
实例诊断

最后更新时间:2024-07-30 18:14:31
背景
为了提升客户在使用 Prometheus 监控采集端的体验,现提供了新的采集端架构,升级后的采集端新架构支持实例诊断、系统健康检查,并提升了采集 Agent 资源利用率和指标采集稳定性。本文将指引用户通过控制台实例诊断页面将旧采集架构升级到新采集架构,并获取关于当前实例采集和存储的细节信息,以获得更优质的使用体验。
操作步骤
升级新架构
1. 登录 Prometheus 监控服务控制台。
2. 在 Prometheus 实例列表中,单击实例 ID/名称 。
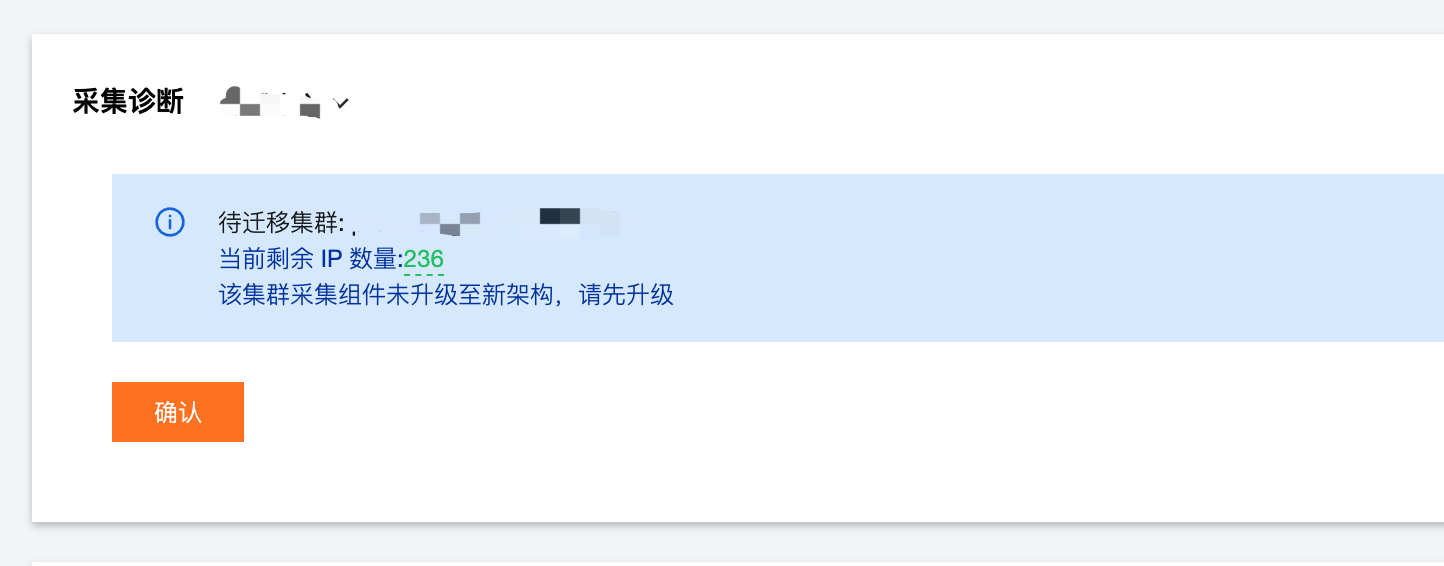
3. 进入 Prometheus 管理中心,在顶部导航栏中单击实例诊断,并选择对应的采集集群。
