- 动态与公告
- 新手指引
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 运维开发指南
- 故障处理
- API 文档
- History
- API Category
- Making API Requests
- Backup APIs
- Introduction
- Instance APIs
- RenameInstance
- OfflineIsolatedDBInstance
- ModifyDBInstanceSpec
- IsolateDBInstance
- DescribeSpecInfo
- DescribeDBInstances
- DescribeClientConnections
- CreateDBInstanceHour
- AssignProject
- RenewDBInstances
- DescribeSlowLogs
- DescribeSlowLogPatterns
- InquirePriceRenewDBInstances
- InquirePriceModifyDBInstanceSpec
- InquirePriceCreateDBInstances
- DescribeDBInstanceDeal
- DescribeSecurityGroup
- DescribeInstanceParams
- ModifyDBInstanceSecurityGroup
- ModifyDBInstanceNetworkAddress
- Account APIs
- Task APIs
- Other APIs
- Data Types
- Error Codes
- SDK 参考
- 产品性能
- 常见问题
- 相关协议
- 词汇表
- 联系我们
- 动态与公告
- 新手指引
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 运维开发指南
- 故障处理
- API 文档
- History
- API Category
- Making API Requests
- Backup APIs
- Introduction
- Instance APIs
- RenameInstance
- OfflineIsolatedDBInstance
- ModifyDBInstanceSpec
- IsolateDBInstance
- DescribeSpecInfo
- DescribeDBInstances
- DescribeClientConnections
- CreateDBInstanceHour
- AssignProject
- RenewDBInstances
- DescribeSlowLogs
- DescribeSlowLogPatterns
- InquirePriceRenewDBInstances
- InquirePriceModifyDBInstanceSpec
- InquirePriceCreateDBInstances
- DescribeDBInstanceDeal
- DescribeSecurityGroup
- DescribeInstanceParams
- ModifyDBInstanceSecurityGroup
- ModifyDBInstanceNetworkAddress
- Account APIs
- Task APIs
- Other APIs
- Data Types
- Error Codes
- SDK 参考
- 产品性能
- 常见问题
- 相关协议
- 词汇表
- 联系我们
内存优化并不是简单地减少内存使用,而是在保证系统性能正常的前提下,让内存使用足够且稳定,并在机器资源和性能之间达到一个最佳的平衡方案。本文从云数据库 MongoDB 通常内存开销的类别出发,说明其内存占用原因,并给出排查方法及解决建议,便于您及时调优数据库性能。
存储引擎内存
云数据库 MongoDB 将存储引擎 WiredTiger 的缓存大小限定为实际申请的实例内存规格大小的60%。如果存储引擎缓存接近于限定范围的95%,说明实例负载已经很高。存储引擎脏数据缓存占比如果达到20%,将会阻塞用户线程。
排查方法
在 MongoDB Shell 中通过
db.serverStatus().wiredTiger.cache命令可查看引擎内存的使用情况。返回信息中bytes currently in the cache后的值为缓存数据的大小。如下图所示:{......"bytes belonging to page images in the cache":6511653424,"bytes belonging to the cache overflow table in the cache":65289,"bytes currently in the cache":8563140208,"bytes dirty in the cache cumulative":NumberLong("369249096605399"),......}
