- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- CKafka 连接器
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- DataHub APIs
- ACL APIs
- Topic APIs
- DescribeTopicProduceConnection
- BatchModifyGroupOffsets
- BatchModifyTopicAttributes
- CreateConsumer
- CreateDatahubTopic
- CreatePartition
- CreateTopic
- CreateTopicIpWhiteList
- DeleteTopic
- DeleteTopicIpWhiteList
- DescribeDatahubTopic
- DescribeTopic
- DescribeTopicAttributes
- DescribeTopicDetail
- DescribeTopicSubscribeGroup
- FetchMessageByOffset
- FetchMessageListByOffset
- ModifyDatahubTopic
- ModifyTopicAttributes
- DescribeTopicSyncReplica
- Instance APIs
- Route APIs
- Other APIs
- Data Types
- Error Codes
- SDK 文档
- 通用参考
- 常见问题
- 服务等级协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- CKafka 连接器
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- DataHub APIs
- ACL APIs
- Topic APIs
- DescribeTopicProduceConnection
- BatchModifyGroupOffsets
- BatchModifyTopicAttributes
- CreateConsumer
- CreateDatahubTopic
- CreatePartition
- CreateTopic
- CreateTopicIpWhiteList
- DeleteTopic
- DeleteTopicIpWhiteList
- DescribeDatahubTopic
- DescribeTopic
- DescribeTopicAttributes
- DescribeTopicDetail
- DescribeTopicSubscribeGroup
- FetchMessageByOffset
- FetchMessageListByOffset
- ModifyDatahubTopic
- ModifyTopicAttributes
- DescribeTopicSyncReplica
- Instance APIs
- Route APIs
- Other APIs
- Data Types
- Error Codes
- SDK 文档
- 通用参考
- 常见问题
- 服务等级协议
- 联系我们
- 词汇表
Storm 是一个分布式实时计算框架,能够对数据进行流式处理和提供通用性分布式 RPC 调用,可以实现处理事件亚秒级的延迟,适用于对延迟要求比较高的实时数据处理场景。
Storm 工作原理
在 Storm 的集群中有两种节点,控制节点
Master Node和工作节点Worker Node。Master Node上运行Nimbus进程,用于资源分配与状态监控。Worker Node上运行Supervisor进程,监听工作任务,启动executor执行。整个 Storm 集群依赖zookeeper负责公共数据存放、集群状态监听、任务分配等功能。用户提交给 Storm 的数据处理程序称为
topology,它处理的最小消息单位是tuple,一个任意对象的数组。topology由spout和bolt构成,spout是产生tuple的源头,bolt可以订阅任意spout或bolt发出的tuple进行处理。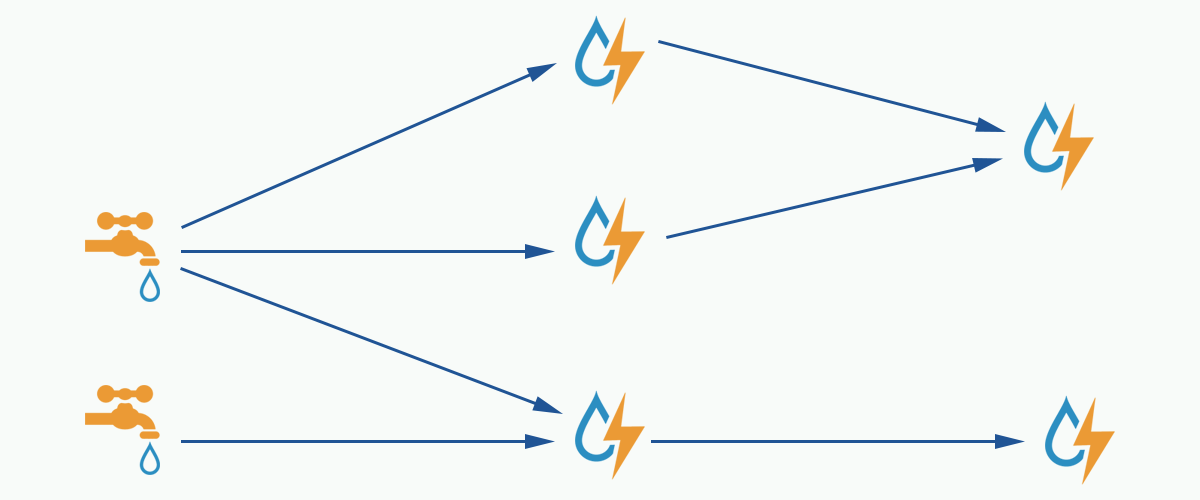
Storm with CKafka
Storm 可以把 CKafka 作为
spout,消费数据进行处理;也可以作为bolt,存放经过处理后的数据提供给其它组件消费。测试环境
Centos6.8系统
package | version |
maven | 3.5.0 |
storm | 2.1.0 |
ssh | 5.3 |
Java | 1.8 |
前提条件
下载并安装 JDK 8。具体操作,请参见 Download JDK 8。
下载并安装 Storm,参见 Apache Storm downloads。
已 创建 CKafka 实例。
操作步骤
步骤1:获取 CKafka 实例接入地址
1. 登录 CKafka 控制台。
2. 在左侧导航栏选择实例列表,单击实例的“ID”,进入实例基本信息页面。
3. 在实例的基本信息页面的接入方式模块,可获取实例的接入地址。
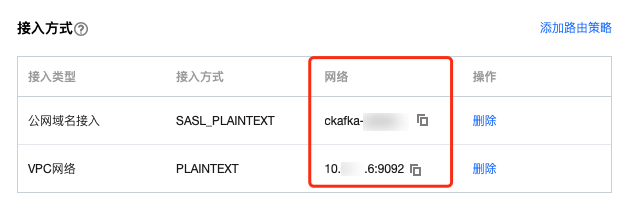
步骤2:创建 Topic
1. 在实例基本信息页面,选择顶部Topic管理页签。
2. 在 Topic 管理页面,单击新建,创建一个 Topic。

步骤3:添加 Maven 依赖
pom.xml 配置如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>storm</groupId><artifactId>storm</artifactId><version>0.0.1-SNAPSHOT</version><name>storm</name><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.apache.storm</groupId><artifactId>storm-core</artifactId><version>2.1.0</version></dependency><dependency><groupId>org.apache.storm</groupId><artifactId>storm-kafka-client</artifactId><version>2.1.0</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.11</artifactId><version>0.10.2.1</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion></exclusions></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency></dependencies><build><plugins><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><mainClass>ExclamationTopology</mainClass></manifest></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins></build></project>
步骤4:生产消息
使用 spout/bolt
topology 代码:
//TopologyKafkaProducerSpout.javaimport org.apache.storm.Config;import org.apache.storm.LocalCluster;import org.apache.storm.StormSubmitter;import org.apache.storm.kafka.bolt.KafkaBolt;import org.apache.storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper;import org.apache.storm.kafka.bolt.selector.DefaultTopicSelector;import org.apache.storm.topology.TopologyBuilder;import org.apache.storm.utils.Utils;import java.util.Properties;public class TopologyKafkaProducerSpout {//申请的ckafka实例ip:portprivate final static String BOOTSTRAP_SERVERS = "xx.xx.xx.xx:xxxx";//指定要将消息写入的topicprivate final static String TOPIC = "storm_test";public static void main(String[] args) throws Exception {//设置producer属性//函数参见:https://kafka.apache.org/0100/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html//属性参见:http://kafka.apache.org/0102/documentation.htmlProperties properties = new Properties();properties.put("bootstrap.servers", BOOTSTRAP_SERVERS);properties.put("acks", "1");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//创建写入kafka的bolt,默认使用fields("key" "message")作为生产消息的key和message,也可以在FieldNameBasedTupleToKafkaMapper()中指定KafkaBolt kafkaBolt = new KafkaBolt().withProducerProperties(properties).withTopicSelector(new DefaultTopicSelector(TOPIC)).withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper());TopologyBuilder builder = new TopologyBuilder();//一个顺序生成消息的spout类,输出field是sentenceSerialSentenceSpout spout = new SerialSentenceSpout();AddMessageKeyBolt bolt = new AddMessageKeyBolt();builder.setSpout("kafka-spout", spout, 1);//为tuple加上生产到ckafka所需要的fieldsbuilder.setBolt("add-key", bolt, 1).shuffleGrouping("kafka-spout");//写入ckafkabuilder.setBolt("sendToKafka", kafkaBolt, 8).shuffleGrouping("add-key");Config config = new Config();if (args != null && args.length > 0) {//集群模式,用于打包jar,并放到storm运行config.setNumWorkers(1);StormSubmitter.submitTopologyWithProgressBar(args[0], config, builder.createTopology());} else {//本地模式LocalCluster cluster = new LocalCluster();cluster.submitTopology("test", config, builder.createTopology());Utils.sleep(10000);cluster.killTopology("test");cluster.shutdown();}}}
创建一个顺序生成消息的 spout 类:
import org.apache.storm.spout.SpoutOutputCollector;import org.apache.storm.task.TopologyContext;import org.apache.storm.topology.OutputFieldsDeclarer;import org.apache.storm.topology.base.BaseRichSpout;import org.apache.storm.tuple.Fields;import org.apache.storm.tuple.Values;import org.apache.storm.utils.Utils;import java.util.Map;import java.util.UUID;public class SerialSentenceSpout extends BaseRichSpout {private SpoutOutputCollector spoutOutputCollector;@Overridepublic void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {this.spoutOutputCollector = spoutOutputCollector;}@Overridepublic void nextTuple() {Utils.sleep(1000);//生产一个UUID字符串发送给下一个组件spoutOutputCollector.emit(new Values(UUID.randomUUID().toString()));}@Overridepublic void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {outputFieldsDeclarer.declare(new Fields("sentence"));}}
为
tuple 加上 key、message 两个字段,当 key 为 null 时,生产的消息均匀分配到各个 partition,指定了 key 后将按照 key 值 hash 到特定 partition 上://AddMessageKeyBolt.javaimport org.apache.storm.topology.BasicOutputCollector;import org.apache.storm.topology.OutputFieldsDeclarer;import org.apache.storm.topology.base.BaseBasicBolt;import org.apache.storm.tuple.Fields;import org.apache.storm.tuple.Tuple;import org.apache.storm.tuple.Values;public class AddMessageKeyBolt extends BaseBasicBolt {@Overridepublic void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {//取出第一个filed值String messae = tuple.getString(0);// System.out.println(messae);//发送给下一个组件basicOutputCollector.emit(new Values(null, messae));}@Overridepublic void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {//创建发送给下一个组件的schemaoutputFieldsDeclarer.declare(new Fields("key", "message"));}}