点击确认即可升级新架构。
注意:
升级过程预计需要5分钟,可能存在1-2分钟的指标断点。
若实例的托管集群中 IP 数量少于10个会出现风险提示,为防止由于 IP 数量不足问题导致组件无法正常升级,请根据下文指引增加可用 IP 数量。
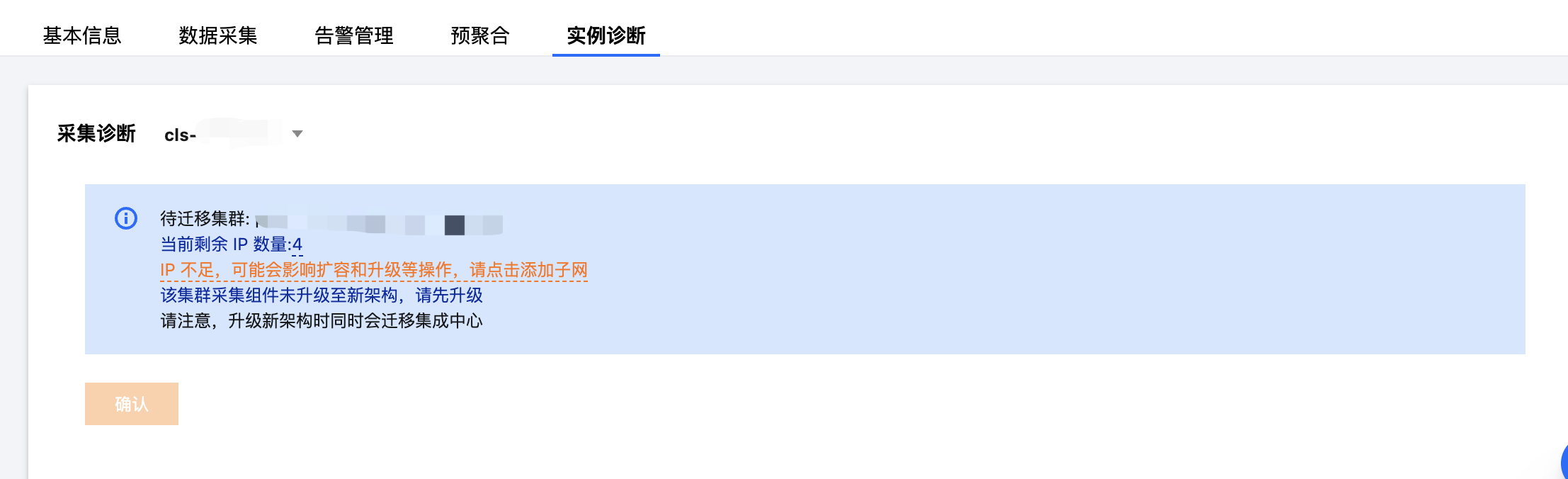
添加子网
1. 在实例诊断页面中点击子网信息,进入托管集群子网管理页面。
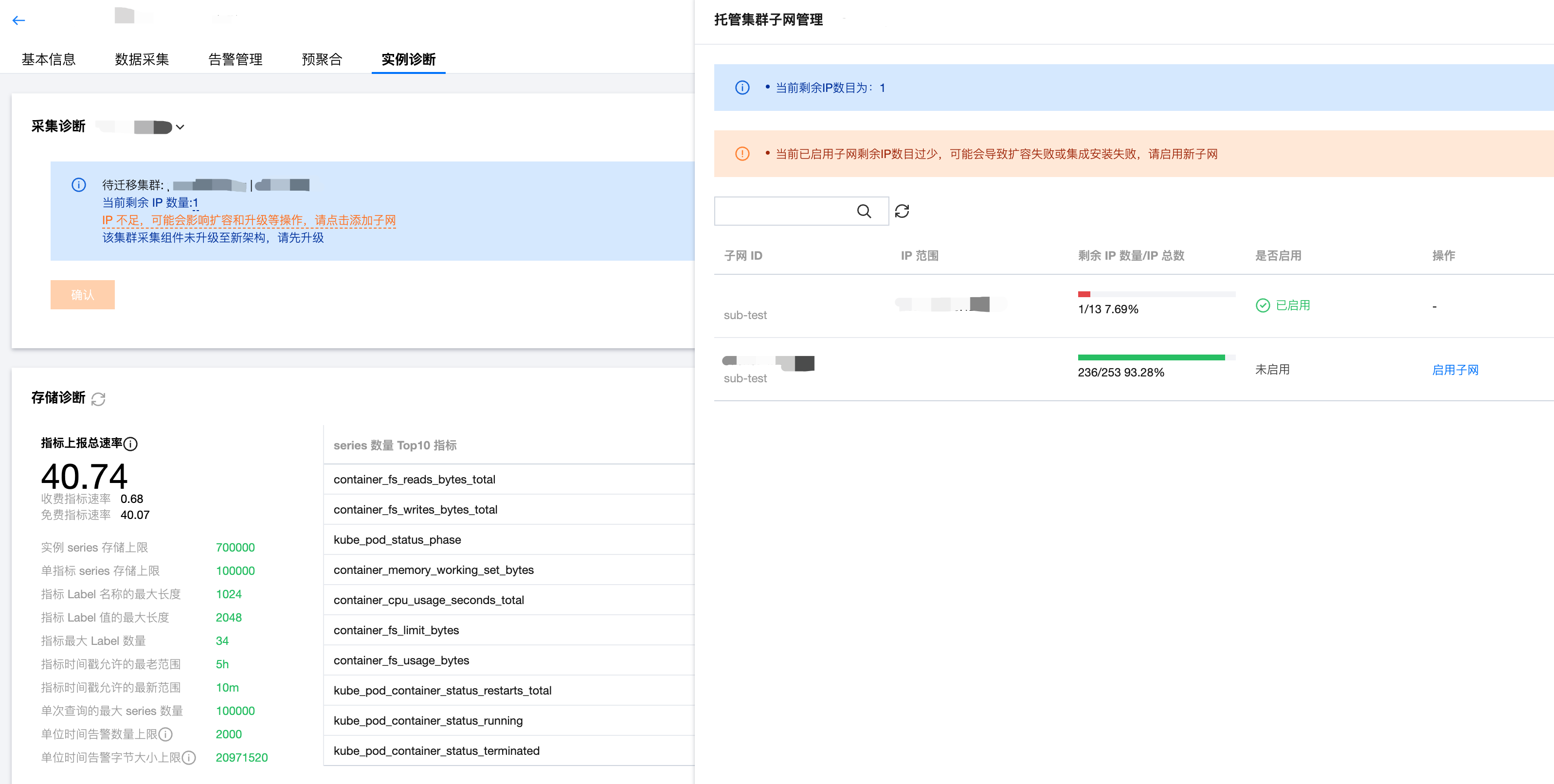
2. 页面当前 VPC 内已经添加到托管集群内的子网和未添加的子网,可根据规划点击启用子网启用剩余 IP 足够的子网。
3. 若没有可用子网,请先 添加子网 后再在当前页面中启用。
实例诊断
