- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- EMR on CVM 操作指南
- EMR on TKE 操作指南
- EMR Serverless HBase 操作指南
- EMR 开发指南
- Hadoop开发指南
- Spark 开发指南
- HBASE开发指南
- Phoenix on Hbase 开发指南
- Hive 开发指南
- Presto开发指南
- Sqoop 开发指南
- Hue 开发指南
- Oozie 开发指南
- Flume 开发指南
- Kerberos 开发指南
- Knox 开发指南
- Alluxio 开发指南
- Kylin 开发指南
- Livy 开发指南
- Kyuubi 开发指南
- Zeppelin 开发指南
- Hudi 开发指南
- Superset 开发指南
- Impala 开发指南
- Druid 开发指南
- Tensorflow 开发指南
- Kudu 开发指南
- Ranger 开发指南
- Kafka 开发指南
- Iceberg 开发指南
- StarRocks 开发指南
- Flink 开发指南
- 实践教程
- API 文档
- 常见问题
- 服务等级协议
- 联系我们
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- EMR on CVM 操作指南
- EMR on TKE 操作指南
- EMR Serverless HBase 操作指南
- EMR 开发指南
- Hadoop开发指南
- Spark 开发指南
- HBASE开发指南
- Phoenix on Hbase 开发指南
- Hive 开发指南
- Presto开发指南
- Sqoop 开发指南
- Hue 开发指南
- Oozie 开发指南
- Flume 开发指南
- Kerberos 开发指南
- Knox 开发指南
- Alluxio 开发指南
- Kylin 开发指南
- Livy 开发指南
- Kyuubi 开发指南
- Zeppelin 开发指南
- Hudi 开发指南
- Superset 开发指南
- Impala 开发指南
- Druid 开发指南
- Tensorflow 开发指南
- Kudu 开发指南
- Ranger 开发指南
- Kafka 开发指南
- Iceberg 开发指南
- StarRocks 开发指南
- Flink 开发指南
- 实践教程
- API 文档
- 常见问题
- 服务等级协议
- 联系我们
功能介绍
集群事件中包含事件列表和事件策略。
事件列表:记录集群发生的关键变化事件或异常事件。
事件策略:支持根据业务情况自定义事件监控触发策略,已开启监控的事件可设置为集群巡检项。
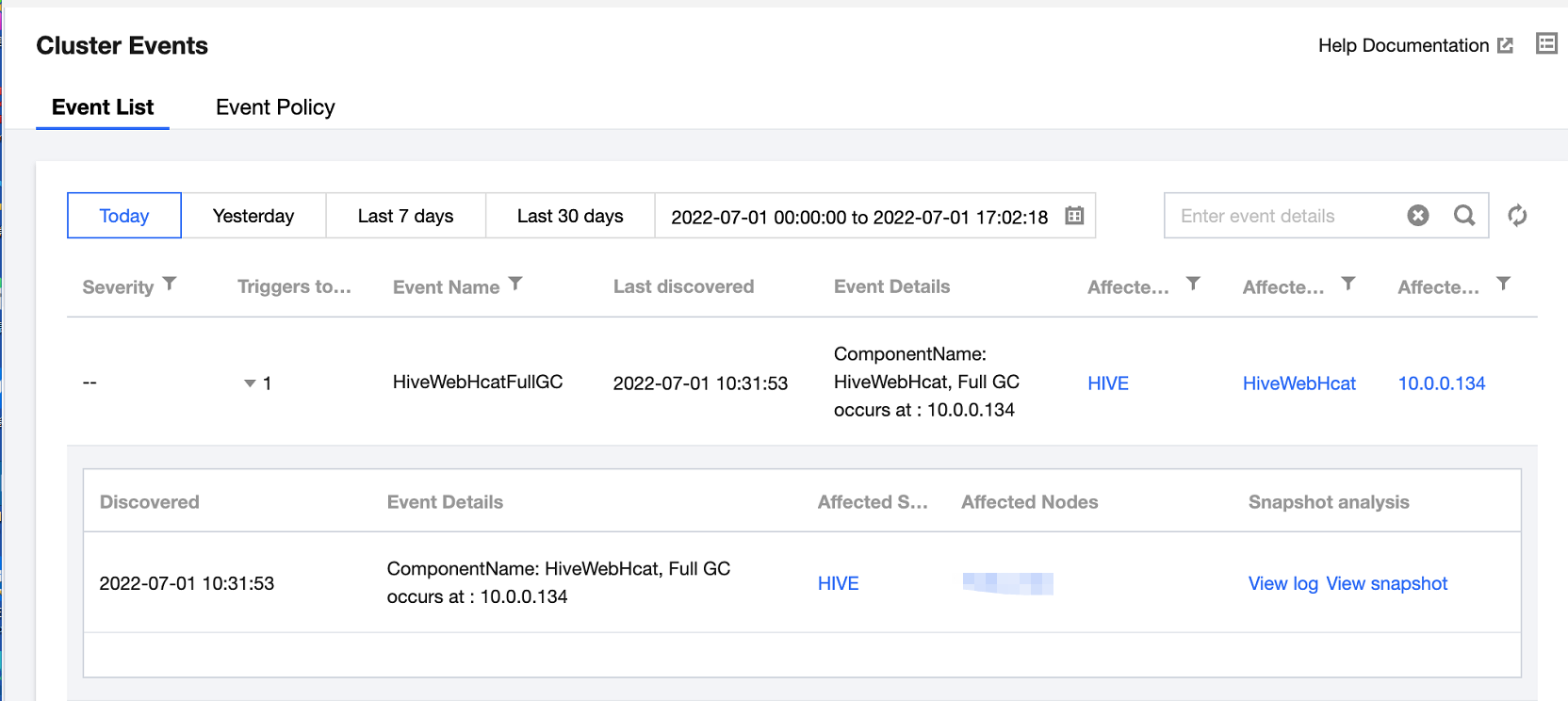
查看事件列表
1. 登录 弹性 MapReduce 控制台,在集群列表中单击对应的集群 ID/名称进入集群详情页。
2. 在集群详情页中选择集群监控 > 集群事件 > 事件列表,可直接查看当前集群所有操作事件。

致命:节点或服务的异常事件,人工干预处理,否则服务不可用,这类事件可能持续一段时间。
严重:暂时未造成服务或节点不可用问题,属于预警类,如果一直不处理会产生致命事件。
一般:记录集群发生的常规事件,一般无需特别处理。
3. 单击当日触发次数列值可查看事件的触发记录,同时可查看事件记录相关指标、日志或现场。
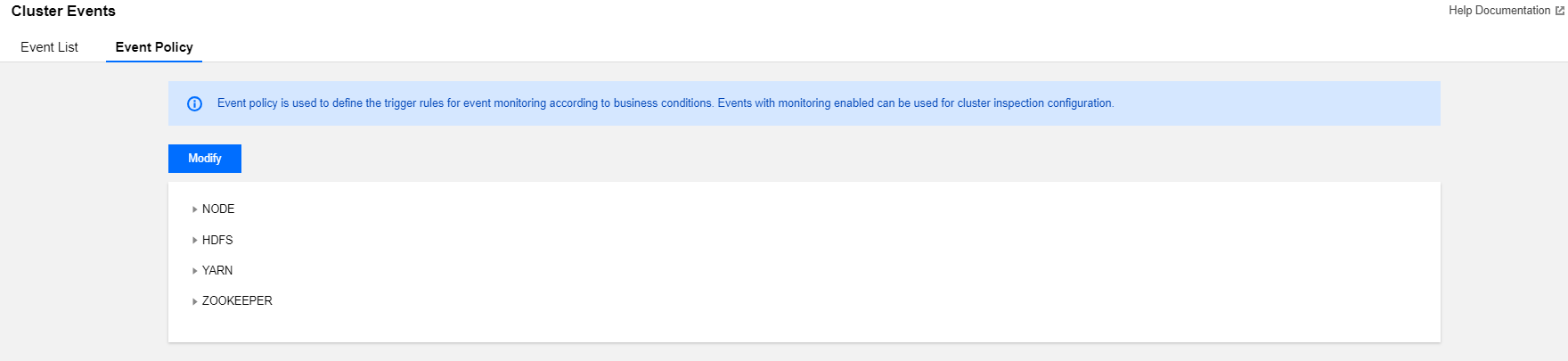
设置事件策略
1. 登录 EMR 控制台,在集群列表中单击对应的集群 ID/名称进入集群详情页。
2. 在集群详情页中选择集群监控 > 集群事件 > 事件策略,可以自定义设置事件监控触发策略。
3. 事件配置列表包含:事件名、事件发现策略、严重程度(致命/严重/一般)、开启监控,支持修改和保存。
4. 事件发现策略分两类:一类事件为系统固定策略事件,不支持用户修改;另一类事件会因客户业务标准的不同而变化,支持用户设置。
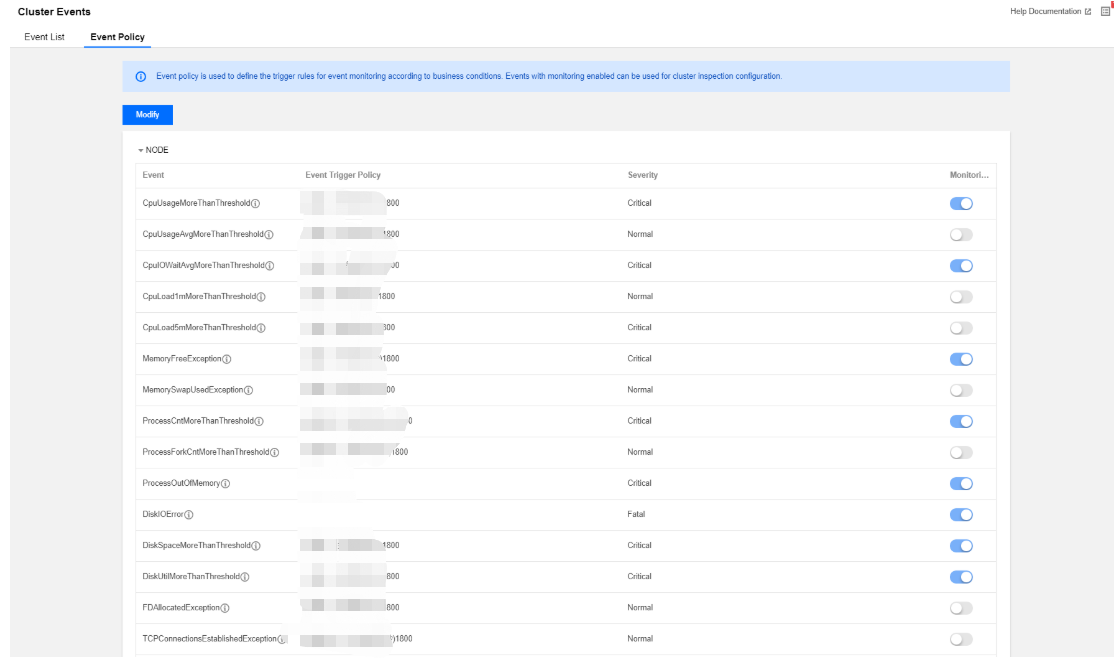
5. 事件策略可自定义是否开启事件监控,已开启监控的事件才支持在集群巡检的巡检项中选择。部分事件默认开启,部分事件默认开启且不可关闭。具体规则如下:
类别 | 事件名称 | 事件含义 | 建议&措施 | 默认值 | 严重程度 | 允许关闭 | 默认开启 |
节点 | CPU 利用率连续高于阈值 | 机器 CPU 利用率 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=85, t=1800 | 严重 | 是 | 是 |
