- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 准备工作
- 数据迁移
- 数据同步
- 数据订阅(Kafka 版)
- 前置校验不通过处理方法
- 割接说明
- 监控与告警
- 运维管理
- 实践教程
- 常见问题
- 错误处理
- API 文档
- History
- Introduction
- Introduction
- API Category
- Making API Requests
- (NewDTS) Data Migration APIs
- DescribeMigrationJobs
- CreateMigrationService
- ModifyMigrationJob
- CreateMigrateCheckJob
- DescribeMigrationCheckJob
- SkipCheckItem
- StartMigrateJob
- CompleteMigrateJob
- ContinueMigrateJob
- DescribeMigrateDBInstances
- DescribeMigrationDetail
- DestroyMigrateJob
- IsolateMigrateJob
- ModifyMigrateJobSpec
- ModifyMigrateName
- ModifyMigrateRuntimeAttribute
- PauseMigrateJob
- RecoverMigrateJob
- ResumeMigrateJob
- StopMigrateJob
- ModifyMigrateRateLimit
- Data Sync APIs
- DescribeSyncJobs
- CreateSyncJob
- ConfigureSyncJob
- CreateCheckSyncJob
- DescribeCheckSyncJobResult
- SkipSyncCheckItem
- StartSyncJob
- IsolateSyncJob
- RecoverSyncJob
- PauseSyncJob
- ContinueSyncJob
- ResumeSyncJob
- StopSyncJob
- DestroySyncJob
- ResizeSyncJob
- ModifySyncJobConfig
- CreateModifyCheckSyncJob
- DescribeModifyCheckSyncJobResult
- StartModifySyncJob
- ModifySyncRateLimit
- Data Consistency Check APIs
- (NewDTS) Data Subscription APIs
- CreateSubscribe
- ConfigureSubscribeJob
- CreateSubscribeCheckJob
- DescribeSubscribeCheckJob
- StartSubscribe
- ModifySubscribeObjects
- DescribeSubscribeDetail
- DescribeSubscribeJobs
- ResumeSubscribe
- CreateConsumerGroup
- DescribeConsumerGroups
- ModifyConsumerGroupDescription
- ModifyConsumerGroupPassword
- DescribeOffsetByTime
- ResetConsumerGroupOffset
- DeleteConsumerGroup
- ResetSubscribe
- ModifySubscribeAutoRenewFlag
- ModifySubscribeName
- DescribeSubscribeReturnable
- IsolateSubscribe
- DestroyIsolatedSubscribe
- Data Types
- Error Codes
- DTS API 2018-03-30
- 相关协议
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 准备工作
- 数据迁移
- 数据同步
- 数据订阅(Kafka 版)
- 前置校验不通过处理方法
- 割接说明
- 监控与告警
- 运维管理
- 实践教程
- 常见问题
- 错误处理
- API 文档
- History
- Introduction
- Introduction
- API Category
- Making API Requests
- (NewDTS) Data Migration APIs
- DescribeMigrationJobs
- CreateMigrationService
- ModifyMigrationJob
- CreateMigrateCheckJob
- DescribeMigrationCheckJob
- SkipCheckItem
- StartMigrateJob
- CompleteMigrateJob
- ContinueMigrateJob
- DescribeMigrateDBInstances
- DescribeMigrationDetail
- DestroyMigrateJob
- IsolateMigrateJob
- ModifyMigrateJobSpec
- ModifyMigrateName
- ModifyMigrateRuntimeAttribute
