This document describes how to use table partitioning in Tencent Cloud TCHouse-P.
Partitioned Table Overview
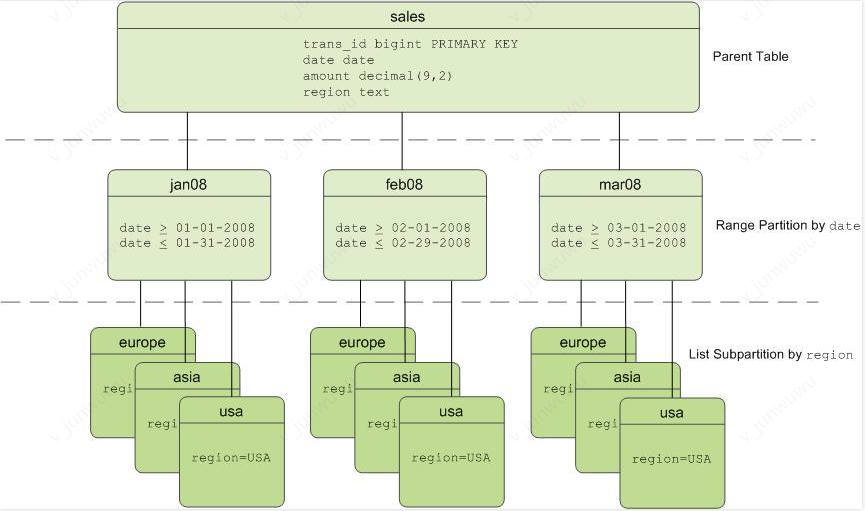
Partitioned tables are small tables imperceptibly divided from a large table, indicating that you can manipulate the large table without caring about which small table the data actually falls into. Tencent Cloud TCHouse-P applies the same table partitioning principle as PostgreSQL, both of which implement table inheritance and constraints.
Below is a sample partitioned table:
Partitioned Table Use Cases
You can consider the following aspects to determine whether to use a partitioned table:
Whether the table data volume is large enough: Partitioning can be used for fact tables with tens to hundreds of millions of data records. There is no absolute criterion for the data volume, and the decision is usually made based on experience and whether you are satisfied with the current performance.
Whether the table has suitable partition fields: If the data volume is large enough, you need to look for suitable fields that can be used for partitioning. Ideally, you can use time dimensions such as day and month if present.
Whether the data in the table has a lifecycle: The data in the data warehouse will not be stored forever and generally has a lifecycle, such as data in the past year. This involves the management of legacy data. If there is a partitioned table, it will be easy to delete legacy data or archive it to a cheaper storage medium such as COS.
Whether the query statement contains partition fields: If a table is partitioned, but none queries contain partition fields, the performance will be lowered rather than improved, because all partitioned tables will be scanned for all queries.
Creating Partitioned Table
Range partition
List partition
A combination of both types
Range partition example:
CREATE TABLE test_range_partition
(
uid int,
fdate character varying(32)
)
PARTITION BY RANGE(fdate)
(
PARTITION p1 START ('2018-11-01') INCLUSIVE END ('2018-11-02') EXCLUSIVE,
PARTITION p2 START ('2018-11-02') INCLUSIVE END ('2018-11-03') EXCLUSIVE,
DEFAULT PARTITION pdefault
);
The above example creates a table by day. If the time span is large, the table creation statement will be very long and inconvenient to write. In this case, you can use the following syntax:
CREATE TABLE test_range_partition_every_1
(
uid int,
fdate date
)
partition by range (fdate)
(
PARTITION pn START ('2018-11-01'::date) END ('2018-12-01'::date) EVERY ('1 day'::interval),
DEFAULT PARTITION pdefault
);
List partition example:
CREATE TABLE test_list_partition
(
uid int,
gender char(1)
)
PARTITION BY LIST (gender)
(
PARTITION girls VALUES ('F'),
PARTITION boys VALUES ('M'),
DEFAULT PARTITION pdefault
);
Managing Partitioned Table
Just like a common table, a partitioned table supports many operations as listed below, among others:
Clearing partition
ALTER TABLE test_range_partition TRUNCATE PARTITION p1;
Dropping partition
ALTER TABLE test_range_partition DROP PARTITION p1;
Note:
DROP PARTITION is followed by the partition name, not the partitioned table name. There is a difference between the two. If the partitioned table is created by using the EVERY syntax, you need to query the name of the particular partition through the pg_partitions table.
ALTER TABLE test_range_partition ADD PARTITION p3 START ('2018-11-03') INCLUSIVE END ('2018-11-04') EXCLUSIVE;
Note:
If the partitioned table contains the DEFAULT partition, the following error will occur: ERROR: cannot add RANGE partition "p3" to relation "test_range_partition" with DEFAULT partition "pdefault". You can see Rolling Partition for solution.
Rolling Partition
In tables partitioned by time, partitions usually keep rolling forward. For example, if a table is partitioned by day to save data in the past ten days, the partition created ten days ago will be deleted every day, and a new partition will be created to store the latest data.
If there is a default partition, you can use partition split.
ALTER TABLE test_range_partition SPLIT DEFAULT PARTITION START ('2018-11-03') INCLUSIVE END ('2018-11-04') EXCLUSIVE INTO (PARTITION p3, DEFAULT partition);
In this way, the new partition is added, while the default partition is retained. Then, the replacement of the old and new partitions can be completed when the old partition is deleted.
Exchanging Partition
Exchanging partition is to exchange a common table with a partitioned table. This feature is very useful in tiered data storage.
For example, if you need to set partitions according to different COS directories, you can use partition exchanging to implement this, so that less queried historical data in a large table can be placed in COS. The syntax is as follows:
ALTER TABLE {table_name} EXCHANGE PARTITION {partition_name|FOR (RANK(number))|FOR (value)} WITH TABLE {cos_table_name} WITHOUT VALIDATION;
Querying partition
System tables or views related to partitions are as follows:
pg_partition
pg_partition_columns
pg_partition_encoding
pg_partition_rule
pg_partition_templates
pg_partitions
Viewing partition information
t2=# select * from pg_partitions where partitiontablename = 'test_range_partition_1_prt_p1';
-[ RECORD 1]------------+---------------------------------------------------------------------------------------------------
-[ RECORD 1]--------+---------------------------------------------------------------------------------------------------------------
pg_get_partition_def | PARTITION BY RANGE(fdate)
|(
| PARTITION p1 START ('2018-11-01'::character varying(32)) END ('2018-11-02'::character varying(32)),
| PARTITION p2 START ('2018-11-03'::character varying(32)) END ('2018-11-04'::character varying(32)),
| DEFAULT PARTITION pdefault
|)
Best Practices for Partitioned Table
Partition granularity
Range partitioned tables usually involves granularity selection, such as partitioning by day, week, or month. The finer the granularity, the less data per table, but the more the partitioned tables, and vice versa.
There is no absolute criterion for the number of partitioned tables. Generally, 100 is a high number in this regard.
If there are too many partitioned tables, various problems will occur; for example, the query optimizer will be slower to generate execution plans, and many maintenance tasks will also become slower, such as vacuuming, segment recovering, cluster scaling, and disk usage checking.
Query statement
In order to take full advantage of table partitioning, it is better to include a partition condition in a query statement. The ultimate goal is to scan as few partitioned tables as possible.