概述
云数据库 CTSDB 是一款分布式、可扩展、支持近实时数据搜索与分析的时序数据库,且兼容 ELK 生态组件,您可以非常方便的使用 ELK 组件与 CTSDB 对接。
ELK 组件提供了丰富的数据处理功能,包括数据采集、数据清洗、可视化图形展示等。常用的 ELK 生态组件包括 Filebeat、Logstash、Kibana。同时,CTSDB 也支持 Grafana 作为可视化平台。常见架构图如下: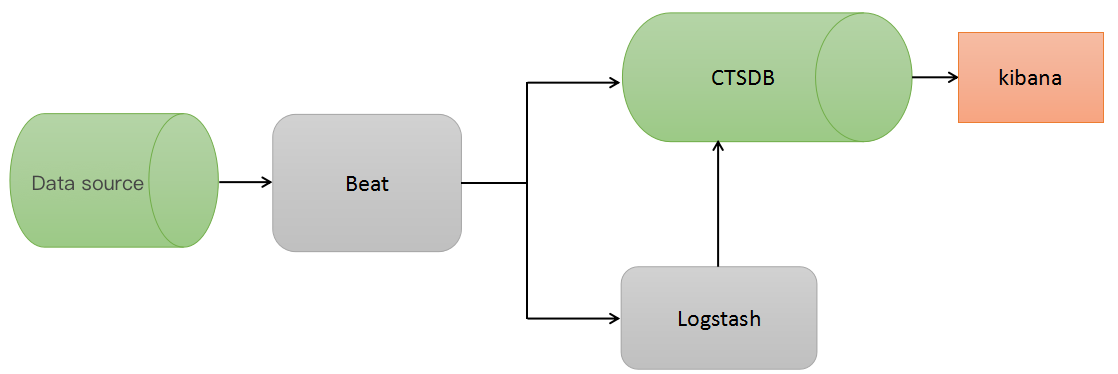
组件的使用
Filebeat
Filebeat 是一个轻量级开源日志文件数据搜集器,作为 agent 安装到服务器上,Filebeat 读取文件内容,发送到 Logstash 进行解析后进入 CTSDB,或直接发送到 CTSDB 进行集中式存储和分析。
Filebeat 的使用流程
- 安装
Filebeat 安装介绍请参见 该地址。 - 配置
Filebeat 的配置采用 YAML 格式文件,主要配置为全局配置、输入配置、输出配置,下节会给出使用样例。 - 启动
Filebeat 启动时可以指定配置文件路径,若不指定则默认使用 filebeat.yml。
Filebeat 使用示例
首先,将 Filebeat 的安装包解压缩到某一目录,如下所示:

然后,配置 filebeat.yml,配置参考如下:
filebeat.shutdown_timeout: 5 # How long filebeat waits on shutdown for the publisher to finish. max_procs: 4 # 可同时执行的最大cpu数,默认为操作系统可用的逻辑cpu数 filebeat.spool_size: 102400 filebeat.idle_timeout: 2s processors: drop_fields: # 需要drop掉的字段 fields: ["beat","input_type","source","offset"] filebeat.prospectors: paths: ["/data/log/filebeat-tutorial.log"] # 样例数据所在的路径 fields: metricname: metric1 harvester_buffer_size: 1638400 close_timeout: 0.5h scan_frequency: 