- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 开发指南
- 操作指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Message APIs
- Cluster APIs
- Namespace APIs
- Topic APIs
- CMQ Message APIs
- CMQ Management APIs
- UnbindCmqDeadLetter
- RewindCmqQueue
- ModifyCmqTopicAttribute
- ModifyCmqSubscriptionAttribute
- ModifyCmqQueueAttribute
- DescribeCmqTopics
- DescribeCmqTopicDetail
- DescribeCmqSubscriptionDetail
- DescribeCmqQueues
- DescribeCmqQueueDetail
- DeleteCmqTopic
- DeleteCmqSubscribe
- DeleteCmqQueue
- CreateCmqTopic
- CreateCmqSubscribe
- CreateCmqQueue
- Other APIs
- Environment Role APIs
- TDMQ for RabbitMQ APIs
- RocketMQ APIs
- DescribeRocketMQVipInstanceDetail
- DescribeRocketMQMsg
- ModifyRocketMQTopic
- ModifyRocketMQNamespace
- ModifyRocketMQGroup
- ModifyRocketMQCluster
- DescribeRocketMQTopics
- DescribeRocketMQNamespaces
- DescribeRocketMQGroups
- DescribeRocketMQClusters
- DescribeRocketMQCluster
- DeleteRocketMQTopic
- DeleteRocketMQGroup
- DeleteRocketMQCluster
- CreateRocketMQTopic
- CreateRocketMQNamespace
- CreateRocketMQGroup
- CreateRocketMQCluster
- TDMQ for RocketMQ APIs
- Production and Consumption APIs
- Data Types
- Error Codes
- SDK 文档
- 常见问题
- TDMQ 政策
- 服务等级协议
- 通用参考
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 开发指南
- 操作指南
- 实践教程
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Message APIs
