
Migrating Data with DTS

Last updated: 2024-01-24 11:08:34
In addition to PostgreSQL’s pg_dump and pg_restore tools, you can also migrate data to the cloud or between database instances through Data Transmission Service (DTS), a migration tool provided by TencentDB.
Supported Features
Data can be migrated from self-built PostgreSQL to TencentDB for PostgreSQL.
Data can be migrated from PostgreSQL of other clouds to TencentDB for PostgreSQL.
Data can be migrated from CVM/container-based self-built PostgreSQL to TencentDB for PostgreSQL.
Data can be migrated from one instance to another in TencentDB for PostgreSQL.
Database can be migrated across accounts.
Data can be migrated between TDSQL-C for PostgreSQL and TencentDB for PostgreSQL.
TencentDB for PostgreSQL 10 and later supports cross-version migration, such as from PostgreSQL 10 to PostgreSQL 12 or PostgreSQL 14 to PostgreSQL 11.
PostgreSQL 9.4, 9.5, and 9.6 can be used as the source database to perform "full + incremental migration" by installing extensions on the source database; otherwise, only full migration is supported.
Notes
To avoid migration failure, we recommend that you read the notes below before migrating data.
When DTS performs full data migration, it will occupy certain source instance resources, which may increase the load of the source instance and the database pressure. If your database has low configurations, we recommend that you migrate data during off-peak hours.
When you migrate an instance over the public network, make sure that the source database service is accessible over the public network and keep the public network connection stable. If the network fluctuates or fails, migration will fail, and you need to restart the migration task.
During migration, the migration rate can be affected by factors such as the read performance of the source, the network bandwidth between the source and the target instances, and the specification of the target instance. Migration concurrency is determined by number of CPU cores of target instance, for instance, if the target instance has 2 cores, concurrency will be 2.
Correlated data objects need to be migrated together; otherwise, migration will fail. Common correlations include table reference by views, view reference by views, view/table reference by stored procedures/functions/triggers, and tables correlated through primary/foreign keys.
To ensure migration efficiency, the data of CVM-based self-built instances cannot be migrated across regions over the private network. If you need to migrate data across regions, you can do so over the public network .
To migrate the entire instance, there cannot be users and roles in the target database with the same name as those in the source database.
If you select “full + incremental migration”, tables in the source database must have a primary key; otherwise data inconsistency will occur in the source and target database. We recommend that you select full + incremental data migration for tables without the primary key.
The migration account of the source database needs to have the replication permission.
DDL sync is not supported during incremental migration. Meanwhile, large object modification is not recommended. To sync DDL, you need to execute DDL modification on both the source database and target database at the same time when data are same in both databases and execute DML after modification is completed.
If the source migration account is not
superuser, select only the data to be migrated. We recommend that you manually create users and roles on the target database instead of migrating roles.The
wal_level parameter in the source database must be set to logical during incremental migration.The value of
max_replication_slots in the source database must be greater than the number of databases to be migrated during incremental migration.The value of
max_wal_senders in the source database must be greater than the number of databases to be migrated during incremental migration.The value of
max_worker_processes of the target database must be greater than that of max_logical_replication_workers during incremental migration . Note:
If logical replication is performed on the source during the migration, or if slots or senders are occupied by tasks such as backup, the migration may fail; therefore, we recommend that you set larger values for the above parameters.
The available size of the target database space must be at least 1.2 times that of the instances to be migrated in the source database. Incremental data migration will execute UPDATE and DELETE operations, causing some tables in the database to generate data fragments. Therefore, after migration is completed, the size of the tables in the target database may be larger than that in the source database. This is mainly because that the
autovcauum trigger conditions of the source and target databases are different. If the data in the source database is modified infrequently, the capacity of the target database may be smaller than that of the source instance.The target database and the source database can’t have migration object with the same name. To migrate roles, the account name can’t be the same in both databases.
Incremental migration is not supported for special extensions such as timescaledb and pipelinedb.
To avoid migration failure by unsupported extensions, the extensions must be the same in both the source and the target.
Most extensions have no impact on the migration, but the pre-migration check will check whether there is a different extension in the target database. If yes, the extension will be created in the target database during migration. If it is not created successfully, the migration will fail.
