- 动态与公告
- 新手指引
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 开发者指南
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Topic Management APIs
- Log Set Management APIs
- Index APIs
- Topic Partition APIs
- Machine Group APIs
- Collection Configuration APIs
- Log APIs
- Metric APIs
- Alarm Policy APIs
- Data Processing APIs
- Kafka Protocol Consumption APIs
- CKafka Shipping Task APIs
- Kafka Data Subscription APIs
- COS Shipping Task APIs
- SCF Delivery Task APIs
- Scheduled SQL Analysis APIs
- COS Data Import Task APIs
- Data Types
- Error Codes
- 常见问题
- 服务等级协议
- CLS 政策
- 联系我们
- 词汇表
- 动态与公告
- 新手指引
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 开发者指南
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Topic Management APIs
- Log Set Management APIs
- Index APIs
- Topic Partition APIs
- Machine Group APIs
- Collection Configuration APIs
- Log APIs
- Metric APIs
- Alarm Policy APIs
- Data Processing APIs
- Kafka Protocol Consumption APIs
- CKafka Shipping Task APIs
- Kafka Data Subscription APIs
- COS Shipping Task APIs
- SCF Delivery Task APIs
- Scheduled SQL Analysis APIs
- COS Data Import Task APIs
- Data Types
- Error Codes
- 常见问题
- 服务等级协议
- CLS 政策
- 联系我们
- 词汇表
安装与升级相关
如何在 TKE 集群中部署日志采集组件?
1. 登录 容器服务控制台。
2. 在左侧导航栏中,单击运维功能管理,进入功能管理页面。
3. 找到待操作的集群,单击设置。
4. 在弹出的窗口中,单击日志采集栏的编辑。
5. 勾选开启日志采集,单击确定。
6. 单击关闭。
如何在 TKE 集群中升级日志采集组件?
1. 登录 容器服务控制台。
2. 在左侧导航栏中,单击运维功能管理,进入功能管理页面。
3. 找到可升级组件的集群,单击设置。
4. 在弹出的窗口中,单击日志采集栏的编辑。
5. 单击升级组件。
网络与权限相关
云 API 域名不通,怎么办?
容器服务(Tencent Kubernetes Engine,TKE)日志采集组件和日志服务(Cloud Log Service,CLS)通信的组件 cls-provisioner 使用腾讯云 API 域名,需要保证域名的可连通性。如果存在组件部署失败等问题,并在日志中看到有如下图所示报错,即表示网络域名不通。

如上图所示,cls-provisioner 启动异常。通过查看日志发现,cls.internal.tencentcloudapi.com 域名不通。
在腾讯云上的机器,默认腾讯云的内外网域名都是联通的。通常导致此类问题的原因是 TKE 节点的 DNS 配置被修改过,您可通过如下两种方法进行修复:
TKE 节点机器的 DNS 配置添加腾讯云默认 DNS。
如果宿主机上的 DNS 是服务器是 core-dns,在 coredns 上添加腾讯云 DNS 解析即可。
说明:
建议在 TKE 集群中遇到域名不通的问题优先检查 TKE 节点 DNS 配置。
CLS 日志上传域名不通,怎么办?
日志上传的域名和云 API 域名不同,日志上传的域名为
<region>.cls.tencentcs.com(外网)和<region>.cls.tencentyun.com(内网),更多详情请参考 域名 文档。修复方案:
在集群节点机器打通域名的访问。
在 cls-provisioner 和 CLS 的通信中提示未授权,怎么办?
在 cls-provisioner 和 CLS 的通信中,一般会有类似如下的报错:

采集相关
采集到 CLS 的日志被截断了,怎么办?
在某些情况下,用户日志的输出类型是标准输出,但采集到 CLS 的日志发现被截断了。因为 Docker 的默认日志存储 json-tool,对单行日志大小有限制,所以超过16K的日志会进行截断。
修复方案:
修改日志输出,单行日志打印不要超过16K。
日志重复采集,怎么办?