| CPU 利用率平均值高于阈值 | 机器 CPU 利用率平均值 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=85, t=1800 | 一般 | 是 | 否 |
| CPU IOwait 平均值高于阈值 | t 秒内机器 CPU iowait 使用率平均值 >= m(300<=t<=2592000) | 人工排查 | m=60, t=1800 | 严重 | 是 | 是 |
| CPU 1秒负载连续高于阈值 | CPU 1分钟负载 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=8, t=1800 | 一般 | 是 | 否 |
| CPU 5秒负载连续高于阈值 | CPU 5分钟负载 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=8, t=1800 | 严重 | 是 | 否 |
| 内存使用率持续高于阈值 | 内存使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=85, t=1800 | 严重 | 是 | 是 |
| SWAP 空间持续高于阈值 | 机器 swap 内存 > m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=0.1, t=300 | 一般 | 是 | 否 |
| 系统进程总数连续高于阈值 | 系统进程总数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=10000, t=1800 | 严重 | 是 | 是 |
| fork 子进程总数平均值高于阈值 | t 秒内机器 fork 子进程总数平均值 >= m(300<=t<=2592000) | 人工排查 | m=5000, t=1800 | 一般 | 是 | 否 |
| 进程 OOM 暂无 | 进程发生 OOM 错误 | 调整进程堆内存大小 | - | 严重 | 否 | 是 |
| 磁盘 IO 错误 暂不支持 | 磁盘 IO 发生错误 | 更换磁盘 | - | 致命 | 是 | 是 |
| 磁盘空间平均使用率持续高于阈值 | 磁盘空间平均使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=85, t=1800 | 严重 | 是 | 是 |
| 磁盘 IO 设备平均利用率持续高于阈值 | 磁盘 IO 设备平均利用率 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=85, t=1800 | 严重 | 是 | 是 |
| 节点文件句柄使用率持续超过阈值 | 节点文件句柄使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=85, t=1800 | 一般 | 是 | 否 |
| 节点 TCP 连接数持续超过阈值 | 节点 TCP 连接数 >= m,持续时间 t 秒(300<=t<=2592000) | 检查是否存在连接泄露 | m=10000, t=1800 | 一般 | 是 | 否 |
| 节点内存使用配置超过阈值 | 节点上所有角色内存使用配置叠加超过节点物理内存阈值 | 调整节点进程堆内存分配 | 90% | 严重 | 是 | 否 |
| 节点进程不可用 | 节点服务进程不可用 | 查看服务日志以定位服务无法被拉起原因 | - | 一般 | 是 | 是 |
| 节点心跳丢失 | 节点心跳未定时上报 | 人工排查 | - | 致命 | 否 | 是 |
| Hostname 错误 | 节点 hostname 错误 | 人工排查 | - | 致命 | 否 | 是 |
| 元数据库 Ping 失败 | CDB 心跳未定时上报 | - | - | - | - | - |
| 单盘空间使用率持续高于阈值 | 单盘空间使用率>=m,持续时间 t秒(300<=t<=2592000) | 节点扩容或升配 | m=0.85, t=1800 | 严重 | 是 | 是 |
| 单盘 IO 设备利用率持续高于阈值 | 单盘 IO 设备利用率>=m,持续时间 t秒(300<=t<=2592000) | 节点扩容或升配 | m=0.85, t=1800 | 严重 | 是 | 是 |
| 单盘 INODES 使用率持续高于阈值 | 单盘 INODES 使用率>=m,持续时间 t秒(300<=t<=2592000) | 节点扩容或升配 | m=0.85, t=1800 | 严重 | 是 | 是 |
