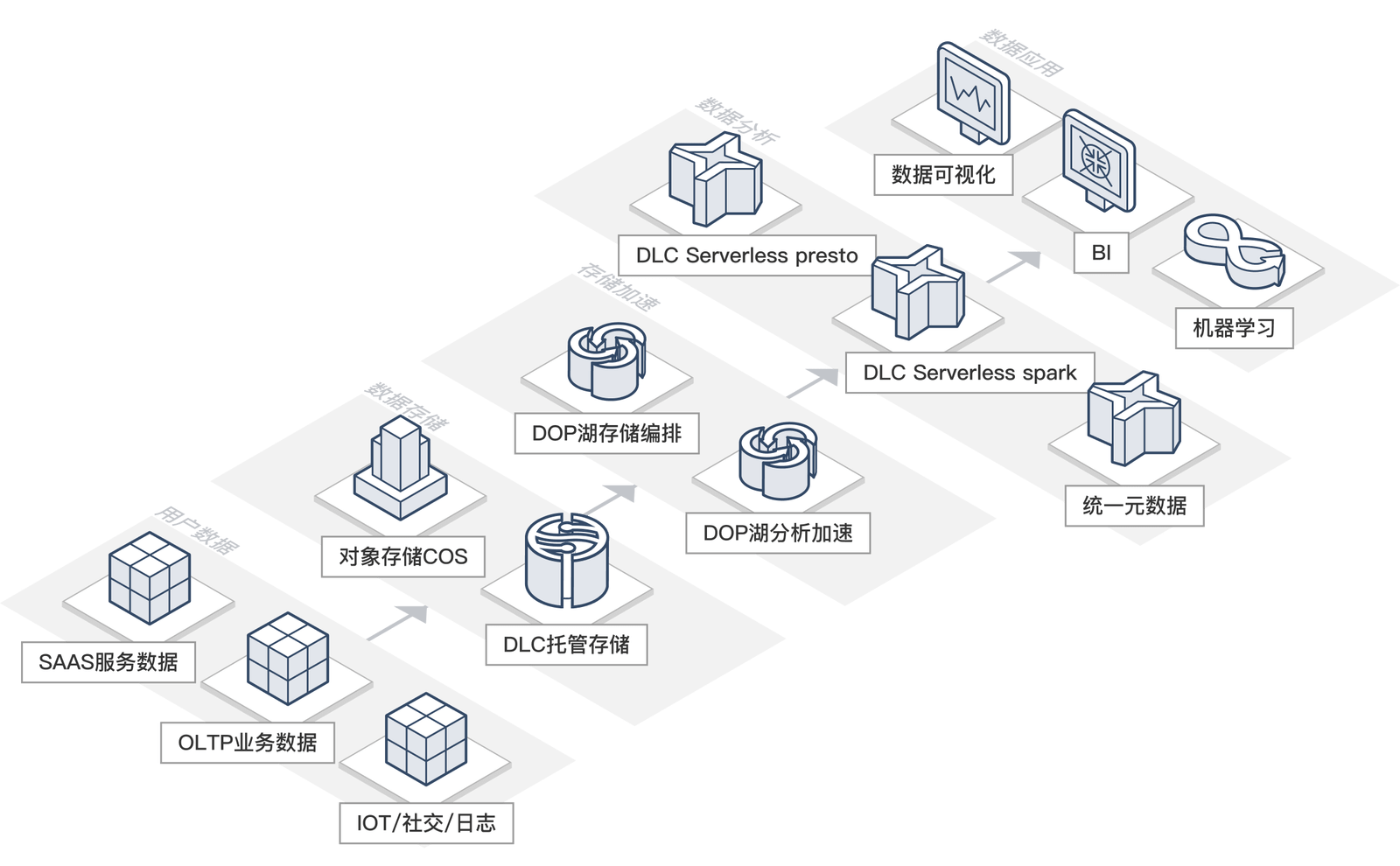
数据湖计算本身作为新型数据架构,本身提供轻量敏捷易用和低成本的闭环大数据分析能力,用户可以借助数据湖提供的统一元数据管理视图,消除数据孤岛。同时也可以组合云上丰富大数据产品的优势,满足各类数据实时、离线分析场景,全方面解决企业各类问题。通过数据的便捷快速流动,可以有机组合不同云上产品的能力和优势,使得数据湖计算得以作为企业最佳数据中台和数据启动场所。
典型场景
- 统一元数据视图
用户在云上可能存在多套元数据视图,数据湖计算内置企业级统一元数据视图,可以集中管理和使用不同数据源的元数据,敏捷快速地构建企业元数据中心,无缝在不同产品和版本之间切换。典型代表同一份元数据,可以在不同产品之间便捷切换使用。
- 一份数据敏捷泛场景分析