用户通过 CLS 控制台检索,发现有些日志出现了重复采集。此时,可以优先检查日志输出的路径,确认日志是否输出到 PV/PVC 创建的持久化存储上。
如果日志输出到持久化存储上,当业务 Pod 重建时,会导致日志会被重新采集。可以使用如下命令,查看 Pod 的 yaml 定义:
kubectl get pods <pod_name> -n <namespace> -o yaml | less
返回类似如下信息即表示日志输出到持久化存储上。
业务使用了 CFS,且 CFS 挂载到容器上。
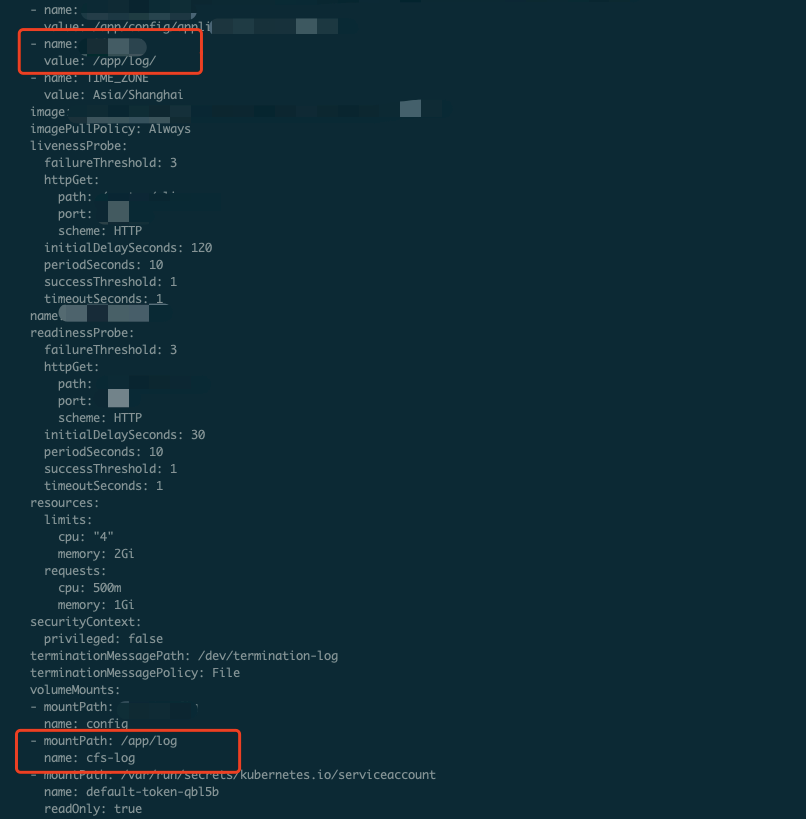
使用了 CFS 声明
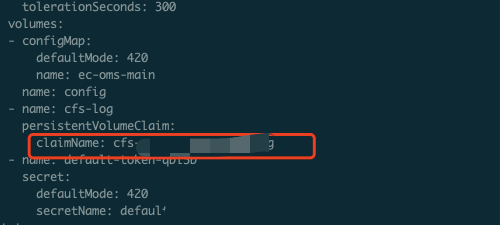
修复方案:
如果日志不需要保存在持久化存储上,可以在容器集群中开启日志采集,即可将日志采集到 CLS 内。
如果需要将日志文件保存在持久化存储上,可以在 CLS 控制台中配置 LogListener 采集规则时,将采集策略修改为增量采集,但是增量采集不保证会采集到全部日志。
日志漏采集,怎么办?
Loglistener 当前不支持保存在 NFS 上的日志。Loglistener 获取文件的更新信息是通过订阅 Linux 内核事件来的,并不是主动去扫描目标文件。
NFS 文件更新信息是在 NFS 服务端完成,无法在 client 本地的内核产生事件,因此无法被感知,所以 NFS 文件无法实时采集,会存在漏采集。
采集配置与 Pod 不匹配,怎么办?