架构升级后,实例诊断页面包括采集和存储两个部分的内容,有助于用户了解 Prometheus 采集和存储的运行情况,从而更加快速地定位存在的问题。
采集诊断
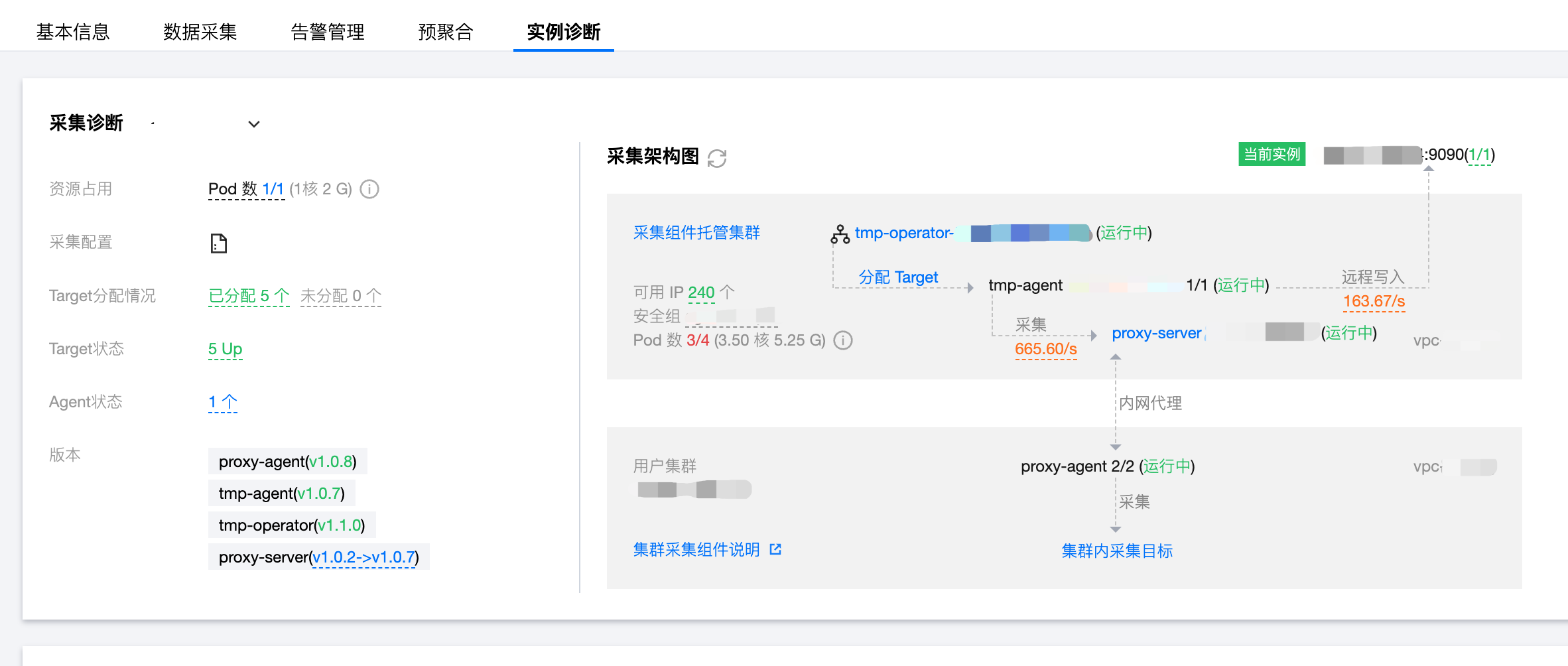
如图所示,采集诊断包括对应采集的资源占用、采集配置、Target 分配情况、Target 状态、Agent 状态、组件版本以及采集的架构图。
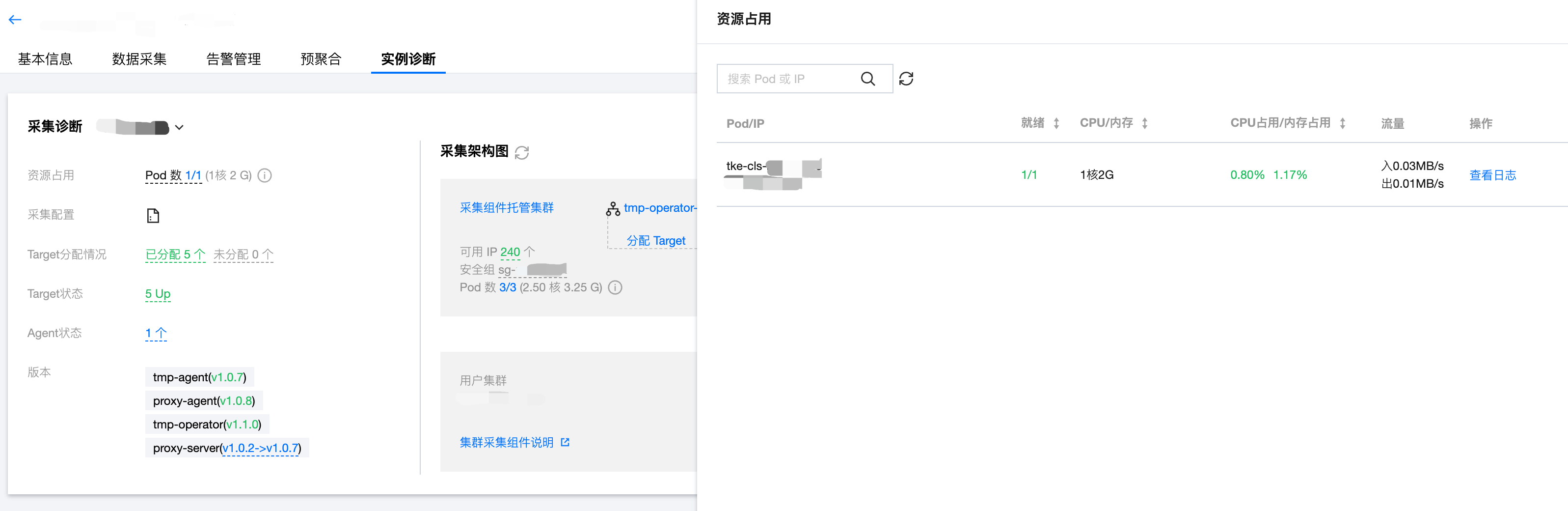
资源占用
采集分片的资源占用情况,展示了包括 CPU、内存上限和占用以及出入流量等信息;点击查看日志可以看到该 Pod 的日志,便于查看运行细节和排查异常问题。
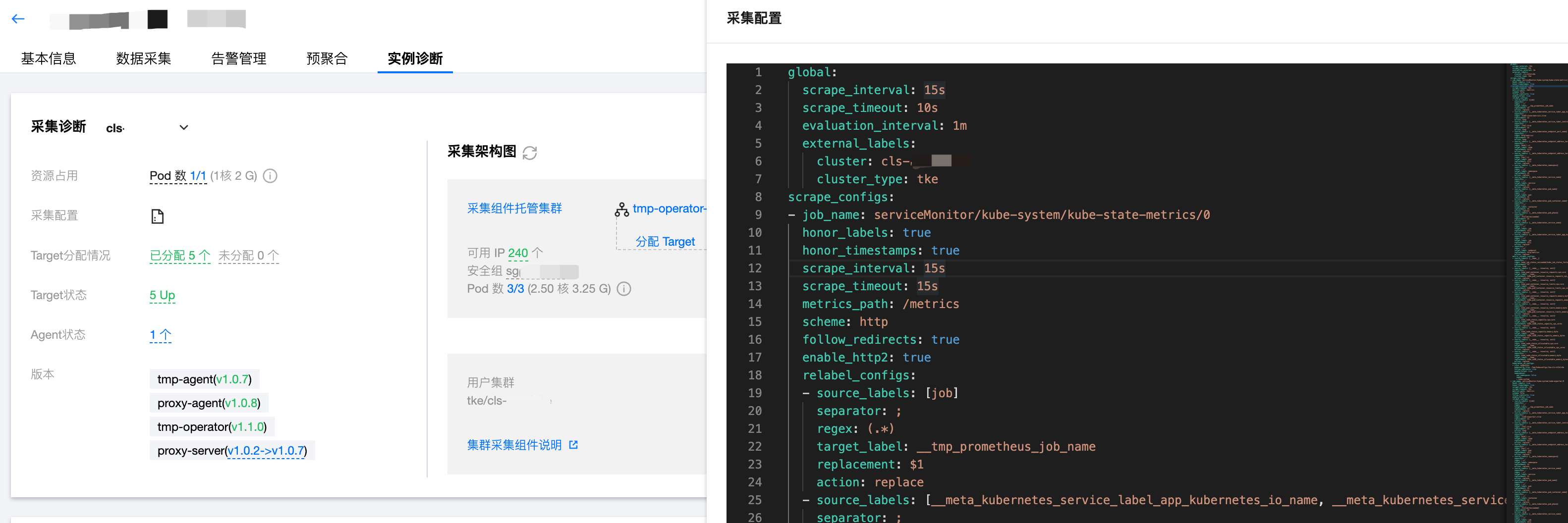
采集配置
展示了当前采集的具体采集配置。
