- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 准备工作
- 数据迁移
- 数据同步
- 数据订阅(Kafka 版)
- 前置校验不通过处理方法
- 割接说明
- 监控与告警
- 运维管理
- 实践教程
- 常见问题
- 错误处理
- API 文档
- History
- Introduction
- Introduction
- API Category
- Making API Requests
- (NewDTS) Data Migration APIs
- DescribeMigrationJobs
- CreateMigrationService
- ModifyMigrationJob
- CreateMigrateCheckJob
- DescribeMigrationCheckJob
- SkipCheckItem
- StartMigrateJob
- CompleteMigrateJob
- ContinueMigrateJob
- DescribeMigrateDBInstances
- DescribeMigrationDetail
- DestroyMigrateJob
- IsolateMigrateJob
- ModifyMigrateJobSpec
- ModifyMigrateName
- ModifyMigrateRuntimeAttribute
- PauseMigrateJob
- RecoverMigrateJob
- ResumeMigrateJob
- StopMigrateJob
- ModifyMigrateRateLimit
- Data Sync APIs
- DescribeSyncJobs
- CreateSyncJob
- ConfigureSyncJob
- CreateCheckSyncJob
- DescribeCheckSyncJobResult
- SkipSyncCheckItem
- StartSyncJob
- IsolateSyncJob
- RecoverSyncJob
- PauseSyncJob
- ContinueSyncJob
- ResumeSyncJob
- StopSyncJob
- DestroySyncJob
- ResizeSyncJob
- ModifySyncJobConfig
- CreateModifyCheckSyncJob
- DescribeModifyCheckSyncJobResult
- StartModifySyncJob
- ModifySyncRateLimit
- Data Consistency Check APIs
