- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- Kubernetes API 操作指引
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- CBS-CSI 说明
- UserGroupAccessControl 说明
- COS-CSI 说明
- CFS-CSI 说明
- P2P 说明
- OOMGuard 说明
- TCR 说明
- TCR Hosts Updater
- DNSAutoscaler 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- Network Policy 说明
- DynamicScheduler 说明
- DeScheduler 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- GPU-Manager 说明
- CFSTURBO-CSI 说明
- tke-log-agent 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 云原生监控
- 远程终端
- 策略管理
- TKE Serverless 集群指南
- TKE 边缘集群指南
- TKE 注册集群指南
- TKE 容器实例指南
- 云原生服务指南
- 最佳实践
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Cluster APIs
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateCluster
- UpdateClusterVersion
- UpdateClusterKubeconfig
- DescribeBackupStorageLocations
- DeleteBackupStorageLocation
- CreateBackupStorageLocation
- Add-on APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- DescribeTKEEdgeScript
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeClusters
- DescribeTKEEdgeClusterStatus
- DescribeTKEEdgeClusterCredential
- DescribeEdgeClusterInstances
- DescribeEdgeCVMInstances
- DescribeECMInstances
- DescribeAvailableTKEEdgeVersion
- DeleteTKEEdgeCluster
- DeleteEdgeClusterInstances
- DeleteEdgeCVMInstances
- DeleteECMInstances
- CreateTKEEdgeCluster
- CreateECMInstances
- CheckEdgeClusterCIDR
- ForwardTKEEdgeApplicationRequestV3
- UninstallEdgeLogAgent
- InstallEdgeLogAgent
- DescribeEdgeLogSwitches
- CreateEdgeLogConfig
- CreateEdgeCVMInstances
- UpdateEdgeClusterVersion
- DescribeEdgeClusterUpgradeInfo
- Cloud Native Monitoring APIs
- Virtual node APIs
- Other APIs
- Scaling group APIs
- Data Types
- Error Codes
- API Mapping Guide
- TKE Insight
- TKE 调度
- 常见问题
- 服务协议
- 联系我们
- 购买渠道
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- TKE 标准集群指南
- TKE 标准集群概述
- 购买 TKE 标准集群
- 容器服务高危操作
- 云上容器应用部署 Check List
- Kubernetes API 操作指引
- 开源组件
- 权限管理
- 集群管理
- 镜像
- Worker 节点介绍
- 普通节点管理
- 原生节点管理
- 超级节点管理
- 注册节点管理
- GPU 共享
- Kubernetes 对象管理
- Service 管理
- Ingress 管理
- 存储管理
- 应用与组件功能管理说明
- 组件管理
- 扩展组件概述
- 组件的生命周期管理
- CBS-CSI 说明
- UserGroupAccessControl 说明
- COS-CSI 说明
- CFS-CSI 说明
- P2P 说明
- OOMGuard 说明
- TCR 说明
- TCR Hosts Updater
- DNSAutoscaler 说明
- NodeProblemDetectorPlus 说明
- NodeLocalDNSCache 说明
- Network Policy 说明
- DynamicScheduler 说明
- DeScheduler 说明
- Nginx-ingress 说明
- HPC 说明
- tke-monitor-agent 说明
- GPU-Manager 说明
- CFSTURBO-CSI 说明
- tke-log-agent 说明
- 应用管理
- 应用市场
- 网络管理
- 集群运维
- 日志管理
- 备份中心
- 云原生监控
- 远程终端
- 策略管理
- TKE Serverless 集群指南
- TKE 边缘集群指南
- TKE 注册集群指南
- TKE 容器实例指南
- 云原生服务指南
- 最佳实践
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Cluster APIs
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateCluster
- UpdateClusterVersion
- UpdateClusterKubeconfig
- DescribeBackupStorageLocations
- DeleteBackupStorageLocation
- CreateBackupStorageLocation
- Add-on APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- DescribeTKEEdgeScript
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeClusters
- DescribeTKEEdgeClusterStatus
- DescribeTKEEdgeClusterCredential
- DescribeEdgeClusterInstances
- DescribeEdgeCVMInstances
- DescribeECMInstances
- DescribeAvailableTKEEdgeVersion
- DeleteTKEEdgeCluster
- DeleteEdgeClusterInstances
- DeleteEdgeCVMInstances
- DeleteECMInstances
- CreateTKEEdgeCluster
- CreateECMInstances
- CheckEdgeClusterCIDR
- ForwardTKEEdgeApplicationRequestV3
- UninstallEdgeLogAgent
- InstallEdgeLogAgent
- DescribeEdgeLogSwitches
- CreateEdgeLogConfig
- CreateEdgeCVMInstances