您可以通过如下操作进行排查:
1. 使用如下命令,确认 Pod 的 label 是否与采集配置匹配。
kubectl get pods <pod_name> -n <namespace> --show-labels
匹配,请执行下一步。
不匹配,请对照正确内容修改采集配置。
2. 检查 Pod 的 workload(Deployment 或者 statefulsets 等)是否和采集配置匹配。
kubectl get pods -n <namespace> |grep testa
匹配,请执行下一步。
不匹配,请对照正确内容修改采集配置。
3. 使用如下命名,查看 Pod 的 yaml 定义,确认 container 的名字和采集配置中指定的容器名是否匹配。
kubectl get pods <pod_name> -n <namespace> -o yaml
匹配,任务完成。
不匹配,请对照正确内容修改采集配置。
采集路径不正确怎么办?
在采集容器文件或者采集宿主机文件的场景下,确认采集的目录路径正确,并且有符合采集规则的日志。
日志文件可以使用软连接吗?
容器文件的采集场景下,不支持匹配到的日志文件存在软连接的场景。
Kubernetes 场景下,CLS 的实现是解析容器文件在宿主机的位置。由于容器中的软连接目标指向的是容器内的路径,如果匹配到的采集文件存在软连接,将不能正确可达。
修复方案:
修改采集规则的路径和匹配文件,即采集日志文件实际所在路径和文件,避免匹配到软连接。
触发采集规格限制是什么?
由于 Loglistener 采集在容器场景下,资源收到限制,所以对监听的目录和文件有个数限制:
监控目录数:5000
监控文件数:10000
在采集容器文件或者采集宿主机文件场景下,可能会遇到此类问题。通常情况下,由于用户没有清理过期的日志文件,在查看 Loglistener 日志时,日志中有类似如下图信息:

修复方案:
在日志目录下,使用
tree 命令,查看整个目录下当前的目录数量和文件数量是否达到 Loglistener 限制。如果没有达到限制,在业务容器所在宿主机的 /var/log/tke-log-agent 下执行
tree -L 5,检查整体机器粒度是否达到限制。
因为 Loglistener 的限制是机器粒度的,如果某一个容器文件数量没有达到阈值,但是可能整体机器粒度所有的容器文件达到限制。如果达到限制,请将过期日志及时归档,减少 Loglistener 监控的目录和文件所消耗的资源。
在 Dockerfile 定义了 volume,怎么办?
Docker 场景:使用
docker history $image 命令,查看镜像在构建信息。Containerd 场景:使用
crictl inspecti $image 命令,查看镜像在构建信息。返回如下信息,可以看出,在 Dockerfile 中,用户自定义了一个 volume /logs/live-srv,刚好是日志所在目录。该操作会干扰日志采集组件找到正确的日志文件。
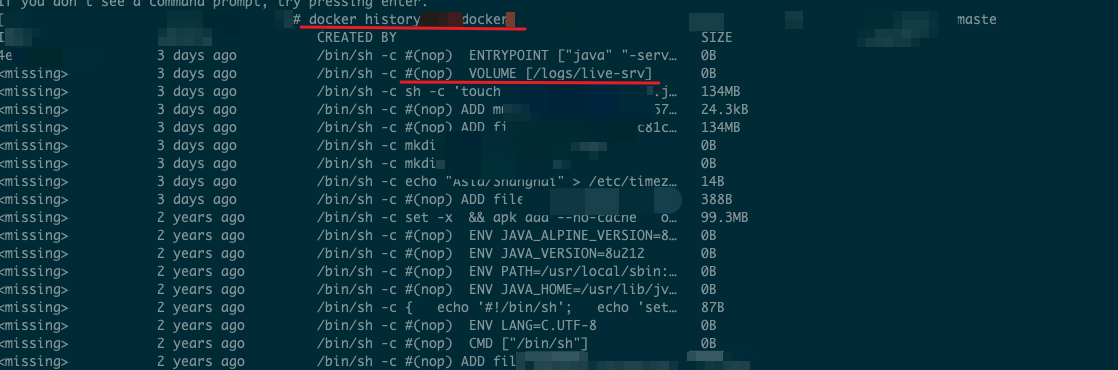
修复方案:
修改 Dockerfile,去掉 volume,然后重新构建镜像,重新部署服务。
修改服务日志写入目录,不要写入 Dockerfile 中定义的 volume 路径中。
其他问题
容器引擎类型识别错误,怎么办?