- (NewDTS) Data Subscription APIs
- CreateSubscribe
- ConfigureSubscribeJob
- CreateSubscribeCheckJob
- DescribeSubscribeCheckJob
- StartSubscribe
- ModifySubscribeObjects
- DescribeSubscribeDetail
- DescribeSubscribeJobs
- ResumeSubscribe
- CreateConsumerGroup
- DescribeConsumerGroups
- ModifyConsumerGroupDescription
- ModifyConsumerGroupPassword
- DescribeOffsetByTime
- ResetConsumerGroupOffset
- DeleteConsumerGroup
- ResetSubscribe
- ModifySubscribeAutoRenewFlag
- ModifySubscribeName
- DescribeSubscribeReturnable
- IsolateSubscribe
- DestroyIsolatedSubscribe
- Data Types
- Error Codes
- DTS API 2018-03-30
- 相关协议
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 准备工作
- 数据迁移
- 数据同步
- 数据订阅(Kafka 版)
- 前置校验不通过处理方法
- 割接说明
- 监控与告警
- 运维管理
- 实践教程
- 常见问题
- 错误处理
- API 文档
- History
- Introduction
- Introduction
- API Category
- Making API Requests
- (NewDTS) Data Migration APIs
- DescribeMigrationJobs
- CreateMigrationService
- ModifyMigrationJob
- CreateMigrateCheckJob
- DescribeMigrationCheckJob
- SkipCheckItem
- StartMigrateJob
- CompleteMigrateJob
- ContinueMigrateJob
- DescribeMigrateDBInstances
- DescribeMigrationDetail
- DestroyMigrateJob
- IsolateMigrateJob