| 子机 UTC 时间和 NTP 时间差值高于阈值 | 子机 UTC 时间和 NTP 时间差值高于阈值(单位毫秒) | 1. 确保 NTP daemon 处于运行状态 2. 确保与 NTP server 的网络通信正常 | 差值=30000 | 严重 | 是 | 是 |
| 故障节点自动补偿 | 当开启自动补偿功能后,task 节点和 router 节点异常时,系统将自动购买同机型规格配置进行补偿替换 | - | 一般 | 是 | 是 | |
| 节点故障 | 集群中有故障节点 | - | 严重 | 否 | 是 | |
HDFS | HDFS 文件总数持续高于阈值 | 集群文件总数量 >= m,持续时间 t 秒(300<=t<=2592000) | 调大 namenode 内存 | m=50,000,000, t=1800 | 严重 | 是 | 否 |
| HDFS 文件总数平均值高于阈值 | t 秒内集群文件总数量平均值 >= m(300<=t<=2592000) | 调大 namenode 内存 | m=50,000,000, t=1800 | 严重 | 是 | 否 |
| HDFS 总 block 数量持续高于阈值 | 集群 Blocks 总数量 >= m,持续时间 t 秒(300<=t<=2592000) | 调大 namenode 内存或调大 block size | m=50,000,000, t=1800 | 严重 | 是 | 否 |
| HDFS 总 block 数量平均值高于阈值 | t 秒内集群 Blocks 总数量平均值 >= m(300<=t<=2592000) | 调大 namenode 内存或调大 block size | m=50,000,000, t=1800 | 严重 | 是 | 否 |
| HDFS 标记为 Dead 状态的数据节点数量持续高于阈值 | 标记为 Dead 状态的数据节点数量 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=1,t=1800 | 一般 | 是 | 否 |
| HDFS 存储空间使用率持续高于阈值 | HDFS 存储空间使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 清理 HDFS 中的文件或对集群扩容 | m=85, t=1800 | 严重 | 是 | 是 |
| HDFS 存储空间使用率平均值高于阈值 | HDFS 存储空间使用率平均值 >= m,持续时间 t 秒(300<=t<=2592000) | 清理 HDFS 中的文件或对集群扩容 | m=85, t=1800 | 严重 | 是 | 否 |
| NameNode 发生主备切换 | NameNode 发生主备切换 | 排查 NameNode 切换的原因 | - | 严重 | 是 | 是 |
| NameNode RPC 请求处理延迟持续高于阈值 | RPC 请求处理延迟 >= m毫秒,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=300, t=300 | 严重 | 是 | 否 |
| NameNode 当前连接数持续高于阈值 | NameNode 当前连接数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=2000, t=1800 | 一般 | 是 | 否 |
| NameNode 发生 full GC | NameNode 发生 full GC | 参数调优 | - | 严重 | 是 | 是 |
| NameNode JVM 内存使用率持续高于阈值 | NameNode JVM 内存使用率持续 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 NameNode 堆内存大小 | m=85, t=1800 | 严重 | 是 | 是 |
| DataNode RPC 请求处理延迟持续高于阈值 | RPC 请求处理延迟 >= m毫秒,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=300, t=300 | 一般 | 是 | 否 |
| DataNode 当前连接数持续高于阈值 | DataNode 当前连接数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=2000, t=1800 | 一般 | 是 | 否 |
| DataNode 发生 full GC | NameNode 发生 full GC | 参数调优 | - | 一般 | 是 | 否 |
