- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 内核能力介绍
- 操作指南
- ServerlessDB 相关
- MSSQL 兼容版
- 实践教程
- 性能白皮书
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Instance APIs
- CreateInstances
- DescribeDBInstances
- DescribeDBInstanceAttribute
- DescribeEncryptionKeys
- DescribeDBInstanceHAConfig
- SwitchDBInstancePrimary
- ModifyDBInstanceName
- ModifyDBInstanceSpec
- ModifyDBInstanceDeployment
- UpgradeDBInstanceKernelVersion
- ModifyDBInstanceHAConfig
- ModifyDBInstanceChargeType
- ModifyDBInstancesProject
- ModifySwitchTimePeriod
- RenewInstance
- SetAutoRenewFlag
- RestartDBInstance
- IsolateDBInstances
- DisIsolateDBInstances
- DestroyDBInstance
- CreateDBInstances
- InitDBInstances
- UpgradeDBInstance
- UpgradeDBInstanceMajorVersion
- Read-only Replica APIs
- Backup and Recovery APIs
- DescribeAvailableRecoveryTime
- DescribeCloneDBInstanceSpec
- CloneDBInstance
- RestoreDBInstanceObjects
- DescribeBackupOverview
- DescribeBackupSummaries
- DescribeBackupPlans
- ModifyBackupPlan
- CreateBaseBackup
- DescribeBaseBackups
- ModifyBaseBackupExpireTime
- DeleteBaseBackup
- DescribeLogBackups
- DeleteLogBackup
- DescribeBackupDownloadURL
- DescribeBackupDownloadRestriction
- ModifyBackupDownloadRestriction
- DescribeDBXlogs
- DescribeDBBackups
- Parameter Management APIs
- Security Group APIs
- Performance Optimization APIs
- Account APIs
- Specification APIs
- PostgreSQL for Serverless APIs
- Network APIs
- Data Types
- Error Codes
- 常见问题
- 相关协议
- 词汇表
- 联系我们
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 内核能力介绍
- 操作指南
- ServerlessDB 相关
- MSSQL 兼容版
- 实践教程
- 性能白皮书
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Instance APIs
- CreateInstances
- DescribeDBInstances
- DescribeDBInstanceAttribute
- DescribeEncryptionKeys
- DescribeDBInstanceHAConfig
- SwitchDBInstancePrimary
- ModifyDBInstanceName
