- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 控制台指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Media Processing APIs
- Parameter Template APIs
- CreateTranscodeTemplate
- CreateWatermarkTemplate
- CreateAnimatedGraphicsTemplate
- CreateSnapshotByTimeOffsetTemplate
- CreateSampleSnapshotTemplate
- CreateImageSpriteTemplate
- CreateAdaptiveDynamicStreamingTemplate
- CreateContentReviewTemplate
- CreateAIAnalysisTemplate
- CreateAIRecognitionTemplate
- CreateQualityControlTemplate
- CreateLiveRecordTemplate
- DeleteTranscodeTemplate
- DeleteWatermarkTemplate
- DeleteAnimatedGraphicsTemplate
- DeleteSnapshotByTimeOffsetTemplate
- DeleteSampleSnapshotTemplate
- DeleteImageSpriteTemplate
- DeleteAdaptiveDynamicStreamingTemplate
- DeleteQualityControlTemplate
- DeleteContentReviewTemplate
- DeleteAIAnalysisTemplate
- DeleteAIRecognitionTemplate
- DeleteLiveRecordTemplate
- DescribeTranscodeTemplates
- DescribeQualityControlTemplates
- DescribeWatermarkTemplates
- DescribeAnimatedGraphicsTemplates
- DescribeSnapshotByTimeOffsetTemplates
- DescribeSampleSnapshotTemplates
- DescribeImageSpriteTemplates
- DescribeAdaptiveDynamicStreamingTemplates
- DescribeContentReviewTemplates
- DescribeAIAnalysisTemplates
- DescribeAIRecognitionTemplates
- DescribeLiveRecordTemplates
- ModifyQualityControlTemplate
- ModifyTranscodeTemplate
- ModifyWatermarkTemplate
- ModifyAnimatedGraphicsTemplate
- ModifySnapshotByTimeOffsetTemplate
- ModifySampleSnapshotTemplate
- ModifyImageSpriteTemplate
- ModifyAdaptiveDynamicStreamingTemplate
- ModifyContentReviewTemplate