| DataNode JVM 内存使用率持续高于阈值 | NameNode JVM 内存使用率持续 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 DataNode 堆内存大小 | m=85, t=1800 | 一般 | 是 | 是 |
| HDFS 两个NameNode 服务状态均为 Standby | 两个 NameNode 角色同时处于 StandBy 状态 | 人工排查 | - | 严重 | 是 | 是 |
| HDFS MissingBlocks 数量高于阈值 | 集群 MissingBlocks 数量>=m,持续时间t秒(300<=t<=604800) | 建议排查 HDFS 出现数据块损坏,使用命令 hadoop fsck / 检查 HDFS 文件分布的情况 | m=1,t=1800 | 严重 | 是 | 是 |
| HDFS NameNode 进入安全模式 | NameNode 进入安全模式(持续300s) | 建议排查 HDFS 出现数据块损坏,使用命令 hadoop fsck / 检查 HDFS 文件分布的情况 | - | 严重 | 是 | 是 |
YARN | 集群当前丢失的 NodeManager 的个数持续高于阈值 | 集群当前丢失的 NodeManager 的个数 >= m,持续时间 t 秒(300<=t<=2592000) | 检查 NM 进程状态,检查网络是否畅通 | m=1, t=1800 | 一般 | 是 | 否 |
| Pending Containers 个数持续高于阈值 | pengding Containers 个数 >= m个,持续时间 t 秒(300<=t<=2592000) | 合理指定 YARN 任务可用资源 | m=90, t=1800 | 一般 | 是 | 否 |
| 集群内存使用率持续高于阈值 | 内存使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 集群扩容 | m=85, t=1800 | 严重 | 是 | 是 |
| 集群内存使用率平均值高于阈值 | t 秒内内存使用率平均值 >= m(300<=t<=2592000) | 集群扩容 | m=85, t=1800 | 严重 | 是 | 否 |
| 集群 CPU 使用率持续高于阈值 | CPU 使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 集群扩容 | m=85, t=1800 | 严重 | 是 | 是 |
| 集群 CPU 使用率平均值高于阈值 | t 秒内 CPU 使用率平均值 >= m(300<=t<=2592000) | 集群扩容 | m=85, t=1800 | 严重 | 是 | 否 |
| 各队列中可用的 CPU 核数持续低于阈值 | 任意队列中可用 CPU 核数 <= m,持续时间 t 秒(300<=t<=2592000) | 给队列分配更多资源 | m=1, t=1800 | 一般 | 是 | 否 |
| 各队列中可用的内存持续低于阈值 | 任意队列中可用内存 <= m,持续时间 t 秒(300<=t<=2592000) | 给队列分配更多资源 | m=1024, t=1800 | 一般 | 是 | 否 |
| ResourceManager 发生主备切换 | ResourceManager 发生了主备切换 | 检查 RM 进程状态,查看 standby RM 日志查看主备切换原因 | - | 严重 | 是 | 是 |
| ResourceManager 发生 full GC | ResourceManager 发生了 full GC | 参数调优 | - | 严重 | 是 | 是 |
| ResourceManager JVM 内存使用率持续高于阈值 | RM JVM 内存使用率持续 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 ResourceManager 堆内存大小 | m=85, t=1800 | 严重 | 是 | 是 |
| NodeManager 发生 full GC | NodeManager 发生 full GC | 参数调优 | - | 一般 | 是 | 否 |
| NodeManager 可用的内存持续低于阈值 | 单个 NM 可用内存持续 <= m,持续时间 t 秒(300<=t<=2592000) | 调整 NodeManager 堆内存大小 | m=1, t=1800 | 一般 | 是 | 否 |
| NodeManager JVM 内存使用率持续高于阈值 | NM JVM 内存使用率持续 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 NodeManager 堆内存大小 | m=85, t=1800 | 一般 | 是 | 否 |
