We use cookies that are necessary to provide the Tencent Cloud website. We would also like to use other cookies to improve your experience, optimise and analyse Tencent Cloud website features and usage. For more information, please refer to our Cookies Policy.
































14天试用边缘安全加速平台 EO 限时免费
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 控制台指南
- 工具指南
- 实践教程
- 开发者指南
- 数据湖存储
- 数据处理
- 故障处理
- API 文档
- 简介
- 公共请求头部
- 公共响应头部
- 错误码
- 请求签名
- 操作列表
- Service 接口
- Bucket 接口
- Object 接口
- 批量处理接口
- 数据处理接口
- 任务与工作流
- 内容审核接口
- 云查毒接口
- SDK 文档
- SDK 概览
- 准备工作
- Android SDK
- C SDK
- C++ SDK
- .NET(C#) SDK
- Flutter SDK
- Go SDK
- iOS SDK
- Java SDK
- JavaScript SDK
- Node.js SDK
- PHP SDK
- Python SDK
- React Native SDK
- 小程序 SDK
- 错误码
- 常见问题
- 相关协议
- 附录
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 控制台指南
- 工具指南
- 实践教程
- 开发者指南
- 数据湖存储
- 数据处理
- 故障处理
- API 文档
- 简介
- 公共请求头部
- 公共响应头部
- 错误码
- 请求签名
- 操作列表
- Service 接口
- Bucket 接口
- Object 接口
- 批量处理接口
- 数据处理接口
- 任务与工作流
- 内容审核接口
- 云查毒接口
- SDK 文档
- SDK 概览
- 准备工作
- Android SDK
- C SDK
- C++ SDK
- .NET(C#) SDK
- Flutter SDK
- Go SDK
- iOS SDK
- Java SDK
- JavaScript SDK
- Node.js SDK
- PHP SDK
- Python SDK
- React Native SDK
- 小程序 SDK
- 错误码
- 常见问题
- 相关协议
- 附录
- 词汇表
Hadoop 工具依赖 Hadoop-2.7.2 及以上版本,实现了以腾讯云对象存储(Cloud Object Storage,COS)作为底层存储文件系统运行上层计算任务的功能。启动 Hadoop 集群主要有单机、伪分布式和完全分布式等三种模式,本文主要以 Hadoop-2.7.4 版本为例进行 Hadoop 完全分布式环境搭建及 wordcount 简单测试介绍。
准备环境
准备若干台机器。
安装配置系统,可前往 CentOS 官网 下载安装。本文使用 CentOS 7.3.1611系统版本。
安装 Java 环境,具体操作请参见 Java 安装与配置。
安装 Hadoop 可用包:Apache Hadoop Releases Download。
网络配置
使用
ifconfig -a 查看各台机器的 IP,相互使用 ping 命令检查 ,看是否可以 ping 通,同时记录每台机器的 IP。配置 CentOS
配置 hostname
分别给机器设置相应 hostname,如"master"、"slave*"等。
hostnamectl set-hostname master
配置 hosts
vi /etc/hosts
编辑内容:
202.xxx.xxx.xxx master202.xxx.xxx.xxx slave1202.xxx.xxx.xxx slave2202.xxx.xxx.xxx slave3# IP 地址替换为真实 IP
关闭防火墙
systemctl status firewalld.service # 检查防火墙状态systemctl stop firewalld.service # 关闭防火墙systemctl disable firewalld.service # 禁止开机启动防火墙
时间同步
yum install -y ntp # 安装 ntp 服务ntpdate cn.pool.ntp.org # 同步网络时间
安装配置 JDK
上传 JDK 安装包(如jdk-8u144-linux-x64.tar.gz)到
root 根目录。mkdir /usr/javatar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/java/rm -rf jdk-8u144-linux-x64.tar.gz
各个主机之间复制 JDK
scp -r /usr/java slave1:/usrscp -r /usr/java slave2:/usrscp -r /usr/java slave3:/usr.......
配置各个主机 JDK 环境变量
vi /etc/profile
编辑内容:
export JAVA_HOME=/usr/java/jdk1.8.0_144export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
保存文件后,使/etc/profile 生效,执行以下命令:
source /etc/profile # 使配置文件生效java -version # 查看 java 版本
配置 SSH 无密钥访问
分别在各个主机上检查 SSH 服务状态:
systemctl status sshd.service # 检查 SSH 服务状态yum install openssh-server openssh-clients # 安装 SSH 服务,如果已安装,则不用执行该步骤systemctl start sshd.service # 启动 SSH 服务,如果已安装,则不用执行该步骤
分别在各个主机上生成密钥:
ssh-keygen -t rsa # 生成密钥
在 slave1 上:
cp ~/.ssh/id_rsa.pub ~/.ssh/slave1.id_rsa.pubscp ~/.ssh/slave1.id_rsa.pub master:~/.ssh
在 slave2 上:
cp ~/.ssh/id_rsa.pub ~/.ssh/slave2.id_rsa.pubscp ~/.ssh/slave2.id_rsa.pub master:~/.ssh
依此类推...