- ModifyDBInstanceSpec
- ModifyDBInstanceDeployment
- UpgradeDBInstanceKernelVersion
- ModifyDBInstanceHAConfig
- ModifyDBInstanceChargeType
- ModifyDBInstancesProject
- ModifySwitchTimePeriod
- RenewInstance
- SetAutoRenewFlag
- RestartDBInstance
- IsolateDBInstances
- DisIsolateDBInstances
- DestroyDBInstance
- CreateDBInstances
- InitDBInstances
- UpgradeDBInstance
- UpgradeDBInstanceMajorVersion
- Read-only Replica APIs
- Backup and Recovery APIs
- DescribeAvailableRecoveryTime
- DescribeCloneDBInstanceSpec
- CloneDBInstance
- RestoreDBInstanceObjects
- DescribeBackupOverview
- DescribeBackupSummaries
- DescribeBackupPlans
- ModifyBackupPlan
- CreateBaseBackup
- DescribeBaseBackups
- ModifyBaseBackupExpireTime
- DeleteBaseBackup
- DescribeLogBackups
- DeleteLogBackup
- DescribeBackupDownloadURL
- DescribeBackupDownloadRestriction
- ModifyBackupDownloadRestriction
- DescribeDBXlogs
- DescribeDBBackups
- Parameter Management APIs
- Security Group APIs
- Performance Optimization APIs
- Account APIs
- Specification APIs
- PostgreSQL for Serverless APIs
- Network APIs
- Data Types
- Error Codes
- 常见问题
- 相关协议
- 词汇表
- 联系我们
除了使用传统的 pg_dump 和 pg_restore 方法进行数据导入和导出之外,腾讯云数据库提供了数据传输服务 DTS 以支持数据迁移上云以及云上实例数据迁移的功能。
支持功能
支持云下自建 PostgreSQL 迁移至腾讯云数据库。
支持其他云的 PostgreSQL 数据库迁移至腾讯云数据库。
支持云上 CVM 或容器等自建的 PostgreSQL 迁移至腾讯云数据库。
支持腾讯云数据库 PostgreSQL 迁移至腾讯云数据库。
支持跨账号数据库迁移。
支持 TDSQL-C PostgreSQL 版与云数据库 PostgreSQL 数据互相迁移。
支持 PostgreSQL 10及之后的所有版本互相跨版本迁移,如 PostgreSQL 10迁移至 PostgreSQL 12,PostgreSQL 14迁移至 PostgreSQL 11。
PostgreSQL 9.4、9.5、9.6版本可通过源端安装插件的形式支持作为源数据库进行“全量 + 增量迁移”。否则仅支持全量迁移。
注意事项
以下注意事项非常重要,在执行数据迁移之前一定要详细了解,避免迁移失败。
DTS 在执行全量数据迁移时,会占用一定源端实例资源,可能会导致源实例负载上升,增加数据库自身压力。如果您的数据库配置过低,建议您在业务低峰期进行迁移。
外网实例迁移时,请确保源实例服务在外网环境下可访问,并且要保持外网连接的稳定性,当网络出现波动或者故障时会导致迁移失败,迁移一旦失败,就需要重新发起迁移任务。
迁移过程中,迁移速率会受源端的读取性能、源端与目标端实例间网络带宽、目标端实例的规格性能等因素影响而不同。迁移并发度由目标端实例规格的核心数决定,如目标端实例为2核,并发度则为2。
