操作场景
TDMQ RocketMQ 支持监控您账户下创建的资源,包括集群、Topic、Group 等,您可以根据这些监控数据,分析集群的使用情况,针对可能存在的风险及时处理。同时您也可以对监控项设置报警规则,以便数据异常时收到报警消息,及时处理风险,保障系统的稳定运行。
监控指标
TDMQ RocketMQ 版支持的监控指标如下:
指标 | 单位 | 备注 | 指标支持维度 |
总 TPS | Count/s | 集群、Topic | |
生产 TPS | Count/s | 集群、Topic | |
消费 TPS | Count/s | 集群、Topic、Group | |
消息存储空间 | GB | | 集群、Topic |
消息堆积条数 | Count/s | | 集群、Topic、Group、Topic&Group |
被限流的生产 TPS | Count/s | | 集群、Topic |
被限流的消费 TPS | Count/s | | 集群、Topic、Group |
生产消息条数 | Count/s | | 集群、Topic |
消费消息条数 | Count/s | | 集群、Topic、Group |
生产消息流量 | MB/s | | 集群、Topic |
消费消息流量 | MB/s | | 集群、Topic、Group |
生产者数量 | Count | 仅统计在线的生产者客户端 | 集群、Topic |
生产成功率 | % | | 集群、Topic |
生产消息平均耗时(发送RT) | ms | 使用 SDK 调用发送消息接口成功的耗时,即生产消息的 RT,仅 5.x 客户端能采集到该指标 | 集群、Topic |