HBase | 集群处于 RIT Region 个数持续高于阈值 | 集群处于 RIT Region 个数 >= m,持续时间 t 秒(300<=t<=2592000) | HBase2.0 版本以下,hbase hbck -fixAssigment | m=1, t=60 | 严重 | 是 | 是 |
| 集群 dead RS 数量持续高于阈值 | 集群 dead RegionServer 数量 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=1, t=300 | 一般 | 是 | 是 |
| 集群每个 RS 平均 REGION 数持续高于阈值 | 集群每个 RegionServer 平均 REGION 数 >= m,持续时间 t 秒(300<=t<=2592000) | 节点扩容或升配 | m=300, t=1800 | 一般 | 是 | 是 |
| HMaster 发生 full GC | HMaster 发生了 full GC | 参数调优 | m=5, t=300 | 一般 | 是 | 是 |
| HMaster JVM 内存使用率持续高于阈值 | HMaster JVM 内存使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 HMaster 堆内存大小 | m=85, t=1800 | 严重 | 是 | 是 |
| HMaster 当前连接数持续高于阈值 | HMaster 当前连接数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=1000, t=1800 | 一般 | 是 | 否 |
| RegionServer 发生 full GC | RegionServer 发生 full GC | 参数调优 | m=5, t=300 | 严重 | 是 | 否 |
| RegionServer JVM 内存使用率持续高于阈值 | RegionServer JVM 内存使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 RegionServer 堆内存大小 | m=85, t=1800 | 一般 | 是 | 否 |
| RegionServer 当前 RPC 连接数持续高于阈值 | RegionServer 当前 RPC 连接数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=1000, t=1800 | 一般 | 是 | 否 |
| RegionServer Storefile 个数持续高于阈值 | RegionServer Storefile 个数 >= m,持续时间 t 秒(300<=t<=2592000) | 建议执行 major compaction | m=50000, t=1800 | 一般 | 是 | 否 |
| HBaseThrift 发生 full GC | HBaseThrift 发生 full GC | 参数调优 | m=5, t=300 | 严重 | 是 | 否 |
| HBaseThrift JVM 内存使用率持续高于阈值 | HBaseThrift JVM 内存使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 HBaseThrift 堆内存大小 | m=85, t=1800 | 一般 | 是 | 否 |
| HBASE 两个 HMaster 服务状态均为 Standby | 两个 HMaster 角色同时处于 StandBy 状态 | 人工排查 | - | 严重 | 是 | 是 |
Hive | HiveServer2 发生 full GC | HiveServer2 发生 full GC | 参数调优 | m=5, t=300 | 严重 | 是 | 是 |
| HiveServer2 JVM 内存使用率持续高于阈值 | HiveServer2 JVM 内存使用率 >= m,持续时间 t 秒(300<=t<=2592000) | 调整 HiveServer2 堆内存大小 | m=85, t=1800 | 严重 | 是 | 是 |
| HiveMetaStore 发生 full GC | HiveMetaStore 发生 full GC | 参数调优 | m=5, t=300 | 一般 | 是 | 是 |
| HiveWebHcat 发生 full GC | HiveWebHcat 发生 full GC | 参数调优 | m=5, t=300 | 一般 | 是 | 是 |