- PauseMigrateJob
- RecoverMigrateJob
- ResumeMigrateJob
- StopMigrateJob
- ModifyMigrateRateLimit
- Data Sync APIs
- DescribeSyncJobs
- CreateSyncJob
- ConfigureSyncJob
- CreateCheckSyncJob
- DescribeCheckSyncJobResult
- SkipSyncCheckItem
- StartSyncJob
- IsolateSyncJob
- RecoverSyncJob
- PauseSyncJob
- ContinueSyncJob
- ResumeSyncJob
- StopSyncJob
- DestroySyncJob
- ResizeSyncJob
- ModifySyncJobConfig
- CreateModifyCheckSyncJob
- DescribeModifyCheckSyncJobResult
- StartModifySyncJob
- ModifySyncRateLimit
- Data Consistency Check APIs
- (NewDTS) Data Subscription APIs
- CreateSubscribe
- ConfigureSubscribeJob
- CreateSubscribeCheckJob
- DescribeSubscribeCheckJob
- StartSubscribe
- ModifySubscribeObjects
- DescribeSubscribeDetail
- DescribeSubscribeJobs
- ResumeSubscribe
- CreateConsumerGroup
- DescribeConsumerGroups
- ModifyConsumerGroupDescription
- ModifyConsumerGroupPassword
- DescribeOffsetByTime
- ResetConsumerGroupOffset
- DeleteConsumerGroup
- ResetSubscribe
- ModifySubscribeAutoRenewFlag
- ModifySubscribeName
- DescribeSubscribeReturnable
- IsolateSubscribe
- DestroyIsolatedSubscribe
- Data Types
- Error Codes
- DTS API 2018-03-30
- 相关协议
问题1
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:6 #rdb rdbfile:./tmp1600869159_89068.rdb rdbsize:2753701723 rdb_writed_size:1606959104 rdb_parsed_size:0 rdb_parsed_begin:0 rdb_parsed_time:0 #replication master_replid:0549e2f0bdf373cef0c4c89bb0ce9e1757c4b105 repl_offset:1327777565448 write_command_count:0 finish_command_count:0 last_replack_time:0 #queue send_write_pos:0 send_read_pos:0 response_write_pos:0 response_read_pos:0 errtime:1600870264 errmsg:read rdb eof save rdb fail ready shutdown dts
问题原因
检查源端 Redis 数据库日志,是否包含以下信息,说明源端的配置的缓冲区 client-output-buffer-limit 溢出。
psync scheduled to be closed ASAP for overcoming of output buffer limits
解决方法
请执行如下命令,设置 client-output-buffer-limit 为无限大,重新发起 DTS 任务。
config set client-output-buffer-limit 'slave 0 0 0'
问题2
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:8 #rdb rdbfile:./tmp1600395232_34851.rdb rdbsize:107994104 rdb_writed_size:107994104 rdb_parsed_size:107994104 rdb_parsed_begin:1600395238 rdb_parsed_time:5 #replication master_replid:995dba8ccffb7cc32a7c85de7b1632b952b74496 repl_offset:23851025 write_command_count:940765 finish_command_count:940763 last_replack_time:1600395298 #queue send_write_pos:440766 send_read_pos:440765 response_write_pos:440765 response_read_pos:440764 errtime:1600395297 errmsg:get rsp error:ERR value is not an integer or out of range command:*2 $4 INCR $35 APP_API_ORDER_CREATION_USER_4260882