在大数据生态中,Presto擅长交互式分析,Spark擅长ETL任务,通过数据湖计算提供的统一语法和轻量化集群能力,可以做到同一份数据无缝在不同引擎间切换,满足各类场景。也可以通过结合Wedata将数据导入导出到其它数十种数据产品和数据源,如云数据库、日志服务等,通过数据的便捷流动,充分发挥不同产品的优势。
服务价值
- 开箱即用:无需多余运维,节省运维成本
- 元数据管理:支持多种数据源,统一元数据管理,打破数据孤岛
- 场景全覆盖:数据分析、应用场景覆盖全面,数据集成、协同、调度、开发、治理全覆盖
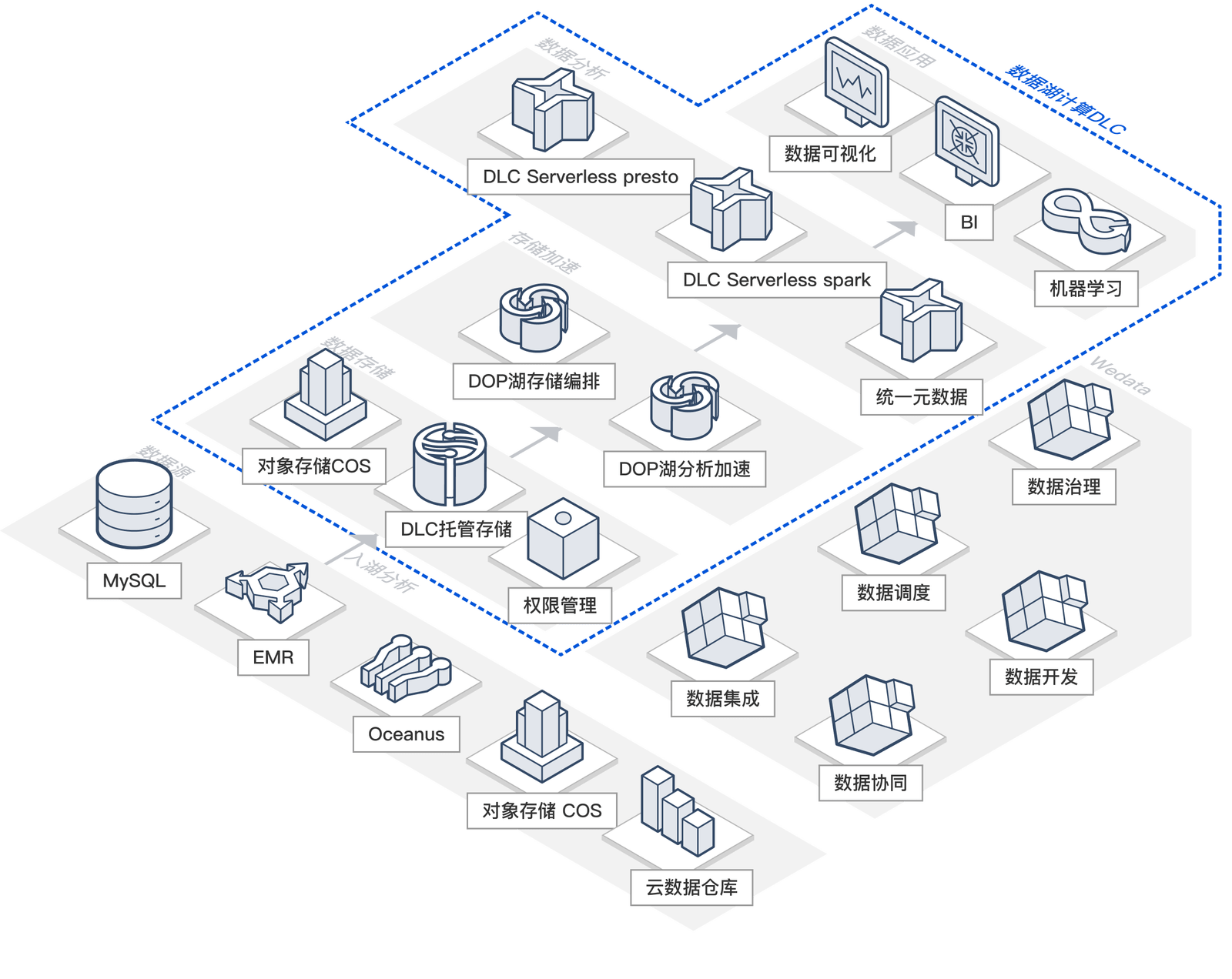
数据湖计算帮助客户实现由数据库场景无缝升级到大数据场景,支持对多源异构数据进行联合查询分析,包括对象存储、云数据库、其他数据服务等。用户通过统一的数据视图,使用标准的 SQL 即可快速实现多源数据联邦分析,打通数据孤岛,发挥数据价值。
典型场景
跨业务数据联合查询