- ModifyAIAnalysisTemplate
- ModifyAIRecognitionTemplate
- ModifyLiveRecordTemplate
- AI-based Sample Management APIs
- Workflow Management APIs
- Task Management APIs
- StreamLink Input Security Group Management APIs
- Parse Notification APIs
- Other APIs
- Data Types
- Error Codes
- 常见问题
- 相关协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 控制台指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Media Processing APIs
- Parameter Template APIs
- CreateTranscodeTemplate
- CreateWatermarkTemplate
- CreateAnimatedGraphicsTemplate
- CreateSnapshotByTimeOffsetTemplate
- CreateSampleSnapshotTemplate
- CreateImageSpriteTemplate
- CreateAdaptiveDynamicStreamingTemplate
- CreateContentReviewTemplate
- CreateAIAnalysisTemplate
- CreateAIRecognitionTemplate
- CreateQualityControlTemplate
- CreateLiveRecordTemplate
- DeleteTranscodeTemplate
- DeleteWatermarkTemplate
- DeleteAnimatedGraphicsTemplate
- DeleteSnapshotByTimeOffsetTemplate
- DeleteSampleSnapshotTemplate
- DeleteImageSpriteTemplate
- DeleteAdaptiveDynamicStreamingTemplate
- DeleteQualityControlTemplate
- DeleteContentReviewTemplate
- DeleteAIAnalysisTemplate
- DeleteAIRecognitionTemplate
- DeleteLiveRecordTemplate
- DescribeTranscodeTemplates
- DescribeQualityControlTemplates
- DescribeWatermarkTemplates
- DescribeAnimatedGraphicsTemplates
- DescribeSnapshotByTimeOffsetTemplates
- DescribeSampleSnapshotTemplates
- DescribeImageSpriteTemplates
- DescribeAdaptiveDynamicStreamingTemplates
- DescribeContentReviewTemplates
- DescribeAIAnalysisTemplates
- DescribeAIRecognitionTemplates
- DescribeLiveRecordTemplates
