- Release Notes and Announcements
- User Tutorial
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Operation Overview
- Access Management
- SDK Connection
- Daily Instance Operation
- Viewing Instance Information
- Viewing Memcached Edition Instances
- Assigning Instance to Project
- Editing Instance Tag
- Setting Maintenance Time
- Changing Instance Specification
- Adjusting the Number of Connections
- Enabling/Disabling Read/Write Separation
- Clearing Instances
- Returning and Isolating Instance
- Restoring Isolated Instance
- Eliminating Instance
- Upgrading Redis Edition Instances
- Managing Redis Edition Nodes
- Multi-AZ Deployment Management
- Backup and Restoration
- Data Migration for Redis Edition Instances
- Migration Scheme Overview
- Migration with DTS
- Migrating with Redis-Port
- Version Upgrade with DTS
- Check on Migration from Standard Architecture to Cluster Architecture
- Migration Guide for Legacy Cluster Edition
- Pika-to-Redis Data Migration Scheme
- SSDB-to-Redis Data Migration Scheme
- Common Error Messages
- FAQs
- Migration with redis-port
- Account and Password (Redis Edition)
- Parameter Configuration
- Slow Query
- Network and Security
- Monitoring and Alarms
- Redis Edition Event Management
- Global Replication for Redis Edition
- Performance Optimization
- Sentinel Mode
- Development Guidelines
- Command Compatibility
- Troubleshooting
- Practical Tutorial
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Instance APIs
- AddReplicationInstance
- AllocateWanAddress
- ChangeInstanceRole
- ChangeMasterInstance
- CleanUpInstance
- ClearInstance
- CloseSSL
- CreateInstanceAccount
- CreateReplicationGroup
- DeleteInstanceAccount
- DeleteReplicationInstance
- DescribeAutoBackupConfig
- DescribeBandwidthRange
- DescribeInstanceAccount
- DescribeInstanceDTSInfo
- DescribeInstanceZoneInfo
- DescribeInstances
- DescribeProxySlowLog
- DescribeSlowLog
- DescribeTendisSlowLog
- DestroyPostpaidInstance
- DestroyPrepaidInstance
- DisableReplicaReadonly
- EnableReplicaReadonly
- InquiryPriceCreateInstance
- InquiryPriceUpgradeInstance
- KillMasterGroup
- ModifyAutoBackupConfig
- ModifyInstance
- ModifyInstanceAccount
- ModifyInstanceReadOnly
- ModifyMaintenanceWindow
- ModifyNetworkConfig
- OpenSSL
- ReleaseWanAddress
- RenewInstance
- ResetPassword
- StartupInstance
- SwitchProxy
- UpgradeInstanceVersion
- UpgradeProxyVersion
- UpgradeSmallVersion
- UpgradeVersionToMultiAvailabilityZones
- DescribeCommonDBInstances
- ChangeReplicaToMaster
- CloneInstances
- CreateInstances
- DescribeInstanceDealDetail
- DescribeInstanceNodeInfo
- DescribeInstanceShards
- DescribeMaintenanceWindow
- DescribeParamTemplateInfo
- DescribeReplicationGroup
- DescribeSSLStatus
- DescribeTaskInfo
- DescribeTaskList
- ModfiyInstancePassword
- RemoveReplicationInstance
- UpgradeInstance
- DescribeInstanceEvents
- ModifyInstanceAvailabilityZones
- ModifyInstanceEvent
- SwitchAccessNewInstance
- DescribeInstanceSupportFeature
- Parameter Management APIs
- Other APIs
- Region APIs
- Monitoring and Management APIs
- Backup and Restoration APIs
- Data Types
- Error Codes
- FAQs
- Service Agreement
- Glossary
- Contact Us
- Release Notes and Announcements
- User Tutorial
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Operation Overview
- Access Management
- SDK Connection
- Daily Instance Operation
- Viewing Instance Information
- Viewing Memcached Edition Instances
- Assigning Instance to Project
- Editing Instance Tag
- Setting Maintenance Time
- Changing Instance Specification
- Adjusting the Number of Connections
- Enabling/Disabling Read/Write Separation
- Clearing Instances
- Returning and Isolating Instance
- Restoring Isolated Instance
- Eliminating Instance
- Upgrading Redis Edition Instances
- Managing Redis Edition Nodes
- Multi-AZ Deployment Management
- Backup and Restoration
- Data Migration for Redis Edition Instances
- Migration Scheme Overview
- Migration with DTS
- Migrating with Redis-Port
- Version Upgrade with DTS
- Check on Migration from Standard Architecture to Cluster Architecture
- Migration Guide for Legacy Cluster Edition
- Pika-to-Redis Data Migration Scheme
- SSDB-to-Redis Data Migration Scheme
- Common Error Messages
- FAQs
- Migration with redis-port
- Account and Password (Redis Edition)
- Parameter Configuration
- Slow Query
- Network and Security
- Monitoring and Alarms
- Redis Edition Event Management
- Global Replication for Redis Edition
- Performance Optimization
- Sentinel Mode
- Development Guidelines
- Command Compatibility
- Troubleshooting
- Practical Tutorial
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Instance APIs
- AddReplicationInstance
- AllocateWanAddress
- ChangeInstanceRole
- ChangeMasterInstance
- CleanUpInstance
- ClearInstance
- CloseSSL
- CreateInstanceAccount
- CreateReplicationGroup
- DeleteInstanceAccount
- DeleteReplicationInstance
- DescribeAutoBackupConfig
- DescribeBandwidthRange
- DescribeInstanceAccount
- DescribeInstanceDTSInfo
- DescribeInstanceZoneInfo
