- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- CKafka 连接器
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- DataHub APIs
- ACL APIs
- Topic APIs
- DescribeTopicProduceConnection
- BatchModifyGroupOffsets
- BatchModifyTopicAttributes
- CreateConsumer
- CreateDatahubTopic
- CreatePartition
- CreateTopic
- CreateTopicIpWhiteList
- DeleteTopic
- DeleteTopicIpWhiteList
- DescribeDatahubTopic
- DescribeTopic
- DescribeTopicAttributes
- DescribeTopicDetail
- DescribeTopicSubscribeGroup
- FetchMessageByOffset
- FetchMessageListByOffset
- ModifyDatahubTopic
- ModifyTopicAttributes
- DescribeTopicSyncReplica
- Instance APIs
- Route APIs
- Other APIs
- Data Types
- Error Codes
- SDK 文档
- 通用参考
- 常见问题
- 服务等级协议
- 联系我们
- 词汇表
- 动态与公告
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- CKafka 连接器
- 实践教程
- 故障处理
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- DataHub APIs
- ACL APIs
- Topic APIs
- DescribeTopicProduceConnection
- BatchModifyGroupOffsets
- BatchModifyTopicAttributes
- CreateConsumer
- CreateDatahubTopic
- CreatePartition
- CreateTopic
- CreateTopicIpWhiteList
- DeleteTopic
- DeleteTopicIpWhiteList
- DescribeDatahubTopic
- DescribeTopic
- DescribeTopicAttributes
- DescribeTopicDetail
- DescribeTopicSubscribeGroup
- FetchMessageByOffset
- FetchMessageListByOffset
- ModifyDatahubTopic
- ModifyTopicAttributes
- DescribeTopicSyncReplica
- Instance APIs
- Route APIs
- Other APIs
- Data Types
- Error Codes
- SDK 文档
- 通用参考
- 常见问题
- 服务等级协议
- 联系我们
- 词汇表
数据上报查询
CKafka 连接器可应用在需要进行数据上报的场景。如手机 App 的操作行为分析、前端页面的 Bug 日志上报、业务数据的上报等等。一般情况下,这些上报的数据都需要转储到下游的存储分析系统里面进行处理(例如 Elasticsearch,HDFS 等)。在常规操作中,我们需要搭建 Server、购买存储系统、并在中间自定义代码进行数据接收、处理、转储等。流程繁琐,长期系统维护成本高。
CKafka 连接器旨在用 SaaS 化的思路解决这个问题,目标是通过如下两步:界面配置、SDK 上报,完成整个链路的搭建,并基于 Serverless 理念,以按量计费,弹性伸缩,无需预估容量等方式,简化客户的研发投入成本和实际的使用成本。

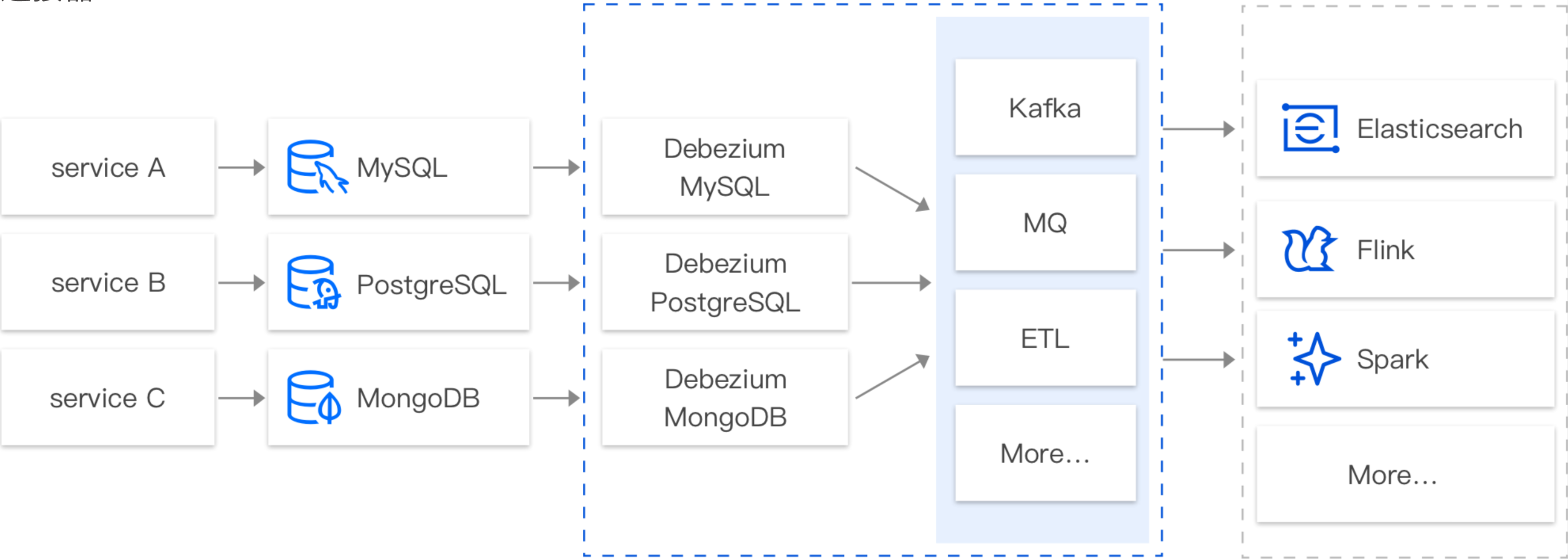
数据库变更信息订阅