Zookeeper | Zookeeper 连接数持续高于阈值 | Zookeeper 连接数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=65535, t=1800 | 一般 | 是 | 否 |
| ZNode 节点数量持续高于阈值 | ZNode 节点数 >= m,持续时间 t 秒(300<=t<=2592000) | 人工排查 | m=2000, t=1800 | 一般 | 是 | 否 |
Impala | ImpalaCatalog JVM 内存使用率持续高于阈值 | ImpalaCatalog JVM 内存使用率>=m,持续时间 t秒(300<=t<=604800) | 调整 ImpalaCatalog 堆内存大小 | m=0.85, t=1800 | 一般 | 是 | 否 |
| ImpalaDaemon JVM 内存使用率持续高于阈值 | ImpalaDaemon JVM 内存使用率>=m,持续时间 t秒(300<=t<=604800) | 调整 ImpalaDaemon 堆内存大小 | m=0.85, t=1800 | 一般 | 是 | 否 |
| Impala Beeswax API 客户端连接数高于阈值 | Impala Beeswax API 客户端连接数 >=m | 控制台调整 impalad.flgs 配置 fs_sevice_threads 数量 | m=64,t=120 | 严重 | 是 | 是 |
| Impala HS2客户端连接数高于阈值 | Impala HS2客户端连接数 >=m | 控制台调整 impalad.flgs 配置 fs_sevice_threads 数量 | m=64,t=120 | 严重 | 是 | 是 |
| Query 运行时长超过阈值 | Query 运行时长超过阈值>=m(seconds) | 人工排查 | - | 严重 | 是 | 否 |
| 执行 Query 失败总数高于阈值 | 执行 Query 失败率高于阈值>=m,统计时间粒度t秒(300<=t<=604800) | 人工排查 | m=1,t=300 | 严重 | 是 | 否 |
| 提交 Query 总数高于阈值 | 执行 Query 失败总数高于阈值>=m,统计时间粒度t秒(300<=t<=604800) | 人工排查 | m=1,t=300 | 严重 | 是 | 否 |
| 执行 Query 失败率高于阈值 | 提交 Query 总数高于阈值 >=m,统计时间粒度t秒(300<=t<=604800) | 人工排查 | m=1,t=300 | 严重 | 是 | 否 |
PrestoSQL | PrestoSQL 当前失败节点数量持续高于阈值 | PrestoSQL 当前失败节点数量>=m,持续时间t秒(300<=t<=604800) | 人工排查 | m=1, t=1800 | 严重 | 是 | 是 |
| PrestoSQL 当前资源组排队资源持续高于阈值 | PrestoSQL 资源组排队任务>=m,持续时间 t秒(300<=t<=604800) | 参数调优 | m=5000, t=1800 | 严重 | 是 | 是 |
| PrestoSQL 每分钟失败查询数量超过阈值 | PrestoSQL 失败查询数量 >=m | 人工排查 | m=1, t=1800 | 严重 | 是 | 否 |
| PrestoSQLCoordinator 发生full GC | PrestoSQLCoordinator 发生full GC | 参数调优 | - | 一般 | 是 | 否 |
| PrestoSQLCoordinator JVM 内存使用率持续高于阈值 | PrestoSQLCoordinator JVM 内存使用率>=m,持续时间 t秒(300<=t<=604800) | 调整 PrestoSQLCoordinator 堆内存大小 | m=0.85, t=1800 | 严重 | 是 | 是 |
| PrestoSQLWorker 发生 full GC | PrestoSQLWorker 发生 full GC | 参数调优 | - | 一般 | 是 | 否 |
| PrestoSQLWorker JVM 内存使用率持续高于阈值 | PrestoSQLWorker JVM 内存使用率>=m,持续时间 t秒(300<=t<=604800) | 调整 PrestoSQLWorker 堆内存大小 | m=0.85, t=1800 | 严重 | 是 | 否 |
Presto | Presto 当前失败节点数量持续高于阈值 | Presto 当前失败节点数量>=m,持续时间t秒(300<=t<=604800) | 人工排查 | m=1, t=1800 | 严重 | 是 | 是 |