- ModifyMigrateJobSpec
- ModifyMigrateName
- ModifyMigrateRuntimeAttribute
- PauseMigrateJob
- RecoverMigrateJob
- ResumeMigrateJob
- StopMigrateJob
- ModifyMigrateRateLimit
- Data Sync APIs
- DescribeSyncJobs
- CreateSyncJob
- ConfigureSyncJob
- CreateCheckSyncJob
- DescribeCheckSyncJobResult
- SkipSyncCheckItem
- StartSyncJob
- IsolateSyncJob
- RecoverSyncJob
- PauseSyncJob
- ContinueSyncJob
- ResumeSyncJob
- StopSyncJob
- DestroySyncJob
- ResizeSyncJob
- ModifySyncJobConfig
- CreateModifyCheckSyncJob
- DescribeModifyCheckSyncJobResult
- StartModifySyncJob
- ModifySyncRateLimit
- Data Consistency Check APIs
- (NewDTS) Data Subscription APIs
- CreateSubscribe
- ConfigureSubscribeJob
- CreateSubscribeCheckJob
- DescribeSubscribeCheckJob
- StartSubscribe
- ModifySubscribeObjects
- DescribeSubscribeDetail
- DescribeSubscribeJobs
- ResumeSubscribe
- CreateConsumerGroup
- DescribeConsumerGroups
- ModifyConsumerGroupDescription
- ModifyConsumerGroupPassword
- DescribeOffsetByTime
- ResetConsumerGroupOffset
- DeleteConsumerGroup
- ResetSubscribe
- ModifySubscribeAutoRenewFlag
- ModifySubscribeName
- DescribeSubscribeReturnable
- IsolateSubscribe