在 Docker 场景下,一些场景会触发老版本的一些 bug,导致日志采集组件不能正常启动,出现 panic 日志。
其主要原因是由于用户自定义了 TKE 集群节点的 Docker 配置,从而导致出现如下图所示的错误:
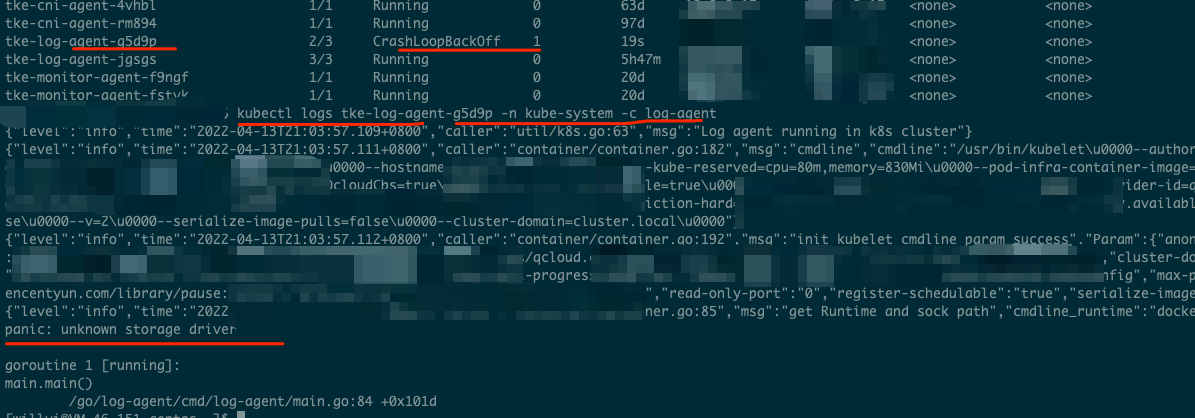
修复方案:
在 /etc/docker/daemon.json 配置中,添加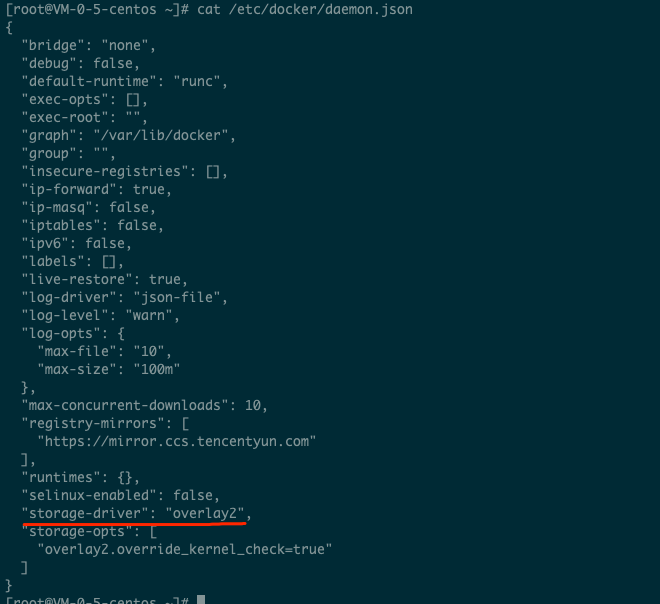
"storage-driver": "overlay2"。如下图所示:
在 TKE 控制台升级日志采集组件版本。因为新版本采集组件已经修复此问题,无需修改 Docker 配置。
filePattern 设置了子目录,怎么办?
如下图所示,用户在 filePattern 字段参数中设置了子目录。此操作会导致日志不能正常采集。
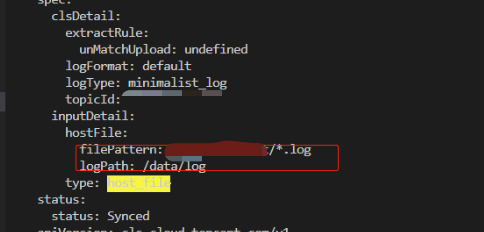
修复方案:
在 logPath 参数中设置日志文件目录,filePattern 中只设置文件类型参数,不设置子目录。

 是
是
 否
否
本页内容是否解决了您的问题?