| Presto 当前资源组排队资源持续高于阈值 | Presto 资源组排队任务>=m,持续时间 t秒(300<=t<=604800) | 参数调优 | m=5000, t=1800 | 严重 | 是 | 是 |
| Presto 每分钟失败查询数量超过阈值 | Presto 失败查询数量 >=m | 人工排查 | m=1, t=1800 | 严重 | 是 | 否 |
| PrestoCoordinator 发生full GC | PrestoCoordinator 发生full GC | 参数调优 | - | 一般 | 是 | 否 |
| PrestoCoordinator JVM 内存使用率持续高于阈值 | PrestoCoordinator JVM 内存使用率>=m,持续时间 t秒(300<=t<=604800) | 调整 PrestoCoordinator 堆内存大小 | m=0.85, t=1800 | 一般 | 是 | 是 |
| PrestoWorker 发生 full GC | PrestoWorker 发生 full GC | 参数调优 | - | 一般 | 是 | 否 |
| PrestoWorker JVM 内存使用率持续高于阈值 | PrestoWorker JVM 内存使用率>=m,持续时间 t秒(300<=t<=604800) | 调整 PrestoWorker 堆内存大小 | m=0.85, t=1800 | 严重 | 是 | 否 |
Alluxio | Alluxio 当前 Worker 总数持续低于阈值 | Alluxio 当前 Worker 总数持续低于阈值<=m,持续时间 t秒(300<=t<=604800) | 人工排查 | m=1, t=1800 | 严重 | 是 | 否 |
| Alluxio 当前 Worker 的层上容量使用率高于阈值 | Alluxio 当前 Worker 的层上容量使用率>=m, 持续时间 t秒(300<=t<=604800) | 参数调优 | m=0.85, t=1800 | 严重 | 是 | 否 |
| AlluxioMaster 发生full GC | AlluxioMaster 发生full GC | 人工排查 | - | 一般 | 是 | 否 |
| AlluxioMaster JVM 内存使用率持续高于阈值 | AlluxioMaster JVM 内存使用率 >=m, 持续时间 t秒(300<=t<=604800) | 调整 AlluxioWorker 堆内存大小 | m=0.85, t=1800 | 严重 | 是 | 是 |
| AlluxioWorker 发生 full GC | AlluxioWorker 发生 full GC | 人工排查 | - | 一般 | 是 | 否 |
| AlluxioWorker JVM 内存使用率持续高于阈值 | AlluxioWorker JVM 内存使用率 >=m, 持续时间 t秒(300<=t<=604800) | 调整 AlluxioMaster 堆内存大小 | m=0.85, t=1800 | 严重 | 是 | 是 |
kudu | 集群副本倾斜度高于阈值 | 集群副本倾斜度 >=m,持续时间 t秒(300<=t<=3600) | 使用 rebalance 命令对 replica 进行平衡 | m=100, t=300 | 一般 | 是 | 是 |
| 混合时钟错误高于阈值 | 混合时钟错误 >=m,持续时间 t秒(300<=t<=3600) | 确保 NTP daemon 处于运行状态,确保与 NTP server 的网络通信正常 | m=5000000, t=300 | 一般 | 是 | 是 |
| 处于运行中状态的 tablet 高于阈值 | 处于运行中状态的 tablet 数量 >=m,持续时间 t秒(300<=t<=3600) | 单个节点 tablet 数量太多会影响性能,建议清理不需要的表和分区,或适当扩容 | m=1000, t=300 | 一般 | 是 | 是 |
| 处于失败状态的 tablet 高于阈值 | 处于失败状态的 tablet 数量 >=m,持续时间 t秒(300<=t<=3600) | 检查是否有磁盘不可用或者数据文件损坏 | m=1, t=300 | 一般 | 是 | 是 |
| 处于失败状态的数据目录数量高于阈值 | 处于失败状态的数据目录数量 >=m,持续时间 t秒(300<=t<=3600) | 检查 fs_data_dirs 参数中配置的路径是否可用 | m=1, t=300 | 严重 | 是 | 是 |
| 容量耗尽的数据目录数量高于阈值 | 容量耗尽的数据目录数量 >=m,持续时间 t秒(120<=t<=3600) | 清理不需要的数据文件,或适当扩容 | m=1, t=120 | 严重 | 是 | 是 |