- ModifyQualityControlTemplate
- ModifyTranscodeTemplate
- ModifyWatermarkTemplate
- ModifyAnimatedGraphicsTemplate
- ModifySnapshotByTimeOffsetTemplate
- ModifySampleSnapshotTemplate
- ModifyImageSpriteTemplate
- ModifyAdaptiveDynamicStreamingTemplate
- ModifyContentReviewTemplate
- ModifyAIAnalysisTemplate
- ModifyAIRecognitionTemplate
- ModifyLiveRecordTemplate
- AI-based Sample Management APIs
- Workflow Management APIs
- Task Management APIs
- StreamLink Input Security Group Management APIs
- Parse Notification APIs
- Other APIs
- Data Types
- Error Codes
- 常见问题
- 相关协议
- 联系我们
- 词汇表
媒体处理将音视频文件转码为不同码率和分辨率的格式,以满足不同网络带宽和终端设备的用户需求。支持以下功能:
音视频转码

转码是将原始音视频码流转换成另一个音视频码流的过程,是一种离线任务。通过转码,可以改变原始码流的编码格式、分辨率和码率等参数,从而适应不同终端和网络环境的播放。通过转码功能可以实现:
可实现功能 | 说明 |
适配更多终端 | 将原始视频转码成拥有更强的终端适配能力的格式(如 MP4),使视频资源能够在更多设备上播放。 |
适配不同带宽 | 将视频转换成流畅、标清、高清及超清等输出,用户可以根据当前网络环境选择合适码率的视频播放。 |
改善播放效率 | 转码可以将 MP4 位于尾部的元信息 MOOV 提前到头部,播放器无需下载完整视频即可立即播放。 |
节省带宽 | 采用更先进的编码方式(如 H.265)转码,在不损失原始画质的情况下显著降低码率,节省播放带宽。 |
转码的目标规格包含编码格式、分辨率和码率等参数。您可自定义以下转码相关参数。
参数 | 类型 | 详细说明 |
输入格式 | 封装格式 | 3GP、AVI、FLV、MP4、M3U8、MPG、ASF、WMV、MKV、MOV、TS、WebM、MXF。 |
| 视频编码格式 | AV1、AVS2、H.264/AVC、H.263、 H.263+、H.265、MPEG-1、MPEG-2、MPEG-4、MJPEG、VP8、VP9、RealVideo、Windows Media Video、Quicktime。 |
| 音频编码格式 | AAC、ADPCM、AMR、DSD、MP1、MP2、MP3、PCM、RealAudio、Windows Media Audio、VORBIS、AC-3。 |
输出格式 | 封装格式 | 视频:FLV、MP4、HLS(m3u8+ts)、MXF。 |
| | 音频:MP3、MP4、OGG、FLAC、m4a。 |
| | 图片:GIF、WEBP。 |
| 视频编码格式 | H.264/AVC、 H.265/HEVC、AV1。 |
| 音频编码格式 | MP3、AAC、FLAC、MP2、VORBIS。 |
封装 | 删除视频流 | 如果开启“删除视频流”,转码出来的视频将不包含视频流(仅保留音频流)。 |
| 删除音频流 | 如果开启“删除音频流”,转码出来的视频将不包含音频流(仅保留视频流)。 |