- Cluster APIs
- Namespace APIs
- Topic APIs
- CMQ Message APIs
- CMQ Management APIs
- UnbindCmqDeadLetter
- RewindCmqQueue
- ModifyCmqTopicAttribute
- ModifyCmqSubscriptionAttribute
- ModifyCmqQueueAttribute
- DescribeCmqTopics
- DescribeCmqTopicDetail
- DescribeCmqSubscriptionDetail
- DescribeCmqQueues
- DescribeCmqQueueDetail
- DeleteCmqTopic
- DeleteCmqSubscribe
- DeleteCmqQueue
- CreateCmqTopic
- CreateCmqSubscribe
- CreateCmqQueue
- Other APIs
- Environment Role APIs
- TDMQ for RabbitMQ APIs
- RocketMQ APIs
- DescribeRocketMQVipInstanceDetail
- DescribeRocketMQMsg
- ModifyRocketMQTopic
- ModifyRocketMQNamespace
- ModifyRocketMQGroup
- ModifyRocketMQCluster
- DescribeRocketMQTopics
- DescribeRocketMQNamespaces
- DescribeRocketMQGroups
- DescribeRocketMQClusters
- DescribeRocketMQCluster
- DeleteRocketMQTopic
- DeleteRocketMQGroup
- DeleteRocketMQCluster
- CreateRocketMQTopic
- CreateRocketMQNamespace
- CreateRocketMQGroup
- CreateRocketMQCluster
- TDMQ for RocketMQ APIs
- Production and Consumption APIs
- Data Types
- Error Codes
- SDK 文档
- 常见问题
- TDMQ 政策
- 服务等级协议
- 通用参考
- 联系我们
- 词汇表
消息元数据组成
Pulsar 中每个分区 Topic 的消息数据以 ledger 的形式存储在 BookKeeper 集群的 bookie 存储节点上,每个 ledger 包含一组 entry,而 bookie 只会按照 entry 维度进行写入、查找、获取。
说明:
批量生产消息的情况下,一个 entry 中可能包含多条消息,所以 entry 和消息并不一定是一一对应的。
Ledger 和 entry 分别对应不同的元数据。