在数据库智能管家 DBbrain 性能趋势的 MongoStatus 功能,可实时查看存储引擎 Cache 脏数据占比。具体信息,请参见 mongostat。
使用建议
如果存储引擎 Cache Dirty 持续性升高超过20%,请按照如下步骤处理:
a. 控制单位时间写入的数据量。
c. 提升清理脏数据线程数量。其线程数量越高,越消耗实例资源,请谨慎调整合适的数值。默认为
threads_max=4,threads_min=1,其设置方式如下:db.runCommand({"setParameter":1, "wiredTigerEngineRuntimeConfig":"eviction=(threads_max=8,threads_min=4)"})
说明:
通过 db.runCommand 调整清理脏数据的线程数量,仅适合副本集架构 4.0 及其之后的版本。
如果存储引擎 Cache Used 持续性升高超过95%,请按照如下步骤处理:
c. 提升清理脏数据线程数。
连接和请求内存
每个连接都需要对应一个请求线程进行处理,过多的请求线程会引起请求上下文频繁切换而导致内存开销增加。每个线程最多可以使用1MB的线程栈,通常情况下内存在几十KB到几KB之间。
每当接收到一个请求命令时,都会创建一个请求上下文,整个过程中可能会分配很多临时缓冲区,例如请求包、应答包和排序的临时缓冲区等。这些缓冲区在请求结束时都会被释放。但是,此时释放只是将其归还给内存分配器
tcmalloc。tcmalloc 会优先将这些缓冲区返回到自己的缓存中,然后逐步将它们归还给操作系统。很多情况下,内存使用率高的原因是 tcmalloc 未能及时将内存归还给操作系统,导致内存最大可能达到几十GB。排查方法
tcmalloc未归给操作系统的内存大小,可以通过命令db.serverStatus().tcmalloc.tcmalloc.formattedString或者
db.serverStatus().tcmalloc 查看。如下图所示,使用db.serverStatus().tcmalloc.tcmalloc.formattedString查询内存信息。其中的Bytes in use by application对应的内存指 Mongod 节点实际消耗的内存,Bytes in page heap freelist 为未归还给操作系统的内存。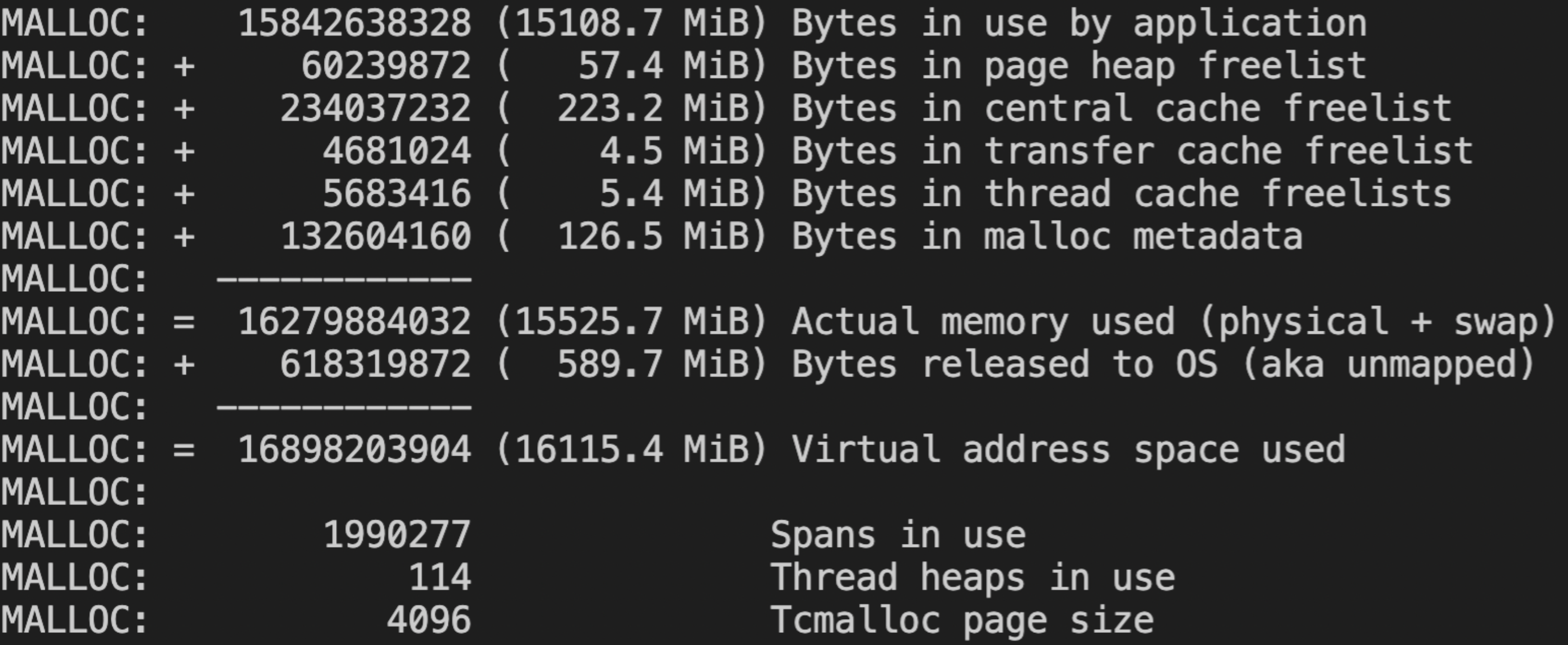
登录 MongoDB控制台,在系统监控页面,查看实例监控指标连接百分比的趋势变化图。连接百分比指当前集群的连接数量与最大连接数的比例。
使用建议
1. 快速回收内存。
tcmallocReleaseRate是一个用于控制内存释放的参数,它指定了当内存占用超过一定比例时,应该释放多少内存。tcmallocReleaseRate的值越高,MongoDB 释放内存的速度就越快,但是也会对性能产生一定的影响。在配置tcmallocReleaseRate时需要根据实际情况进行调整,以平衡内存使用和性能需求。执行如下命令,可配置tcmallocReleaseRate的值,其取值范围为[1,10]。diagnosticDataCollectionVerboseTCMalloc 为 true 时,可直接暴力回收内存,执行方式,如下所示:db.adminCommand( { setParameter: 1, tcmallocReleaseRate: 5.0 } )db.runCommand( { setParameter: 1, diagnosticDataCollectionVerboseTCMalloc:true} )
说明:
tcmallocReleaseRate 适用于云数据库 MongoDB 4.2及其之上的版本,且数据库实例为副本集。diagnosticDataCollectionVerboseTCMalloc 适用于云数据库 MongoDB 4.4及其之上的版本,且数据库实例为副本集。2. 控制并发连接数。
建议数据库中最大创建100个长连接,默认 MongoDB Driver 可以和后端建立100个连接池。当存在很多客户端时,降低每个客户端的连接池大小,⼀般建议与整个数据库建立的长连接控制在1000以内。连接百分比较高,请参见 连接使用率偏高异常分析及解决方法 进行调优。
3. 降低单次请求的内存开销。
4. 升级内存规格。