音视频增强
基于 MPS 业界领先的音视频 AI 处理模型和丰富的业务数据积累,音视频增强功能可以大幅提升音频和视频质量,广泛应用在 OTT、电商、赛事等场景,带来QoE、QoS 提升等业务收益。
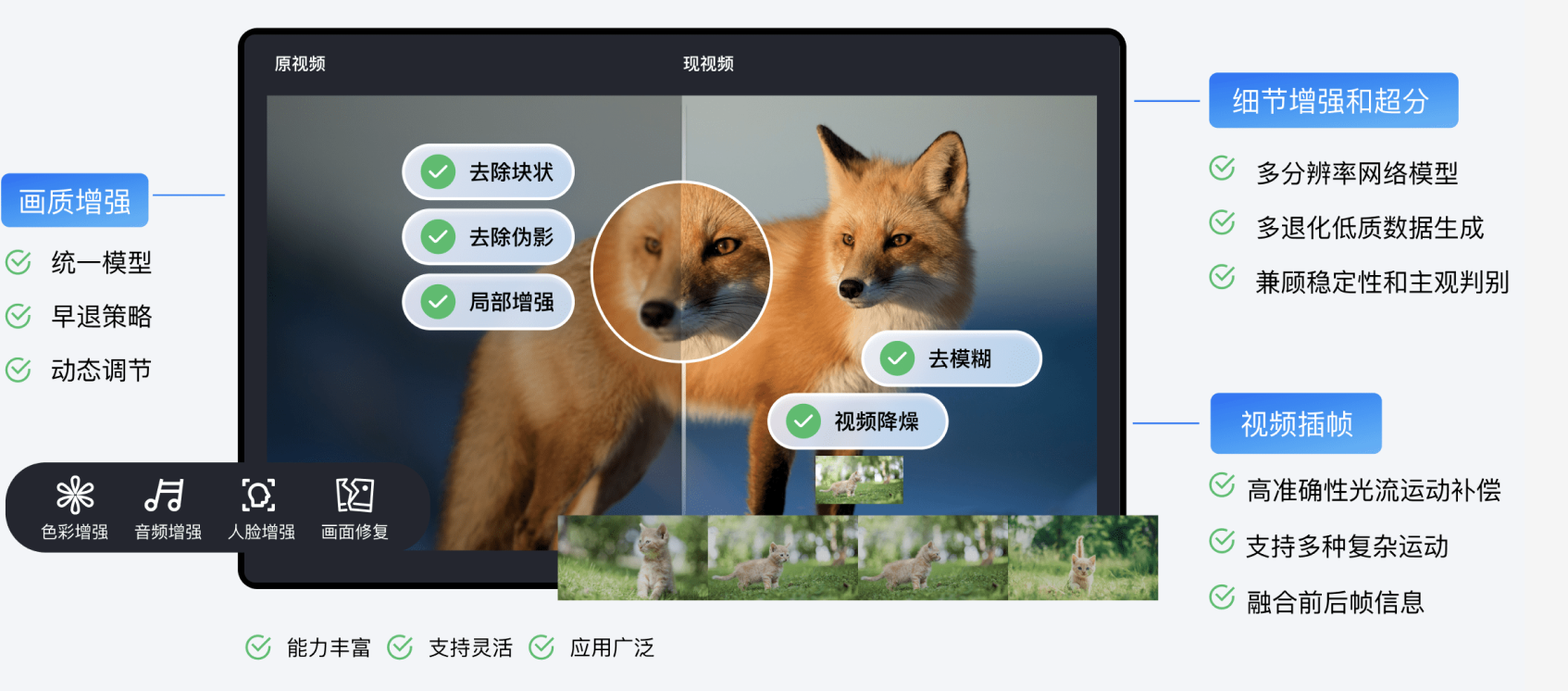
增强类型 | 能力 | 说明 |
视频增强 | 超分辨率 | 超分辨率可以识别视频的内容与轮廓,高清重建视频的细节与局部特征,将低分辨率的视频转换为高分辨率的视频,适用于老片修复等场景。 |
| 低光照增强 | 因环境状况及拍摄摄像头的硬件限制,在某些场景下拍摄的画面存在亮度和对比度缺失问题,导致画面较暗或细节缺失。通过开启低光照增强,可以大幅提升暗区的细节和对比度,提升人眼主观质量。 |
| HDR | 支持 HDR10、HLG,能够获得更宽的色域,展现更多色彩细节,以提供更高品质的视频内容。 |
| 综合增强 | 通过 AI 的综合分析能力,自动平衡画面中的纹理内容,在去除压缩伪影和毛刺的同时增强关键细节,从而提高整个画面的总体主观感受。 |
| 色彩增强 | 色彩增强可以使画面更接近真实色彩,并在一定程度上进行增强满足人眼的喜好。 |
| 细节增强 | 细节增强对视频中需要关注的细节(例如赛场草地)进行增强,使画面内容更清晰,内容更丰富。 |
| 人脸增强 | 通过人脸检测针对视频中人眼视觉特别关注的人脸部分进行增强,使该区域的细节更加清晰,提高主观感受。 |
| 去划痕 | 去划痕可以修复视频中的划痕和雪花点等破坏的内容。 |
| 去毛刺(去伪影) | 由于影片在转码或多次转码过程中对视频进行了多次压缩,会引入块效应、振铃效应、色度渗透和蚊噪等,使得视频画面出现一些影响视觉效果的失真,去压缩失真能有效修复编码引入的失真。 |
| 视频降噪 | 由于影片拍摄中会因为相机和环境引入随机噪点,这里提供降噪服务,在保持细节不损失的情况下,消除画面中的随机噪声。 |
音频增强 | 音频降噪 | 音频智能降噪,去除设备底噪、环境噪声等,适用于录制课程、户外拍摄后期等场景。 |
| 音频分离 | 分离音视频文件中人声与背景声,或者演唱声和伴奏声,生成独立音频素材,便于后期实现其他风格艺术加工。 |
| 音量均衡 | 1. 响度标准化:使整体响度水平保持一致,播放时听起来具有相似的音量,避免出现过于响亮或过于安静的问题,提供更好的听觉体验。 2. 音量突变抑制:平滑过于响亮的音频片段,避免出现音量突变的问题,提供更平稳的听觉体验。 |
| 音频美化 | 1. 杂音去除:减少音频中包含的不需要的杂音或干扰声,提高音频的质量和清晰度。 2. 齿音压制:齿音是指音频中尖锐的、刺耳的声音,通常可能由声音源接近麦克风时产生。压制齿音旨在减少或消除这种不自然的声音,从而改善音频质量。 |
水印
添加水印是在视频转码或截图时,将特定的图片附加在画面指定位置的过程,是一种离线任务。媒体处理支持以下类型的水印:
静态图片水印:PNG 格式的图片水印,可以是版权方的 LOGO、台标等,常用于表明视频的版权归属。
动态图片水印:APNG 格式的动态图片水印,可以实现水印图片动态变化的效果。
媒体处理支持为视频或截图添加多个水印,并可以指定各个水印在画面中的大小和位置。
水印的目标规格包含水印类型、宽高和位置等参数。您可自定义以下水印相关参数。
参数 | 说明 |
水印类型(Type) | 支持静态图片水印和动态图片水印 |
水印位置(Position) | 水印在视频画面中的相对位置 |
图片大小(ImageSize) | 图片水印占视频画面的大小 |
图片内容(ImageContent) | 图片水印中图片的二进制内容 |
视频截图
