- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 安全白皮书
- 开发指南
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Security Group APIs
- Other APIs
- Account APIs
- Parameter Management APIs
- Monitoring Management APIs
- Instance Management APIs
- CancelDcnJob
- CloseDBExtranetAccess
- CreateDBInstance
- CreateHourDBInstance
- DescribeDBInstanceDetail
- DescribeDBInstances
- DescribeDcnDetail
- DescribeInstanceNodeInfo
- DescribeOrders
- DescribePrice
- DestroyDBInstance
- DestroyHourDBInstance
- IsolateDBInstance
- IsolateDedicatedDBInstance
- ModifyDBInstancesProject
- ModifyInstanceNetwork
- ModifyInstanceVip
- ModifyInstanceVport
- TerminateDedicatedDBInstance
- UpgradeDedicatedDBInstance
- ModifyBackupTime
- OpenDBExtranetAccess
- DescribeFlow
- DescribeBackupTime
- InitDBInstances
- ModifyDBInstanceName
- SwitchDBInstanceHA
- IsolateHourDBInstance
- ActivateHourDBInstance
- Backup and Restoration APIs
- Data Types
- Error Codes
- 常见问题
- 通用参考
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 安全白皮书
- 开发指南
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Security Group APIs
- Other APIs
- Account APIs
- Parameter Management APIs
- Monitoring Management APIs
- Instance Management APIs
- CancelDcnJob
- CloseDBExtranetAccess
- CreateDBInstance
- CreateHourDBInstance
- DescribeDBInstanceDetail
- DescribeDBInstances
- DescribeDcnDetail
- DescribeInstanceNodeInfo
- DescribeOrders
- DescribePrice
- DestroyDBInstance
- DestroyHourDBInstance
- IsolateDBInstance
- IsolateDedicatedDBInstance
- ModifyDBInstancesProject
- ModifyInstanceNetwork