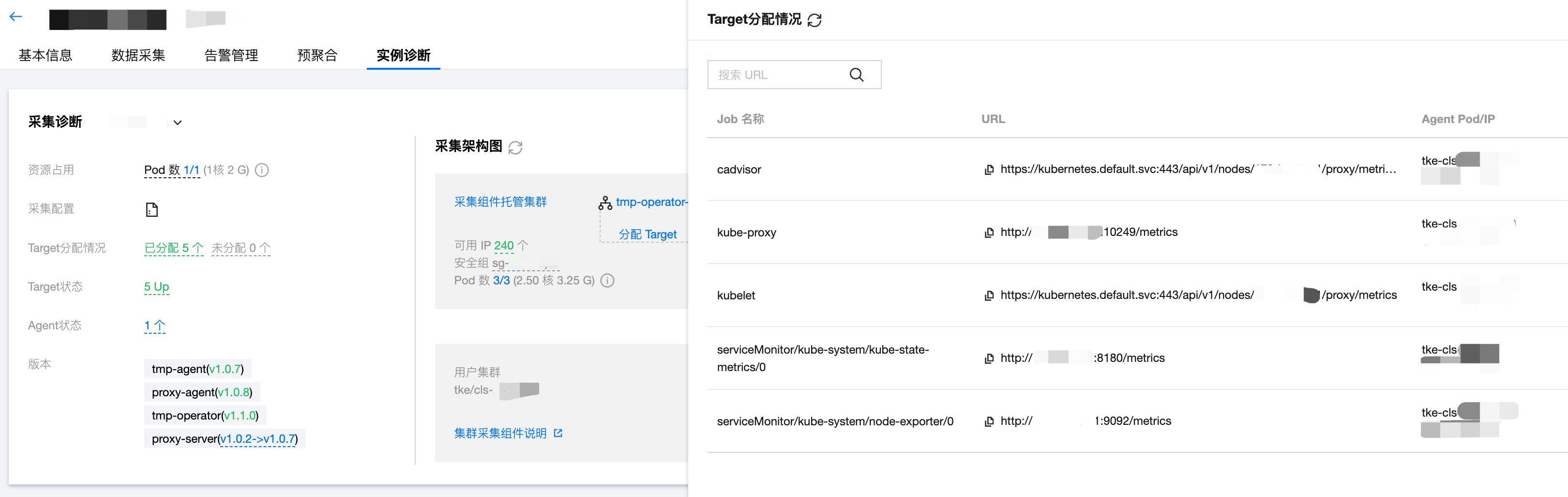
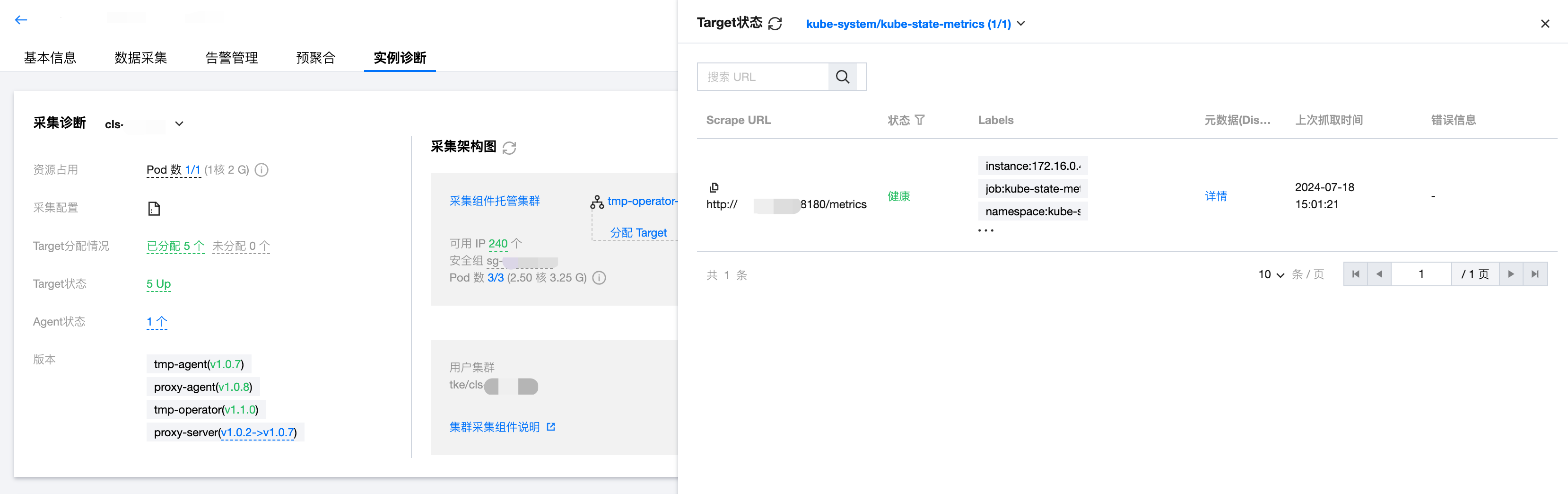
Target 分配情况
展示了采集目标 Target 的 URL、Target 所属的采集任务 Job 名称,以及目前由哪个采集分片进行采集。
Target 状态
可根据采集任务 Job 筛选活跃的采集目标 Targets,并获取对应 Target 的状态、Labels、Discovered Labels 等信息。Target 状态在正常情况下是“健康”,若为“异常”且已经有过上次抓取时间,可根据最右边的错误信息进行排查,常见的问题可能为 Target 本身不健康、权限配置错误、网络错误等等。
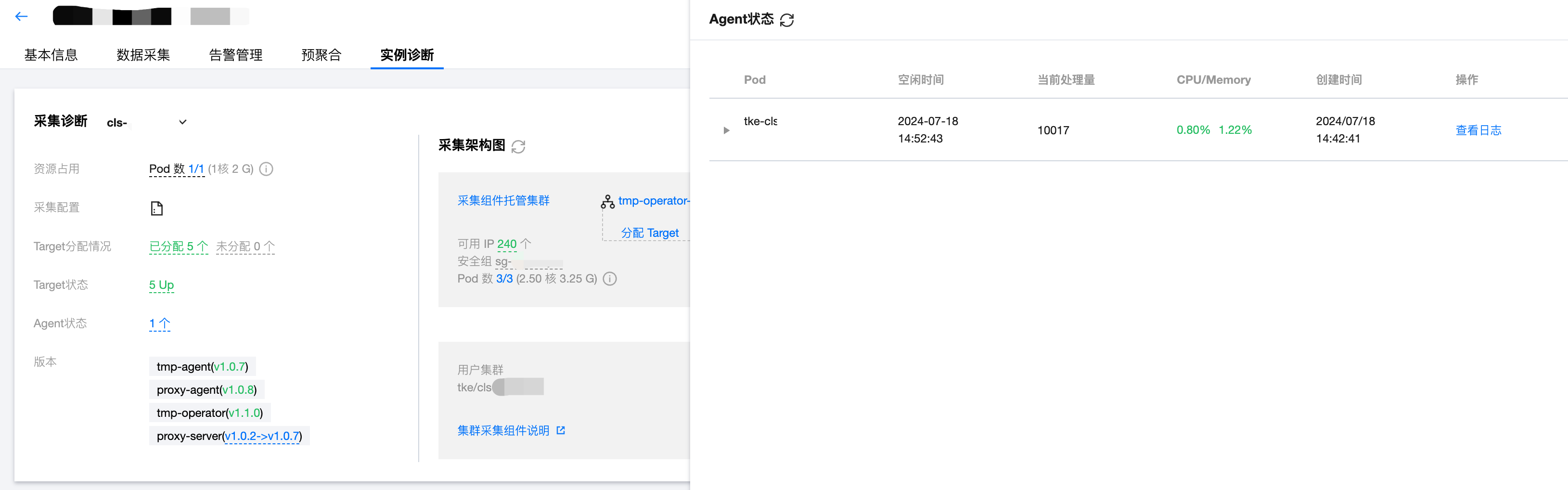