- DescribeInstances
- DescribeProxySlowLog
- DescribeSlowLog
- DescribeTendisSlowLog
- DestroyPostpaidInstance
- DestroyPrepaidInstance
- DisableReplicaReadonly
- EnableReplicaReadonly
- InquiryPriceCreateInstance
- InquiryPriceUpgradeInstance
- KillMasterGroup
- ModifyAutoBackupConfig
- ModifyInstance
- ModifyInstanceAccount
- ModifyInstanceReadOnly
- ModifyMaintenanceWindow
- ModifyNetworkConfig
- OpenSSL
- ReleaseWanAddress
- RenewInstance
- ResetPassword
- StartupInstance
- SwitchProxy
- UpgradeInstanceVersion
- UpgradeProxyVersion
- UpgradeSmallVersion
- UpgradeVersionToMultiAvailabilityZones
- DescribeCommonDBInstances
- ChangeReplicaToMaster
- CloneInstances
- CreateInstances
- DescribeInstanceDealDetail
- DescribeInstanceNodeInfo
- DescribeInstanceShards
- DescribeMaintenanceWindow
- DescribeParamTemplateInfo
- DescribeReplicationGroup
- DescribeSSLStatus
- DescribeTaskInfo
- DescribeTaskList
- ModfiyInstancePassword
- RemoveReplicationInstance
- UpgradeInstance
- DescribeInstanceEvents
- ModifyInstanceAvailabilityZones
- ModifyInstanceEvent
- SwitchAccessNewInstance
- DescribeInstanceSupportFeature
- Parameter Management APIs
- Other APIs
- Region APIs
- Monitoring and Management APIs
- Backup and Restoration APIs
- Data Types
- Error Codes
- FAQs
- Service Agreement
- Glossary
- Contact Us
Migration Principle
Data can be migrated from Pika to Redis online with support for full sync and incremental sync. The pika-migrate tool is virtualized as the Pika replica to get data from the master and then forward the data to Redis. Incremental sync is supported to implement online hot migration.
1. pika-migrate requests the full database data from the master and the corresponding binlog offsets through DBSync.
2. After getting the current full data from the master, the tool scans the database and then packages and forwards the data to Redis.
3. The tool performs incremental sync from the master through the obtained binlog offsets. During the incremental sync, it reassembles the binlog obtained from the master into a Redis command and forward the command to Redis.
Supported versions
This tool applies to Pika 3.2.0 or later in standalone mode with a single database. If the Pika version is earlier than 3.2.0, you need to upgrade the kernel version to 3.2.0.
Note
Pika supports different data structures using keys with the same name, while Redis does not. Therefore, in scenarios involving data structures using keys with the same name, the first data structure migrated to Redis will apply, and other data structures will be discarded.
This tool supports hot migration from Pika only in standalone mode with a single database. It will report an error and exit in case of the cluster mode or a multi-database scenario.
To prevent the tool from triggering repeated full syncs due to the clearing of binlogs from the master and writing dirty data to Redis, the tool is self-protected by reporting an error and exiting when full sync is triggered for the second time.
Migration Directions
1. Run the following command in the Pika master to keep 10,000 binlog files.
config set expire-logs-nums 10000
Note:
It may take a long time for pika-port to write full data to Redis, which will cause the original binlog offsets to be cleared from the master. It is necessary to keep 10,000 binlog files in the Pika master and ensure that they still exist when the tool requests incremental sync.
As binlog files use disk capacity, you can determine the number of binlog files to be retained as needed.
2. Modify the following parameters in the
pika.conf configuration file of the migration tool.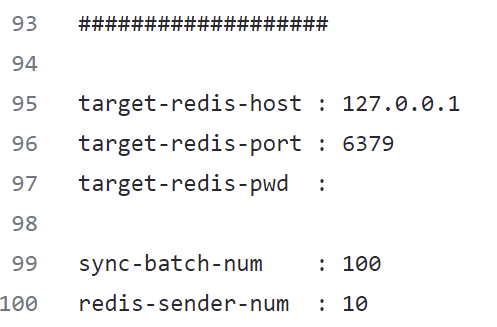
target-redis-host: Specify the IP address of Redis.
target-redis-port: Specify the port number of Redis.
target-redis-pwd: Specify the password of the default Redis account.
sync-batch-num: Specify
sync-batch-num data entries received by pika-migrate from the master for packaging and sending to Redis to increase the forwarding efficiency.redis-sender-num: Specify
redis-sender-num threads for forwarding packets. The forwarding command distributes the data to different threads based on the hash value of the key for sending, so you don't need to worry about messy data caused by multi-threaded sending.3. Run the following command in the path of the toolkit to start the pika-migrate tool and view the returned information.
pika -c pika.conf
4. Run the following command to disguise the migration tool as the slave and request sync from the master, and then observe whether an error is reported.
slaveof ip port force
5. After confirming that the master/slave relationship is successfully established, pika-migrate will forward data to the target Redis database. Run the following command to check for the delay in the master/slave sync. You can write a special key and then check in Redis whether the key can be obtained immediately, so as to determine whether the data sync is completed.
info Replication

 はい
はい
 いいえ
いいえ
この記事はお役に立ちましたか?