截图是截取视频特定位置的图像并生成图片的过程,是一种离线任务。媒体处理提供以下类型的截图:
指定时间点截图:指定一组时间点,截取视频在这些时间点的图像。
采样截图:按相同的时间间隔对视频截取多张图。
雪碧图:按相同的时间间隔对视频截取多张小图,然后组装成若干大图(即 雪碧图)。
截图的目标规格,包含了截图文件格式、截图宽高等参数。您可自定义以下截图相关参数。
时间点截图
参数 | 说明 |
格式(Format) | 截图文件的输出格式,目前仅支持 JPG |
宽度(Width) | 截图宽度,范围是128px - 4096px |
高度(Height) | 截图高度,范围是128px - 4096px |
填充方式(FillType) | 当截图的宽高比与原始视频的宽高比不一致时,对截图的处理方式,即为“填充”。一般有以下几种填充方式: 拉伸:对图片进行拉伸,填满整个图片,可能导致图片被“压扁”或者“拉长” 留黑:保持图片宽高比不变,边缘剩余部分使用黑色填充 留白:保持图片宽高比不变,边缘剩余部分使用白色填充 高斯模糊:保持图片宽高比不变,边缘剩余部分使用高斯模糊化后填充 |
采样截图
参数 | 说明 |
格式(Format) | 截图文件的输出格式,目前仅支持 JPG |
宽度(Width) | 截图宽度,范围是128px - 4096px |
高度(Height) | 截图高度,范围是128px - 4096px |
采样方式(SampleType) | 采样方式分为两种: 按百分比采样:例如按照5%为间隔采样,生成截图张数将为20张 按时间间隔采样:例如按照10s为间隔采样,截图张数取决于视频的时长 |
采样间隔(Interval) | 采样的间隔长度: 如果按百分比采样,间隔是百分比 如果按时间间隔采样,间隔是多少秒 |
填充方式(FillType) | 当截图的宽高比与原始视频的宽高比不一致时,对截图的处理方式,即为“填充”。一般有以下几种填充方式: 拉伸:对图片进行拉伸,填满整个图片,可能导致图片被“压扁”或者“拉长” 留黑:保持图片宽高比不变,边缘剩余部分使用黑色填充 留白:保持图片宽高比不变,边缘剩余部分使用白色填充 高斯模糊:保持图片宽高比不变,边缘剩余部分使用高斯模糊化后填充 |
雪碧图
参数 | 说明 |
格式(Format) | 雪碧图文件的输出格式,目前仅支持 JPG |
小图宽度(Width) | 雪碧图中小图的宽度 |
小图高度(Height) | 雪碧图中小图的高度 |
小图行数(Rows) | 一张大图中有多少行小图 |
小图列数(Columns) | 一张大图中有多少列小图 |
采样方式(SampleType) | 小图采样方式,目前仅支持按照时间间隔采样 |
采样间隔(Interval) | 小图采样的间隔,即隔多久采样一张小图 |
注意:
Width × Columns 需要在128px - 4096px之间(即大图宽度在128px - 4096px之间)。
Height × Rows 需要在128px - 4096px之间(即大图高度在128px - 4096px之间)。
视频转动图
转动图是选取视频片段生成动图(GIF 和 WEBP 等)的过程,是一种离线任务。动图是一组连续帧的无缝循环,以较小的体积实现动画效果。
转动图的目标规格,包含了动图格式、宽高和帧率等参数。您可自定义以下动图相关参数。
参数 | 说明 |
格式(Format) | 动图文件的输出格式,目前仅支持 GIF 和 WEBP |
宽度(Width) | 动图宽度,范围是128px - 4096px |
高度(Height) | 动图高度,范围是128px - 4096px |
帧率(FPS) | 支持的帧率范围是1fps - 60fps |