Agent 状态
展示了采集分片 Agent 的运行状态;点击查看日志可以看到该 Pod 的日志以了解运行细节和排查异常问题。
组件版本
当前采集的组件版本信息,点击进入组件版本页面,包括 IP 数量检查和各组件版本的当前版本、最新版本和组件描述、升级描述等信息。
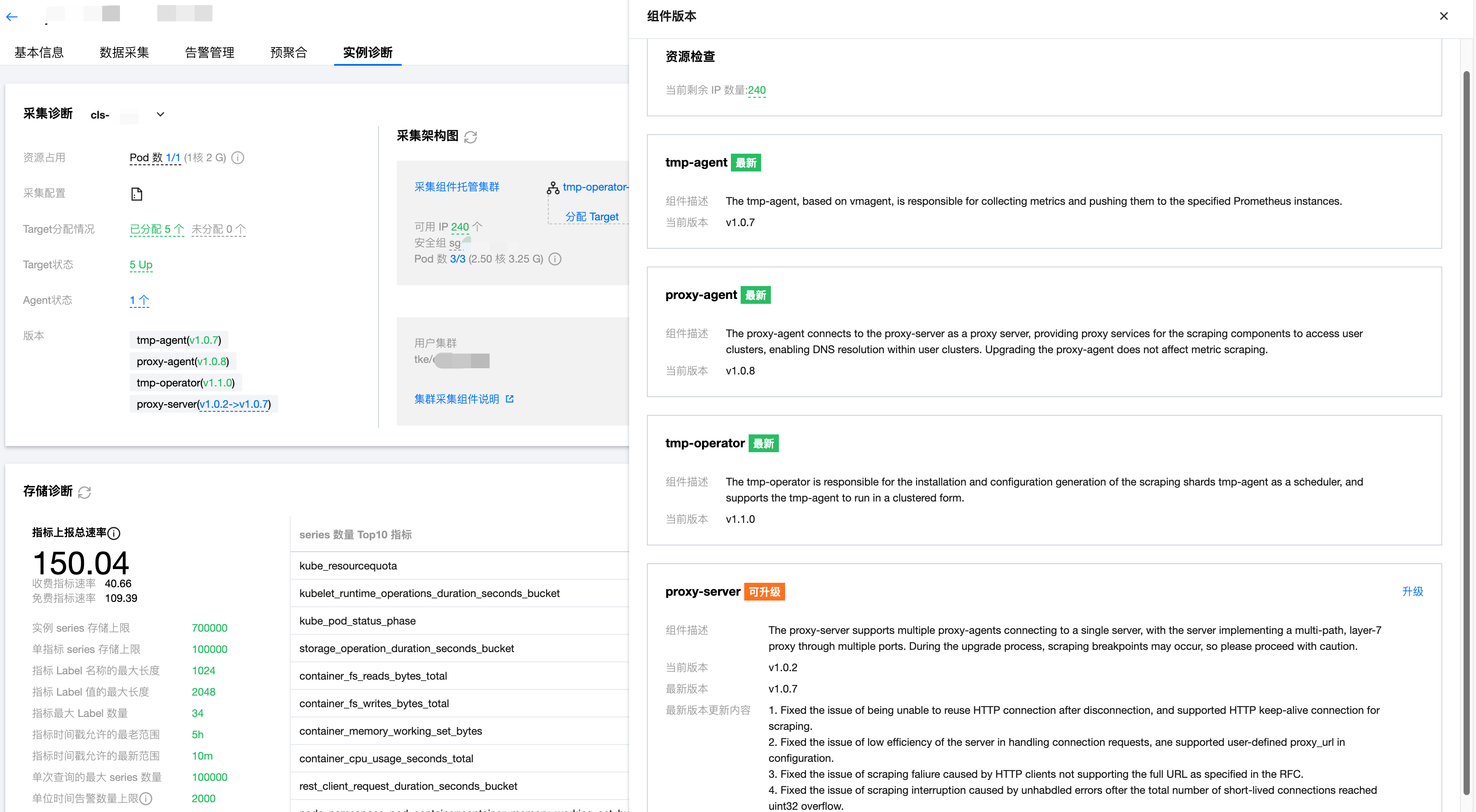
说明:
采集组件请尽量保持最新版本,可通过对应组件的升级进行升级;
组件 tmp-operator、tmp-agent、proxy-agent 正常情况下能够无影响升级;
组件 proxy-server 在升级过程中会出现采集断点,断点时长为 eks 拉起组件 Pod 的时间,并且影响范围是整个 Prometheus 实例的采集(包括集成中心和容器集群),请谨慎操作。