2s paths: ["/mylog/*.log","/mylog1/*.log"] fields: metricname: table2 harvester_buffer_size: 1638401 close_timeout: 0.5h scan_frequency: 2s output.elasticsearch: hosts: ["127.0.0.1:9200"] index: "%{[fields.indexname]}" # 通配,可以达到不同类别的数据写入不同index的目的 username: "root" # 对于有权限的CTSDB这里需要填用户名和密码 password: "changeme" worker: 2 # 工作线程数 loadbalance: true # 是否开启负载均衡 bulk_max_size: 512 # 一次bulk的最大文档数 flush_interval: 2s template: enabled: false # 注意:Filebeat启动后会put一个默认的template,对接CTSDB时,需要禁用Filebeat的template部分样例数据如下:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36" 83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-dashboard3.png HTTP/1.1" 200 171717 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36" 83.149.9.216 - - [04/Jan/2015:05:13:44 +0000] "GET /presentations/logstash-monitorama-2013/plugin/highlight/highlight.js HTTP/1.1" 200 26185 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"启动 Filebeat,并观察 CTSDB 中对应表的数据:
nohup ./filebeat & less logs/filebeat # 查看部分日志,通过日志libbeat.es.published_and_acked_events=100可以看出我们的100条日志都成功写入到es中 2018-05-25T14:32:24+08:00 INFO Non-zero metrics in the last 30s: filebeat.harvester.open_files=1 filebeat.harvester.running=1 filebeat.harvester.started=1 libbeat.es.call_count.PublishEvents=1 libbeat.es.publish.read_bytes=1535 libbeat.es.publish.write_bytes=40172 libbeat.es.published_and_acked_events=100 libbeat.publisher.published_events=100 publish.events=101 registrar.states.current=1 registrar.states.update=101 registrar.writes=2 # 通过kibana或curl查看es中是否有数据写入到metric1 # 命令: GET metric1/_search { "sort": [ { "@timestamp": { "order": "desc" } } ], "docvalue_fields": ["@timestamp", "message"] } # 结果: { "took": 2, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 100, "max_score": null, "hits": [ { "_index": "metric1@1525536000000_30", "_type": "doc", "_id": "AWOV_o1wBzkw2jsSfrLN", "_score": null, "fields": { "@timestamp": [ 1527229914629 ], "message": [ "218.30.103.62 - - [04/Jan/2015:05:27:57 +0000] \"GET /blog/geekery/c-vs-python-bdb.html HTTP/1.1\" 200 11388 \"-\" \"Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)\"" ] }, "sort": [ 