企业内部不同部门和业务线通常基于业务体系采用不同的数据架构,业务数据存放在不同的存储系统中,存在数据割裂的情况:如交易型数据存储到关系型数据库、活跃数据存储到Redis、历史记录存储到对象存储。数据湖计算帮助用户实现异构数据打通,用户可以跨多个数据源进行联合分析,助力用户跨业务数据分析更加迅捷。
服务价值
- 开箱即用:无需构建数据传输管道,无需多余运维,节省运维成本
- 安全高效:统一权限管理体系,数据权限精确到列,极致查询速度
- 迅捷使用:无需适配编程语言,轻松实现跨业务分析
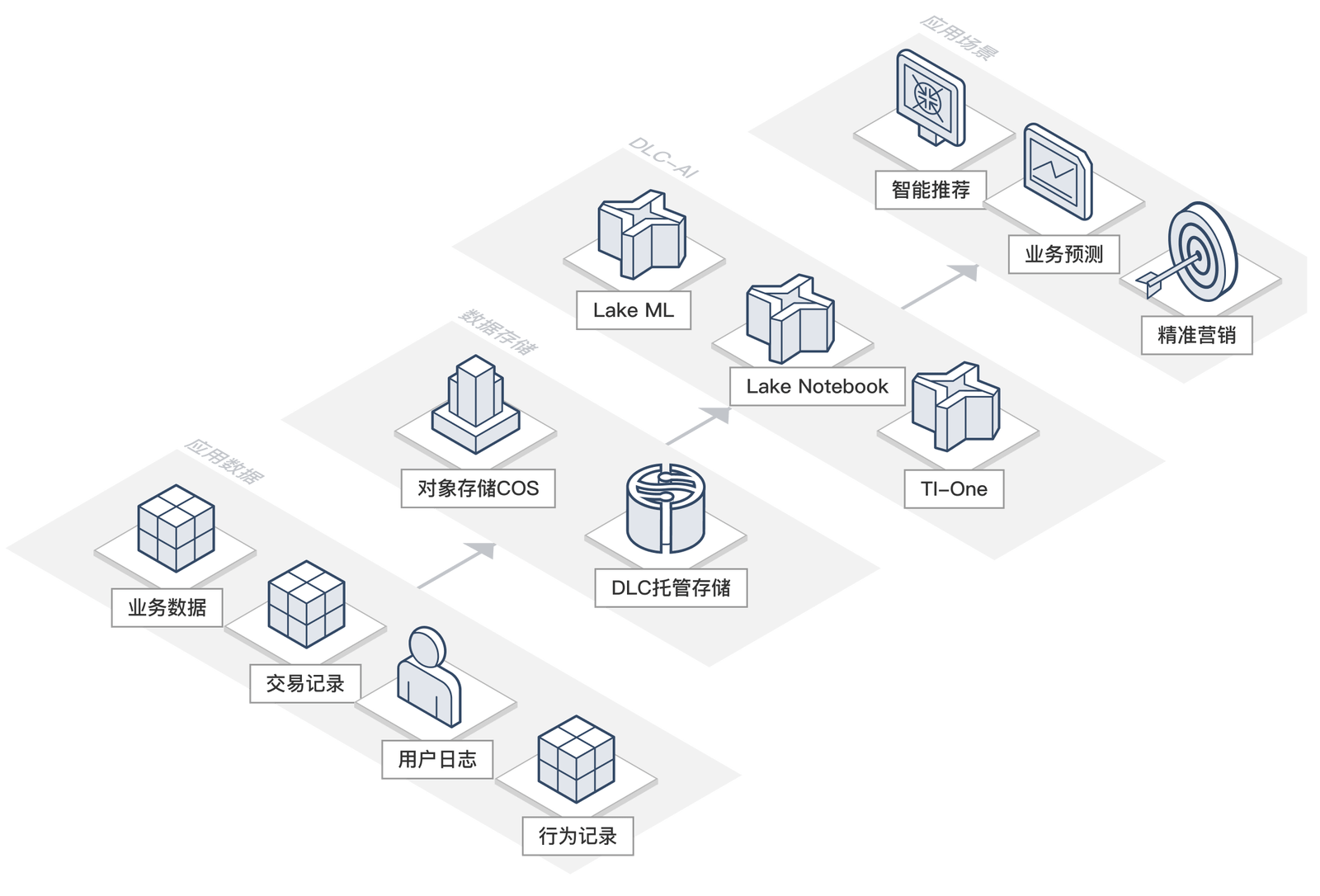
数据湖是AI场景的大数据基座,在经典机器学习场景和深度学习场景下服务用户,数据湖计算提供结合各种AI能力及平台,快速支持各种机器学习能力,在多种智能数据湖分析场景下,提供综合性解决方案。数据湖计算将多个行业数据免费开放给用户,无需数据获取、清洗即可直接进入数据分析阶段。产品提供强大的BI能力助力用户通过预测分析快速实现数据洞察。
典型场景
数据科学赋能业务增长
数据湖计算提供原生机器学习能力,融合成熟的机器学习平台,为用户提供完善的智慧分析解决方案,解决用户实际的业务问题,如智能推荐、召回策略等,助力企业实现业务增长。 在机器学习场景下,用户面临数据量大,模型训练慢,算法效果差的问题。数据湖计算提供的机器学习算法模型开箱即用,用户可以快速基于数据构建机器学习模型,轻松预测业务成果。数据湖计算为用户提供BI能力,助力企业实现高效商业智能分析,提供企业运营效率。
服务价值
- 易用性强:无缝对接腾讯云机器学习平台,提供多种模型及API方便使用
- 数据规范:对数据进行统一管理、治理,为数据科学提供标准化数据
定价
腾讯云数据湖计算提供三种购买方式:按扫描量计费、按量计费和包年包月。有关详细信息,请参阅 定价文档。

