- 动态与公告
- 新手指引
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 开发者指南
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Topic Management APIs
- Log Set Management APIs
- Index APIs
- Topic Partition APIs
- Machine Group APIs
- Collection Configuration APIs
- Log APIs
- Metric APIs
- Alarm Policy APIs
- Data Processing APIs
- Kafka Protocol Consumption APIs
- CKafka Shipping Task APIs
- Kafka Data Subscription APIs
- COS Shipping Task APIs
- SCF Delivery Task APIs
- Scheduled SQL Analysis APIs
- COS Data Import Task APIs
- Data Types
- Error Codes
- 常见问题
- 服务等级协议
- CLS 政策
- 联系我们
- 词汇表
- 动态与公告
- 新手指引
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 实践教程
- 开发者指南
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Topic Management APIs
- Log Set Management APIs
- Index APIs
- Topic Partition APIs
- Machine Group APIs
- Collection Configuration APIs
- Log APIs
- Metric APIs
- Alarm Policy APIs
- Data Processing APIs
- Kafka Protocol Consumption APIs
- CKafka Shipping Task APIs
- Kafka Data Subscription APIs
- COS Shipping Task APIs
- SCF Delivery Task APIs
- Scheduled SQL Analysis APIs
- COS Data Import Task APIs
- Data Types
- Error Codes
- 常见问题
- 服务等级协议
- CLS 政策
- 联系我们
- 词汇表
前提条件
2. 子账号/协作者需要主账号授权,授权步骤参见 基于 CAM 管理权限,复制授权策略参见 CLS 访问策略模板。
消费组消费流程
使用消费组消费数据时,服务端会管理消费组里的所有消费者的消费任务,根据主题分区和消费者的数量关系自动调整消费任务的均衡性,同时会记录每个主题分区的消费进度,保证不同消费者可以无重复消费数据。消费组消费的具体流程如下:
1. 创建消费组。
2. 每个消费者定期向服务端发送心跳。
3. 消费组根据主题分区负载情况自动分配主题分区给消费者。
4. 消费者根据所分配的分区列表,获取分区 offset 并消费数据。
5. 消费者周期性地更新分区的消费进度到消费组,便于下次消费组分配任务。
6. 重复步骤2 - 步骤6,直至消费结束。
负载均衡消费原理
消费组会根据活跃消费者和主题分区的数量动态调整每个消费者的消费任务,保证消费的均衡性。同时,消费者会保存每个主题分区的消费进度,保证故障恢复后可继续消费数据,避免重复消费。
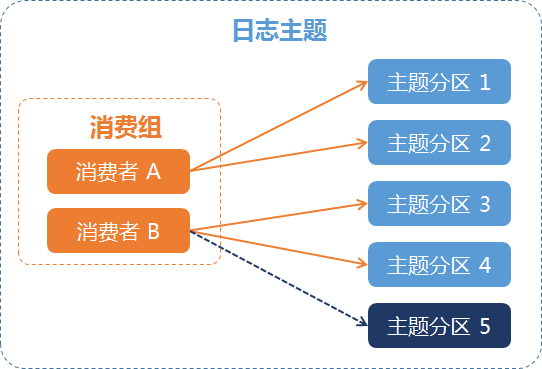
例一:主题分区发生变化
例如,某个日志主题有两个消费者,消费者 A 负责消费1,2号分区,消费者 B 负责消费3,4号分区,通过分裂操作新增主题分区5后,消费组会自动将5号分区分配给消费者 B 进行消费,如下图所示:
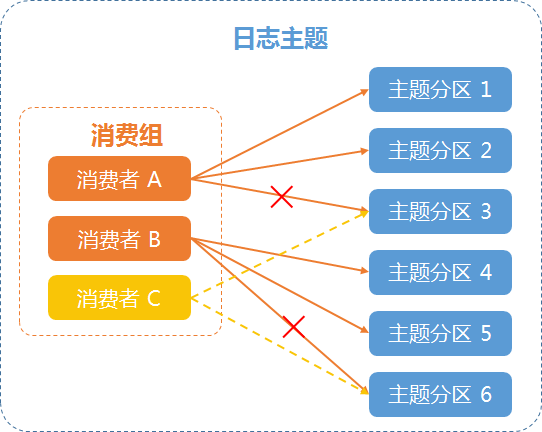
例二:消费者发生变化
例如,某个日志主题有两个消费者,消费者 A 负责消费1,2,3号分区,消费者 B 负责消费4,5,6号分区,为保证消费速度持平生成速度,新增一个消费者 C,消费组会重新进行均衡分配,将3、6号分区分配给新消费者 C 进行消费,如下图所示:
消费 Demo (Python)
说明:
Demo 的使用和说明如下:
1. 安装 SDK,具体可参见 tencentcloud-cls-sdk-python。
pip install git+https://github.com/TencentCloud/tencentcloud-cls-sdk-python.git
2. 消费者处理消费的数据,用户的日志数据被保存到 log_group 结构体中。log_group 结构体如下:
log_group {source //日志来源,一般为机器的 IPfilename //日志文件名logs {time //日志时间,unix 时间戳,微秒级别user_defined_log_kvs //用户日志字段}}
下面是 SampleConsumer 方法的实现:
class SampleConsumer(ConsumerProcessorBase):last_check_time = 0log_results = []lock = RLock()def initialize(self, topic_id):self.topic_id = topic_id# 处理消费的数据def process(self, log_groups, offset_tracker):for log_group in log_groups:for log in log_group.logs:# 处理单行数据item = dict()item['filename'] = log_group.filenameitem['source'] = log_group.sourceitem['time'] = log.timefor content in log.contents:item[content.key] = content.valuewith SampleConsumer.lock:# 数据汇总到SampleConsumer.log_resultsSampleConsumer.log_results.append(item)# 每隔3s提交一次offsetcurrent_time = time.time()if current_time - self.last_check_time > 3:try:self.last_check_time = current_timeoffset_tracker.save_offset(True)except Exception:import tracebacktraceback.print_exc()else:try:offset_tracker.save_offset(False)except Exception:import tracebacktraceback.print_exc()return None# Worker退出时,会调用该函数,可以在此处执行清理工作def shutdown(self, offset_tracker):try:offset_tracker.save_offset(True)except Exception:import tracebacktraceback.print_exc()
