In a production system, a high-availability scheme is usually required to ensure continuous operation of the system. As a database is the core of system data storage and service, its availability requirement is higher than that of computing services. Currently, in most database high-availability schemes, multiple databases are used together, so that whenever a database fails, another one can immediately take its place to eliminate or minimize service interruption; or, multiple databases provide services at the same time, so that users can access any of them, and whenever a database fails, access requests will be immediately directed to another one.
As a database records data in it, to switch between multiple databases, the data in them must be synchronous. Therefore, data sync is the foundation of database high-availability scheme. Currently, data replication can be implemented in the following three modes:
Async replication: an application initiates an update request such as adding, deletion, or modification. After completing the corresponding operation, the primary node (primary) responds to the application immediately and replicates data to the replica node (replica) asynchronously. Therefore, in async replication mode, an unavailable replica does not affect operations on the primary database, while an unavailable primary may cause data inconsistency.
Strong sync replication: an application initiates an update request. After completing the operation, the primary replicates data to the replica immediately. After receiving the data, the replica returns a success message to the primary. Only after receiving the message from the replica will the primary respond to the application. The data is replicated synchronously from the primary to the replica. Therefore, an unavailable replica will affect operations on the primary database, while an unavailable primary will not cause data inconsistency.
Note:
When you perform strong sync replication, the primary database will be hanged if it is disconnected from the replica database or the replica database fails. If there is only one primary or replica database, the high-availability scheme is unavailable, because if only one single server is used, part of data will be lost completely when a failure occurs, which does not meet the requirements for finance-level data security.
Semi-sync replication: proposed by Google, this sync method works in the following way: generally, strong sync replication is employed. When an exception occurs with the data replication from the primary to the replica (for example, the replica becomes unavailable or an exception occurs with the network connection between the two nodes), the replication will be downgraded to async replication. When the replication returns to a normal state, strong sync replication will be restored from async replication. In semi-sync replication, there is a slight chance that a primary failure may cause data inconsistency.
Commonly used high-availability architectures
Shared storage scheme: shared storage such as SAN storage is used. In SAN, multiple database servers share the same storage region, so that they can read/write the same copy of data. When the primary database fails, a third-party high-availability application can mount the file system to a replica database and start the replica to complete primary/replica switch.
Log sync or streaming replication sync: this is the most common database replication mode for various databases such as MySQL. Whenever data is written, MySQL primary server will transfer its binary logs to the replica through the replication thread; then, the replica will write the same data as in the binary logs to the file system. Currently, MySQL provides the following replication modes:
Async replication: async replication ensures quick response but cannot guarantee that binary logs actually arrive at the replica, i.e., data consistency cannot be guaranteed.
Semi-sync replication (sync plugin provided by Google): semi-sync replication has slower response to client requests and may downgrade to async replication in cases such as timeout. It can guarantee basic but not complete data consistency
Trigger-based sync: a trigger is used to record data changes which are then synced to another database.
Middleware-based sync: the system is connected to a middleware program instead of multiple underlying databases, which sends data changes to underlying databases for data sync. In earlier years, due to issues such as business requirements, database performance, and sync mechanisms, some software developers usually used this architecture or similar ones.
TencentDB for MariaDB Architecture Overview
Multi-thread asynchronous replication
In the development of sync technology, schemes such as async and semi-sync replication emerged. These two schemes are oriented to general users and can ensure basic data sync when the user requirements are not high, network condition is good, and performance pressure is low. However, they generally tend to cause data inconsistency, which directly affects system reliability and even leads to transaction data loss, thus incurring direct or indirect economic loss.
Backed by many years' experience in business operations, Tencent Cloud has developed an MAR (Multi-thread Async Replication) scheme for database sync. MAR outperforms the NDB engine of Oracle, Percona XtraDB Cluster, and MariaDB Galera Cluster in terms of performance, efficiency, and availability. The MAR strong sync scheme has the following advantages:
Consistent sync replication ensures strong consistency of data between nodes.
Complete transparency to the service. Read/write separation or synchronization enhancement is not required for the service.
Asynchronization of serial sync threads and introduction of thread pool boost a substantial increase in performance.
Cluster architecture is supported.
Automatic member control is supported and faulty nodes are automatically removed from the cluster.