使用 trident
使用 trident 类生成 topology:
//TopologyKafkaProducerTrident.javaimport org.apache.storm.Config;import org.apache.storm.LocalCluster;import org.apache.storm.StormSubmitter;import org.apache.storm.kafka.trident.TridentKafkaStateFactory;import org.apache.storm.kafka.trident.TridentKafkaStateUpdater;import org.apache.storm.kafka.trident.mapper.FieldNameBasedTupleToKafkaMapper;import org.apache.storm.kafka.trident.selector.DefaultTopicSelector;import org.apache.storm.trident.TridentTopology;import org.apache.storm.trident.operation.BaseFunction;import org.apache.storm.trident.operation.TridentCollector;import org.apache.storm.trident.tuple.TridentTuple;import org.apache.storm.tuple.Fields;import org.apache.storm.tuple.Values;import org.apache.storm.utils.Utils;import java.util.Properties;public class TopologyKafkaProducerTrident {//申请的ckafka实例ip:portprivate final static String BOOTSTRAP_SERVERS = "xx.xx.xx.xx:xxxx";//指定要将消息写入的topicprivate final static String TOPIC = "storm_test";public static void main(String[] args) throws Exception {//设置producer属性//函数参见:https://kafka.apache.org/0100/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html//属性参见:http://kafka.apache.org/0102/documentation.htmlProperties properties = new Properties();properties.put("bootstrap.servers", BOOTSTRAP_SERVERS);properties.put("acks", "1");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//设置TridentTridentKafkaStateFactory stateFactory = new TridentKafkaStateFactory().withProducerProperties(properties).withKafkaTopicSelector(new DefaultTopicSelector(TOPIC))//设置使用fields("key", "value")作为消息写入 不像FieldNameBasedTupleToKafkaMapper有默认值.withTridentTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper("key", "value"));TridentTopology builder = new TridentTopology();//一个批量产生句子的spout,输出field为sentencebuilder.newStream("kafka-spout", new TridentSerialSentenceSpout(5)).each(new Fields("sentence"), new AddMessageKey(), new Fields("key", "value")).partitionPersist(stateFactory, new Fields("key", "value"), new TridentKafkaStateUpdater(), new Fields());Config config = new Config();if (args != null && args.length > 0) {//集群模式,用于打包jar,并放到storm运行config.setNumWorkers(1);StormSubmitter.submitTopologyWithProgressBar(args[0], config, builder.build());} else {//本地模式LocalCluster cluster = new LocalCluster();cluster.submitTopology("test", config, builder.build());Utils.sleep(10000);cluster.killTopology("test");cluster.shutdown();}}private static class AddMessageKey extends BaseFunction {@Overridepublic void execute(TridentTuple tridentTuple, TridentCollector tridentCollector) {//取出第一个filed值String messae = tridentTuple.getString(0);//System.out.println(messae);//发送给下一个组件//tridentCollector.emit(new Values(Integer.toString(messae.hashCode()), messae));tridentCollector.emit(new Values(null, messae));}}}
创建一个批量生成消息的 spout 类:
//TridentSerialSentenceSpout.javaimport org.apache.storm.Config;import org.apache.storm.task.TopologyContext;import org.apache.storm.trident.operation.TridentCollector;import org.apache.storm.trident.spout.IBatchSpout;import org.apache.storm.tuple.Fields;import org.apache.storm.tuple.Values;import org.apache.storm.utils.Utils;import java.util.Map;import java.util.UUID;public class TridentSerialSentenceSpout implements IBatchSpout {private final int batchCount;public TridentSerialSentenceSpout(int batchCount) {this.batchCount = batchCount;}@Overridepublic void open(Map map, TopologyContext topologyContext) {}@Overridepublic void emitBatch(long l, TridentCollector tridentCollector) {Utils.sleep(1000);for(int i = 0; i < batchCount; i++){tridentCollector.emit(new Values(UUID.randomUUID().toString()));}}@Overridepublic void ack(long l) {}@Overridepublic void close() {}@Overridepublic Map<String, Object> getComponentConfiguration() {Config conf = new Config();conf.setMaxTaskParallelism(1);return conf;}@Overridepublic Fields getOutputFields() {return new Fields("sentence");}}
步骤5:消费消息
使用 spout/bolt
//TopologyKafkaConsumerSpout.javaimport org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.storm.Config;import org.apache.storm.LocalCluster;import org.apache.storm.StormSubmitter;import org.apache.storm.kafka.spout.*;import org.apache.storm.task.OutputCollector;import org.apache.storm.task.TopologyContext;import org.apache.storm.topology.OutputFieldsDeclarer;import org.apache.storm.topology.TopologyBuilder;import org.apache.storm.topology.base.BaseRichBolt;import org.apache.storm.tuple.Fields;import org.apache.storm.tuple.Tuple;import org.apache.storm.tuple.Values;import org.apache.storm.utils.Utils;import java.util.HashMap;import java.util.Map;import static org.apache.storm.kafka.spout.FirstPollOffsetStrategy.LATEST;public class TopologyKafkaConsumerSpout {//申请的ckafka实例ip:portprivate final static String BOOTSTRAP_SERVERS = "xx.xx.xx.xx:xxxx";//指定要将消息写入的topicprivate final static String TOPIC = "storm_test";public static void main(String[] args) throws Exception {//设置重试策略KafkaSpoutRetryService kafkaSpoutRetryService = new KafkaSpoutRetryExponentialBackoff(KafkaSpoutRetryExponentialBackoff.TimeInterval.microSeconds(500),KafkaSpoutRetryExponentialBackoff.TimeInterval.milliSeconds(2),Integer.MAX_VALUE,KafkaSpoutRetryExponentialBackoff.TimeInterval.seconds(10));ByTopicRecordTranslator<String, String> trans = new ByTopicRecordTranslator<>((r) -> new Values(r.topic(), r.partition(), r.offset(), r.key(), r.value()),new Fields("topic", "partition", "offset", "key", "value"));//设置consumer参数//函数参见http://storm.apache.org/releases/1.1.0/javadocs/org/apache/storm/kafka/spout/KafkaSpoutConfig.Builder.html//参数参见http://kafka.apache.org/0102/documentation.htmlKafkaSpoutConfig spoutConfig = KafkaSpoutConfig.builder(BOOTSTRAP_SERVERS, TOPIC).setProp(new HashMap<String, Object>(){{put(ConsumerConfig.GROUP_ID_CONFIG, "test-group1"); //设置groupput(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "50000"); //设置session超时put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, "60000"); //设置请求超时}}).setOffsetCommitPeriodMs(10_000) //设置自动确认时间.setFirstPollOffsetStrategy(LATEST) //设置拉取最新消息.setRetry(kafkaSpoutRetryService).setRecordTranslator(trans).build();TopologyBuilder builder = new TopologyBuilder();builder.setSpout("kafka-spout", new KafkaSpout(spoutConfig), 1);builder.setBolt("bolt", new BaseRichBolt(){private OutputCollector outputCollector;@Overridepublic void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {}@Overridepublic void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {this.outputCollector = outputCollector;}@Overridepublic void execute(Tuple tuple) {System.out.println(tuple.getStringByField("value"));outputCollector.ack(tuple);}}, 1).shuffleGrouping("kafka-spout");Config config = new Config();config.setMaxSpoutPending(20);if (args != null && args.length > 0) {config.setNumWorkers(3);StormSubmitter.submitTopologyWithProgressBar(args[0], config, builder.createTopology());}else {LocalCluster cluster = new LocalCluster();cluster.submitTopology("test", config, builder.createTopology());Utils.sleep(20000);cluster.killTopology("test");cluster.shutdown();}}}