1527229914629 ] }, # 内容太多,这里省略,通过hits.total可以看出,查询命中了100条文档,证明100条log都成功写入CTSDB`上述示例是直接通过 Filebeat 将原始日志数据写入到 CTSDB 中,并没有做字段的解析,下节将会介绍通过 Logstash 解析数据,然后写入 CTSDB。
Logstash
Logstash 是一款具有实时数据解析功能的开源数据收集引擎。Logstash 能够搜集各种数据源,并对数据进行过滤、分析、格式化等操作,然后存储到 CTSDB。
Logstash 使用流程
- 安装
Logstash 安装请参见 该地址。 - 配置
Logstash 的主要配置包含三个模块,分别为数据源输入,数据解析规则,数据输出。下节会给出使用样例。 - 启动
Logstash 启动时,可以指定配置文件,否则,默认使用 logstash.yml 作为配置,解析规则默认使用 pipelines.yml 中的配置。
Logstash使用示例
- 首先,将 Logstash 的安装包解压缩到某一目录,如下所示:

- 然后,创建一个配置文件,当然也可以在 logstash.yml 和 pipelines.yml 中进行配置。这里创建一个配置文件名为 first-pipeline.conf,配置如下:
# 输入源 input { beats { port => "5044" } } # 解析过滤 filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } } # 输出 output { elasticsearch { action => "index" hosts => ["localhost:9200"] index => "logstash_metric" # CTSDB中创建的metric名 document_type => "doc" user => "root" # 对于有权限的CTSDB需要指定用户名和密码 password => "changeme" } } - 启动 Logstash、Filebeat,并观察 CTSDB 中对应表的数据:
# 这里需要注意的是,Filebeat的输出是Logstash,因此Filebeat的输出项配置改为: output.logstash: hosts: ["localhost:5044"] # 