Nodes can be automatically added without human intervention.
Each node contains a complete replica of the data and the primary and replica nodes can switch at any time.
There is no need to share storage devices.
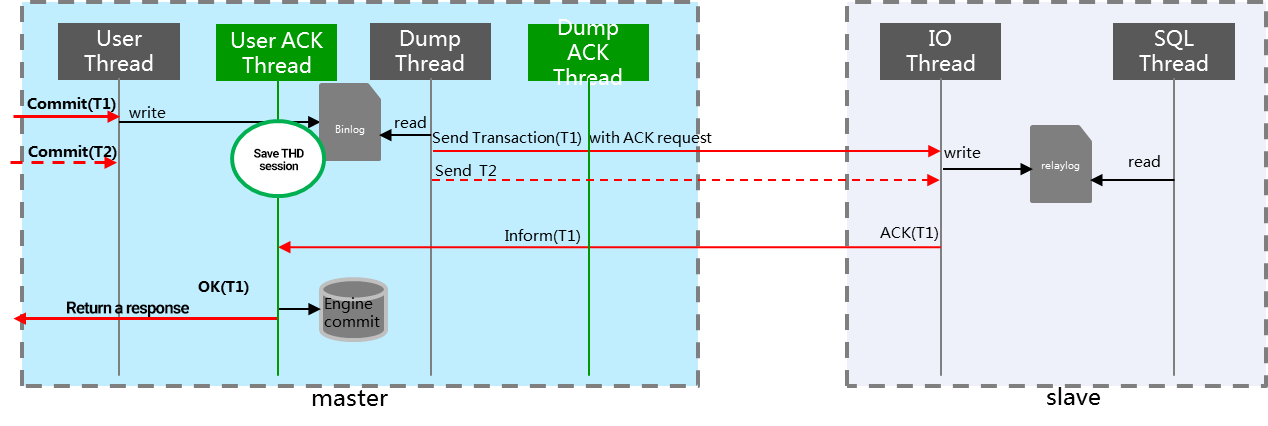
With the MAR strong sync technology of Tencent, the primary will return a transaction response to the application only after data is synced to the replica as shown below:
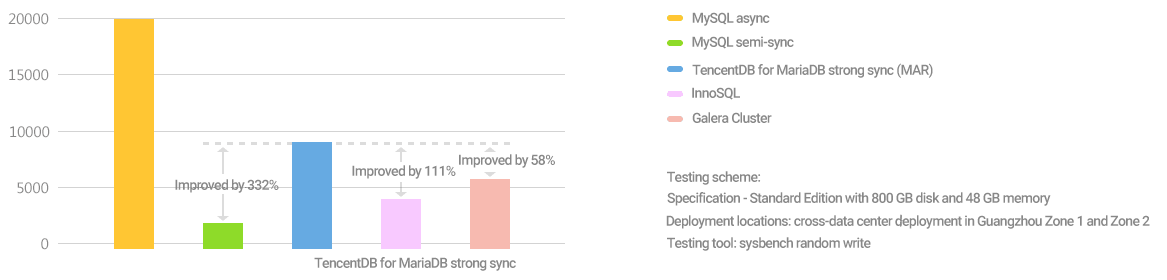
Its performance is higher than that of other mainstream sync schemes. Tests in the same cross-AZ (cross-IDC) testing configuration (with the standard sysbench use case) show that the performance of MAR is about 5 times higher than that of MySQL semi-sync replication and 1.5 times higher than that of MariaDB Galera Cluster.