- DestroyIsolatedSubscribe
- Data Types
- Error Codes
- DTS API 2018-03-30
- 相关协议
本场景介绍使用 DTS 创建腾讯云数据库 MongoDB 的数据订阅任务操作指导。
版本说明
目前仅支持对腾讯云 MongoDB 的数据订阅,具体版本为3.6、4.0、4.2、4.4。
MongoDB 3.6版本仅支持集合级别的订阅。
前提条件
已准备好待订阅的腾讯云数据库,并且数据库版本符合要求,请参见 数据订阅支持的数据库。
建议在源端实例中创建只读账号,可参考如下语法进行操作。源库为腾讯云 MongoDB 的,也可在 MongoDB 控制台创建只读账号。
# 创建全实例只读账号use admindb.createUser({user: "username",pwd: "password",roles:[{role: "readAnyDatabase",db: "admin"}]})# 创建指定库只读账号use admindb.createUser({user: "username",pwd: "password",roles:[{role: "read",db: "指定库的库名"}]})
注意事项
订阅的消息保存在 DTS 内置 Kafka(单 Topic)中,目前默认保存时间为最近1天,单 Topic 的最大存储为500G,当数据存储时间超过1天,或者数据量超过500G时,内置 Kafka 都会开始清除最先写入的数据。所以请用户及时消费,避免数据在消费完之前就被清除。
数据消费的地域需要与订阅任务所属的地域相同。
DTS 中内置的 Kafka 处理单条消息有一定上限,当源库中的单行数据超过10MB时,这条数据在消费端可能会被丢弃。
在源数据库中删除已选订阅对象的指定库或者集合后,该库或者集合的订阅数据(Change Stream)将会被无效化,即使在源数据库中重建该库或者集合也无法续订数据,需要重置订阅任务,重新勾选订阅对象。
支持订阅的 SQL 操作
操作类型 | 支持的 SQL 操作 |
DML | INSERT、UPDATE、DELETE |
DDL | INDEX:createIndexes、createIndex、dropIndex、dropIndexes
COLLECTION:createCollection、drop、collMod、renameCollection
DATABASE:dropDatabase、copyDatabase |
订阅配置步骤
1. 登录 DTS 控制台,在左侧导航选择数据订阅,单击新建数据订阅。
2. 在新建数据订阅页,选择相应配置,单击立即购买。
计费模式:支持包年包月和按量计费。
地域:地域需与待订阅的数据库实例地域保持一致。