媒体 AI / 媒体智能
媒体 AI 包括智能字幕、智能擦除、大模型摘要、智能标签、智能 ROI、智能横转竖、人脸识别、语音/文本识别、智能分析等功能。在直播、泛娱乐、教育等多个行业有深度积累,能够满足短剧出海、视频会议、在线教育、平台直播等多场景需求,提高内容制作效率。
智能字幕
智能字幕功能可以将点播视频文件或直播流中的语音信息进行实时语音识别,将其转换成字幕并进行多语言翻译,支持中文、英语、日韩语等多种语言。适用于直播实时字幕、视频转译出海等场景。也支持通过文字识别提取视频画面中的原有字幕并生成字幕文件,适用于老片修复、高清重制等场景。该功能还支持配置热词库、术语库以增加识别和翻译的准确率。查看 字幕生成及翻译。
技术优势
全平台支持:支持处理点播文件、直播流、互动音视频。直播实时同传字幕支持稳态、渐变模式,接入门槛低,无需播放端改造。
准确率高:大模型处理,支持热词、术语库,准确率行业领先。
语种丰富:支持上百种语种,支持多地方言,支持中英文夹杂等混合语种识别。
样式自定义:支持将字幕压制至视频,且字幕样式(字体、字号、颜色、背景、位置等)可自定义,支持页面自定义渲染。

智能擦除
高可定制性:支持针对您的具体的视频场景,对模型参数进行定制化调整,从而提高擦除的准确率和处理效果,确保最终呈现的画面更加自然流畅。

高光集锦 / 精彩集锦
高光集锦定义了精彩场景对应的关键词,例如“男女主角冲突”或“精彩打斗戏”。通过将图像特征和文本特征映射到一个统一的特征空间,我们可以利用这些关键词精准地找到视频中的精彩场景,从而提取出最引人注目的片段。支持影视剧、足球、篮球、绝地求生、王者荣耀等视频场景,支持定制。查看 高光集锦接入。
技术优势
全平台支持:支持处理点播离线视频,也支持对直播流进行处理,实现对过往的直播内容生成精彩片段。
多场景支持:支持影视剧、体育赛事、游戏竞赛、新闻资讯等视频场景。
高可定制性:支持针对您的具体的视频场景,对模型参数进行定制化调优。

智能拆条
智能拆条功能可以对视频内容进行结构化分析,将完整的长视频进行分段处理,适用于会议、培训、课程等多种场景。例如,将一段新闻联播的素材拆分成多个独立的新闻事件视频。这可以显著提升新闻和体育类视频的拆条质量,促进二次创作,节省人力和硬件成本。查看 智能拆条接入。

大模型视频摘要
借助 NLP 能力,大模型视频摘要功能可以对教学课程、新闻、演讲等视频场景,基于 ASR 识别结果进行混元大模型摘要提取。其提取和概括力强,无需反复拖拽即可快速理解视频内容。同时还支持离线分段和直播实时分段,自动提取段落摘要及关键词,帮助用户快速定位感兴趣的视频片段,提高使用效率。查看 大模型视频摘要接入。
技术优势
全平台支持:支持处理点播离线视频,也支持对直播流进行处理。
多语种支持:支持中文、英文等语种。
智能横转竖
横转竖不是单纯的旋转,而是通过识别感兴趣区域 (ROI,Region of Interest),将视频裁剪成一定比例的适合移动设备播放的视频。横转竖提供批量生成短视频的能力,能够将现有的横屏视频资源转换成竖屏视频资源。查看 智能横转竖接入。
技术优势
支持多人物场景:当视频中出现两个人物时,支持自动将画面上下分割,并在竖屏视频中分别显示这两个人物。
高可定制性:支持针对您的具体的视频场景,对模型参数进行定制化调优。

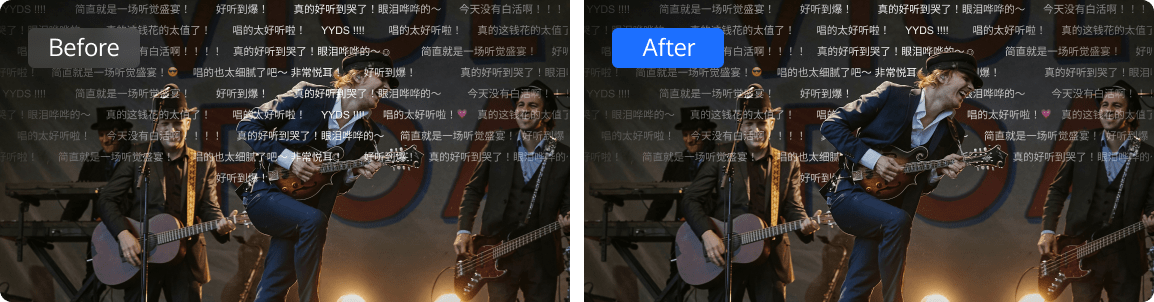
ROI 智能识别
ROI 智能识别技术可以实时识别视频中的人脸、游戏人物、主播等关键元素的坐标信息,并将感兴趣区域信息(ROI)随着视频编码传输到播放端。通过播放器结合 ROI 信息,可以实现智能弹幕防遮挡、背景模糊等功能。当前 ROI 智能识别支持处理直播流,如有处理离线视频的需求,请联系我们。查看直播ROI智能识别接入指引。