问题原因
分别在该地区的两个 DTS Syncer 上进行抓包,发现 key 的 value 为字符,而非数字,导致 INCR 执行时失败。

解决方法
请删除相关 key 后,重新发起 DTS 迁移。
问题3
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
errmsg:Error reading bulk length while SYNCing:Operation now in progress read rdb length from src fail save rdb fail ready shutdown dts
问题原因
查看源实例的报错信息,可发现 rdb 文件没有目录的访问权限。
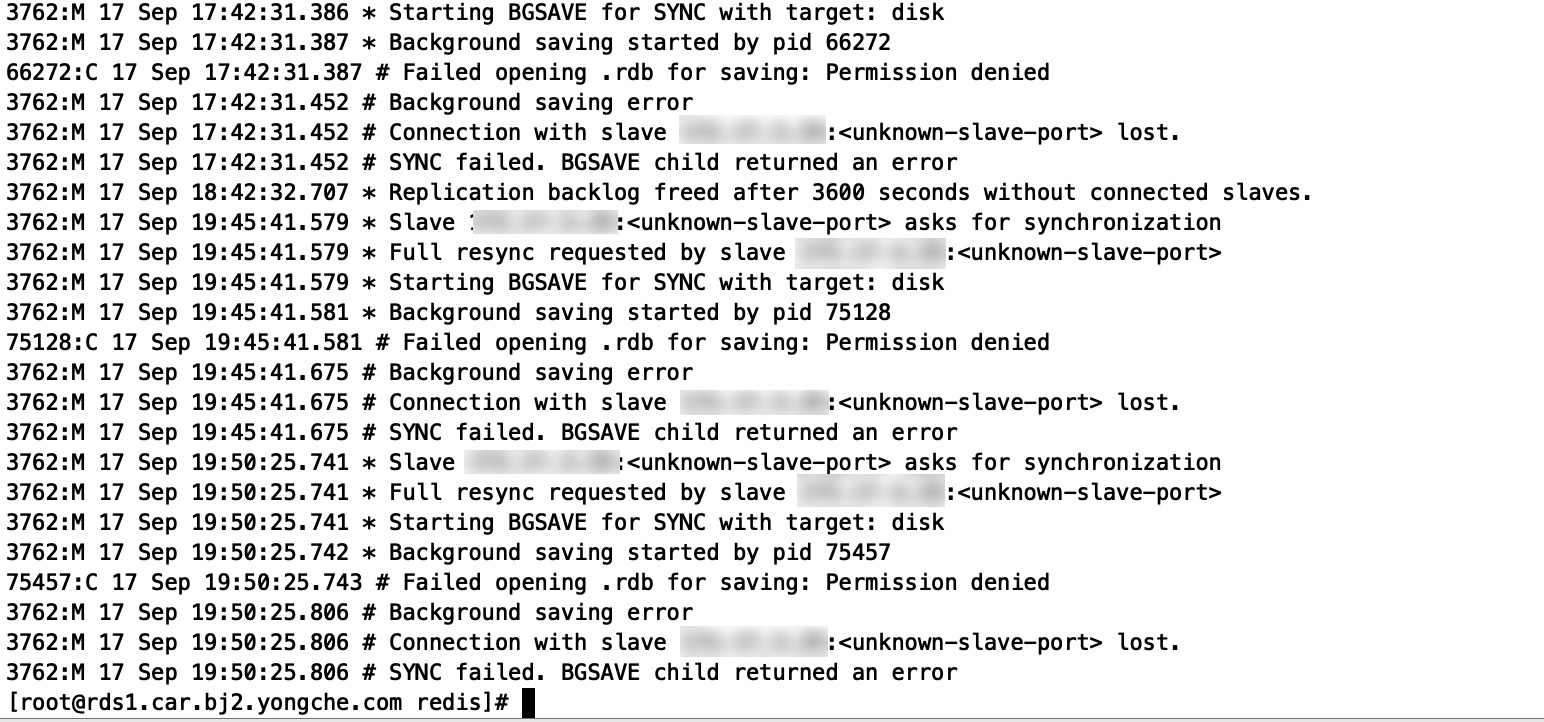
解决方法
执行如下命令,设置“无盘复制”,重新发起 DTS 任务。
config set repl-diskless-sync yes
问题4
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:6 #rdb rdbfile:./tmp1597977351_20216.rdb rdbsize:24282193511 rdb_writed_size:18683334200 rdb_parsed_size:0 rdb_parsed_begin:0 rdb_parsed_time:0 #replication master_replid:1b0da9f595cc40b795803eba3c9bea3aad1a1d68 repl_offset:921330115650 write_command_count:0 finish_command_count:0 last_replack_time:0 #queue send_write_pos:0 send_read_pos:0 response_write_pos:0 response_read_pos:0 errtime:1597978778 errmsg:write rdb data fail:456!=1696 error:No space left on device save rdb fail ready shutdown dts
问题原因
DTS Syncer 机器上的磁盘空间不足。
解决方法
清理 DTS Syncer 机器上的磁盘,或者挂一块新盘,然后重新发起 DTS 任务。
问题5
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:4/5 #rdb rdbfile: rdbsize:0 rdb_writed_size:0 rdb_parsed_size:0 rdb_parsed_begin:0 rdb_parsed_time:0 #replication master_replid:d3e707ec0e72c3908b0ce70dd2460f48086c5386 repl_offset:683087907631 write_command_count:0 finish_command_count:0 last_replack_time:0 #queue send_write_pos:0 send_read_pos:0 response_write_pos:0 response_read_pos:0 errtime:1654369638 errmsg:Error reading bulk length while SYNCing:Operation now in progress read rdb length from src fail save rdb fail ready shutdown dts
问题原因
源端内存不足导致 rdb 生成失败或者是网络不稳定。
解决方法
1. 调整源端内核连接限制和缓冲区限制。
断开源端链接,调整源端系统内核连接限制。
echo "net.ipv4.tcp_max_syn_backlog=4096" >> /etc/sysctl.confecho "net.core.somaxconn=4096" >> /etc/sysctl.confecho "net.ipv4.tcp_abort_on_overflow=0" /etc/sysctl.confsysctl -p
执行如下命令,调整源端的 client-output-buffer-limit 无限大。
config set client-output-buffer-limit 'slave 0 0 0'
2. 如果仍未解决,则增加源端节点所在机器的内存,保证节点有足够的资源产生 rdb 文件。
问题6
问题现象
在使用 DTS 从 Redis 标准架构(内存版)迁移到集群架构迁移过程中,提示如下错误信息:
[launch]state:8 #rdb rdbfile:./tmp1645683629_34614.rdb rdbsize:781035471 rdb_writed_size:781035471 rdb_parsed_size:781035471 rdb_parsed_begin:1645683632 rdb_parsed_time:25 #replication master_replid:5abe7987b1e263582c68835412d2963eeb0a3d60 repl_offset:895807918761 write_command_count:6102523 finish_command_count:6102137 last_replack_time:1645683656 #queue send_write_pos:101832 send_read_pos:101742 response_write_pos:101742 response_read_pos:101357 errtime:1645683657 errmsg:get rsp error:CROSSSLOT Keys in request don't hash to the same slot command:*3 $6 RENAME $16 dispatch:km:pool $34 dispatch:km:tmp-pool:1645683651224 ready shutdown dts send replconf ack to src fail:Bad file descriptor
问题原因
解决方法
请先迁移数据至云上标准架构的实例,或者更改业务逻辑清理多 key 操作。
问题7
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:7 #rdb rdbfile:./tmp1633836033_79441.rdb rdbsize:1008499748 rdb_writed_size:1008499748 rdb_parsed_size:607311937 rdb_parsed_begin:1633836038 rdb_parsed_time:0 #replication master_replid:d42935b9537b1d76ddd9e99e7cb8d4bc22a3e0c3 repl_offset:4649070152868 write_command_count:1569934 finish_command_count:1546843 last_replack_time:1633836088 #queue send_write_pos:69933 send_read_pos:69934 response_write_pos:69934 response_read_pos:46843 errtime:1633836089 errmsg:send replconf ack to src fail:Connection reset by peer rdb parse error: Wrong RDB checksum rdb load fail ready shutdown dts
在源节点运行日志里可以看到如下信息:
44:M 05 Jun 03:31:06.728 * Starting BGSAVE for SYNC with target: disk44:M 05 Jun 03:31:06.978 * Background saving started by pid 8989:C 05 Jun 03:32:08.417 # Error moving temp DB file temp-89.rdb on the final destination 20617.20324.rdb (in server root dir /opt/data/dump): No such file or directory44:M 05 Jun 03:32:08.698 # Background saving error44:M 05 Jun 03:32:08.698 # Connection with slave 10.xx.xx.119:<unknown-slave-port> lost.44:M 05 Jun 03:32:08.698 # SYNC failed. BGSAVE child returned an error44:M 05 Jun 03:50:24.626 * Slave 10.xx.xx.119:<unknown-slave-port> asks for synchronization44:M 05 Jun 03:50:24.626 * Full resync requested by slave 10.xx.xx.119:<unknown-slave-port>44:M 05 Jun 03:50:24.626 * Starting BGSAVE for SYNC with target: disk44:M 05 Jun 03:50:24.880 * Background saving started by pid 9090:C 05 Jun 03:51:22.585 * DB saved on disk90:C 05 Jun 03:51:22.739 * RDB: 280 MB of memory used by copy-on-write44:M 05 Jun 03:51:23.008 * Background saving terminated with success44:M 05 Jun 03:51:27.898 * Synchronization with slave 10.xx.xx.119:<unknown-slave-port> succeeded44:M 05 Jun 03:52:19.531 # Connection with slave client id #317862457 lost.