消息平均大小 | Bytes | | 集群、Topic |
各类型消息数量变化 | Count | | 集群 |
每秒被保存的死信消息条数 | Count | 每秒新增的状态为 DLQ 的消息数量,表示消息达最大重试次数后依旧消费失败,但是保存到指定Topic 的消息数 | 集群、Topic、Group、Topic&Group |
已就绪消息的排队时间 | ms | 最早一条已就绪消息的就绪时间和当前时刻的时间差,反映了消费者拉取消息的及时性 | 集群、Topic、Group、Topic&Group |
处理中的消息数 | Count | 状态为 Inflight 的消息数量,表示消息在服务端消费,还未返回消费结果的消息数量 | 集群、Topic、Group、Topic&Group |
已就绪消息的排队时间 | ms | 最早一条已就绪消息的就绪时间和当前时刻的时间差,反映了消费者拉取消息的及时性 | 集群、Topic、Group、Topic&Group |
消费处理滞后时间 | ms | 最早一条未返回响应的消息的就绪时间和当前时刻的时间差,反映了消费者完成消费消息的及时性 | 集群、Topic、Group、Topic&Group |
本地缓存队列中的平均排队时间 | ms | 仅展示 5.x 版本的PushConsumer客户端的数据,SimpleConsumer客户端没有缓存队列 | 集群、Topic、Group、Topic&Group |