采集架构图
通过采集架构图可以了解当前的采集架构信息。
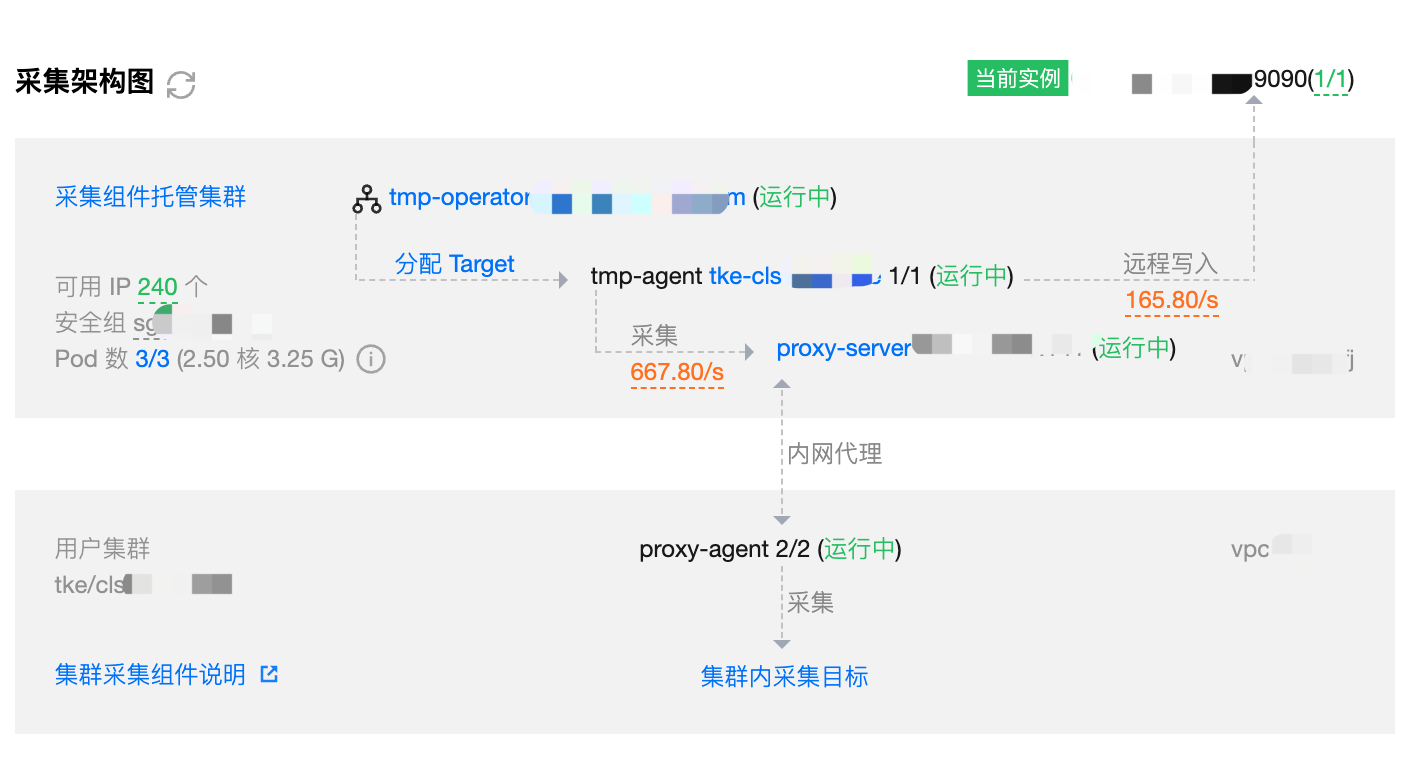
采集组件托管集群:
可用 IP 数量,当 IP 数量不足时会出现 IP 数量不足的提示,点击进入托管集群子网管理页面,具体操作可参考前面 添加子网;
托管集群的安全组,及其正常运行的放通要求,采集出现的部分网络问题可能是因为安全组未放通;
当前采集相关的 Pod 数量及资源使用情况;
采集调度组件 tmp-operator 的运行状态;
采集目标 Target 分配情况;
采集分片组件 tmp-agent 的运行状态;
指标采集速率及入带宽;
代理组件 proxy-server 的运行状态;
指标写入速率及出带宽;
写入目标状态,包括当前实例对应的存储和用户配置的数据多写。
