echo"select * from system.clusters"|curl'http://xxx.xxx.xxx.xxx:8123/' --data-binary @-
创建数据表
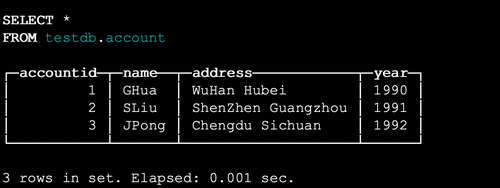
使用 clickhouse-client 连接集群,创建数据库和表。
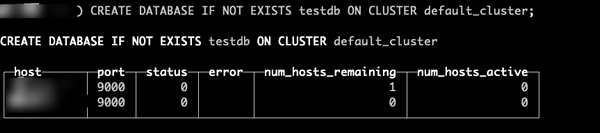
高可用模式下数据库
CREATE DATABASE IF NOT EXISTS testdb ON CLUSTER default_cluster;
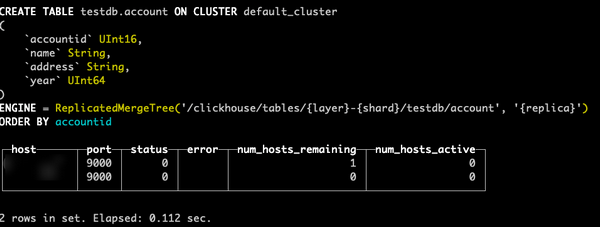
高可用模式下创建表
CREATE TABLE testdb.account ON CLUSTER default_cluster(accountid UInt16,name String,address String,year UInt64) ENGINE =ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/testdb/account', '{replica}') ORDER BY (accountid);
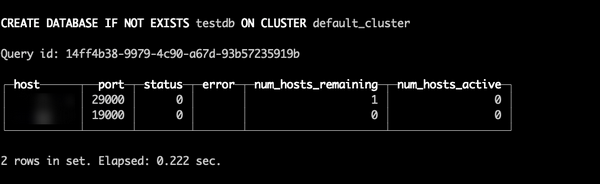
非高可用下创建数据库
CREATE DATABASE IF NOT EXISTS testdb ON CLUSTER default_cluster;
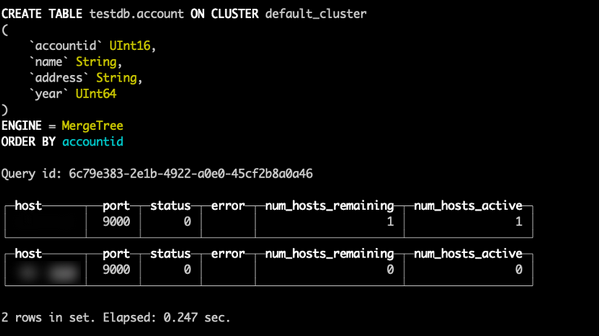
非高可用模式下创建表
CREATE TABLE testdb.account ON CLUSTER default_cluster(accountid UInt16, name String, address String, year UInt64) ENGINE =MergeTree() ORDER BY (accountid);




 是
是
 否
否
本页内容是否解决了您的问题?