The migration user in the source database must have permissions on all objects; otherwise the data export will fail.
Ensure that the rules on character set and translation are same in the source and target database; otherwise the query result will be different. For details, see Parameter Configuration Conflict Check. If language and collation is “C”, and the counterpart is “UTF8” in other database, you can ignore this note.
It is recommended that all tables in the source database have a primary key. If not, the migration efficiency will be reduced, and same data will occur in extreme scenarios.
Directions
1 (Optional) When PostgreSQL 9.4, 9.5, and 9.6 are used as the source database for “full + incremental migration”, you can install the tencent_decoding extension as instructed below. For other scenarios, skip this step.
1. Download extension based on architecture of server where source database resides.
Only “x86_64” and “aarch64” system architectures are supported.
The version of the extension version need to be the same as that of PostgreSQL.
Requirements for the Glibc version: x86_64 system should be v2.17 - 323 or later; aarch64 system should be v2.17 - 260 or later.
View Glibc version on Linux system
RHEL/CentOS: rpm -q glibc
View Glibc version on other operation systems (Debian/Ubuntu/SUSE)
ldd --version | grep -i libc
2. Place the downloaded tencent_decoding.so file in the lib folder of the Postgres process directory without restarting the instance.
3. Log in to the DTS console, select Data Migration on the left sidebar, click Create Migration Task, and enter the Create Migration Task page.
4. On the Create Migration Task page, select the types, regions, and specifications of the source and target instances and click Buy Now.
Configuration Item | Description |
Source Instance Type | It is selected based on the source database type, and can’t be modified after purchase. In this document, select PostgreSQL. |
Source Instance Region | Select the source database region. If the source database is a self-built one, select a region nearest to it. |
Target Instance Type | It is selected based on the target database type, and can’t be modified after purchase. In this document, select PostgreSQL. |
Target Instance Region | Select the target database region. |
Specification | Select the specification of the migration linkage based on your business conditions. |
5. Complete task configuration, source database settings, and target database settings on the “Set source and target databases” page. After the connectivity test for the source and target databases is passed, click Create.
Note:
If the connectivity test fails, troubleshoot as prompted or as instructed in Database Connection Check and try again.
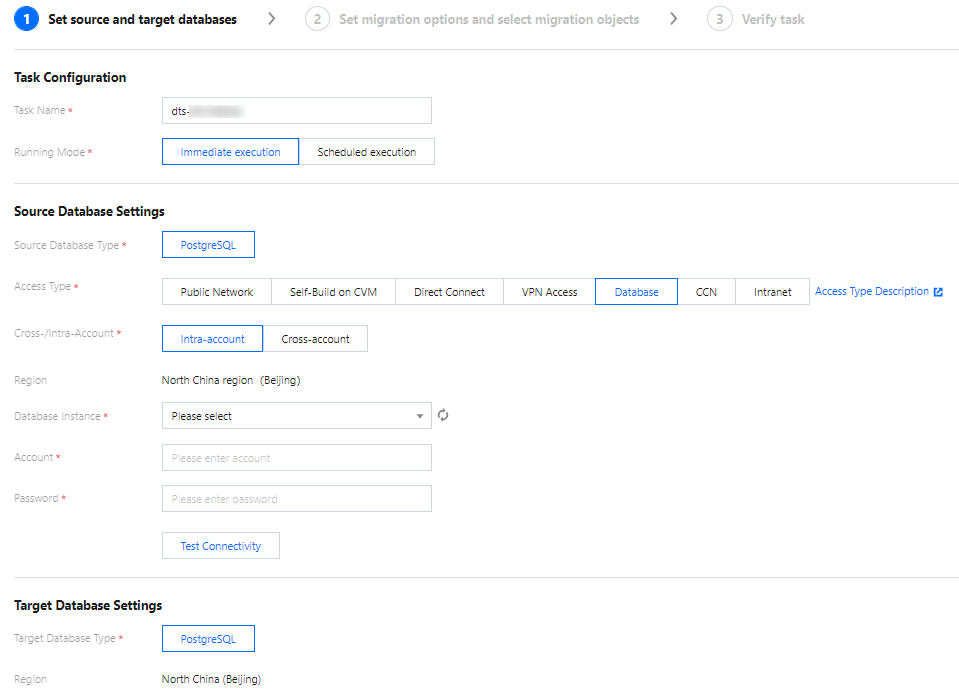
Configuration Type | Configuration Item | Description |
Task Configuration | Task name | Set a task name that is easy to identify |
| Running Mode | Immediate execution: The task will be started immediately after the task verification is passed. Scheduled execution: You need to configure a task execution time and the task will be started automatically then. |
| Tag | The tag is used to manage resources by category from different dimensions. If the existing tag does not meet your requirements, you can manage tags in the console. |
Source Database Settings | Source Database Type | The source database type selected during purchase, which can’t be modified. |
| Region | The source database region selected during purchase, which can’t be modified. |
| Access Type | Select a type based on your scenario. In this document, TencentDB is selected as an example. For the preparations for different access types, see . To ensure migration efficiency, the data of CVM-based self-built instances cannot be migrated across regions over the private network. If you need to migrate data across regions, you can do so over the public network. Public Network: The source database can be accessed through a public IP. Database: The source database is a TencentDB database. CCN: The source database can be interconnected with VPCs through CCN |