ledger 的元数据存储在 zk 上。
entry 除了消息数据部分之外,还包含元数据,entry 的数据存储在 bookie 存储节点上。

类型 | 参数 | 参数说明 | 数据存放位置 |
ledger | ensemble size(E) | 每个 ledger 选用的 bookie 节点的个数 | 元数据存储在 zk 上 |
| | write quorum size(Qw) | 每个 entry 需要向多少个 bookie 发送写入请求 |
| | ack quorum size(Qa) | 收到多少个写入确认后,即可认为写入成功 |
| | Ensembles(E) | 使用的 ensemble 列表,形式为<entry id,="" ensembles=""> 元组 key(entry id):使用这个 ensembles 列表开始时的 entry id value(ensembles):ledger 选用的 bookie ip 列表,每个 value 中包含 ensemble size (E)个 IP 每个 ledger 可能包含多个 ensemble 列表,同一时刻每个 ledger 最多只有一个 ensembles 列表在使用 |
Entry | Ledger ID | entry 所在的 ledger id | 数据存储在 bookie 存储节点上 |
| | Entry ID | 当前 entry id |
| | Last Add Confirmed | 创建当前 entry 的时候,已知最新的写入确认的 entry id |
| | Digest | CRC |
每个 ledger 在创建的时候,会在现有的 BookKeeper 集群中的可写状态的 bookie 候选节点列表中,选用 ensemble size 对应个数的 bookie 节点,如果没有足够的候选节点则会抛出 BKNotEnoughBookiesExceptio 异常。选出候选节点后,将这些信息组成 <entry id, ensembles> 元组,存储到 ledger 的元数据里的 ensembles 中。
消息副本机制
消息写入流程
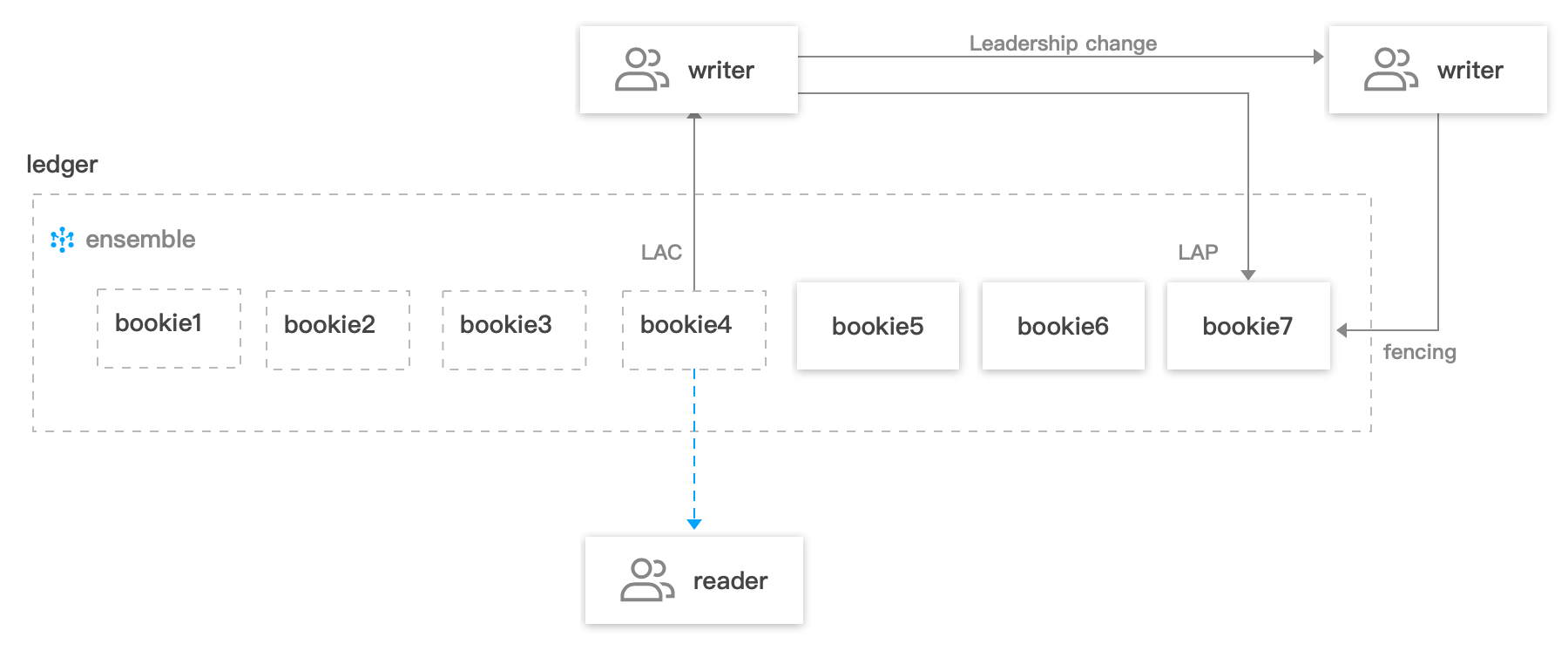
客户端在写入消息时,每个 entry 会向 ledger 当前使用的 ensemble 列表中的 Qw 个 bookie 节点发送写入请求,当收到 Qa 个写确认后,即认为当前消息写入存储成功。同时会通过 LAP(lastAddPushed)和 LAC(LastAddConfirmed)分别标识当前推送的位置和已经收到存储确认的位置。
每个正在推送的 entry 中的 LAC 元数据值,为当前时刻创建发送 entry 请求时,已经收到最新的确认位置值。LAC 所在位置及之前的消息对读客户端是可见的。
同时,pulsar 通过 fencing 机制,来避免同时有多个客户端对同一个 ledger 进行写操作。这里主要适用于一个 topic/partition 的归属关系从一个 broker 变迁到另一个 broker 的场景。