在 master 上:
cd ~/.sshcat id_rsa.pub >> authorized_keyscat slave1.id_rsa.pub >>authorized_keyscat slave2.id_rsa.pub >>authorized_keysscp authorized_keys slave1:~/.sshscp authorized_keys slave2:~/.sshscp authorized_keys slave3:~/.ssh
安装配置 Hadoop
安装 Hadoop
上传 hadoop 安装包(如 hadoop-2.7.4.tar.gz)到
root 根目录。tar -zxvf hadoop-2.7.4.tar.gz -C /usrrm -rf hadoop-2.7.4.tar.gzmkdir /usr/hadoop-2.7.4/tmpmkdir /usr/hadoop-2.7.4/logsmkdir /usr/hadoop-2.7.4/hdfmkdir /usr/hadoop-2.7.4/hdf/datamkdir /usr/hadoop-2.7.4/hdf/name
进入
hadoop-2.7.4/etc/hadoop 目录下,进行下一步操作。配置 Hadoop
1. 修改
hadoop-env.sh 文件,增加如下内容:export JAVA_HOME=/usr/java/jdk1.8.0_144
若 SSH 端口不是默认的22,可在
hadoop-env.sh 文件里修改:export HADOOP_SSH_OPTS="-p 1234"
2. 修改
yarn-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_144
3. 修改
slaves配置内容:
删除:localhost添加:slave1slave2slave3
4. 修改
core-site.xml<configuration><property><name>fs.default.name</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/hadoop-2.7.4/tmp</value></property></configuration>
5. 修改
hdfs-site.xml<configuration><property><name>dfs.datanode.data.dir</name><value>/usr/hadoop-2.7.4/hdf/data</value><final>true</final></property><property><name>dfs.namenode.name.dir</name><value>/usr/hadoop-2.7.4/hdf/name</value><final>true</final></property></configuration>
6. 将
mapred-site.xml.template 拷贝一份出来命名为 mapred-site.xmlcp mapred-site.xml.template mapred-site.xml
7. 修改
mapred-site.xml<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property></configuration>
8. 修改
yarn-site.xml<configuration><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.mapred.ShuffleHandler</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property></configuration>
9. 各个主机之间复制 Hadoop
scp -r /usr/hadoop-2.7.4 slave1:/usrscp -r /usr/hadoop-2.7.4 slave2:/usrscp -r /usr/hadoop-2.7.4 slave3:/usr
10. 各个主机配置 Hadoop 环境变量
打开配置文件:
vi /etc/profile
编辑内容:
export HADOOP_HOME=/usr/hadoop-2.7.4export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport HADOOP_LOG_DIR=/usr/hadoop-2.7.4/logsexport YARN_LOG_DIR=$HADOOP_LOG_DIR
使配置文件生效:
source /etc/profile
启动 Hadoop
1. 格式化 namenode
cd /usr/hadoop-2.7.4/sbinhdfs namenode -format
2. 启动
cd /usr/hadoop-2.7.4/sbinstart-all.sh
3. 检查进程
master 主机包含 ResourceManager、SecondaryNameNode、NameNode 等,则表示启动成功,例如:
2212 ResourceManager2484 Jps1917 NameNode2078 SecondaryNameNode
各个 slave 主机包含 DataNode、NodeManager 等,则表示启用成功,例如:
17153 DataNode17334 Jps17241 NodeManager
运行 wordcount
由于 Hadoop 自带 wordcount 例程,所以可以直接调用。在启动 Hadoop 之后,我们可以通过以下命令来对 HDFS 中的文件进行操作:
hadoop fs -mkdir /inputhadoop fs -put input.txt /inputhadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /input /output/
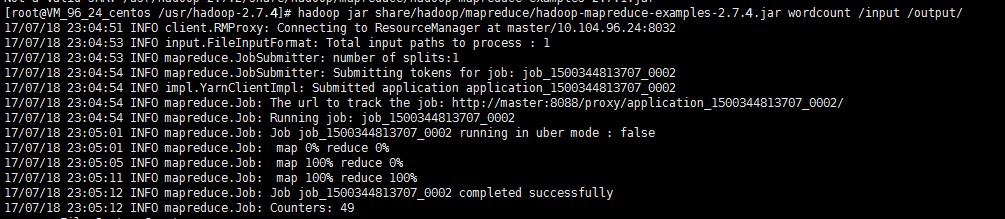
出现如上图结果就说明 Hadoop 安装已经成功了。
查看输出目录
hadoop fs -ls /output
查看输出结果
hadoop fs -cat /output/part-r-00000
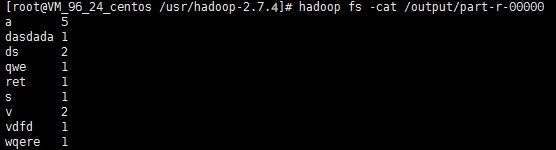
说明:

 是
是
 否
否
本页内容是否解决了您的问题?