| Database Instance | Select the instance ID of source PostgreSQL database . |
| Account | The account of the source PostgreSQL database, which needs to have required permissions. |
| Password | The password of the source PostgreSQL database account. |
Target Database Settings | Target Database Type | The target database type selected during purchase, which cannot be changed. |
| Region | The target database region selected during purchase, which cannot be changed. |
| Access Type | In this document, “TencentDB” is selected by default based on your scenario. |
| Database Instance | Select the target TencentDB instance ID. |
| Account | The account of the target TencentDB database, which needs to have required permissions. |
| Password | The password of the target database account. |
6. On the “Set migration options and select migration objects” page, set the migration type and objects, and click Save.
Configuration Item | Description |
Migration Type | Select a type based on your scenario. Structural migration: Structured data such as databases and tables in the database will be migrated. Full migration: The entire database will be migrated. The migrated data will include only the existing data from the source database when the task is started, not incremental data written to the source database after the task is started. Full + incremental migration: The migrated data will include the existing data from the source database when the task is started as well as the incremental data written to the source database after the task is started. If there are data writes to the source database during migration, and you want to smoothly migrate the data in a non-stop manner, select this type. |
Migration Object | Entire instance: Migrate the entire database instance, including the metadata definitions of roles and users but excluding system databases such as system objects in PostgreSQL. Specified objects: Migrate specified objects. |
Specified objects | Select the object to be migrated in the “Source Database Object” box, and drag it to the “Selected Object” box. |
7. Verify the migration task on the “Verify task” page. After the task is verified, click Start.
If the verification failed, fix the problem as instructed in Fix for Verification Failure and initiate the verification task again.
Failed: It indicates that a check item failed and the task is blocked. You need to fix the problem and run the verification task again.
Alarm: It indicates that a check item doesn't completely meet the requirements, and the task can be continued, but the business will be affected. You need to assess whether to ignore the alarm or fix the problem and continue the task based on the alarm message.
8. Return to the data migration task list, and the task will be in the “Preparing” status. After running for 1-2 minutes, the data migration task will be started.
Select Structural migration or Full migration: Once completed, the task will be stopped automatically.
Select Full + Incremental migration: After full migration is completed, the migration task will automatically enter the incremental data sync stage, which will not stop automatically. You need to click Complete to manually stop the incremental data sync. Then, the task will enter the Completed status. At this point, do not make any changes to the source and target databases. The backend will automatically align some objects with the source.
Manually complete incremental data sync and business switchover at appropriate time.
Check whether the migration task is in the incremental sync stage without any lag. If so, stop writing data to the source database for a few minutes.
Manually complete incremental sync when the data gap between the target and the source databases is 0 MB and the time lag between them is 0 second.
9. (Optional) If you want to view or delete a task, click the task and select the target operation in the Operation column. For more information, see Viewing Task.
10. After the migration task status becomes Task successful, you can cut over the business. For more information, see Cutover Description.
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No
Feedback