清空Filebeat的data目录,启动Filebeat rm data/registry nohup ./filebeat & # 启动Logstash nohup bin/logstash -f first-pipeline.conf --config.reload.automatic & # 通过kibana或curl查看CTSDB中是否有数据写入到metric1 # 命令: GET logstash_metric/_search { "sort": [ { "@timestamp": { "order": "desc" } } ], "docvalue_fields": ["@timestamp","request", "response", "type", "bytes", "verb", "agent", "clientip"] } # 结果: { "took": 0, "timed_out": false, "_shards": { "total": 0, "successful": 0, "skipped": 0, "failed": 0 }, "hits": { "total": 0, "max_score": 0, "hits": [] } } # 这里发现结果是空的,说明没有数据没有写入到CTSDB,查看Logstash日志: [2018-05-25T21:00:07,081][ERROR][logstash.outputs.elasticsearch] Encountered a retryable error. Will Retry with exponential backoff {:code=>403, :url=>"http://127.0.0.1:9200/_bulk"} [2018-05-25T21:00:07,081][ERROR][logstash.outputs.elasticsearch] Encountered a retryable error. Will Retry with exponential backoff {:code=>403, :url=>"http://127.0.0.1:9200/_bulk"} # 发现bulk出错,并返回403权限错误,仔细验证 用户名和密码,发现并无问题,继续查看es日志: [2018-05-25T20:59:27,545][WARN ][o.e.p.o.OPackActionFilter] [1505480279000001609] process index failed: Invalid format: "2018-05-25T12:51:18.905Z" [2018-05-25T20:59:27,547][WARN ][o.e.p.o.OPackActionFilter] [1505480279000001609] process index failed: Invalid format: "2018-05-25T12:51:18.905Z" # 从es的日志可以看出 ,时间格式解析出错。出错的原因是,笔者建metric时没有指定时间字段的格式,那么CTSDB默认为epoch_millis,因此需要修改下时间格式: POST /_metric/logstash_metric/update?pretty { "time": { "name": "@timestamp", "format": "strict_date_optional_time" } } # 重启Logstash、Filebeat重新写入数据,再查看CTSDB: # 结果 { "took": 2, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 100, "max_score": null, "hits": [ { "_index" : "logstash_metric@1527004800000_30", "_type" : "doc", "_id" : "AWOvG0YgQoCkIV2BLcov", "_score" : null, "fields" : { "request" : [ "/blog/tags/puppet?flav=rss20" ], "agent" : [ "\"UniversalFeedParser/4.2-pre-314-svn +http://feedparser.org/\"" ], "@timestamp" : [ 1527651156725 ], "response" : [ "200" ], "bytes" : [ 14872 ], "clientip" : [ "46.105.14.53" ], "verb" : [ "GET" ], "type" : [ "log" ] }, "sort" : [ 1527651156725 ] }, ... ... # 内容太多,这里省略,通过hits.total可以看出,查询命中了100条文档,证明100条log都成功写入CTSDB
Kibana