消费消息平均耗时(发送RT) | ms | 使用 SDK 调用发送消息接口成功的耗时,即生产消息的 RT,仅 5.x 客户端能采集到该指标 | 集群、Topic、Group、Topic&Group、消费者客户端 |
重试消息条数 | Count | | Topic、Group、Topic&Group |
消费耗时分布 | - | 不同消费消息耗时范围的热力分布图(仅专业版和铂金版) | 集群、Topic、Group、Topic&Group、消费者客户端 |
生产耗时分布 | - | 不同生产消息耗时范围的热力分布图(仅专业版和铂金版) | 集群、Topic |
生产消息大小分布 | - | 不同消息大小的热力分布图(仅专业版和铂金版) | 集群、Topic |
公网流出/入流量 | MB/s | | 集群 |
公网流出/入带宽 | Mbps/s | | 集群 |
公网流出/入带宽利用率 | % | | 集群 |
公网丢弃出/入带宽 | Mbps/s | | 集群 |
查看监控数据
1. 登录 RocketMQ 控制台。
2. 在左侧导航栏单击监控大盘,选择好地域和要查看的集群。
3. 在监控页面选择要查看的资源页签,设置好时间范围后,查看对应的监控数据。
图标 | 说明 |
 | 单击可调整图表时间粒度,支持1分钟、5分钟和1小时。 |
 | 单击可刷新获取最新的监控数据,支持设置30s、1min和5min时间间隔自动刷新监控数据。 |
 |
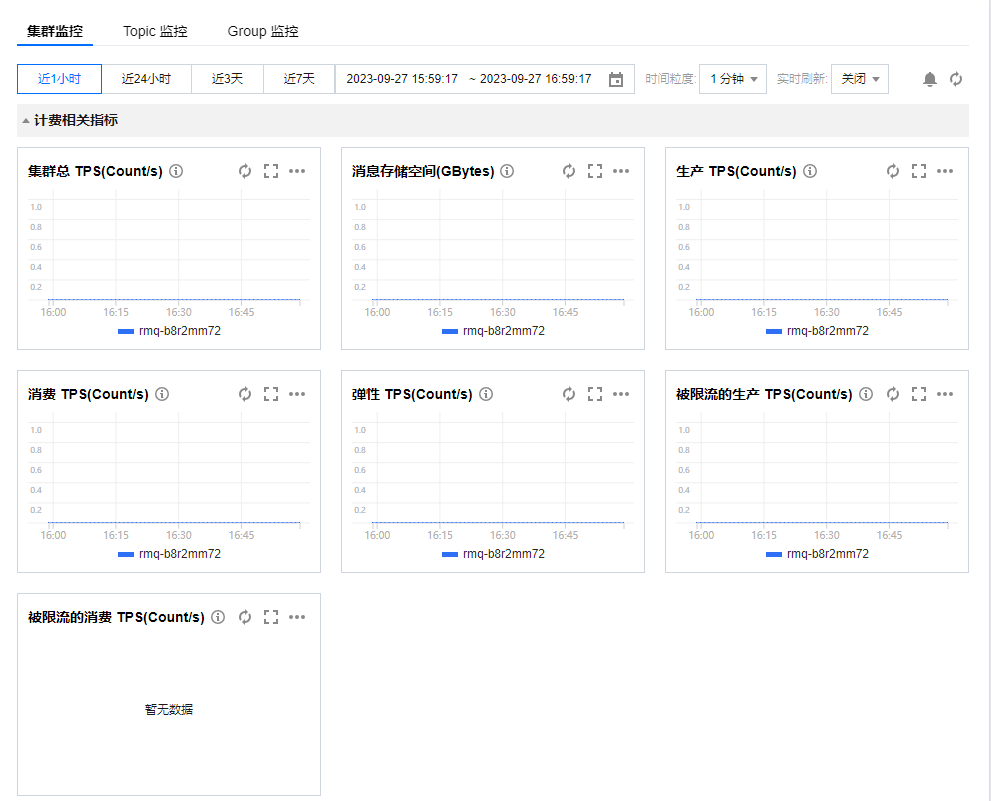
在集群监控页面,您可以选择集群内的多个 Topic,查看多个 Topic 的指标对比,如下图所示。