相互关联的数据对象需要同时迁移,否则会导致迁移失败。常见的关联关系:视图引用表、视图引用视图、存储过程/函数/触发器引用视图/表、主外键关联表等。
为保障迁移效率,CVM 自建实例迁移不支持跨地域迁移。如需要跨地域迁移,请选择公网接入方式。
如果进行整个实例迁移,目标库中不能存在与源库同名的用户和角色。
迁移类型选择全量 + 增量迁移时,源数据库中的表必须有主键,否则会出现源库和目标库数据不一致,对于无主键的表,建议选择全量迁移。
源端库迁移账户必须具有 replication 权限。
在增量迁移过程中,不支持同步 DDL。同时也不要做大对象的变更。若一定要做 DDL,则一定要在两端数据一致时,同时在源端和目标端同时执行 DDL 变更。DDL 变更完成后再执行 DML。
若源端迁移账户不为 superuser,请在迁移对象选择时,不要选择所有对象迁移,在选择迁移对象时,只选择待迁移的数据。不要迁移角色,需要手动在目标端创建用户和角色。
增量迁移时源库 wal_level 参数值必须为 logical。
增量迁移时源库 max_replication_slots 值必须大于待迁移的 database 数量。
增量迁移时源库 max_wal_senders 值必须大于待迁移的 database 数量。
增量迁移时目标库 max_worker_processes 值必须大于 max_logical_replication_workers。
注意:
以上值在设置时,建议将值设置大一些,避免因为源端业务自身也在做逻辑复制,或者备份等任务将 slot 或者 senders 占用掉而致使迁移失败。
目标库的可用空间大小须是源库中待迁移实例的1.2倍以上。(数据增量迁移会执行 update,delete 操作,导致数据库的表产生碎片,因此迁移完成后目标数据库的表存储空间很可能会比源实例的表存储空间大,这主要是因为源端和目标端不同的 autovcauum 触发条件导致)。若源数据库的数据变更并不频繁,则目标库的实际容量也有可能小于源实例。
目标库不能有和源库同名的迁移对象。如要需要迁移角色,也不能有同名的用户。
特殊插件如 timescaledb 、pipelinedb 不支持增量迁移。
源端的插件和目标端的插件不一致时,最好是先将两端插件对齐,避免因为插件不支持导致无法迁移。
大部分插件对迁移过程不会产生影响,但是预检查依然会检查目标端是否存在此插件,若不存在,则在迁移过程中会创建此插件,并发生迁移失败。
源端的迁移用户,一定要具备所有对象的权限,否则会导出数据失败。
源端和目标端关于字符集或部分转换规则建议保持一致,否则会出现查询结果不一样的情况。可参考 参数配置冲突检查,若语言和排序规则为 C ,另一端实例为 UTF8,此类可忽略。
建议源端的表都要有主键,如无主键,迁移效率会降低。并且在极端场景下会出现重复数据。
操作步骤
1. (可选)PostgreSQL 9.4、9.5、9.6 版本作为源数据库进行“全量 + 增量迁移”时,需要参考如下指导安装 tencent_decoding 插件,其他场景请跳过该步骤。
2. 根据源数据库所在服务器的系统架构,下载对应的插件。
只支持系统架构为 x86_64 和 aarch64。
插件版本需要和 PostgreSQL 版本保持一致。
Glibc 版本需要满足要求:x86_64 系统不低于 2.17 - 323 版本,aarch64 系统不低于 2.17 - 260 版本。
在 Linux 系统上查看 Glibc 版本:
RHEL/CentOS: rpm -q glibc
在其他操作系统(Debian/Ubuntu/SUSE 等)上查看 Glibc 版本:
ldd --version | grep -i libc
3. 将下载得到的 tencent_decoding.so 文件放置于 Postgres 进程目录的 lib 文件夹下,无需重启实例。
4. 登录 DTS 控制台,在左侧导航选择数据迁移页,单击新建迁移任务,进入新建迁移任务页面。
5. 在新建迁移任务页面,选择迁移的源实例类型和所属地域,目标实例类型和所属地域,规格等,然后单击立即购买。
配置项 | 说明 |
源实例类型 | 请根据您的源数据库类型选择,购买后不可修改。本场景选择“PostgreSQL”。 |
