- Release Notes and Announcements
- User Guide
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Resource Management
- Permission Management
- Log Collection
- Collection Overview
- Collecting Logs in Self-Built Kubernetes Cluster
- Collecting Syslog
- Collection by LogListener
- Collecting Text Log
- Uploading Log over Kafka
- Uploading Logs via Anonymous Write
- Uploading Logs via Logback Appender
- Uploading Logs via Log4j Appender
- Uploading Log via SDK
- Uploading Log via API
- Importing Data
- Tencent Cloud Service Log Access
- Metric Collection
- Log Storage
- Metric Storage
- Search and Analysis (Log Topic)
- Overview of Search and Analysis
- Syntax and Rules
- Statistical Analysis (SQL)
- Quick Analysis
- SQL Syntax
- SQL Functions
- String Function
- Date and Time Functions
- IP Geographic Function
- URL Function
- Mathematical Calculation Functions
- Mathematical Statistical Function
- General Aggregate Function
- Geospatial Function
- Binary String Function
- Estimation Function
- Type Conversion Function
- Logical Function
- Operators
- Bitwise Operation
- Regular Expression Function
- Lambda Function
- Conditional Expressions
- Array Functions
- Interval-Valued Comparison and Periodicity-Valued Comparison Functions
- JSON Functions
- Window Functions
- Sampling Analysis
- Configuring Indexes
- Reindexing
- Multi-Topic Search
- Context Search and Analysis
- Custom Redirect
- Downloading Log
- Search and Analysis (Metric Topic)
- Dashboard
- Data Processing documents
- Data Processing
- Data Processing Overview
- Creating Processing Task
- Viewing Data Processing Details
- Data Processing Functions
- Function Overview
- Key-Value Extraction Functions
- Enrichment Functions
- Flow Control
- Row Processing Functions
- Field Processing Functions
- Value Structuring Functions
- Regular Expression Processing Functions
- Time Value Processing Functions
- String Processing Functions
- Type Conversion Functions
- Logical and Mathematical Functions
- Encoding and Decoding Functions
- IP Parsing Functions
- Processing Cases
- Scheduled SQL Analysis
- SCF
- Data Processing
- Shipping and Consumption
- Monitoring Alarm
- Historical Documentation
- Practical Tutorial
- Developer Guide
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Topic Management APIs
- Log Set Management APIs
- Index APIs
- Topic Partition APIs
- Machine Group APIs
- Collection Configuration APIs
- Log APIs
- Metric APIs
- Alarm Policy APIs
- Data Processing APIs
- Kafka Protocol Consumption APIs
- CKafka Shipping Task APIs
- Kafka Data Subscription APIs
- COS Shipping Task APIs
- SCF Delivery Task APIs
- Scheduled SQL Analysis APIs
- COS Data Import Task APIs
- Data Types
- Error Codes
- FAQs
- CLS Service Level Agreement
- CLS Policy
- Contact Us
- Glossary
- Release Notes and Announcements
- User Guide
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Resource Management
- Permission Management
- Log Collection
- Collection Overview
- Collecting Logs in Self-Built Kubernetes Cluster
- Collecting Syslog
- Collection by LogListener
- Collecting Text Log
- Uploading Log over Kafka
- Uploading Logs via Anonymous Write
- Uploading Logs via Logback Appender
- Uploading Logs via Log4j Appender
- Uploading Log via SDK
- Uploading Log via API
- Importing Data
- Tencent Cloud Service Log Access
- Metric Collection
- Log Storage
- Metric Storage
- Search and Analysis (Log Topic)
- Overview of Search and Analysis
- Syntax and Rules
- Statistical Analysis (SQL)
- Quick Analysis
- SQL Syntax
- SQL Functions
- String Function
- Date and Time Functions