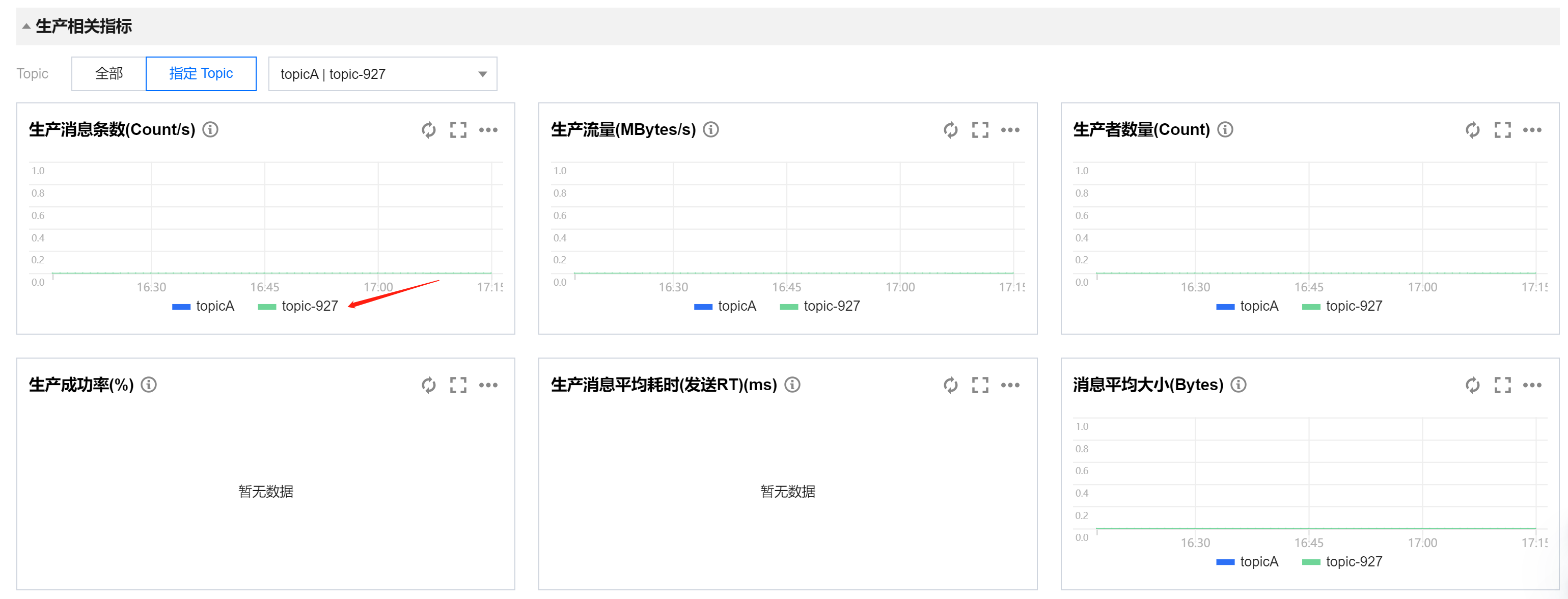
同理,您可以查看某个Topic下,订阅关系内的多个 Group 的相关指标对比;也可以查看某个 Group 下,订阅关系内的多个 Topic 的相关指标对比。
配置告警规则
新建告警规则
您可以为监控指标配置告警规则,当监控指标达到设定的报警阈值时,腾讯云可观测平台可以通过邮件、短信、微信、电话等方式通知您,帮助您及时应对异常情况。
1. 在集群的监控页面,单击下图告警按钮跳转至 腾讯云可观测平台控制台 配置告警策略。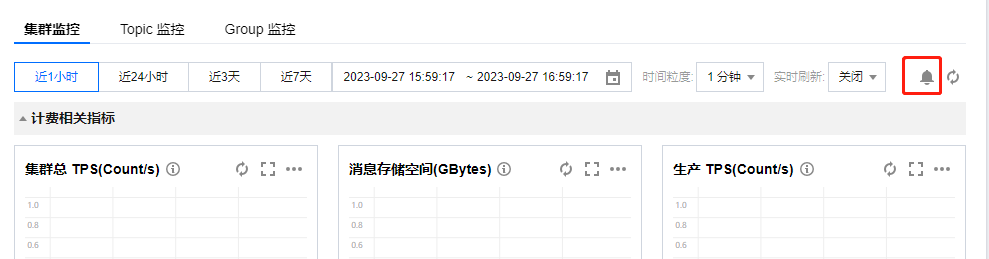
2. 在告警策略页面,选择好策略类型和要设置告警的实例,设置好告警规则和告警通知模板。
策略类型:选择消息队列 TDMQ/RocketMQ5集群。
告警对象:选择需要配置告警策略的 RocketMQ 实例。
触发条件:支持选择模板和手动配置,默认选择手动配置,手动配置参见以下说明,新建模板参见 新建触发条件模板。
说明:
指标:例如“消息生产条数TPS”,选择统计粒度为1分钟,则在1分钟内,消息生产条数TPS连续N个数据点超过阈值,就会触发告警。
告警频次:例如“每30分钟警告一次”,指每30分钟内,连续多个统计周期指标都超过了阈值,如果有一次告警,30分钟内就不会再次进行告警,直到下一个30分钟,如果指标依然超过阈值,才会再次告警。
通知模板:选择通知模板,也可以新建通知模板,设置告警接收对象和接收渠道。
3. 单击完成,完成配置。
说明:
新建触发条件模板