用户集群:
公网代理 CLB 的状态(若开启);
代理组件 proxy-agent 的运行状态;
集群内采集目标 Target 的状态。
存储诊断
如图所示,存储诊断包括了存储相关的状态和限制。
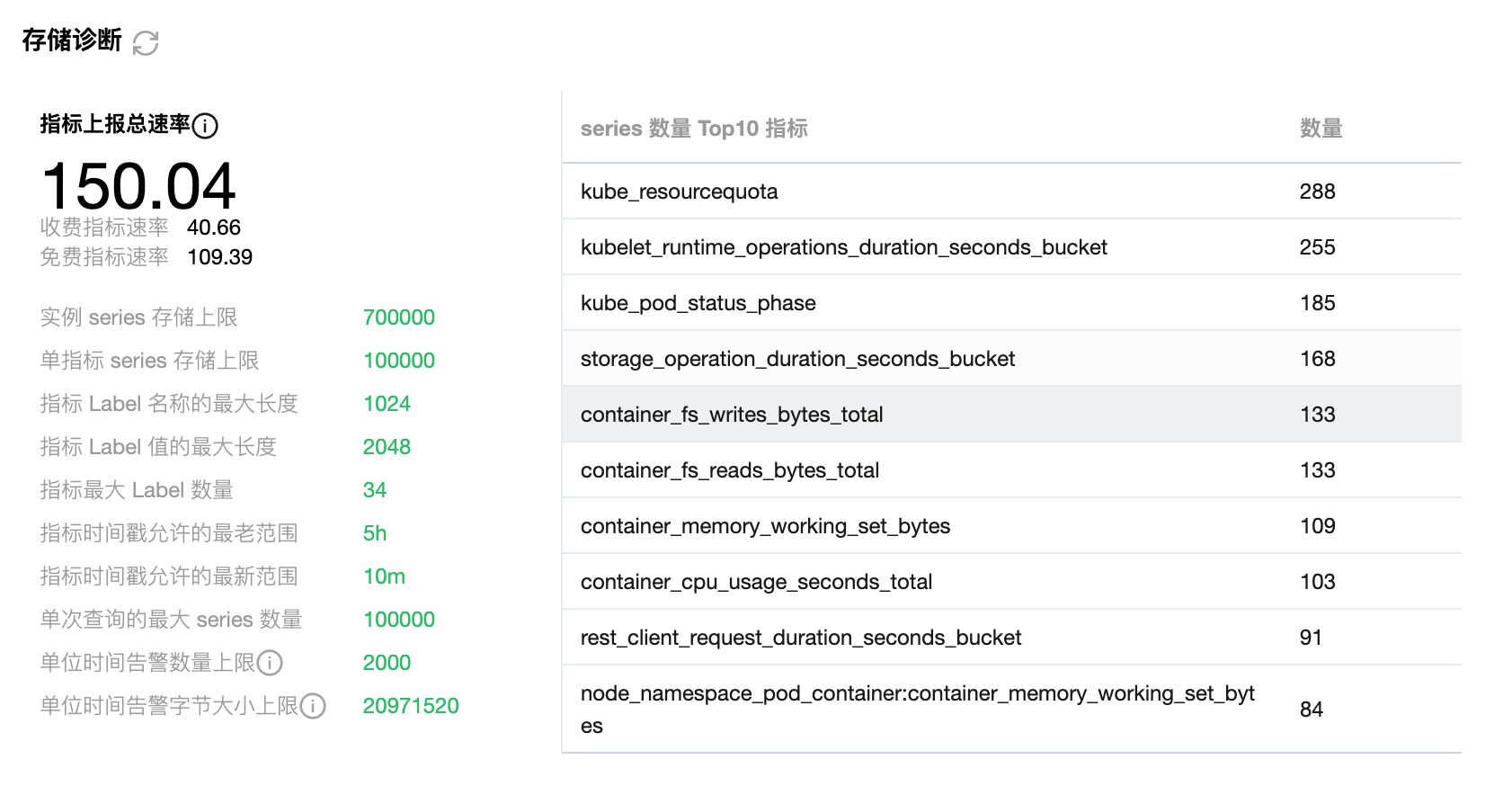
参数说明
参数 | 说明 |
指标上报总速率 | 包括免费指标和收费指标。 |
实例 series 存储上限 | 活跃的 series 数量超过该值会因为超限丢弃。 |
单指标 series 存储上限 | 相同指标名不同 label 是不同的 series,超过该值会因为超限丢弃。 |
指标标签 Label 名称的最大长度 | 超过该值会因为不合法而丢弃。 |
指标最大 Label 数量 | 超过该值会因为不合法而丢弃。 |
指标时间戳允许的最老范围 | 单条 series 中可以接受的最老时间戳(不允许乱序)。 |
指标时间戳允许的最新范围 | 单条 series 中可以接受的最新时间戳(不允许乱序)。 |
单次查询的最大 series 数量 | 查询数据时最大涉及的 series 数量,建议缩短范围查询 Range Query 的时间,或在合适的场景使用即时查询 Instant Query。 |
单位时间告警数量上限 | 5分钟内触发告警数量上限。 |
单位时间告警字节大小上限 | 5分钟内触发告警的标签、Annotation 等字段总的大小上限。 |
series 数量 Top10 指标 | 同一指标名称,不同标签 Label 的键值都是不同的 series,存储收到单指标 series 存储上限限制,数量过大会产生高基数问题。 |
文档反馈