- ModifyInstanceVip
- ModifyInstanceVport
- TerminateDedicatedDBInstance
- UpgradeDedicatedDBInstance
- ModifyBackupTime
- OpenDBExtranetAccess
- DescribeFlow
- DescribeBackupTime
- InitDBInstances
- ModifyDBInstanceName
- SwitchDBInstanceHA
- IsolateHourDBInstance
- ActivateHourDBInstance
- Backup and Restoration APIs
- Data Types
- Error Codes
- 常见问题
- 通用参考
- 词汇表
云数据库 MariaDB 是分布式数据库 TDSQL MySQL 版的单机版本,当您预估您的业务会急剧增长,单机版本已经无法支撑业务发展的场景时,可以使用分布式版本。
概述
数据切分与分片(sharding)
在高性能并发互联网架构中,性能瓶颈往往出现在数据库服务器,特别是当业务(用户)达到百万级用户规模以后,通过在数据层进行合理的数据切分(sharding),可以有效解决数据库性能、可伸缩等问题。数据库切分同样是从两个维度考虑:垂直切分(按功能切分)和水平切分。
垂直切分是按功能切分,这种切分方法跟业务紧密相关,实施思路也比较直接,例如电商平台将数据按功能切分为会员数据库、商品数据库、交易数据库、物流数据库等。而垂直拆分并不能彻底解决压力问题,因为单台数据库服务器的负载和容量也是有限的,随着业务发展势必也会成为瓶颈,解决这些问题的常见方案就是水平切分了。
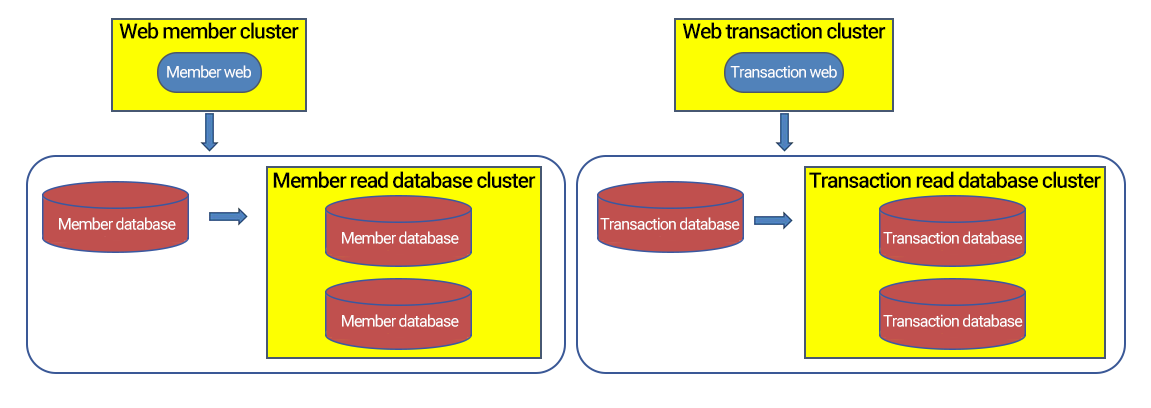
水平切分是按照某种规则,将一个表的数据分散到多个物理独立的数据库服务器中,这些“独立”的数据库“分片”;多个分片组成一个逻辑完整的数据库实例。
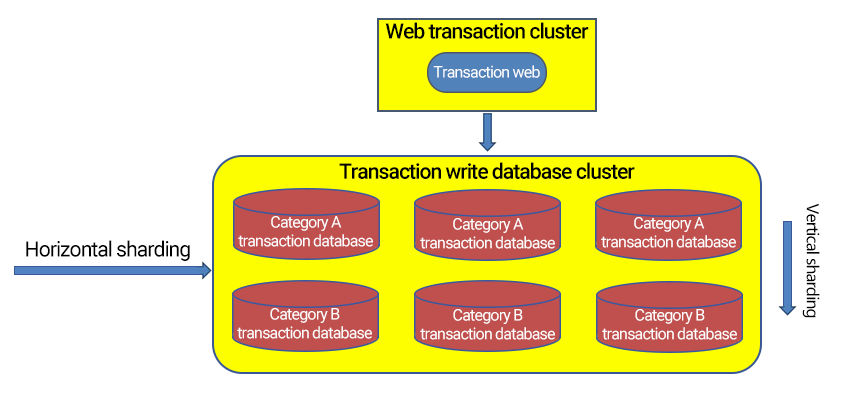
分片规则
关系型数据库是一个二维模型,数据的切分通常就需要找到一个分片字段(shardkey)以确定拆分维度,再通过定义规则来实现数据库的拆分。如何找到合适的分片规则需要综合考量业务,这里介绍几种常见的分片规则:
1. 基于日期顺序。如按年拆分,2015年一个分片,2016年一个分片。
优势:简单明了,易于查找。
劣势:当期(2016年)的热数据的服务器性能可能不足,而存储冷数据性能却闲置。
2. 基于用户 ID 求模,将求模后字段的特定范围分散到不同库中。
优势:性能相对均衡,相同用户数据在一个库中。
劣势:可能导致数据倾斜(如设计的是商户系统,一个大商户数据能比几千个小商户的数据还多)。
3. 将主键(primary key)求模,将求模后字段的特定范围分散到不同库中。
优势:性能相对均衡,不容易出现数据倾斜的问题,相同主键的数据在一个库中。
劣势:数据随机分散,某些业务逻辑可能需要跨分片 join 却不能直接支持。
另外,在分片的数据源管理方面,目前也有两种思路:
1. 客户端模式:由业务程序模块中的配置来管理多个分片的数据源,分片的读写与数据整合在业务程序内进行。
2. 中间件代理模式:在分片数据库前端搭建一个中间件代理,后端多个分片数据库对前端应用程序透明。
分布式数据库 TDSQL
自动水平拆分(分库分表)