数据库:选择 MongoDB。
版本:选择 kafka 版,支持通过 Kafka 客户端直接消费。
订阅实例名称:编辑当前数据订阅实例的名称。
购买数量:单次购买最多支持10个任务。
3. 购买成功后,返回数据订阅列表,选择刚才购买的任务,在操作列单击配置订阅。
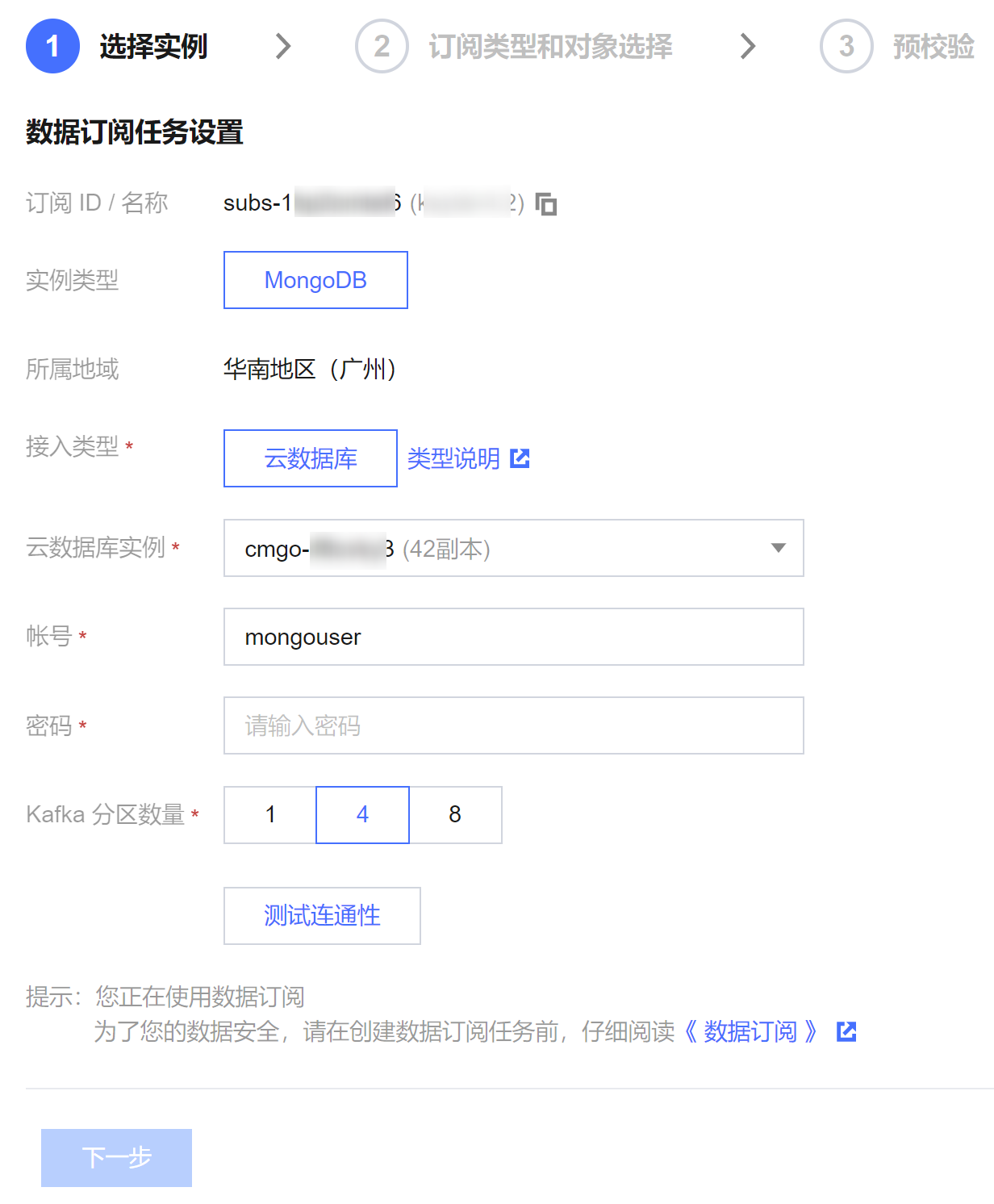
4. 在配置数据库订阅页面,配置源库信息后,单击测试连通性,通过后单击下一步。
接入类型:目前仅支持云数据库。
云数据库实例:选择云数据库实例 ID。
数据库账号/密码:添加订阅实例的账号和密码,账号具有只读权限。
kafka 分区数量:设置 kafka 分区数量,增加分区数量可提高数据写入和消费的速度。单分区可以保障消息的顺序,多分区无法保障消息顺序,如果您对消费到消息的顺序有严格要求,请选择 kafka 分区数量为1。
5. 在订阅类型和对象选择页面,选择订阅参数后,单击保存配置。
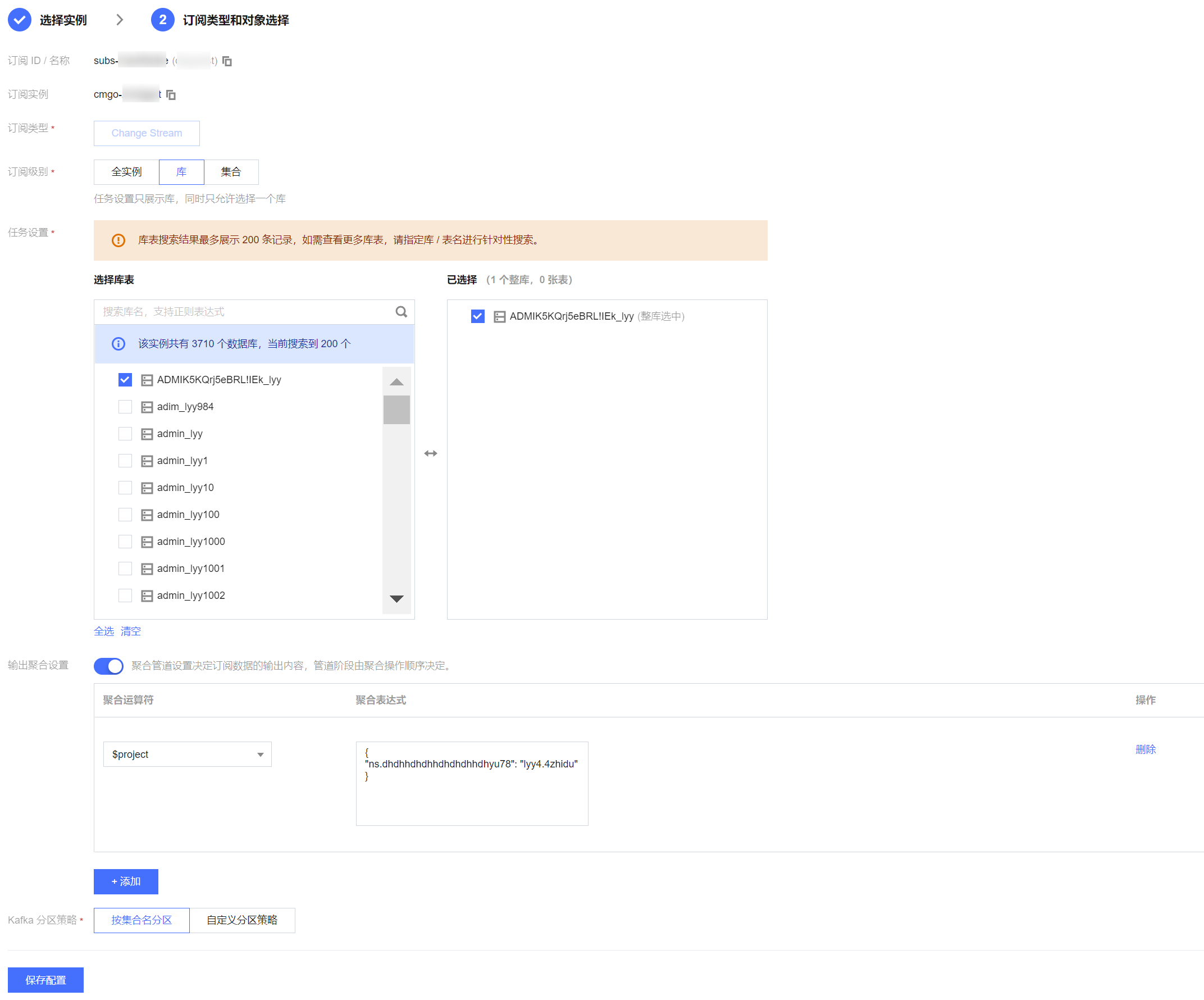
参数 | 说明 |
订阅类型 | 默认Change Stream,不可修改。 |
订阅级别 | 订阅级别,包括全实例、库和集合。 全实例:订阅全实例数据。 库:订阅库级别的数据,选择后,下面的任务设置中,只能选择一个库。 集合:订阅集合级别的数据,选择后,下面的任务设置中,只能选择一个集合。 |
任务设置 | 勾选需要订阅的库、集合。仅支持选择一个库或者一个集合。 |
输出聚合设置 | |
Kafka 分区策略 | 按集合名分区:将源库的订阅数据按照集合名进行分区,设置后相同集合名的数据会写入同一个 Kafka 分区中。 自定义分区策略:先通过正则表达式对订阅数据中的库名和集合名进行匹配,匹配到的数据再按照集合名分区、集合名 + objectid 分区。 |
6. 在预校验页面,预校验任务预计会运行2分钟 - 3分钟,预校验通过后,单击启动完成数据订阅任务配置。
说明:
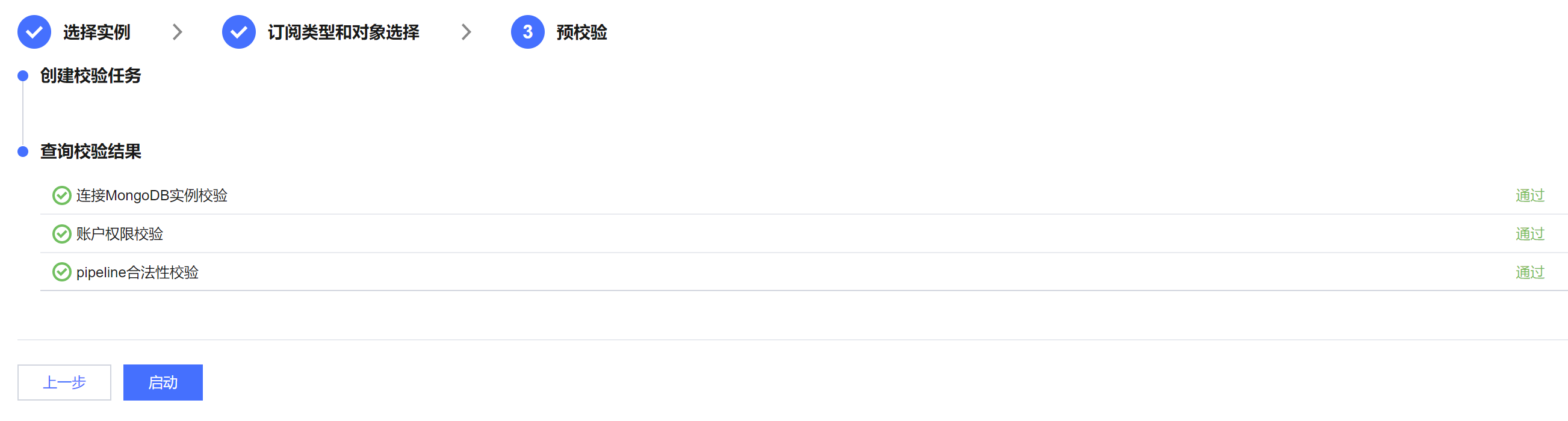
7. 订阅任务进行初始化,预计会运行3分钟 - 4分钟,初始化成功后进入运行中状态。
后续操作
1. 新增消费组。
数据订阅 Kafka 版的消费依赖于 Kafka 的消费组,所以在消费数据前需要创建消费组。数据订阅 Kafka 版支持用户创建多个消费组,进行多点消费。
2. 消费订阅数据。
订阅任务进入运行中状态之后,就可以开始消费数据。Kafka 的消费需要进行密码认证,具体内容请参考消费订阅数据中的 Demo,我们提供了多种语言的 Demo 代码,也对消费的主要流程和关键的数据结构进行了说明。

 是
是
 否
否
本页内容是否解决了您的问题?