使用 trident
//TopologyKafkaConsumerTrident.javaimport org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.storm.Config;import org.apache.storm.LocalCluster;import org.apache.storm.StormSubmitter;import org.apache.storm.generated.StormTopology;import org.apache.storm.kafka.spout.ByTopicRecordTranslator;import org.apache.storm.kafka.spout.trident.KafkaTridentSpoutConfig;import org.apache.storm.kafka.spout.trident.KafkaTridentSpoutOpaque;import org.apache.storm.trident.Stream;import org.apache.storm.trident.TridentTopology;import org.apache.storm.trident.operation.BaseFunction;import org.apache.storm.trident.operation.TridentCollector;import org.apache.storm.trident.tuple.TridentTuple;import org.apache.storm.tuple.Fields;import org.apache.storm.tuple.Values;import org.apache.storm.utils.Utils;import java.util.HashMap;import static org.apache.storm.kafka.spout.FirstPollOffsetStrategy.LATEST;public class TopologyKafkaConsumerTrident {//申请的ckafka实例ip:portprivate final static String BOOTSTRAP_SERVERS = "xx.xx.xx.xx:xxxx";//指定要将消息写入的topicprivate final static String TOPIC = "storm_test";public static void main(String[] args) throws Exception {ByTopicRecordTranslator<String, String> trans = new ByTopicRecordTranslator<>((r) -> new Values(r.topic(), r.partition(), r.offset(), r.key(), r.value()),new Fields("topic", "partition", "offset", "key", "value"));//设置consumer参数//函数参见http://storm.apache.org/releases/1.1.0/javadocs/org/apache/storm/kafka/spout/KafkaSpoutConfig.Builder.html//参数参见http://kafka.apache.org/0102/documentation.htmlKafkaTridentSpoutConfig spoutConfig = KafkaTridentSpoutConfig.builder(BOOTSTRAP_SERVERS, TOPIC).setProp(new HashMap<String, Object>(){{put(ConsumerConfig.GROUP_ID_CONFIG, "test-group1"); //设置groupput(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); //设置自动确认put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "50000"); //设置session超时put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, "60000"); //设置请求超时}}).setFirstPollOffsetStrategy(LATEST) //设置拉取最新消息.setRecordTranslator(trans).build();TridentTopology builder = new TridentTopology();// Stream spoutStream = builder.newStream("spout", new KafkaTridentSpoutTransactional(spoutConfig)); //事务型Stream spoutStream = builder.newStream("spout", new KafkaTridentSpoutOpaque(spoutConfig));spoutStream.each(spoutStream.getOutputFields(), new BaseFunction(){@Overridepublic void execute(TridentTuple tridentTuple, TridentCollector tridentCollector) {System.out.println(tridentTuple.getStringByField("value"));tridentCollector.emit(new Values(tridentTuple.getStringByField("value")));}}, new Fields("message"));Config conf = new Config();conf.setMaxSpoutPending(20);conf.setNumWorkers(1);if (args != null && args.length > 0) {conf.setNumWorkers(3);StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.build());}else {StormTopology stormTopology = builder.build();LocalCluster cluster = new LocalCluster();cluster.submitTopology("test", conf, stormTopology);Utils.sleep(10000);cluster.killTopology("test");cluster.shutdown();stormTopology.clear();}}}
步骤6:提交 Storm
使用 mvn package 编译后,可以提交到本地集群进行 debug 测试,也可以提交到正式集群进行运行。
storm jar your_jar_name.jar topology_name
storm jar your_jar_name.jar topology_name tast_name

 是
是
 否
否
本页内容是否解决了您的问题?