3. 创建消费者并启动消费者线程,该消费者会从指定的主题中消费数据。
配置参数 | 说明 | 默认值 | 取值范围 |
endpoint | - | 支持地域:北京,上海,广州,南京,中国香港,东京,美东,新加坡,法兰克福 | |
access_key_id | - | - | |
access_key | - | - | |
region | - | 支持地域:北京,上海,广州,南京,中国香港,东京,美东,新加坡,法兰克福 | |
logset_id | 日志集 ID,仅支持一个日志集 | - | - |
topic_ids | 日志主题 ID,多个主题请使用','隔开 | - | - |
consumer_group_name | 消费者组名称 | - | - |
internal | 内网:TRUE 公网:FALSE 说明: | FALSE | TRUE/FALSE |
consumer_name | 消费者名称。同一个消费者组内,消费者名称不可重复 | - | 0-9、aA-zZ、'-'、'_'、'.'组成的字符串 |
heartbeat_interval | 消费者心跳上报间隔,2个间隔没有上报心跳,会被认为是消费者下线 | 20 | 0-30分钟 |
data_fetch_interval | 消费者拉取数据间隔,不小于1秒 | 2 | - |
offset_start_time | 拉取数据的开始时间,字符串类型的 unix 时间戳,精度为秒,例如"1711607794",也可以直接可配置为"begin"和"end"。 begin:日志主题生命周期内的最早数据 end:日志主题生命周期内的最新数据 | "end" | "begin"/"end"/unix时间戳 |
max_fetch_log_group_size | 消费者单次拉取数据大小,默认2M,最大10M | 2097152 | 2M - 10M |
offset_end_time | 拉取数据的结束时间,支持字符串类型的 unix 时间戳,精度为秒,例如"1711607794"。不填写代表持续拉取 | - | - |
def sample_consumer_group():# 日志服务接入点,请您根据实际情况填写endpoint = os.environ.get('TENCENTCLOUD_LOG_SAMPLE_ENDPOINT', '')# 访问的地域region = os.environ.get('TENCENTCLOUD_LOG_SAMPLE_REGION', '')# 用户的Secret_idaccess_key_id = os.environ.get('TENCENTCLOUD_LOG_SAMPLE_ACCESSID', '')# 用户的Secret_keyaccess_key = os.environ.get('TENCENTCLOUD_LOG_SAMPLE_ACCESSKEY', '')# 消费的日志集IDlogset_id = os.environ.get('TENCENTCLOUD_LOG_SAMPLE_LOGSET_ID', '')# 消费的日志主题ID列表,多个主题用英文逗号分隔topic_ids = os.environ.get('TENCENTCLOUD_LOG_SAMPLE_TOPICS', '').split(',')# 消费组名称,同一个日志集下的消费组名称唯一consumer_group = 'consumer-group-1'# 消费者名称consumer_name1 = "consumer-group-1-A"consumer_name2 = "consumer-group-1-B"assert endpoint and access_key_id and access_key and logset_id, ValueError("endpoint/access_id/access_key and ""logset_id cannot be empty")# 创建访问云API接口的Clientclient = YunApiLogClient(access_key_id, access_key, region=region)SampleConsumer.log_results = []try:# 创建两个消费者配置option1 = LogHubConfig(endpoint, access_key_id, access_key, region, logset_id, topic_ids, consumer_group,consumer_name1, heartbeat_interval=3, data_fetch_interval=1,offset_start_time='end', max_fetch_log_group_size=1048576)option2 = LogHubConfig(endpoint, access_key_id, access_key, region, logset_id, topic_ids, consumer_group,consumer_name2, heartbeat_interval=3, data_fetch_interval=1,offset_start_time='end', max_fetch_log_group_size=1048576)# 创建消费者print("*** start to consume data...")client_worker1 = ConsumerWorker(SampleConsumer, consumer_option=option1)client_worker2 = ConsumerWorker(SampleConsumer, consumer_option=option2)# 启动消费者client_worker1.start()client_worker2.start()# 等待2分钟,或者获取到数据后继续往后执行sleep_until(120, lambda: len(SampleConsumer.log_results) > 0)# 关闭消费者print("*** stopping workers")client_worker1.shutdown()client_worker2.shutdown()# 打印汇总的日志数据print("*** get content:")for log in SampleConsumer.log_results:print(json.dumps(log))# 打印消费组信息:消费组的名称、消费的日志主题、消费者心跳超时时间print("*** consumer group status ***")ret = client.list_consumer_group(logset_id, topic_ids)ret.log_print()# 删除消费组print("*** delete consumer group")time.sleep(30)client.delete_consumer_group(logset_id, consumer_group)except Exception as e:import tracebacktraceback.print_exc()raise eif __name__ == '__main__':sample_consumer_group()

 是
是
 否
否
本页内容是否解决了您的问题?