源实例地域 | 选择源数据库所属地域。如果源库为自建数据库,选择离自建数据库最近的一个地域即可。 |
目标实例类型 | 请根据您的目标数据库类型选择,购买后不可修改。本场景选择“PostgreSQL”。 |
目标实例地域 | 选择目标数据库所属地域。 |
规格 | 根据业务情况选择迁移链路的规格。 |
6. 在设置源和目标数据库页面,完成任务设置、源库设置和目标库设置,测试源库和目标库连通性通过后,单击新建。
说明:
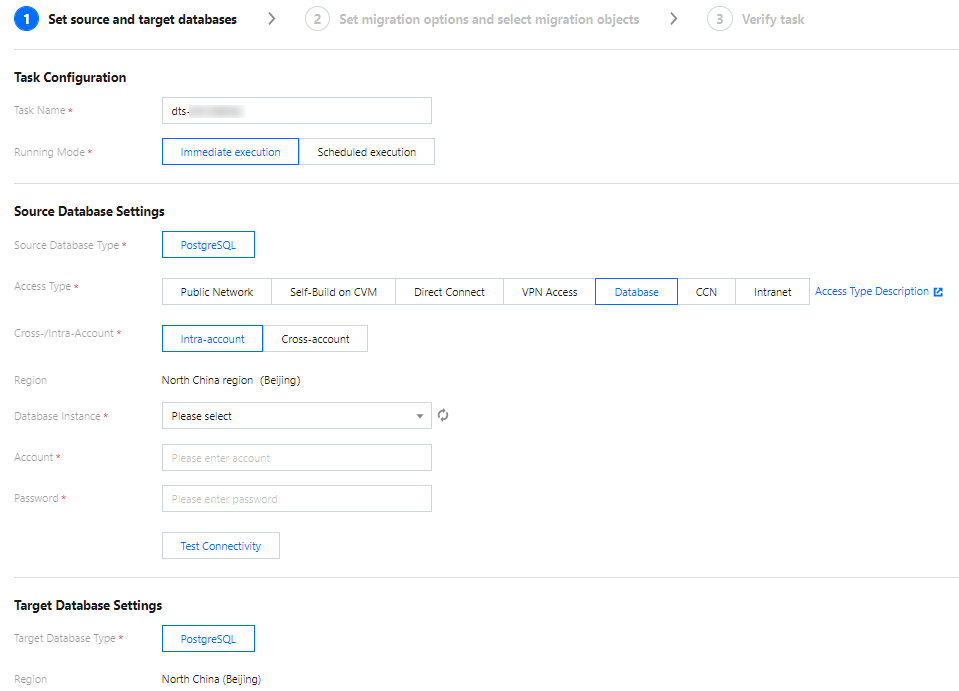
设置类型 | 配置项 | 说明 |
任务设置 | 任务名称 | 设置一个具有业务意义的名称,便于任务识别。 |
| 运行模式 | 立即执行:完成任务校验通过后立即启动任务。 定时执行:需要配置一个任务执行时间,到时间后启动任务。 |
| 标签 | 标签用于从不同维度对资源分类管理。如现有标签不符合您的要求,请前往控制台管理标签。 |
源库设置 | 源库类型 | 购买时选择的源库类型,不可修改。 |
| 所属地域 | 购买时选择的源库地域,不可修改。 |
| 接入类型 | 为保障迁移效率,CVM 自建实例迁移不支持跨地域迁移。如需要跨地域迁移,请选择公网接入方式。 公网:源数据库可以通过公网 IP 访问。 云数据库:源数据库属于腾讯云数据库实例。 |
| 数据库实例 | 选择源库 PostgreSQL 的实例 ID。 |
| 帐号 | 源库 PostgreSQL 的数据库帐号,帐号权限需要满足要求。 |
| 密码 | 源库 PostgreSQL 的数据库帐号的密码。 |
目标库设置 | 目标库类型 | 购买时选择的目标库类型,不可修改。 |
| 所属地域 | 购买时选择的目标库地域,不可修改。 |
| 接入类型 | 根据您的场景选择,本场景默认选择“云数据库”。 |
| 数据库实例 | 选择目标库的实例 ID。 |
| 帐号 | 目标库的数据库帐号,帐号权限需要满足要求。 |
| 密码 | 目标库的数据库帐号的密码。 |
7. 在设置迁移选项及选择迁移对象页面,设置迁移类型、对象,单击保存。
配置项 | 说明 |
迁移类型 | 请根据您的场景选择。 结构迁移:迁移数据库中的库、表等结构化的数据。 全量迁移:迁移整个数据库,迁移数据仅针对任务发起时,源数据库已有的内容,不包括任务发起后源库实时新增的数据写入。 全量 + 增量迁移:迁移数据包括任务发起时源库的已有内容,也包括任务发起后源库实时新增的数据写入。如果迁移过程中源库有数据写入,需要不停机平滑迁移,请选择此场景。 |
迁移对象 | 整个实例:迁移整个实例,但不包括系统库,如postgres中的系统对象,但是会迁移role与用户元数据定义。 指定对象:迁移指定对象。 |
指定对象 | 在源库对象中选择待迁移的对象,然后将其移到已选对象框中。 |
8. 在校验任务页面,进行校验,校验任务通过后,单击启动任务。
如果校验任务不通过,可以参考 校验不通过处理方法 修复问题后重新发起校验任务。
失败:表示校验项检查未通过,任务阻断,需要修复问题后重新执行校验任务。
警告:表示检验项检查不完全符合要求,可以继续任务,但对业务有一定的影响,用户需要根据提示自行评估是忽略警告项还是修复问题再继续。
9. 返回数据迁移任务列表,任务进入准备运行状态,运行1分钟 - 2分钟后,数据迁移任务开始正式启动。
选择结构迁移或者全量迁移:任务完成后会自动结束,不需要手动结束。
选择全量 + 增量迁移:全量迁移完成后会自动进入增量数据同步阶段,增量数据同步不会自动结束,需要您手动单击完成结束增量数据同步。单击完成后任务进入完成中的状态。请不要对源端和目标端进行任何修改,此时后端将自动的将部分对象与源端进行对齐。
请选择合适时间手动完成增量数据同步,并完成业务切换。
观察迁移阶段为增量同步,并显示无延迟状态,将源库停写几分钟。
目标与源库数据差距为0MB及目标与源库时间延迟为0秒时,手动完成增量同步。
10. (可选)如果您需要进行查看任务、删除任务等操作,请单击对应的任务,在操作列进行操作,详情可参考 任务管理。
11. 当迁移任务状态变为任务成功时,即可对业务进行正式割接,更多详情可参考 割接说明。

 是
是
 否
否
本页内容是否解决了您的问题?