Kibana 是一个旨在为 Elasticsearch 设计的开源的分析和可视化平台。可以使用 Kibana 来搜索,查看存储在 CTSDB metric 中的数据并与其进行交互。可以利用 Kibana 中丰富的图表、表格、曲线等功能来可视化数据并进行数据分析。
Kibana 使用流程
- 安装
下载与 Elasticseach 对应的 Kibana 版本,并解压到某一目录。 - 配置
Kibana 的配置很简单,下节会给出样例。具体配置项含义参考 该地址。 - 运行
Kibana 运行时,默认使用 config/kibana.yml 作为配置。
Kibana使用示例
- 首先,将 Kibana 的安装包解压到某一目录,如下所示

- 然后,修改 config 下的配置文件。主要配置如下:
# config/kibana.yml # Kibana server监听的端口 server.port: 5601 # Kibana server所绑定的服务器ip server.host: 127.0.0.1 # 所要连接的CTSDB的url elasticsearch.url: "http://127.0.0.1:9200" # 若使用带权限的CTSDB,则需要指定用户名和密码 elasticsearch.username: "root" elasticsearch.password: "changeme"
- 启动,并通过浏览器访问 kibana
nohup bin/kibana &
利用开发工具,我们可以很方便的访问 CTSDB,如下图所示: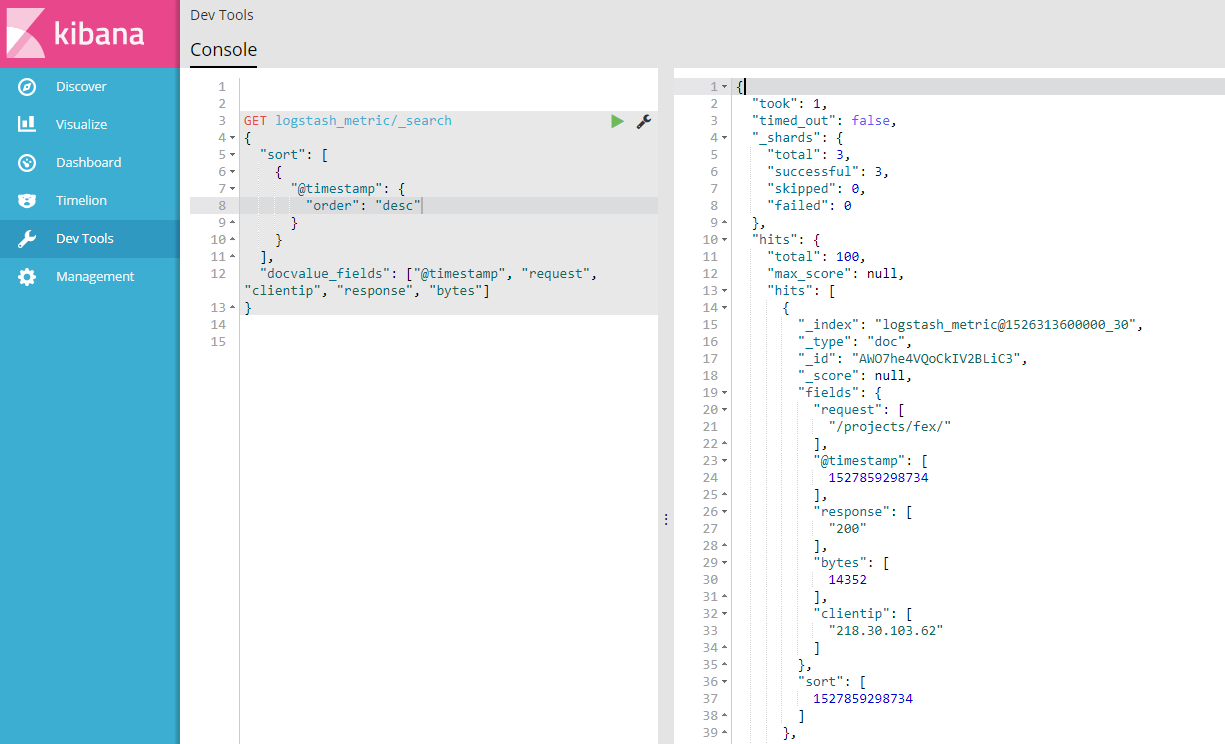
在管理页面创建需要访问的索引,如下所示: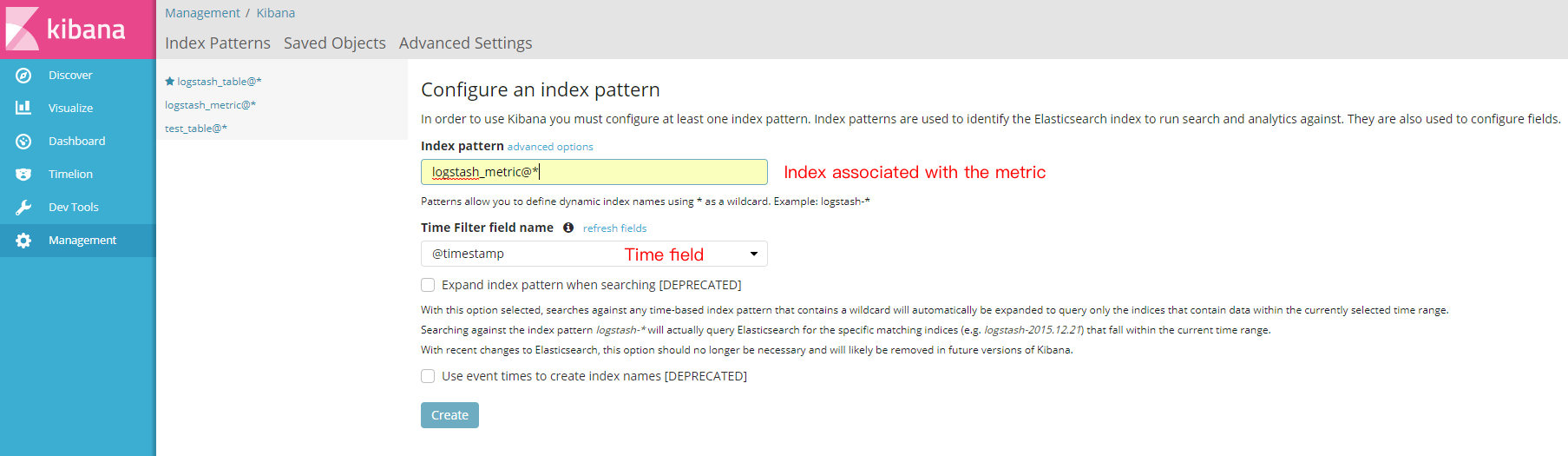
如果您有日志搜索的需求,可能会使用到搜索功能,如下图所示: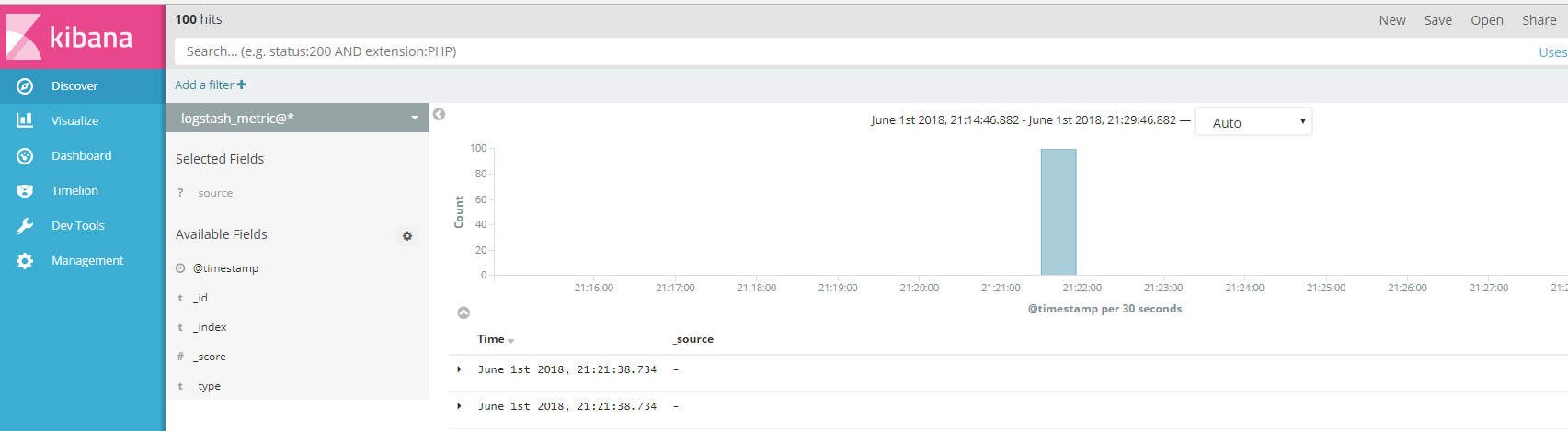
从上图,我们发现,搜索的结果出了时间以外,没有其他,原因是 CTSDB 为了节省存储空间默认没有开启 source 功能,如果您有日志搜索的需求,请联系我们开启 source。开启 source 后的效果如下图所示: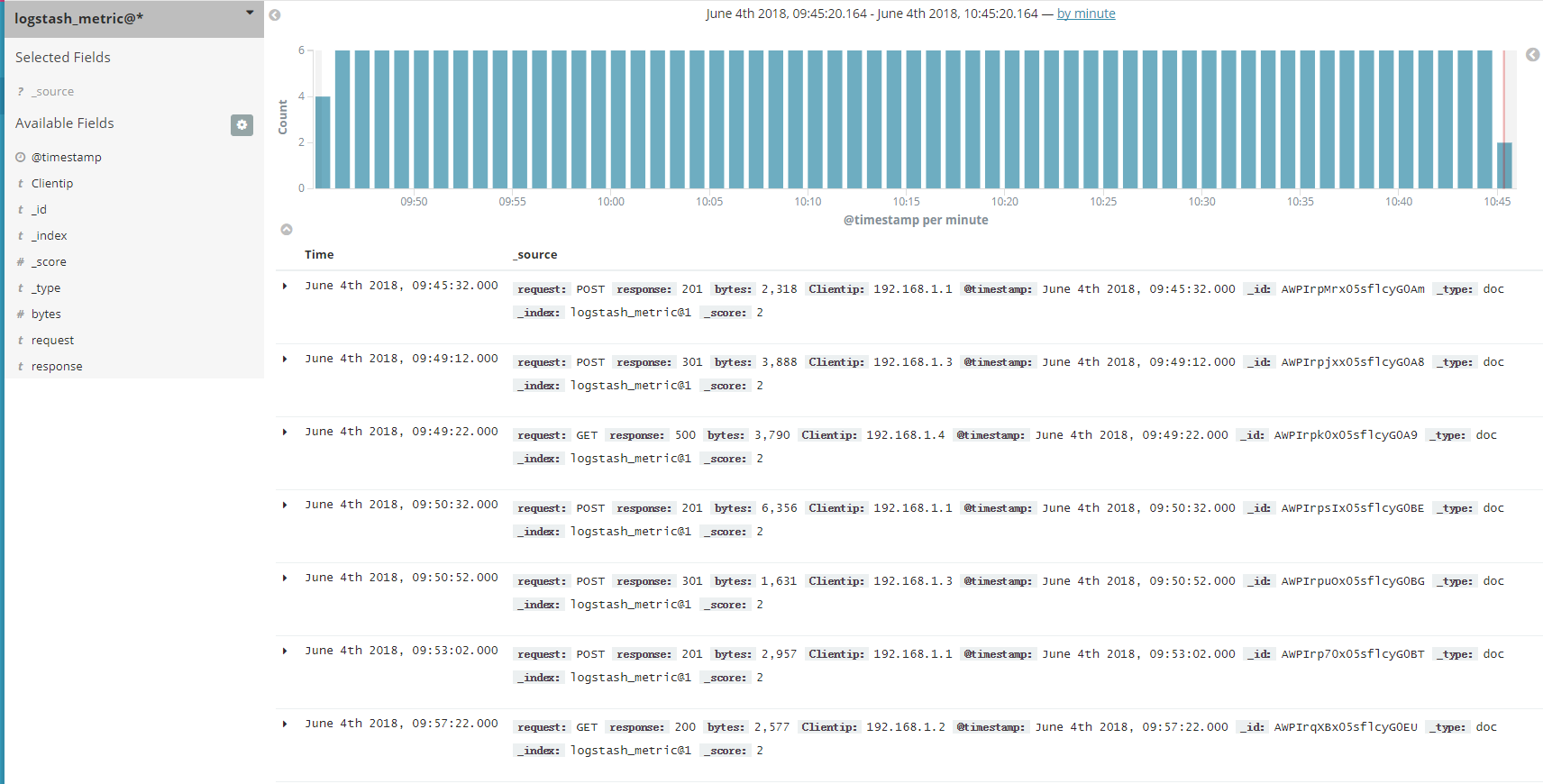