智能识别
智能识别
基于腾讯实验室的最新研究成果,为您提供视频内容的全方位识别,支持识别视频内的人物、语音、文字以及帧标签,对视频进行多维度结构化分析。识别类型 | 功能说明 |
人脸识别 | 基于深度学习方案,帮助客户快速识别视频中的人脸信息并快速定位出视频中的人物所在帧画面,以及人脸所在区域。客户可自定义人物库或调用视频 AI 公共人物库进行人脸识别。 |
语音识别 | 基于深度学习方案,帮助客户快速识别视频中的声音并转化成文字,支持客户自定义关键词且定位出关键词所在视频的时间点。 |
文字识别 | 帮助客户识别视频中出现的文字信息,可用于视频内自定义关键词的提取,也支持竖版文字的识别。 |
帧标签识别 | 基于深度学习方案,支持根据客户自定义视频截帧间隔,自动识别截帧画面内的标签,并定位标签所在的视频位置,帧标签涵盖人物、风景、人造物、建筑、动植物、食物等9个大类,包含日常生活的各个信息维度,并且支持在标签体系基础上使用自定义标签,具备迁移学习能力,只需提供原始用户数据便可定制分类器,满足不同类型的用户需求,使标签分类更具灵活性。 |
片头片尾识别 | 根据视频画面特征、文字、语音等信息自动识别定位电影/电视剧片头片尾时间点。 |
智能分析
分析类型 | 能力说明 |
分类识别 | 通过分析视频内容,给视频推荐一个类别。目前支持美食、旅游、动漫、音乐等19大类(支持定制,需支付定制费)。 |
视频标签识别 | 基于腾讯深度学习方案,智能识别出最符合视频内容的前五项标签摘要,用于视频推荐、检索等场景,用户可在接口中自行选择返回的标签个数。 |
智能封面 | 结合视频画面纹理、场景识别等特征信息自动生成文件封面,支持静态封面输出,提升视频封面体验和点击转化率。 |
智能审核
智能审核包括安全审核和质量审核两大类。
安全审核借助 AI 对视频内容(画面、音频及文字三种维度)进行涉黄、违法违规的检测。
质量审核支持检测直播、点播视频中的画面帧以及声音质量,涵盖花屏、黑边、马赛克、噪声等全方位13项检测类型,并提供主播视频整体质量检测评分。
审核类型 | 检测类型 | 检测项说明 |
安全审核 | 视频画面审核 | 对视频画面做涉黄、违规检测,具体检测项如下: 涉黄检测 porn:色情 vulgar:低俗 intimacy:亲密行为 sexy:性感 违法违规检测 guns:武器枪支 bloody:血腥画面 explosion:爆炸火灾 violation_photo:违规图标 |
| 音频审核 | 对音频中的文字进行检测,具体检测项如下: 涉黄检测:对音频中的文字做涉黄检查,识别出嫌疑关键词。 违法违规检测:对音频中的文字做违法违规检查,识别出嫌疑关键词。 |
| 文字审核 | 对画面中的文字进行检测,具体检测项如下: 涉黄检测:对画面中的文字做涉黄检查,识别出嫌疑关键词。 违法违规检测:对画面中的文字做违法违规检查,识别出嫌疑关键词。 |
质量审核 | 画面质量 | 支持对视频的画面质量做出检测,具体检测项如下: JitterResults:画面抖动。 BlurResults:画面模糊。 AbnormalLightingResults:低光、过曝。 CrashScreenResults:花屏 BlackWhiteEdgeResults:画面黑边、白边、黑屏、白屏、纯色屏时间段。 NoiseResults:画面有噪点。 MosaicResults:画面有马赛克。 QRCodeResults:画面有二维码。 |
| 声音质量 | 支持对视频的声音质量做出检测,具体检测项如下: VoiceResults:音频异常,包括静音、低音、爆音。 |

 是
是
 否
否
本页内容是否解决了您的问题?