- UpdateEdgeClusterVersion
- DescribeEdgeClusterUpgradeInfo
- Cloud Native Monitoring APIs
- Virtual node APIs
- Other APIs
- Scaling group APIs
- Data Types
- Error Codes
- API Mapping Guide
- TKE Insight
- TKE 调度
- 常见问题
- 服务协议
- 联系我们
- 购买渠道
- 词汇表
操作场景
通过在集群节点上以 Daemonset 的形式运行 NodeLocal DNS Cache,能够大幅提升集群内 DNS 解析性能,以及有效避免 conntrack 冲突引发的 DNS 五秒延迟。
本文接下来将详细介绍如何在 TKE 集群中使用 NodeLocal DNS Cache。
操作原理
通过 DaemonSet 在集群的每个节点上部署一个 hostNetwork 的 Pod,该 Pod 是 node-cache,可以缓存本节点上 Pod 的 DNS 请求。如果存在 cache misses ,该 Pod 将会通过 TCP 请求上游 kube-dns 服务进行获取。原理图如下所示:
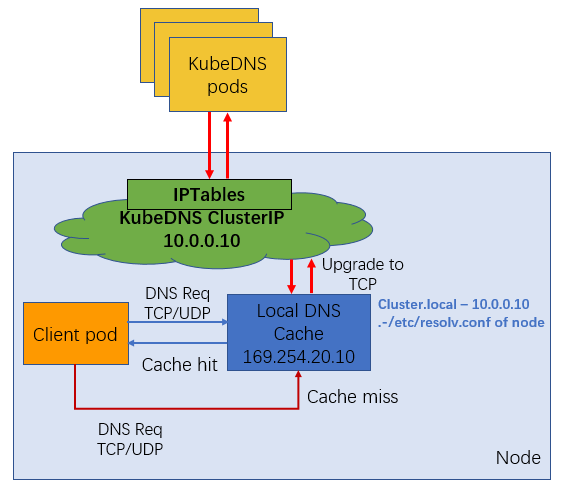
说明:
NodeLocal DNS Cache 没有高可用性(High Availability,HA),会存在单点 nodelocal dns cache 故障(Pod Evicted/ OOMKilled/ConfigMap error/DaemonSet Upgrade),但是该现象其实是任何的单点代理(例如 kube-proxy,cni pod)都会存在的常见故障问题。
前提条件
已通过 容器服务控制台 创建了 Kubernetes 版本为 1.14 及以上的集群,且该集群中存在节点。
操作步骤
- 一键部署 NodeLocal DNS Cache。YAML 示例如下:
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: node-local-dns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: v1
kind: ConfigMap
metadata:
name: node-local-dns
namespace: kube-system
data:
Corefile: |
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
health 169.254.20.10:8080
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . /etc/resolv.conf {
force_tcp
}
prometheus :9253
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-local-dns
namespace: kube-system
labels:
k8s-app: node-local-dns
spec:
updateStrategy:
rollingUpdate:
maxUnavailable: 10%
selector:
matchLabels:
k8s-app: node-local-dns
template:
metadata:
labels:
k8s-app: node-local-dns
annotations:
prometheus.io/port: "9253"
prometheus.io/scrape: "true"
spec:
serviceAccountName: node-local-dns
priorityClassName: system-node-critical
hostNetwork: true
dnsPolicy: Default # Don't use cluster DNS.
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
- effect: "NoExecute"
operator: "Exists"
- effect: "NoSchedule"
operator: "Exists"
containers:
- name: node-cache
image: ccr.ccs.tencentyun.com/hale/k8s-dns-node-cache:1.15.13
resources:
requests:
cpu: 25m
memory: 5Mi
args: [ "-localip", "169.254.20.10", "-conf", "/etc/Corefile", "-setupiptables=true" ]
securityContext:
privileged: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9253
name: metrics
protocol: TCP
livenessProbe:
httpGet:
host: 169.254.20.10
path: /health
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
volumeMounts:
- mountPath: /run/xtables.lock
name: xtables-lock
readOnly: false
- name: config-volume
mountPath: /etc/coredns
- name: kube-dns-config
mountPath: /etc/kube-dns
volumes:
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
- name: kube-dns-config
configMap:
name: kube-dns
optional: true
- name: config-volume
configMap:
name: node-local-dns
items:
- key: Corefile
path: Corefile.base
- 将 kubelet 的指定 dns 解析访问地址设置为 步骤1 中创建的 lcoal dns cache。本文提供以下两种配置方法,请根据实际情况进行选择:
- 依次执行以下命令,修改 kubelet 启动参数并重启。
sed -i '/CLUSTER_DNS/c\CLUSTER_DNS="--cluster-dns=169.254.20.10"' /etc/kubernetes/kubeletsystemctl restart kubelet - 根据需求配置单个 Pod 的 dnsconfig 后重启。YAML 核心部分参考如下:
- 需要将 nameserver 配置为169.254.20.10。
- 为确保集群内部域名能够被正常解析,需要配置 searches。
- 适当降低 ndots 值有利于加速集群外部域名访问。
- 当 Pod 没有使用带有多个 dots 的集群内部域名的情况下,建议将值设为2。
dnsConfig:
nameservers: ["169.254.20.10"]
searches:
- default.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "2"
配置验证
本次测试集群为 Kubernetes 1.14 版本集群。在通过上述步骤完成 NodeLocal DNSCache 组件部署之后,可以参照以下方法进行验证:
- 选择一个 debug pod,调整 kubelet 参数或者配置 dnsConfig 后重启。
- Dig 外网域名,尝试在 coredns pod 上抓包。
- 显示169.254.20.10正常工作即可证明 NodeLocal DNSCache 组件部署成功。如下图所示:


 是
是
 否
否
本页内容是否解决了您的问题?