在连接数合适的情况下内存使用率持续升高,建议升级内存规格,避免内存溢出和大量清除缓存而导致系统性能急剧下滑。
提升 Mongod 的 CPU 与内存配置。具体信息,请参见 变更 Mongod 节点配置规格。
分片集群,可增加分片数量。具体操作,请参见 调整分片数量。
元数据信息内存
数据库 MongoDB 为每个集合维护一些元数据,例如索引信息、文档数量、存储引擎选项等。这些信息的管理会占用一定的系统资源。如果集合、索引等内存元数据数量很多,将会占用大量内存。特别是在云数据库 MongoDB 4.0之前的版本中,全量逻辑备份期间会打开大量文件句柄,但未能及时归还给操作系统,导致内存快速上涨。此外,在低版本的云数据库 MongoDB 中,大量删除集合后可能未能删除文件句柄,也会导致内存泄漏。
排查方法
统计云数据库 MongoDB 中的集合数量与索引数量,请使用如下命令分别统计:
use <database>;db.getCollectionNames().filter(function(c) { return !c.startsWith("system."); }).lengthdb.getCollectionNames().forEach(function(col) { print("Indexes for " + col + ": " + db.getCollection(col).getIndexes().length); })
查询集合数量,执行示例如下所示:
mongos> db.getCollectionNames().filter(function(c) { return !c.startsWith("system."); }).length4
查询每个集合的索引数量,执行示例如下所示:
mongos> db.getCollectionNames().forEach(function(col) { print("Indexes for " + col + ": " + db.getCollection(col).getIndexes().length); })Indexes for nba: 3Indexes for t1: 1Indexes for test: 1Indexes for user: 1
使用建议
在 MongoDB 中,建议将集合的个数保持在数千个以内。否则,导致 MongoDB 管理这些集合时的性能显著下降。
创建索引过程的内存消耗
MongoDB 在创建索引时可能会存在占用大量内存的情况。在正常的业务数据写入情况下,从节点会维持⼀个约256M的
buffer用于数据回放。在 MongoDB 4.2版本之前,主节点通过非后台方式创建索引时,后端回放创建索引是串行的,最多可能消耗500M内存。而在 MongoDB 4.2版本之后,默认废弃了 background 选项,允许从节点并行回放创建索引,导致消耗更多的内存。因此,如果在多个索引同时创建时,可能会导致实例内存溢出。另外,从节点在数据回放过程中也可能会消耗更多的内存,特别是在主节点完成索引创建后。排查方法

使用建议
避免在高峰期同时创建多个大型索引,可以将索引的创建时间分散开来。
尽量使用后台方式创建索引,以避免占用过多的内存。具体创建索引的方式,请参见 MongoDB 官网。
如果内存不足,可以考虑增加系统内存。具体操作,请参见 变更 Mongod 节点配置规格。
可以考虑使用更高效的索引类型,如文本搜索索引、地理位置索引等,以减少内存占用。请通过数据库智能管家(TencentDB for DBbrain,DBbrain)的 索引推荐 功能,选择最优索引。
对于较大的集合,可以考虑使用分片技术来分散数据和索引的存储,以减少单个实例的内存压力。
逻辑备份与主从切换产生的内存
逻辑备份通常会产生大量的数据扫描,导致内存占用较多。如果逻辑备份选择了从节点或者隐藏节点,将会出现从节点内存明显高于主节点的现象。
主从节点切换,原来的主节点变更为从节点,那么当前从节点内存较当前的主节点会明显偏高。
排查方法
1. 登录 MongoDB 控制台,请在任务管理页面确认是否有正在进行的备份任务。当前正在执行的任务通常在任务列表的最上面。单击操作列的任务详情,确认是否为逻辑备份。具体操作,请参见 任务管理。
2. 在任务管理页面的任务类型中,搜索切换主节点,确认业务侧是否进行了主从节点切换。
3. 单击系统监控页签,在左侧集群总览下拉菜单中,分别查看主节点与从节点的内存使用率。

使用建议
物理备份是通过物理文件拷贝来进行备份的。因此备份过程中消耗的内存相对较小。如果对从节点内存要求较高,请选择物理备份方式。各个版本所支持的备份方式,请参见 备份数据。
如果主从切换之后,业务侧没有设置读取从节点,请在控制台重启对应的从节点来释放内存,如果从节点有请求,建议在流量低峰期操作。


 是
是
 否
否
本页内容是否解决了您的问题?