| 因队列过载被拒绝的写请求数高于阈值 | 因队列过载被拒绝的写请求数>=m,持续时间t秒(300<=t<=3600) | 检查是否存在写热点或者工作线程数量偏少 | m=10, t=300 | 一般 | 是 | 否 |
| 过期 scanner 的数量高于阈值 | 过期 scanner 的数量 >=m,持续时间 t秒(300<=t<=3600) | 数据读取完成后,记得调用 scanner 的 close 方法 | m=100, t=300 | 一般 | 是 | 是 |
| 错误日志的数量高于阈值 | 错误日志的数量 >=m,持续时间 t秒(300<=t<=3600) | 人工排查 | m=10, t=300 | 一般 | 是 | 是 |
| 在队列中等待超时的 rpc 请求数量高于阈值 | 在队列中等待超时的 rpc 请求数量 >=m,持续时间 t秒(300<=t<=3600) | 检查系统负载是否过高 | m=100, t=300 | 一般 | 是 | 是 |
Kerberos | Kerberos 响应时间高于阈值 | Kerberos 响应时间>=m(单位毫秒),持续时间t秒(300<=t<=604800) | 人工排查 | m=100,t=1800 | 严重 | 是 | 是 |
集群 | 自动伸缩策略执行失败 | 1. 集群绑定的子网弹性 IP 不足,扩容规则执行失败。2. 预设扩容资源规格库存不足,扩容规则执行失败。3. 账号余额不足,扩容规则执行失败。4. 内部错误。 | - | 严重 | 否 | 是 | |
| 自动伸缩策略执行超时 | 1. 集群处于冷却窗口期,暂时无法扩缩容。2. 当前设置过期重试时间过短,规则在过期重试时间内未触发扩缩容。3. 集群状态未处于不可扩容状态。 | - | 严重 | 否 | 是 | |
| 自动伸缩策略未触发 | 1. 未设置扩容资源规格,扩容规则无法触发。2. 弹性资源已达到最大节点数限制,无法触发扩容。3. 弹性资源已达到最小节点数限制,无法触发缩容。 4. 时间伸缩执行时间范围已到期。5. 集群无弹性资源,缩容规则无法触发。 | 1. 添加伸缩规格配置,请至少设置一个弹性资源规格。2. 弹性资源超过最大节点数,如需继续扩容,可尝试调整最大节点数。3. 弹性资源达到最小节点数,如需继续缩容,可尝试调整最小节点数。4. 如需继续使用该规则进行自动伸缩,请修改规则的生效时间范围。5. 补充弹性资源后执行缩容规则。 | - | 一般 | 是 | 是 |
| 自动伸缩扩容部分成功 | 1. 资源库存量小于扩容数量,仅补充部分资源。2. 扩容数量大于实际发货数量,仅补充部分资源。3. 扩容弹性资源已达到最大节点数限制,扩容规则执行部分成功。4. 缩容弹性资源已达到最小节点数限制,缩容规则执行部分成功。5. 集群绑定的子网弹性 IP 不足,资源补足失败6. 预设扩容资源规格库存不足,资源补足失败7. 账号余额不足,资源补足失败。 | 1. 手动扩容库存充足资源,用于补充缺少需求资源2. 手动扩容库存充足资源,用于补充缺少需求资源3. 弹性资源超过最大节点数,如需继续扩容,可尝试调整最大节点数。4. 弹性资源达到最小节点数,如需继续缩容,可尝试调整最小节点数。5. 更换同vpc下的其他子网。6. 可尝试更换充足的资源规格或 提交工单 联系内部研发人员。7. 进行账户余额充值,保证账号余额充足。 | - | 一般 | 是 | 是 |
| 节点进程不可用 | 节点进程不可用 | 人工排查 | - | 一般 | 否 | 是 |
| 进程被 OOMKiller kill | 进程 OOM 被 OOMKiller kill 掉 | 调整进程堆内存大小 | - | 严重 | 否 | 是 |
| JVM OLD 区异常 | JVM OLD 区异常 | 人工排查 | 1. old 区连续5分钟 80%或者2. JVM 内存使用率达到90% | 严重 | 是 | 是 |
| 服务角色健康状态超时 | 服务角色健康状态超时,持续时间t秒(180=t<=604800) | 服务角色健康状态连续分钟级超时。处理方式:查看对应服务角色日志信息,根据日志处理。 | t=300 | 一般 | 是 | 否 |
| 服务角色健康状态异常 | 服务角色健康状态异常,持续时间t秒(180=t<=604800) | 服务角色健康状态连续分钟级不可用。处理方式:查看对应服务角色日志信息,根据日志处理。 | t=300 | 严重 | 是 | 是 |
| 自动伸缩失败 | 自动伸缩失败告警(包含全部/部分伸缩失败情况) | 人工排查 | / | 严重 | 否 | 是 |
| |||||||

 是
是
 否
否
本页内容是否解决了您的问题?