
TaskManager 背压较高/严重事件

最后更新时间:2023-11-07 16:24:13
事件介绍
Flink 的 背压(也称为反压)描述了作业的一种异常现象:在作业的运行图中,某个算子因为下游算子处理能力较慢、网络传输链路拥塞等原因,无法将数据全速输出到下游算子,引发了数据堆积。随后这个堆积现象会逐步向上游的各个算子扩散,最终传递到数据源,造成数据消费量的减少。如果背压情况长期得不到改善,则作业的总体吞吐量会大幅下降,甚至降低到 0。
如果算子只有轻度的背压现象(例如 Flink Web UI 中算子的背压值小于 50%),则可以继续观察背压是否只是偶现的。如果背压值已经超过了50%(如下图),则很可能对作业的性能造成较大影响,需要尽快着手处理。
注意
该功能目前为 Beta 版,暂不支持规则的自定义,后续该能力会陆续上线。
判定标准
系统每5分钟会检测一次 Flink 作业的算子背压情况。如果发现某个算子的背压值(如果算子有多个并行度,则取最大值)高于50%,则继续向下查找,直到遇到第一个背压值(图中的 Backpressured)低于阈值,但是繁忙度(图中的 Busy)高于50% 的算子,该算子通常是处理速度较慢、引起背压的根源。此时如果 查看 Flink Web UI,可以看到一系列的灰色算子后紧跟着一个红色算子。
如果链路中某个算子的背压超过50% 但小于80%,会触发 TaskManager 背压较高事件。如果算子的背压超过80%,则会触发 TaskManager 背压严重事件。
注意
为了避免频繁告警,每个作业的每个运行实例 ID 每小时最多触发一次该事件的推送。
背压事件检测功能仅支持 Flink 1.13 及之后的版本。
告警配置
注意
TaskManager 背压较高(OceanusBackpressureHigh)、TaskManager 背压过高(OceanusBackpressureTooHigh) 为两种不同的告警事件。如果您只关心影响作业运行的严重背压事件,可以只配置后者的告警通知。
处理建议
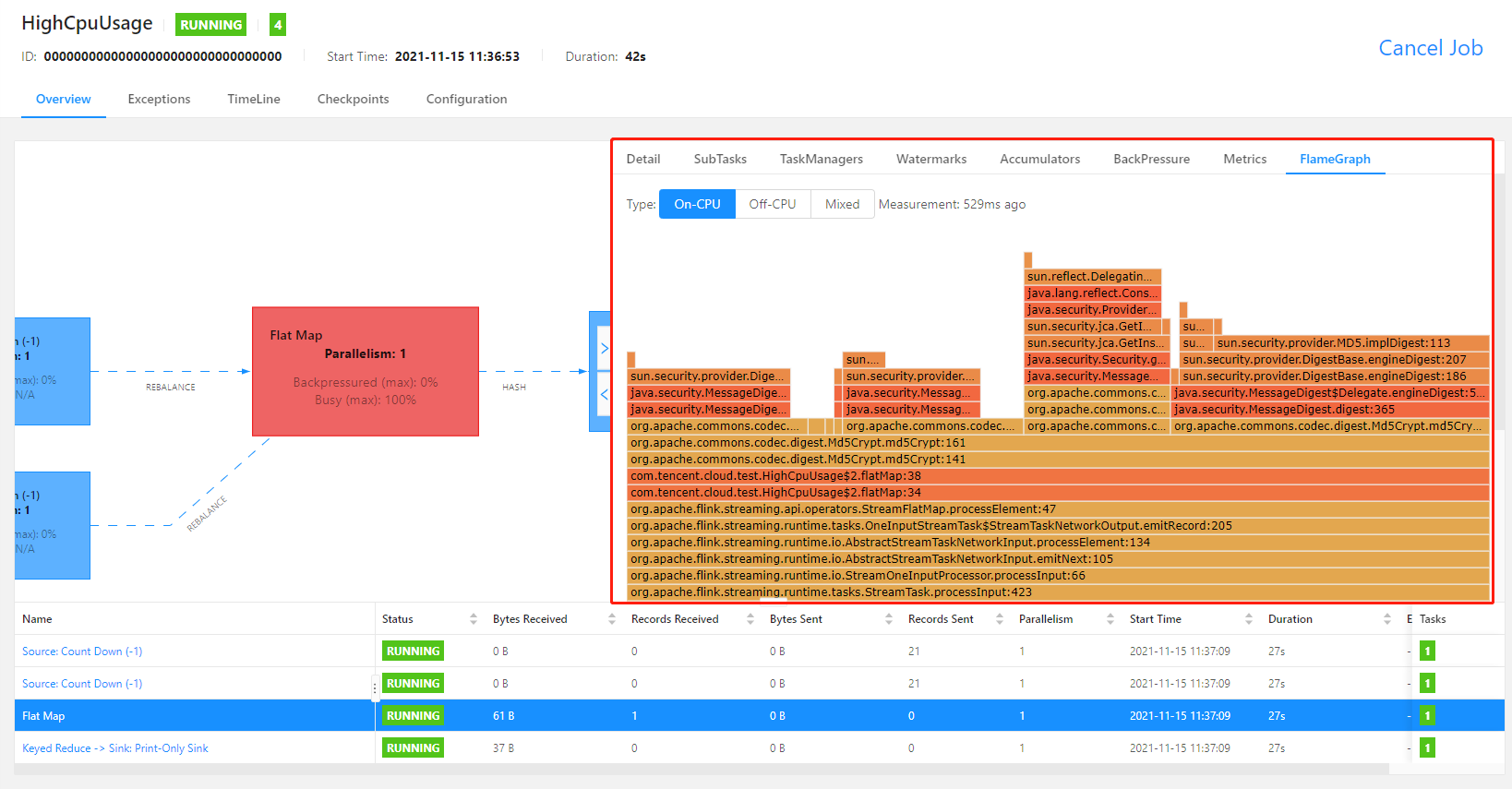
收到该事件推送后,我们建议立刻 查看 Flink Web UI,分析当前的运行图。如果可以找到引发背压的根源算子,则建议使用 Flink UI 内置的 火焰图功能 分析 CPU 调用热点,即占用 CPU 时间片较多的方法(首先需要在作业的 高级参数 选项中,加入
rest.flamegraph.enabled: true 参数,并重新发布作业版本,才可使用火焰图绘制功能)。例如下图的繁忙算子 CPU 火焰图中,MD5 计算的相关方法占用了大量的时间片,已经成为了作业的性能瓶颈。此时我们可以修改 Flink 作业中该算子的计算逻辑,避免如此高频地调用该方法,或者使用更高效的算法等优化措施。
此外,我们建议增加作业的 资源配置,例如调大 TaskManager 的规格(提升 TaskManager 的 CPU 配额,可以有更多的 CPU 资源来处理数据),提升作业的算子并行度(降低单个 TaskManager 的数据处理量,减少 CPU 计算压力)等,令数据能够更有效地处理。
文档反馈