You can use TMP to customize the reported metric monitoring data so as to monitor internal status of applications or services, such as the number of processed requests and the number of orders. You can also monitor the processing duration of some core logic, such as requesting external services.
This document uses Go as an example to describe how to use TMP to customize reported metrics, visualization, and alerting.
Supported Programming Languages
Official SDKs from the native Prometheus community:
Prometheus has multidimensional analysis capabilities. A data model consists of the following parts:
Metric Name + Labels + Timestamp + Value/Sample
Metric Name: monitoring object (for example, http_request_total indicates the current total number of HTTP requests received by the system).
Labels: characteristics dimensions of the current sample, which are in K/V structure. Through such dimensions, Prometheus can filter, aggregate, and perform other operations on the sample data.
Timestamp: a timestamp accurate down to the millisecond
Value: a float64 value, which indicates the current sample value.
Metric Name/Labels can contain only ASCII characters, digits, underscores, and colons and must comply with the regular expression [a-zA-Z_:][a-zA-Z0-9_:]*.
For more information on a data model, please see DATA MODEL.
Prometheus provides four metric types for different monitoring scenarios: Counter, Gauge, Histogram, and Summary, as described below. For more information, please see METRIC TYPES.
The Prometheus community provides SDKs for multiple programing languages, all of which are basically similar in usage but differ mostly in syntax. This document uses Go as an example to describe how to report custom monitoring metrics.
Counter
A metric in Counter type increases monotonically and will be reset after service restart. You can use counters to monitor the numbers of requests, exceptions, user logins, orders, etc.
You can use a counter to monitor the number of orders as follows:
For example, you can use the rate() function to get the order increase rate:
rate(order_service_processed_orders_total[5m])
Gauge
A gauge is a current value, which can be increased or reduced during metric timestamping. You can use gauges to monitor the current memory utilization, CPU utilization, current number of threads, queue size, etc.
You can use a gauge to monitor the size of an order queue as follows:
queueSize.WithLabelValues("make_order").Inc()// Order placement queue
// queueSize.WithLabelValues("cancel_order").Inc() // Order cancellation queue
}
// Consume an order message
func(q *OrderQueue)consumeOrder(){
// Consume an order message
// Reduce the queue size by 1
queueSize.WithLabelValues("make_order").Dec()
}
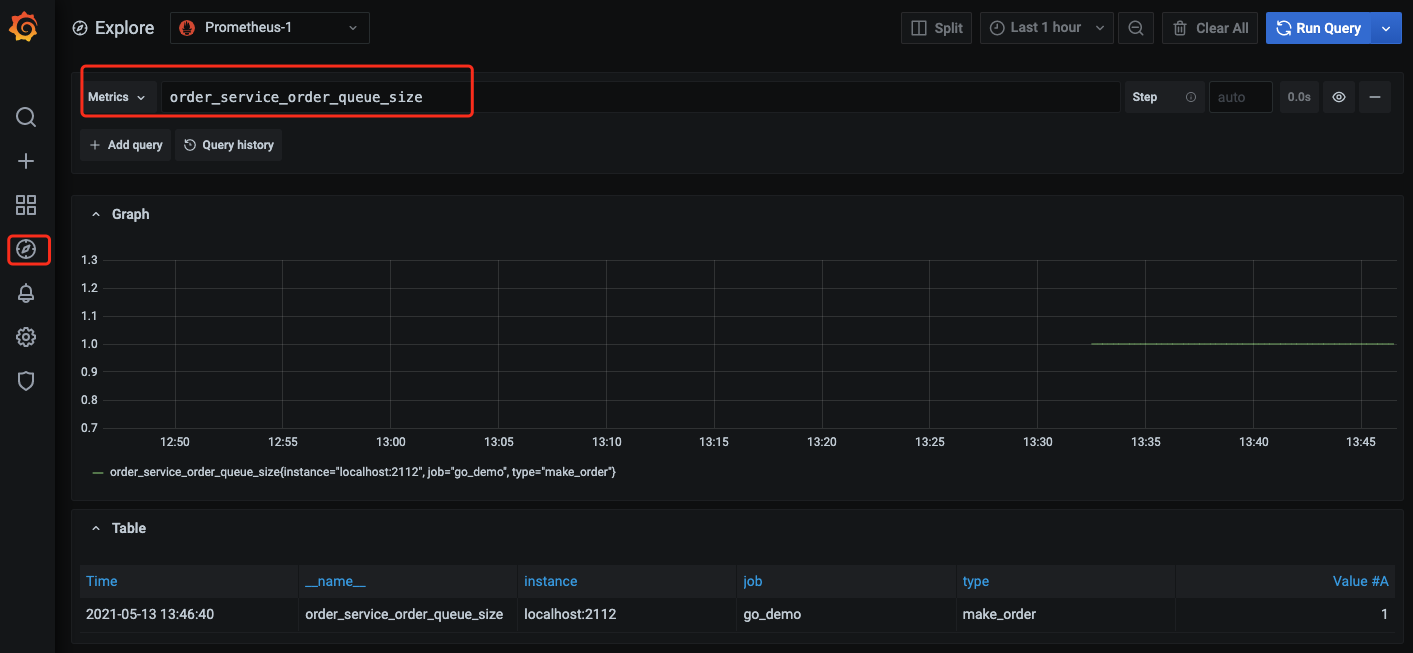
You can use the gauge metric to directly view the current size of each type of queue of an order:
order_service_order_queue_size
Histogram
Prometheus calculates the sample distribution based on the configured Bucket to generate a histogram, which can be processed subsequently and is generally used for duration monitoring. For example, you can use a histogram to calculate the latencies of P99, P95, and P50 and monitor the numbers of processed items. With histograms, you don't need to use counters to count items. In addition, you can use histograms to monitor metrics such as API response time and database access time.
A histogram can be used in a similar way to a summary, so you can directly refer to the summary usage.
Summary
A summary is similar to a histogram, as it also calculates the sample distribution, but their differences lie in that a summary calculates the distribution (P99/P95/Sum/Count) on the client and therefore uses more client resources, and the data cannot be calculated and processed in an aggregated manner subsequently. You can use summaries to monitor metrics such as API response time and database access duration.
You can use a summary to monitor the order processing duration as follows:
After the tracking of custom metrics for your business is completed and the application is released, you can use Prometheus to collect the monitoring metric data. For more information, please see Go Integration.
Viewing Monitoring Data and Alerts
Open the Grafana service that comes with TMP and use Explore to view the monitoring metric data as shown below. You can also customize Grafana monitoring dashboards.
You can use Prometheus together with the alarming capabilities of Cloud Monitor to trigger alerts for custom monitoring metrics in real time. For more information, please see Alert Overview and Usage.