- IP Geographic Function
- URL Function
- Mathematical Calculation Functions
- Mathematical Statistical Function
- General Aggregate Function
- Geospatial Function
- Binary String Function
- Estimation Function
- Type Conversion Function
- Logical Function
- Operators
- Bitwise Operation
- Regular Expression Function
- Lambda Function
- Conditional Expressions
- Array Functions
- Interval-Valued Comparison and Periodicity-Valued Comparison Functions
- JSON Functions
- Window Functions
- Sampling Analysis
- Configuring Indexes
- Reindexing
- Multi-Topic Search
- Context Search and Analysis
- Custom Redirect
- Downloading Log
- Search and Analysis (Metric Topic)
- Dashboard
- Data Processing documents
- Data Processing
- Data Processing Overview
- Creating Processing Task
- Viewing Data Processing Details
- Data Processing Functions
- Function Overview
- Key-Value Extraction Functions
- Enrichment Functions
- Flow Control
- Row Processing Functions
- Field Processing Functions
- Value Structuring Functions
- Regular Expression Processing Functions
- Time Value Processing Functions
- String Processing Functions
- Type Conversion Functions
- Logical and Mathematical Functions
- Encoding and Decoding Functions
- IP Parsing Functions
- Processing Cases
- Scheduled SQL Analysis
- SCF
- Data Processing
- Shipping and Consumption
- Monitoring Alarm
- Historical Documentation
- Practical Tutorial
- Developer Guide
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Topic Management APIs
- Log Set Management APIs
- Index APIs
- Topic Partition APIs
- Machine Group APIs
- Collection Configuration APIs
- Log APIs
- Metric APIs
- Alarm Policy APIs
- Data Processing APIs
- Kafka Protocol Consumption APIs
- CKafka Shipping Task APIs
- Kafka Data Subscription APIs
- COS Shipping Task APIs
- SCF Delivery Task APIs
- Scheduled SQL Analysis APIs
- COS Data Import Task APIs
- Data Types
- Error Codes
- FAQs
- CLS Service Level Agreement
- CLS Policy
- Contact Us
- Glossary
Data processing
provides capabilities for log data filtering, cleansing, data masking, enrichment, and distribution.According to the position of data processing in the data pipeline, and the different sources and sinks, the following data processing scenarios are currently supported:
Scenario | Description |
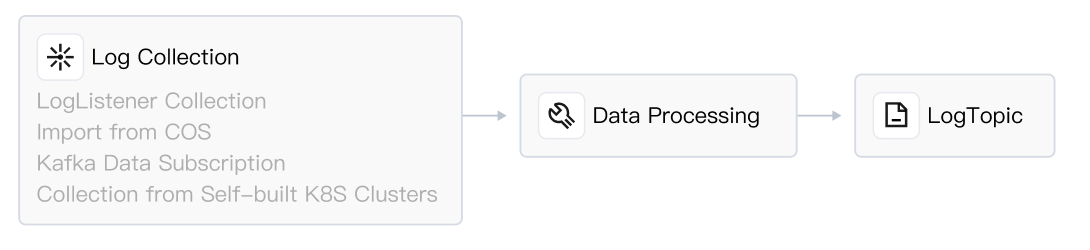 | Log Collection - Processing - Log Topic: Logs are collected to CLS, processed (filtered, structured), and then written to the log topic. As shown, data processing occurs before the log topic in the data pipeline, referred to as preprocessing of data. Performing log filtering in preprocessing can effectively reduce log write traffic, index traffic, index storage, and log storage. Performing log structuring in preprocessing, with key-value indexing enabled, allows for SQL analysis of logs, dashboard configuration, and alarms. |
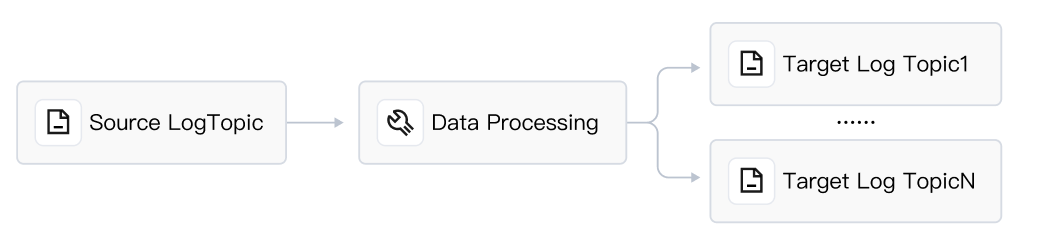 | Log Topic - Processing - Fixed Log Topic: Store the data from the source log topic into a log topic after processing, or distribute logs to multiple log topics. |
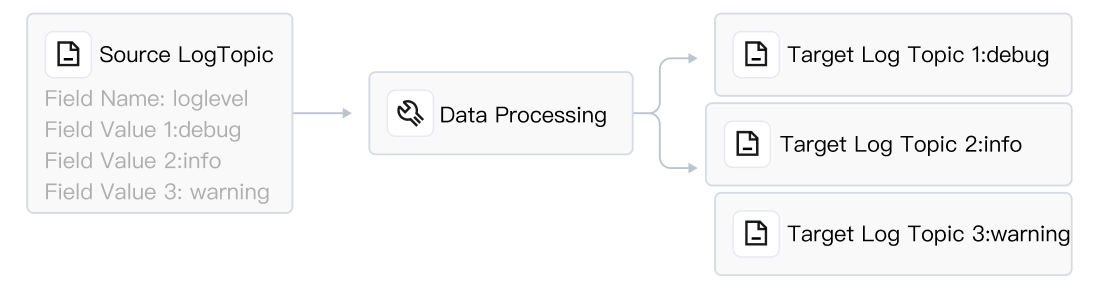 | Log Topic - Processing - Dynamic Log Topic: Based on the field value of the source log topic, dynamically create log topics and distribute related logs to the corresponding log topics. For example, if there is a field named Service in the source log topic with values like "Mysql", "Nginx", "LB", etc., CLS can automatically create log topics named Mysql, Nginx, LB, etc., and write related logs into these topics. |
Basic Concepts
Features