利用可视化,我们可以构建各种图表,这里以创建 Line Chart 为例,展示 Kibana 的图表效果,如下所示: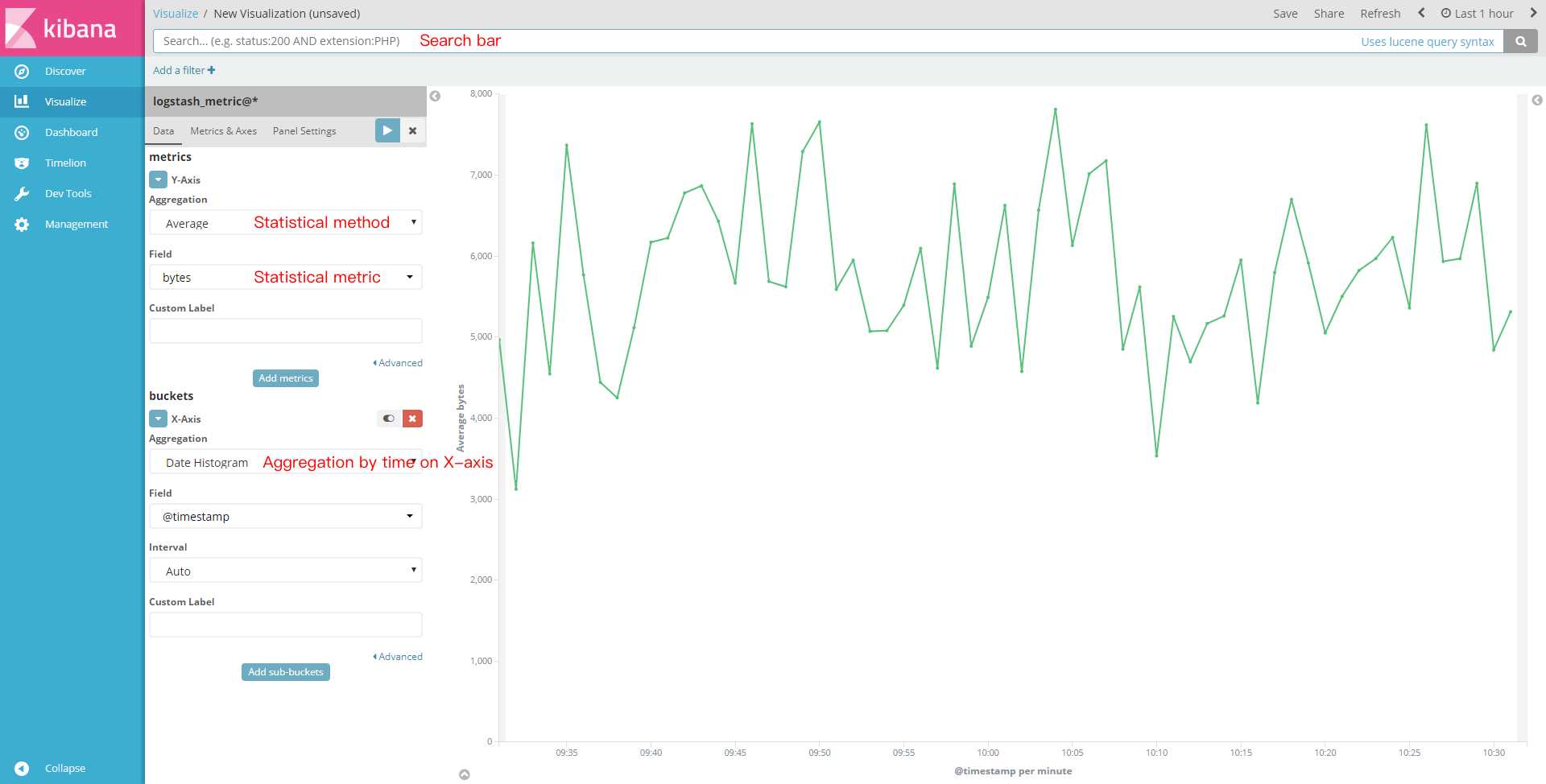
Kibana 不仅提供了丰富的可视化图表功能,而且还可以利用仪表盘将我们保存的可视化图表统一展示都一个页面上,非常方便地查看多个指标的变化状态。这里为了展示效果,贴一张我们内部真实的监控数据的仪表盘视图,如下所示: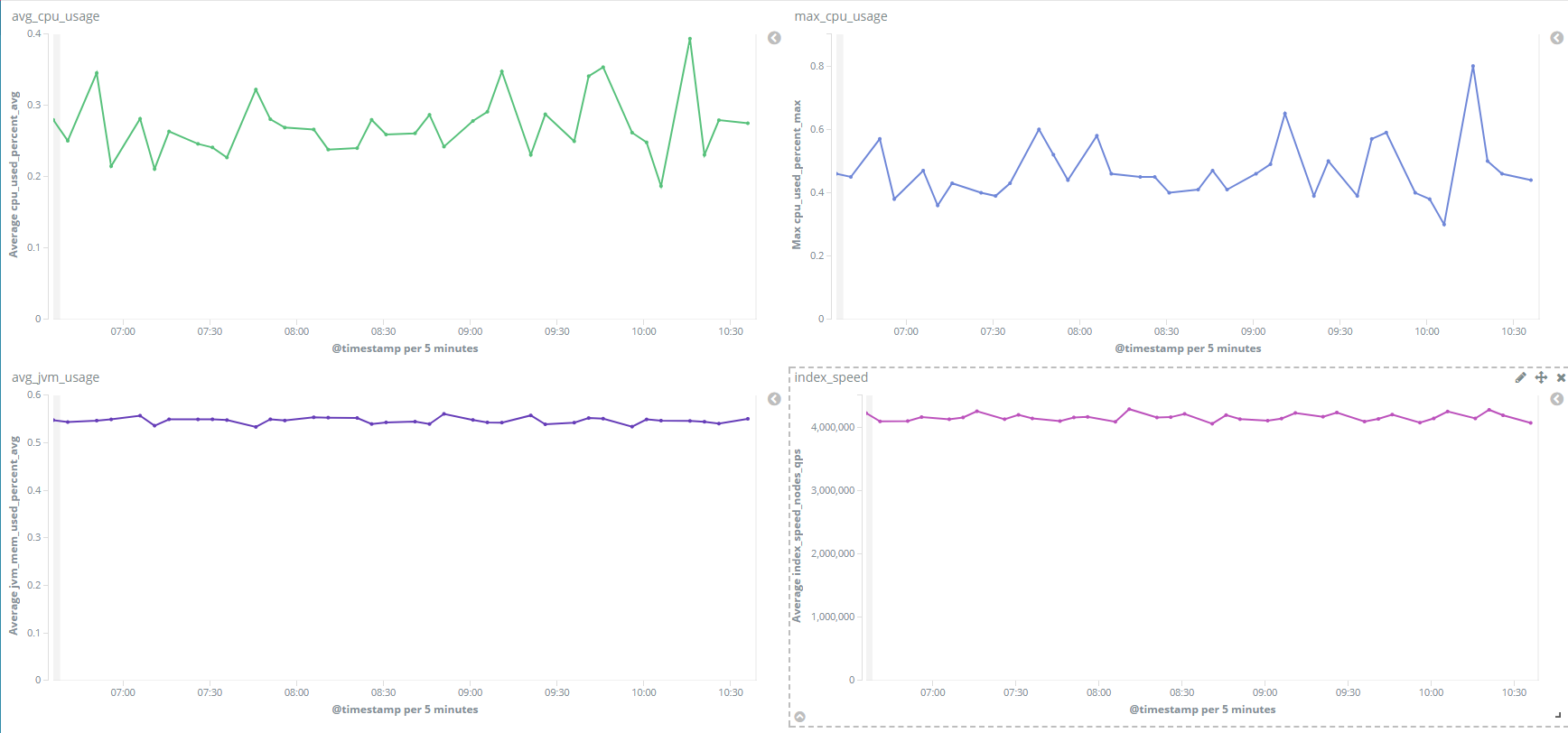
Grafana
Grafana 是一款开源的仪表盘工具,它提供了丰富的图表功能,类似 Kibana,利用 Grafana 精细的展示效果,可以帮助您有效地进行数据分析。和 Kibana 不同的是,Grafana 支持的数据源种类更多,包含 influxdb、opentsdb、Elasticsearch,下面演示利用 Grafana 来可视化的分析 CTSDB 中的数据。
Grafana
- 安装
Grafana 的安装请参见 官方文档。 - 配置
Grafana 的配置项较多,可以使用默认的配置,具体配置说明参考 该地址。 - 运行
Grafana 运行时,默认使用 /etc/grafana/grafana.ini 作为配置。
Grafana 使用示例
- 首先,启动 grafana 服务。
sudo service grafana-server start - 然后,通过浏览器访问 Grafana 服务:

- 创建数据源,建立 dashboard,如下所示:
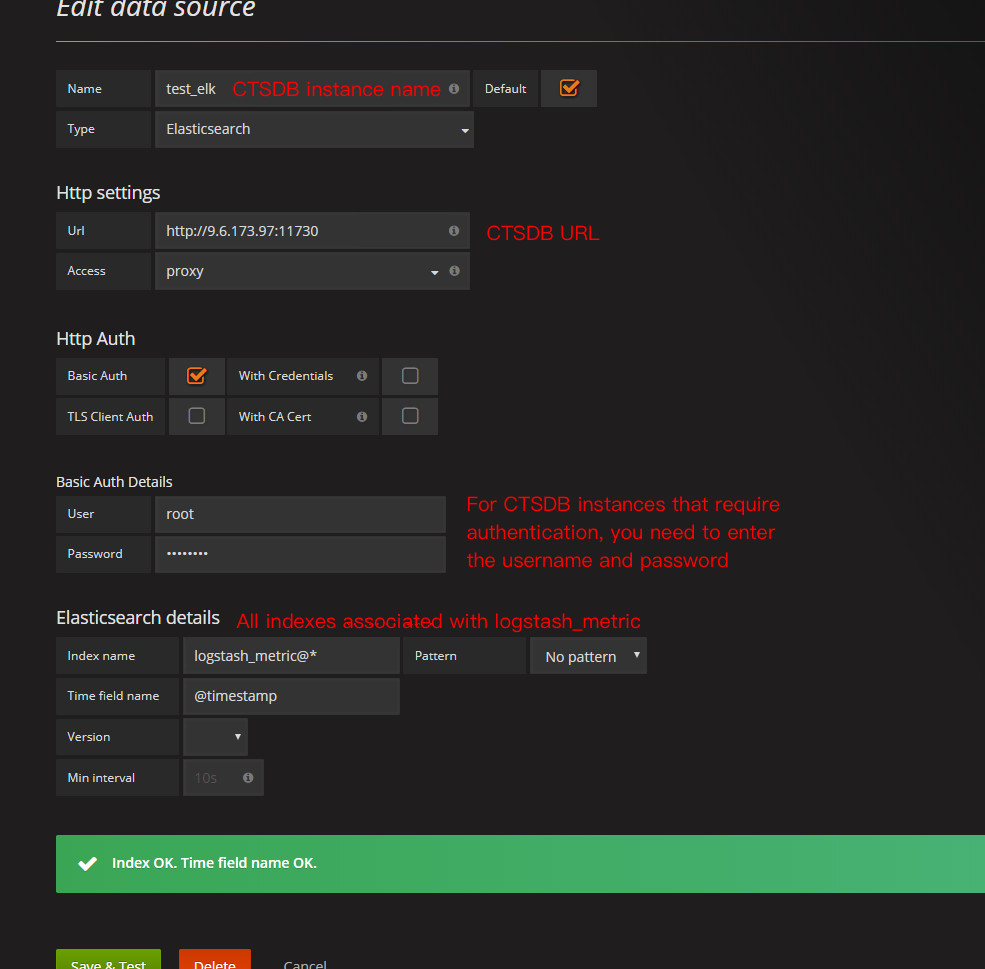
- 利用 dashboard 创建可视化图表,如下图所示:
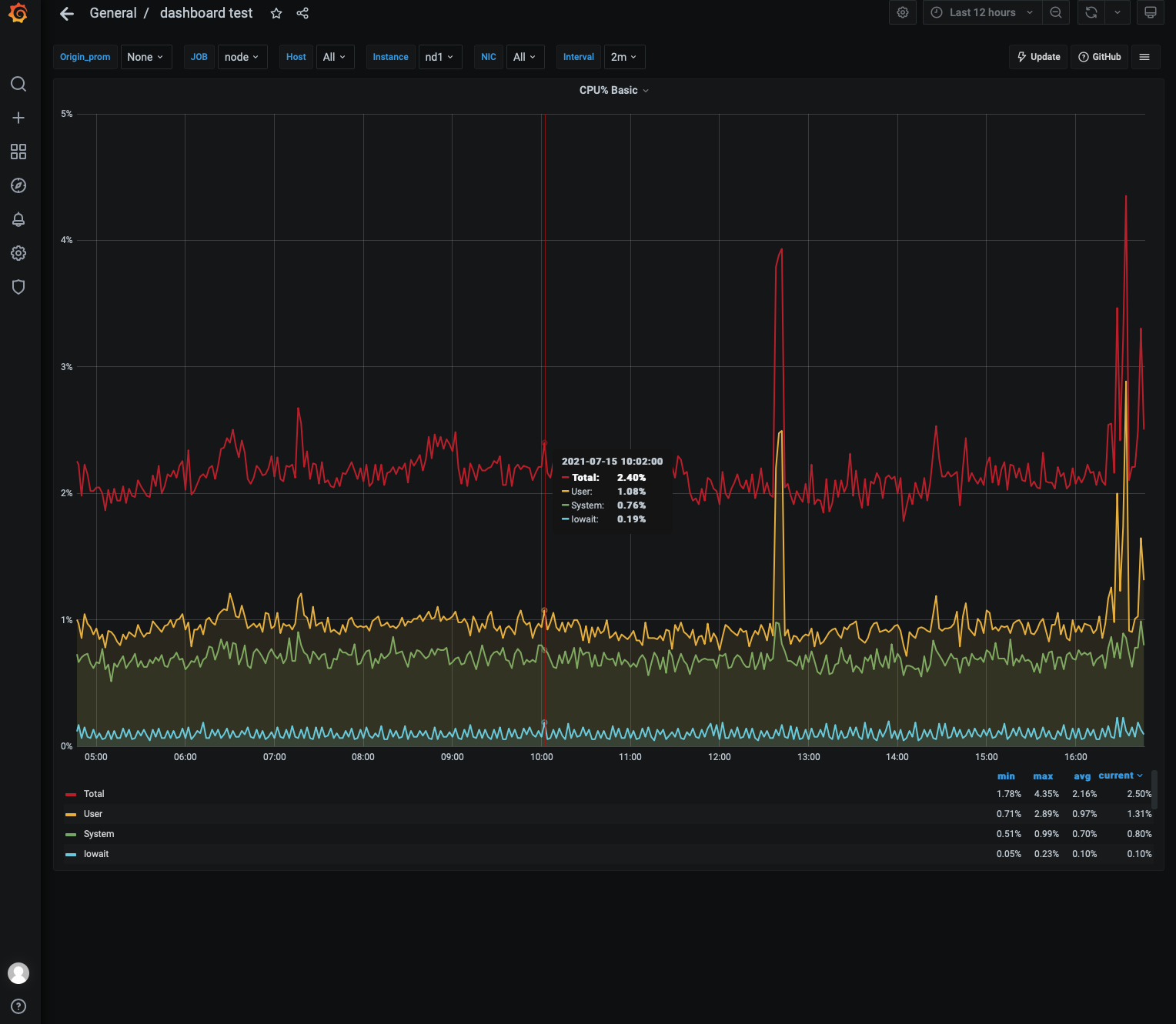
- 从上图可以看出,Grafana 的图表展示效果和 Kibana 略有区别,但是功能本质上是一样的,这个看您的个人使用习惯和爱好。同样,Grafana 的 dashboard 也能同时展示多个可视化图表,如下图所示:
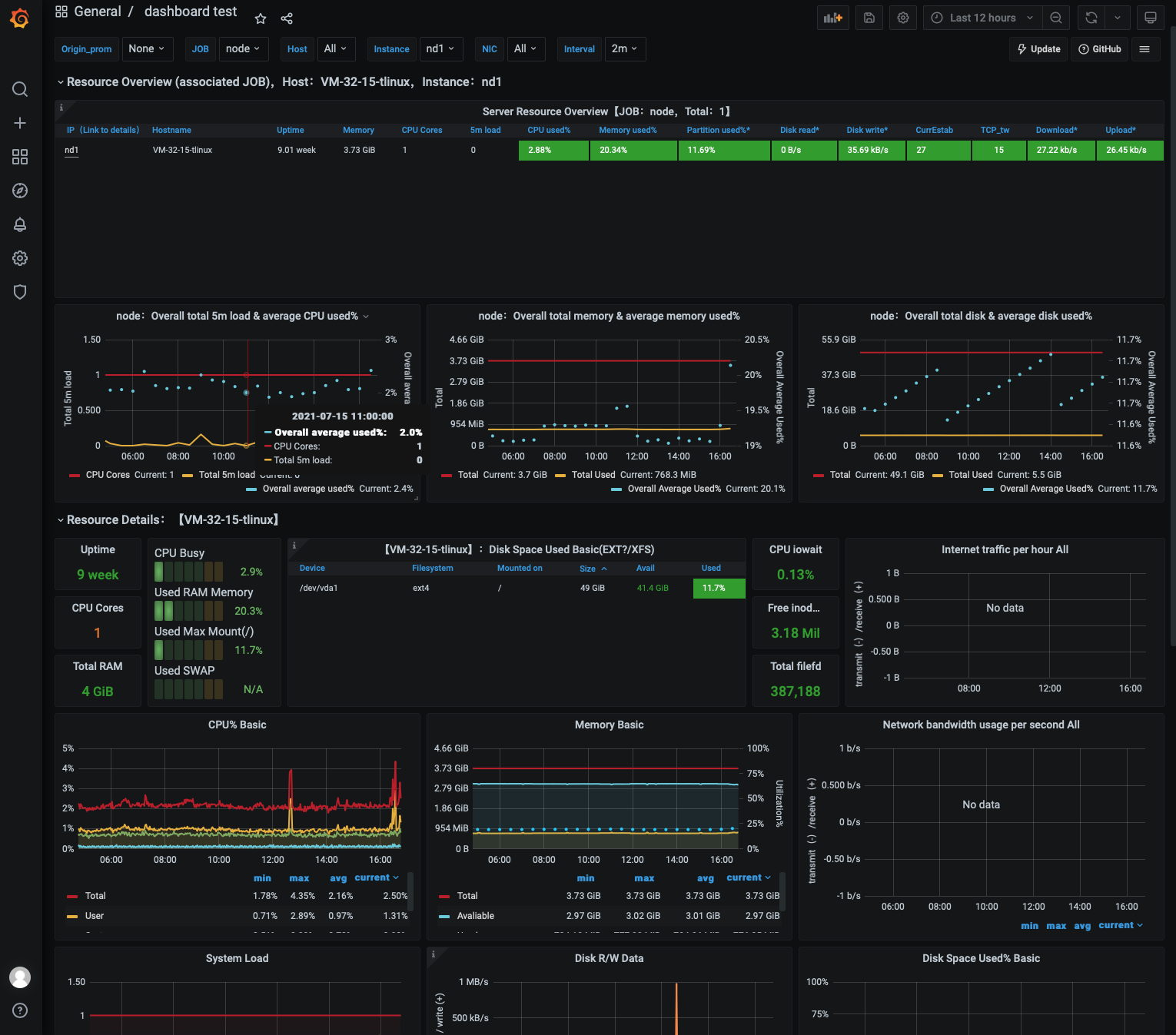
小结
以上为 ELK 生态组件及 Grafana 对接 CTSDB 的详细使用过程,如在使用过程中遇到问题需要解决,请 提交工单 联系我们。

 是
是
 否
否
本页内容是否解决了您的问题?