CKafka 连接器支持基于 CDC(Change Data Capture)机制订阅多款数据库的变更数据。例如订阅 MySQL 的 Binlog,MongoDB 的 Change Stream,PostgreSQL 的行级的数据变更(Row-level Change),SQL Server 的行级的数据变更(Row-level Change)等。例如,在实际业务使用过程当中,业务经常需要订阅 MySQL 的 Binlog 日志,获取 MySQL 的变更记录(Insert、Update、Delete、DDL、DML 等),并针对这些数据进行对应的业务逻辑处理,如查询、故障恢复、分析等。
在默认情况下,客户往往需要自定义搭建基于 CDC 的订阅组件(例如 Canal、Debezium、Flink CDC 等)来完成对数据库的数据订阅。而在搭建、运维这些订阅组件的过程中,人力投入成本较高,需要搭建配套的监控体系,保证订阅组件的稳定运行。
基于此种情况,CKafka 连接器提供 SaaS 化的组件,通过界面配置化的完成数据的订阅、处理、转储等整个流程。
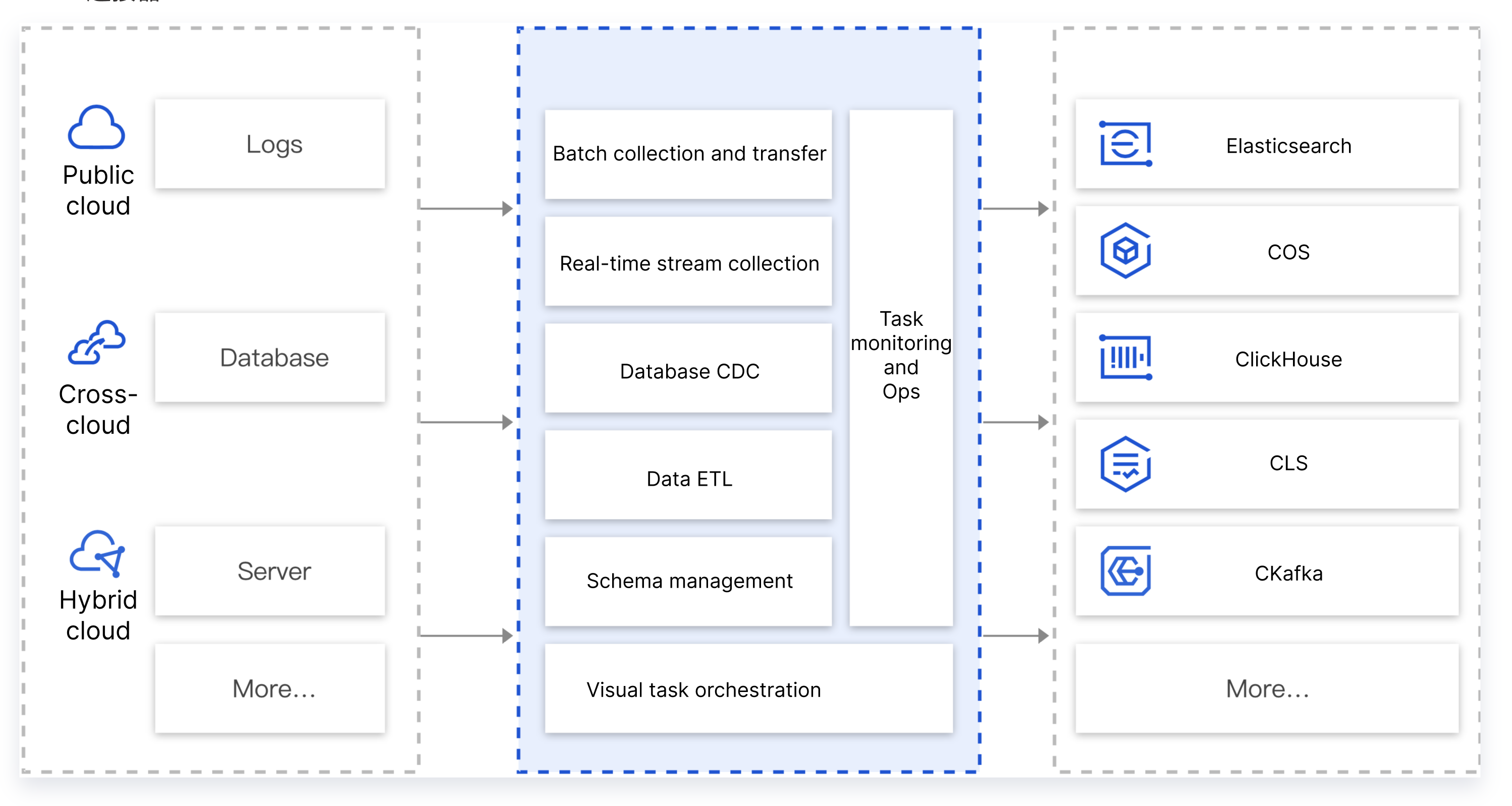
数据集成
CKafka 连接器支持将不同环境(腾讯公有云、用户自建 IDC、跨云、混合云等)的不同数据源(数据库、中间件、日志、应用系统等)的数据集成到公有云的消息队列服务中,以便进行数据的处理和分发。在实际业务过程中,用户经常需要将多个数据源的数据汇总到消息队列中,例如同一个应用业务客户端数据、业务 DB 的数据、业务的运行日志数据汇总到消息队列中进行分析处理。正常情况下,需要先将这些数据进行清洗格式化后,再做统一的转储、分析或处理。
CKafka 连接器提供了数据聚合、存储、处理、转储的能力。简而言之,就是提供数据集成的能力,将不同的数据源连接到下游的数据目标中。
数据清洗/转储
有一些客户的场景中,数据已经存在作为缓存层的消息队列(例如 Kafka)中了,需要进行清洗格式化(ETL)处理后,存储到下游(例如 Kafka、Elasticsearch、COS)等。常见的情况下,用户需要使用 Lostash、Flink 或自定义编码进行数据的清洗,并维护这些组件的稳定运行。当数据只需要简单的处理的情况下,学习数据处理组件的语法、规范、技术原理,维护数据处理组件就显得比较繁琐,额外增加了研发和运维的成本。
CKafka 连接器提供了轻便、界面化、可配置的数据处理(ETL)和转储的能力,支持界面化的配置数据的 ETL,同时将数据转储到下游存储。

 是
是
 否
否
本页内容是否解决了您的问题?