Extract structured data to facilitate subsequent BI analysis, generation of monitoring charts (dashboard), etc. If your raw logs are not structured data, there is no way to perform SQL calculations, which means that OLAP analysis and CLS dashboard (drawing charts based on SQL results) cannot be performed on the logs. Therefore, it is recommended that you use data processing to convert unstructured data into structured data. If your logs are regular, you can also extract structured data at the time of log collection. See Full Regular Expression Format (Single Line) or Delimiter Format. Compared to the collection side, data processing offers more complex structured processing logic.
Log filtering: Reduces subsequent usage costs. Discard unnecessary log data to save storage and traffic costs on the cloud. For example, you may deliver logs to Tencent Cloud COS and CKafka in the future, which can effectively save delivery traffic.
Sensitive Data Masking: For example, masking information such as ID numbers and phone numbers.
Log Distribution: For example, classifying logs according to log levels: ERROR, WARNING, and INFO, and then distributing them to different log topics.
Advantages
Easy to use, especially friendly to data analysts and operations engineers. Provides out-of-the-box functions with no need to purchase, configure, or maintain a Flink cluster. You can achieve stream processing of massive logs, including data cleaning and filtering, data masking, structuring, and distribution, by using our packaged DSL functions. For more information, see Function Overview.
High-throughput real-time log data stream processing. High processing efficiency (millisecond latency) and high throughput, reaching 10-20 MB/s per partition (source log topic partition).
Customer Cases
Data cleaning and filtering: Client A discards invalid logs, retains only specified fields, and fills in some missing fields and values. If the log does not contain the fields product_name and sales_manager, it is considered invalid and discarded. Otherwise, the log is retained, keeping only the fields price, sales_amount, and discount. Other fields are dropped. If the log is missing the discount field, this field is added with a default value, such as "70%".
Data Conversion: Client B has field values in the original logs that are IP addresses. The client needs to add fields and values for country and city based on the IP. For example, for 2X0.18X.51.X5, add the fields country: China and city: Beijing. Convert the UNIX timestamp to Beijing time, for example, 1675826327 to 2023/2/8 11:18:47.
Log classification and delivery: Client C has original logs in multi-level JSON, which includes Array arrays. Client C uses data processing to extract the array from specified nodes in the multi-level JSON as field values. For example, extract the Auth field value from Array[0], and then distribute the log data based on the Auth field value. When the value is "SASL", deliver to target topic A; when the value is "Kerberos", deliver to target topic B; when the value is "SSL", deliver to target topic C.
Log structuring: Client D processes the original log "2021-12-02 14:33:35.022 [1] INFO org.apache.Load - Response:status: 200, resp msg: OK" to complete structuring, resulting in log_time: 2021-12-02 14:33:35.022, loglevel: info, status: 200.
Fee Description
If your business only needs processed logs, it is recommended to set the retention period of the source log topic to 3-7 days and disable the index of the source log topic to save costs effectively.
Specifications and Limits

 Ya
Ya
 Tidak
Tidak
Apakah halaman ini membantu?