1. 登录 腾讯云可观测平台控制台。
2. 在配置告警规则中,单击选择模板 > 新增触发条件模板,进入触发条件列表页面。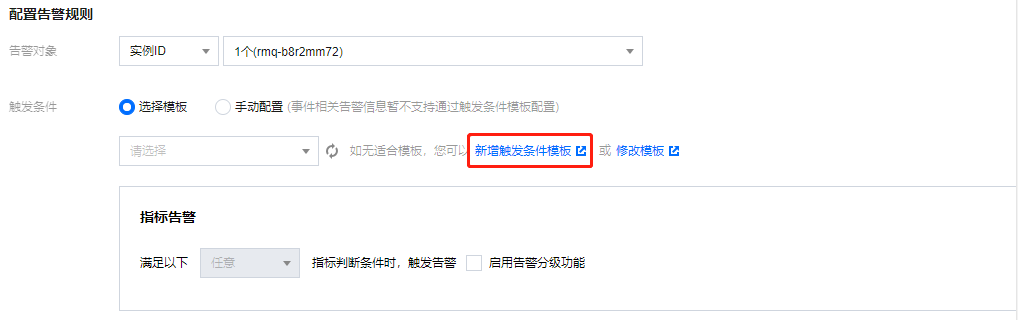
3. 在触发条件模板页单击新建触发条件模板。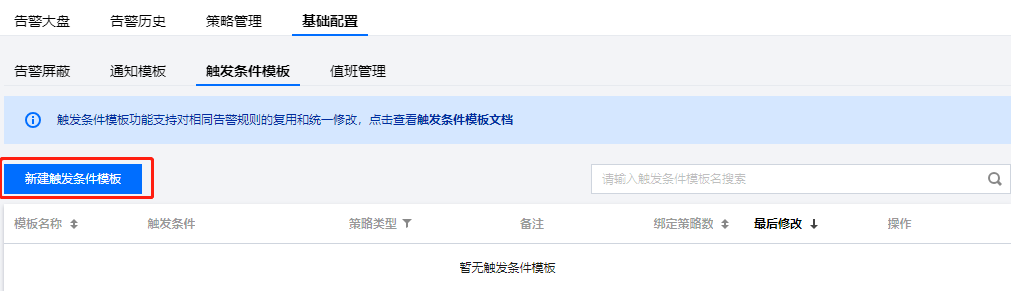
4. 在新建模板页,配置策略类型。
策略类型:选择消息队列 TDMQ/RocketMQ5。
触发条件:勾选此选项,会出现系统建议的告警策略。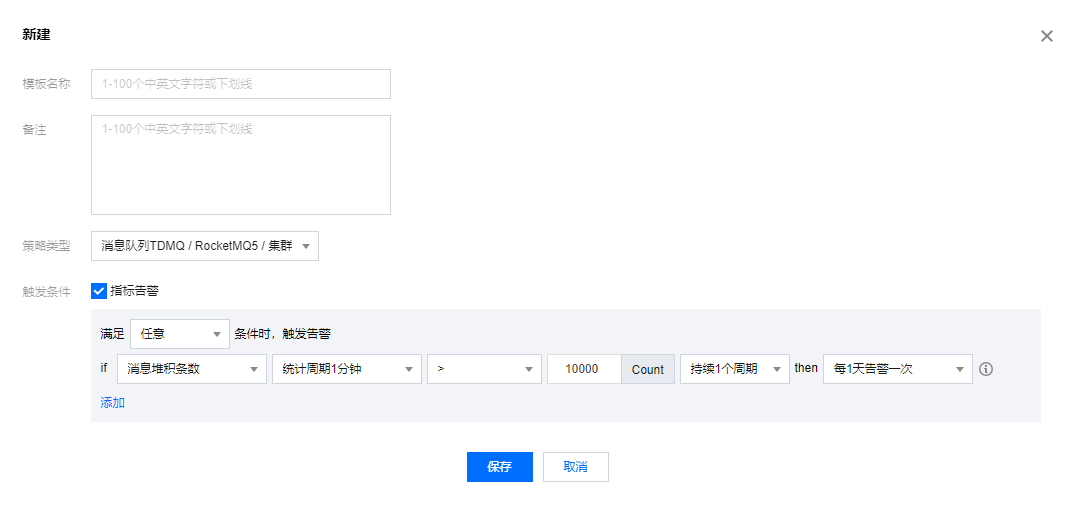
5. 确认无误后,单击保存。
6. 返回新建告警策略页,单击刷新,就会出现刚配置的告警策略模板。
对接云监控 Prometheus
如果您使用了腾讯云可观测平台,并使用了 Prometheus 实例,您可以通过 Prometheus 实例监控腾讯云 RocketMQ。
1. 登录 Prometheus 监控控制台,在实例列表中,选择对应的 Prometheus 实例。
2. 进入实例详情页,选择 数据采集,再点击 集成中心。
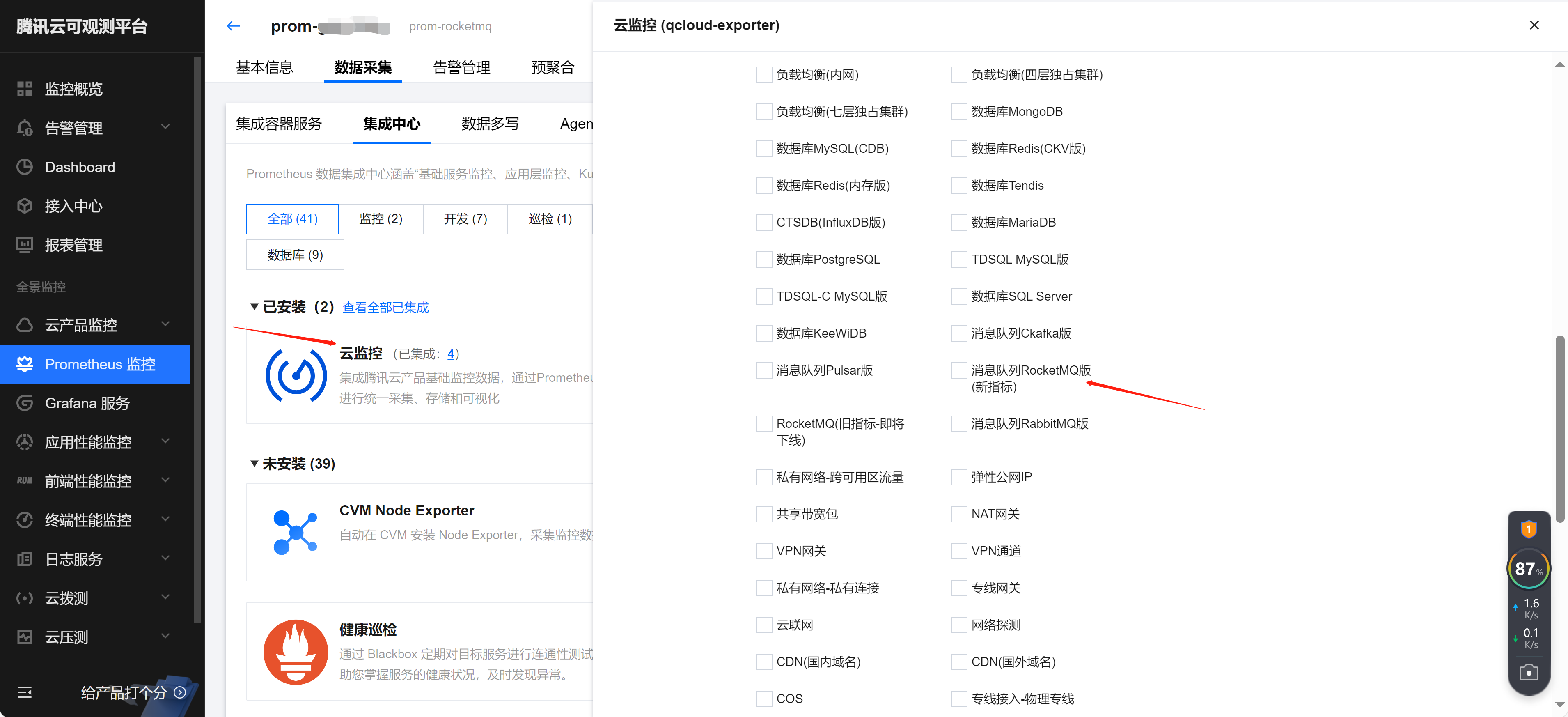
3. 选择 云监控,可以直接点击 一键安装。如果您只需要查看 RocketMQ 的监控数据,如下图所示,您可以在“云产品选择” 处选择 消息队列RocketMQ版(新指标),同时填写其他相关信息,如名称、地域等等。详细操作步骤可以查看Prometheus 集成中心。

 是
是
 否
否
本页内容是否解决了您的问题?