Cluster architecture
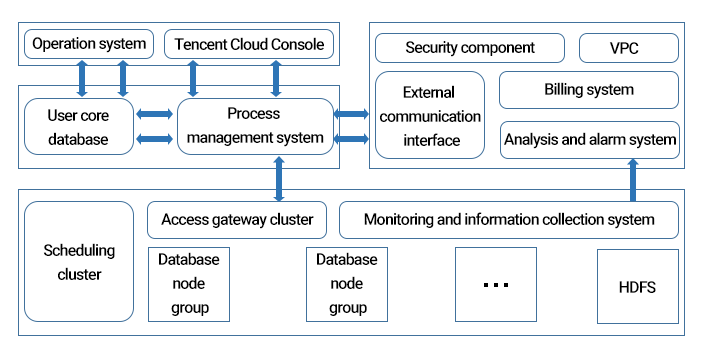
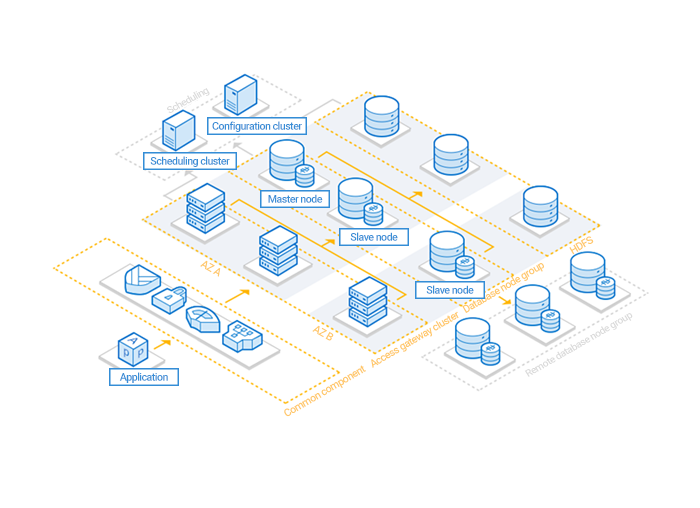
TencentDB for MariaDB adopts a cluster architecture. A set of independent TencentDB for MariaDB system consists of at least 10 systems or components as shown below:
The three most important modules in TencentDB for MariaDB are scheduling cluster (Tschedule), database node group (SET), and access gateway cluster (TProxy), and they communicate with one another through the configuration cluster (TzooKeeper).
Database node group (SET): it consists of the engine compatible with MySQL and monitoring and information collection tool (Tagent). It uses an architecture of "one primary node (Primary, several replica nodes (Replica_n), and several remote backup nodes (Watcher_n)". Generally:
It is deployed in cross-rack and cross-data center servers.
It uses the heartbeat monitoring and information collection module (Tagent) for monitoring to ensure cluster robustness.
In a distributed architecture and based on horizontal sharding, several shards (database node groups) provide a "logically unified and physically scattered" distributed database instance.
Scheduling cluster (Tschedule): this acts as the cluster management scheduling center and is mainly used to manage the normal operations of SET and record and distribute global database configurations. It includes the following components:
Scheduling job cluster (MariaDB Scheduler): it helps the DBA or database users automatically schedule and run various types of jobs, such as database backup, monitoring data collection, generation of different reports, and execution of business flows. TencentDB for MariaDB combines Schedule, ZooKeeper, and operations support system (OSS) to activate specified resource plans through time windows, so as to fulfill various complex requirements of database resource management and job scheduling. Oracle uses DBMS_SCHEDULER to support similar capabilities.
Program coordination and configuration cluster (TzooKeeper): it provides features such as configuration maintenance, election decision-making, and route sync for TencentDB for MariaDB, supports tasks like creation, deletion, and replacement for database node groups (shards), and uniformly delivers and schedules all Data Definition Language (DDL) operations. At least three TzooKeepers need to be deployed.
Operations support system (OSS): it is a comprehensive custom business operations and management platform developed based on MariaDB. It fully takes into account database management characteristics to organically integrate network management, system management, and monitoring service.
The scheduling cluster (Tschedule) is independently deployed in the three major Tencent Cloud data centers in China (with cross-data center deployment and remote disaster recovery).
Access gateway cluster (TProxy): this manages SQL parsing and assigns routes at the network layer (it is not TGW).
The number of deployed TProxies should be the same as that of database engines. TProxy is used to share the load and implement disaster recovery.
It pulls the status of database nodes (shards) from the configuration cluster (TzooKeeper), provides shard routes, and implements imperceptible reads/writes.
It records and monitors SQL execution and user access information, analyzes SQL execution efficiency, and performs security authentication to block risky operations.
TGW is deployed on the frontend of TProxy and provides a unique virtual IP to users.
This architecture greatly simplifies the communication mechanism between each node and lowers the hardware requirements, which means that even simple x86 servers can be used to set up stable and reliable databases similar to minicomputers or shared storage.