消息副本分布
每个 entry 写入时,会根据当前消息的 entry id 和当前使用的 ensembles 列表的开始 entry id(即key值),计算出在当前 entry 需要使用 ensemble 列表中由哪组 Qw 个 bookie 节点进行写入。之后,broker 会向这些 bookie 节点发送写请求,当收到 Qa 个写确认后,即认为当前消息写入存储成功。这时至少能够保证 Qa 个消息的副本个数。
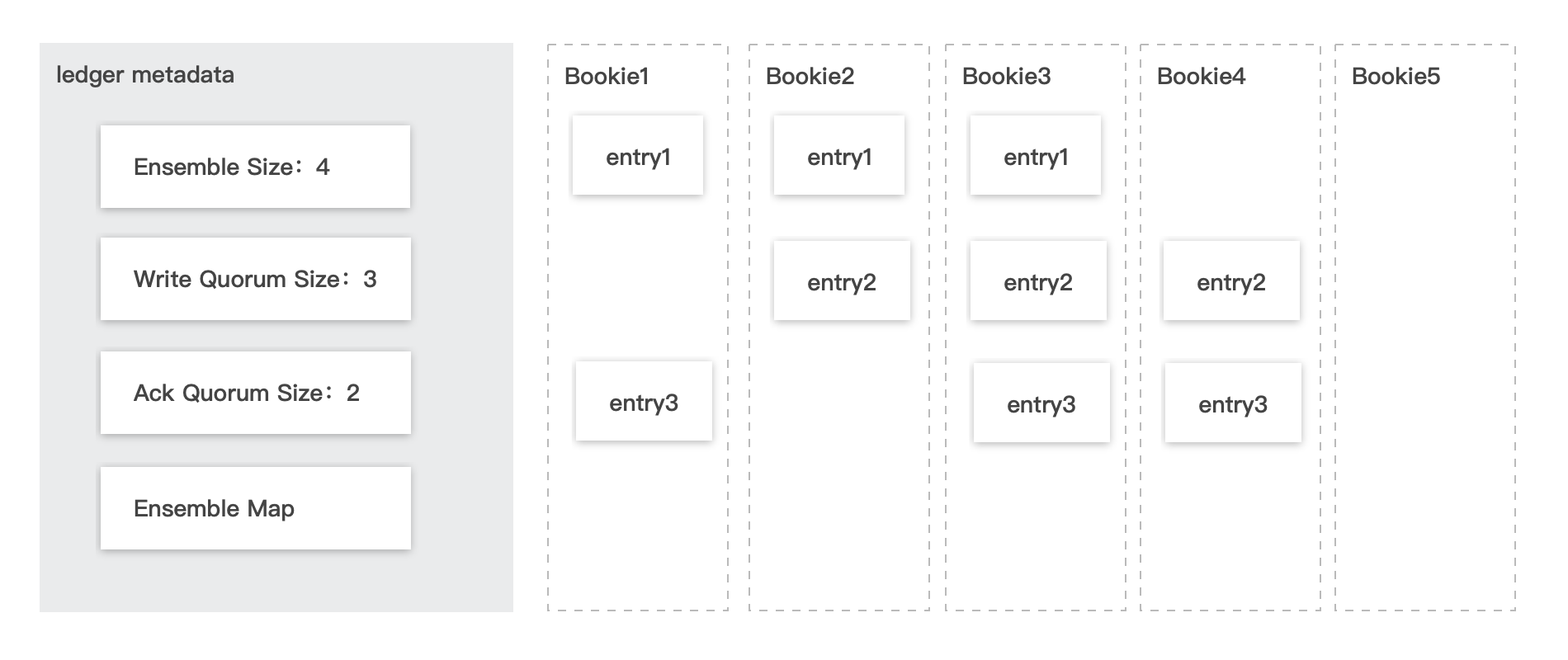
如上图所示,ledger 选用了4个 bookie 节点(bookie1-4 这4个节点),每次写入3个节点,当收到2个写入确认即代表消息存储成功。当前 ledger 选中的 ensemble 从 entry 1开始,使用 bookie1、bookie2、bookie3 进行写入,写入 entry 2的时候选用 bookie2、bookie3、bookie4 写入,而 entry 3 则会根据计算结果,写入 bookie3、bookie4、bookie1。
消息恢复机制
Pulsar 的 BookKeeper 集群中的每个 bookie 在启动的时候,默认自动开启 recovery 的服务,这个服务会进行如下几个事情:
1. auditorElector 审计选举。
2. replicationWorker 复制任务。
3. deathWatcher 宕机监控。
BookKeeper 集群中的每个 bookie 节点,会通过 zookeeper 的临时节点机制进行选主,主 bookie 主要处理如下几个事情:
1. 负责监控 bookie 节点的变化。
2. 到 zk 上面标记出宕机的 bookie 上面的 ledger 为 Underreplicated 状态。
3. 检查所有的 ledger 的副本数(默认一周一个周期)。
4. Entry 副本数检查(默认未开启)。
其中 ledger 中的数据是按照 Fragment 维度进行恢复的(每个 Fragment 对应 ledger 下的一组 ensemble 列表,如果一个 ledger 下有多个 ensemble 列表,则需要处理多个 Fragment)。
在进行恢复时,首先要判断出当前的 ledger 中的哪几个 Fragment 中的哪些存储节点需要用新的候选节点进行替换和恢复数据。当 Fragment 中关联的部分 bookie 节点上面没有对应的 entry 数据(默认是按照首、尾 entry 是否存在判断),则这个 bookie 节点需要被替换,当前的这个 Fragment 需要进行数据恢复。
Fragment 的数据用新的 bookie 节点进行数据恢复完毕后,更新 ledger 的元数据中当前 Fragment 对应的 ensemble 列表的原数据。
经过此过程,因 bookie 节点宕机引起的数据副本数减少的场景,数据的副本数会逐步的恢复成 Qw(后台指定的副本数,TDMQ 默认3副本)个。

 是
是
 否
否
本页内容是否解决了您的问题?