问题原因
这种现象常见为网络环境存在问题、数据库存在大 key 或者源端的 client-output-buffer-limit 溢出导致 DTS 任务连接源节点超时。
解决方法
排查源端网络环境是否存在问题。具体操作,请参见 连接 DB 检查。
清理源端数据库存在的大 key。具体操作,请参见 内存分析 快速查找大key,评估并进行删除。
执行如下命令,调整源端的 client-output-buffer-limit 无限大。
config set client-output-buffer-limit 'slave 0 0 0'
问题8
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:7 #rdb rdbfile:./tmp1654365384_70581.rdb rdbsize:1664871634 rdb_writed_size:1664871634 rdb_parsed_size:1266531 rdb_parsed_begin:1654365387 rdb_parsed_time:0 #replication master_replid:d3e707ec0e72c3908b0ce70dd2460f48086c5386 repl_offset:683001122815 write_command_count:17818 finish_command_count:11224 last_replack_time:0 #queue send_write_pos:30251 send_read_pos:17767 response_write_pos:17767 response_read_pos:11213 errtime:1654365387 errmsg:rdb parse error: Short read or OOM loading DB. Unrecoverable error rdb load fail ready shutdown dts
问题原因
一般在 DTS 任务失败后,再次重试时提示此错误信息,该信息说明目标节点非空或内存已经存满。
解决方法
问题9
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]state:8 #rdb rdbfile:./tmp1653290250_19158.rdb rdbsize:1721160435 rdb_writed_size:1721160435 rdb_parsed_size:1721160435 rdb_parsed_begin:1653290255 rdb_parsed_time:124 #replication master_replid:ed87c56060bc5f9b28da6d7ef2f83a15d56a4827 repl_offset:239048673513 write_command_count:360526495 finish_command_count:360520725 last_replack_time:1654350624 #queue send_write_pos:406694 send_read_pos:406694 response_write_pos:406694 response_read_pos:400925 errtime:1654350625 errmsg:redisBufferRead read rsp from target fail:1:Connection reset by peer ready shutdown dts send replconf ack to src fail:Bad file descriptor
问题原因
目标实例 Redis 节点发生了 HA 主备切换,或者 Proxy 节点发生了故障切换,导致同步任务失败。
解决方法
请重新创建 DTS 任务,配置 HA 切换后的新节点为数据迁移的目标节点。
问题10
问题现象
在使用 DTS 迁移过程中,目标实例的内存驱逐策略设置为 allkey-lru,提示如下错误信息:
[launch]state:8 #rdb rdbfile:./tmp1638263556_29975.rdb rdbsize:597343276 rdb_writed_size:597343276 rdb_parsed_size:428299275 rdb_parsed_begin:1638263575 rdb_parsed_time:7 #replication master_replid:ae0dfc45f72f3ee8642c8e31e493b6442179734f repl_offset:34832262785 write_command_count:6811 finish_command_count:6798 last_replack_time:1638263582 #queue send_write_pos:6811 send_read_pos:6811 response_write_pos:6811 response_read_pos:6799 errtime:1638263583 errmsg:get rsp error:OOM command not allowed when used memory > 'maxmemory'. command:*3 $3 SET $26 all_business_newmikoxmsong $1189783 [{"id":3,"label":"AI\\u5e73\\u53f0\\u90e8","node_level":0,"leaf":false,"children":[{"id":"887381","label":"[OMG][\\u4f53\\u80b2\\u641c\\u7d22][CMDB]","node_level":1,"leaf":false,"children":[{"id":"722605","label":"[\\u4e2a\\u6027\\u5316\\u63a8\\u8350\\u4e2d\\u5fc3][\\u817e\\u8baf\\u7f51\\u4f53\\u80b2APP\\u63a8\\u8350]","node_level":2,"leaf":false,"children":[],"collet":0}],"collet":0},{"id":"460871","label":"[OMG][\\u817e\\u8baf\\u89c6\\u9891\\u641c\\u7d22][CMDB]","node_level":1,"leaf":false,"children":[{"id":"383393","label":"[\\u641c\\u7d22\\u4e1a\\u52a1\\u4e2d\\u5fc3][\\u817e\\u8baf\\u89c6\\u9891\\u641c\\u7d22]","node_level":2,"leaf":false,"children":[],"collet":0}],"collet":0}]},{"id":8,"label":"IDC\\u5e73\\u53f0\\u90e8","node_level":0,"leaf":false,"children":[{"id":"452519","label":"IDC\\u5e73\\u53f0\\u90e8\\u81ea\\u7528[CMDB]","node_level":1,"leaf":false,"children":[{"id":"453099","label":"IDC\\u7cfb\\u7edf\\u5f00\\u53d1","node_level":2,"leaf":false,"children":[],"collet":0}],"collet":0}]},{"id":14 ready shutdown dts send replconf ack to src fail:Bad file descriptor
或出现如下报错,均属于同一类报错:
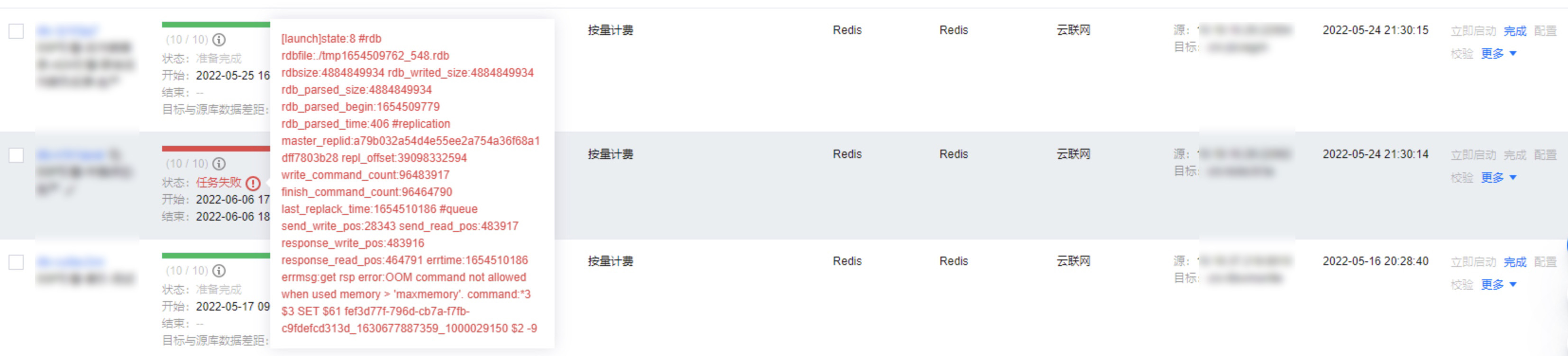
问题原因
目标实例内存容量小于源库待迁移数据所占内存。
解决方法
问题11
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
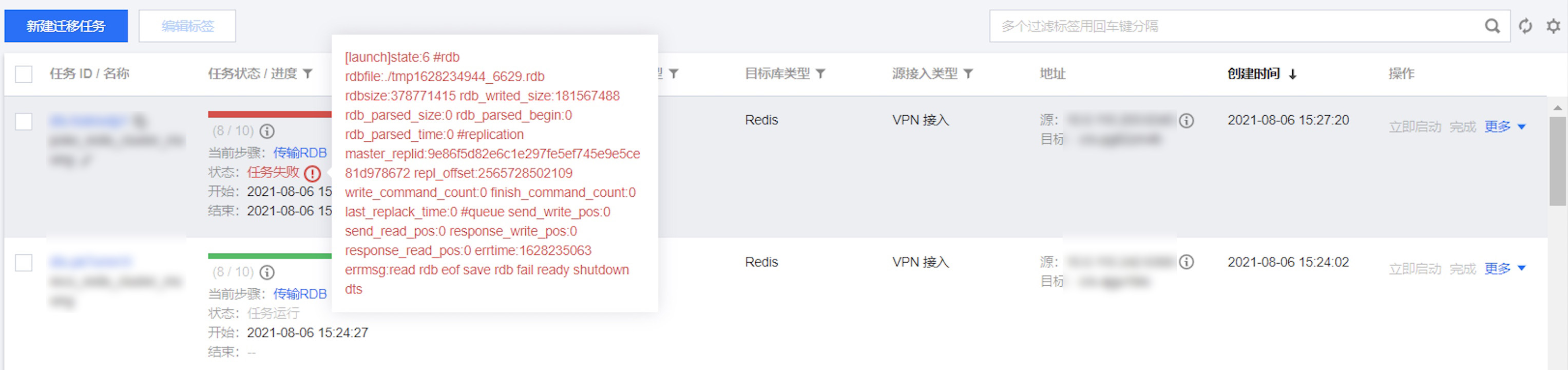
问题原因
使用代理方式启动 DTS 迁移任务,在任务启动阶段报错,通常是由于代理的带宽容量不足导致。
解决方法
问题12
问题现象
在使用 DTS 迁移过程中,提示如下错误信息:
[launch]SrcInstance nodes has changed.
问题原因
源节点发生 HA 切换主备节点,导致 DTS 任务同步失败。
解决方法
重新创建新的 DTS 任务,配置 HA 切换后的新节点为数据迁移的目标节点。

 是
是
 否
否
本页内容是否解决了您的问题?