分布式数据库 TDSQL(TencentDB for TDSQL)是部署在腾讯云公有云上的一种兼容 MySQL 协议和语法,支持自动水平拆分的分布式数据库。分布式数据库即业务获取是完整的逻辑库表,后端却将库表均匀的拆分到多个物理分片节点。目前,TDSQL 默认部署主备架构且提供了容灾、备份、恢复、监控、迁移等方面的全套解决方案,适用于 TB 或 PB 级的海量数据库场景。
TDSQL 的历史可以追溯到2004年,腾讯互联网增值业务开始爆发,业务量的爆炸给 MySQL 数据库带来了巨大的扩容压力,当时即开始引入分库分表机制来解决难题——针对大的表,按照 ShardKey 预先拆成多个子表,分布在不同的物理机器节点上。时至今日,TDSQL 后端存储数据量已相当庞然,以“米大师”为例,分布式数据库 TDSQL 承载米大师各个渠道的100亿的账户,用户数量接近9亿,日交易金额超过10亿人民币。
分布式数据库 TDSQL 能够轻松支撑起海量业务的优势如下:
自动拆分表:TDSQL 支持自动的分库分表,结合数据的统一调度机制,实现按需的容量伸缩。因为 TDSQL 通过网关屏蔽了内部的分库分表细节,对于开发人员来说,不再需要关心如何切分数据、如何路由请求等待,只需初始化分片字段(shardkey),直接面向逻辑库表进行编程、专注业务逻辑的实现即可,极大降低了程序的复杂度。
自动容灾切换:无论是物联网,还是大数据,或是支付服务,任何存储了海量数据的业务都对后台存储数据库的可用性要求非常高。而通常解决方案是,容灾切换需要业务检测和配合,与业务程序深度耦合,而且切换过程复杂,甚至需要人工介入。业务恢复后还需要对切换过程中可能出现的错误数据进行手工修复,运维起来非常耗力。TDSQL 数据节点和网关实现多点容灾,自动检测实例的运行状态。当发现主节点不可用时,会自动触发主备容灾切换流程,保障在主机故障、网络故障、IDC 故障等灾难情况下数据库的高可用性。这个容灾切换过程对业务完全透明,且无需人工干预,在确保用户体验的同时,也极大简化了运维工作。
数据高一致性保障:如果您对数据的丢失或错乱零容忍。TDSQL 在 MySQL 原有异步复制和半同步复制的基础上创新使用了多线程强同步复制机制,确保每一笔交易在返回用户应答前,在集群中至少有两个拷贝,然后再通过一系列切换机制保障在节点故障发生切换时,数据不会丢失或错乱。
集群化管理,自动扩容:业务的请求量会因上线新功能或者做营销活动等原因,峰值请求量激增至平时的几倍甚至几十倍。之前,需要提前知晓业务侧的动向,由 DBA 提前手工扩容,通常,大多数分布式数据库扩容过程繁杂,且中间过程手工操作多,极容易出错。而 TDSQL 在集群层面实现了自动部署、自动容量伸缩、自动备份恢复、数据定点回档以及多维监控等功能。当扩容需求时,DBA 只需要在前台单击按钮发起扩容流程,即可自动完成扩容工作。TDSQL 的集群化运营体系,极大提升了 DBA 的工作效率,同时降低了手工操作可能带来的失误。
TDSQL 架构
TDSQL 实例的基本架构如下:
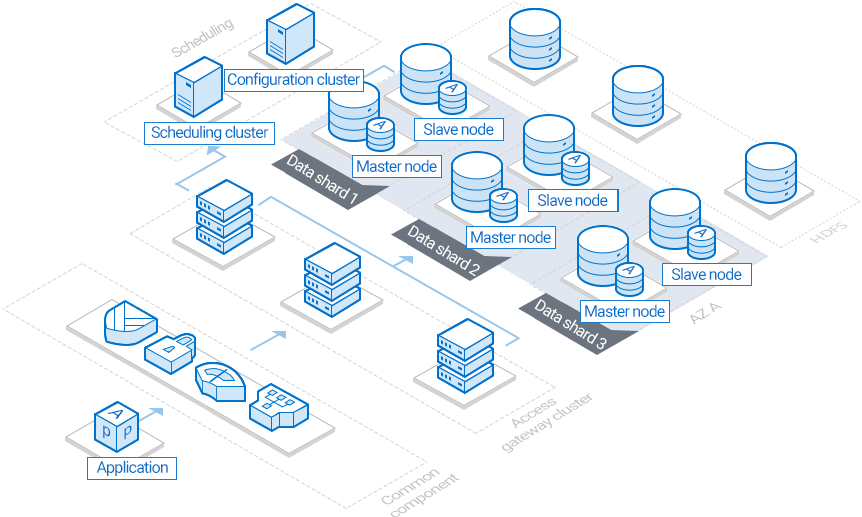
数据分片:兼容开源数据库 MySQL 的数据库引擎、监控和信息采集(Tagent)性能。
说明:
分布式数据库默认为每个分片配置两个节点,即“一主一备”,每个分布式数据库需至少两个分片。
调度集群:作为集群的管理调度中心,主要管理 SET 的正常运行,记录并分发数据库全局配置。
接入网关集群(TProxy):在网络层连接管理 SQL 解析、分配路由,即可以理解为开源分布式数据库的中间件。
说明:
为不让 proxy 成为性能瓶颈,分布式数据库 proxy 数量通常等于分片数量。
备份集群:腾讯云云数据库数据备份集群。
说明:
分布式数据库备份默认保存7天。

 是
是
 否
否
本页内容是否解决了您的问题?