- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
DLC 的数据引擎是 DLC 的数据分析计算服务的基础,用户在 DLC 进行的所有计算都需要使用数据引擎。根据用户的使用场景不同,可选择共享引擎或独享引擎。
共享引擎
共享引擎(public-engine)是 DLC 服务开通后自带的数据引擎,适合分析频率低、计算数据量较小的场景使用。用户无需配置、管理资源,按任务扫描量计费(具体资费参见 计费概述 ),不运行则不计费,具有高灵活、高可用的特点。
DLC 为 Serverless 架构,在一段时间内首次执行任务需要调度数据引擎,等待时间可能稍长。
独享引擎
按量计费:适合分析数据具有周期性,需根据业务峰谷进行弹性伸缩的用户,具有高灵活、高稳定对的特点,按 CU 使用量付费。
包年包月:适合长期大量稳定的数据分析需求,可根据业务峰谷进行弹性伸缩,无需等待资源拉起,随时可用,按集群规格按月付费,弹性扩容集群按 CU 使用量计费。
计算引擎类型
根据不同的使用场景,独享引擎可以选择不同的计算引擎来应对不同场景。
SparkSQL:适用于稳定高效的离线 SQL 任务。
Spark 作业:适用于 Spark 原生的流式/批式数据作业处理。
Presto:适用于敏捷、快速的交互式查询分析。
注意:
不同计算引擎类型不影响独享引擎计费单价。
引擎弹性规则
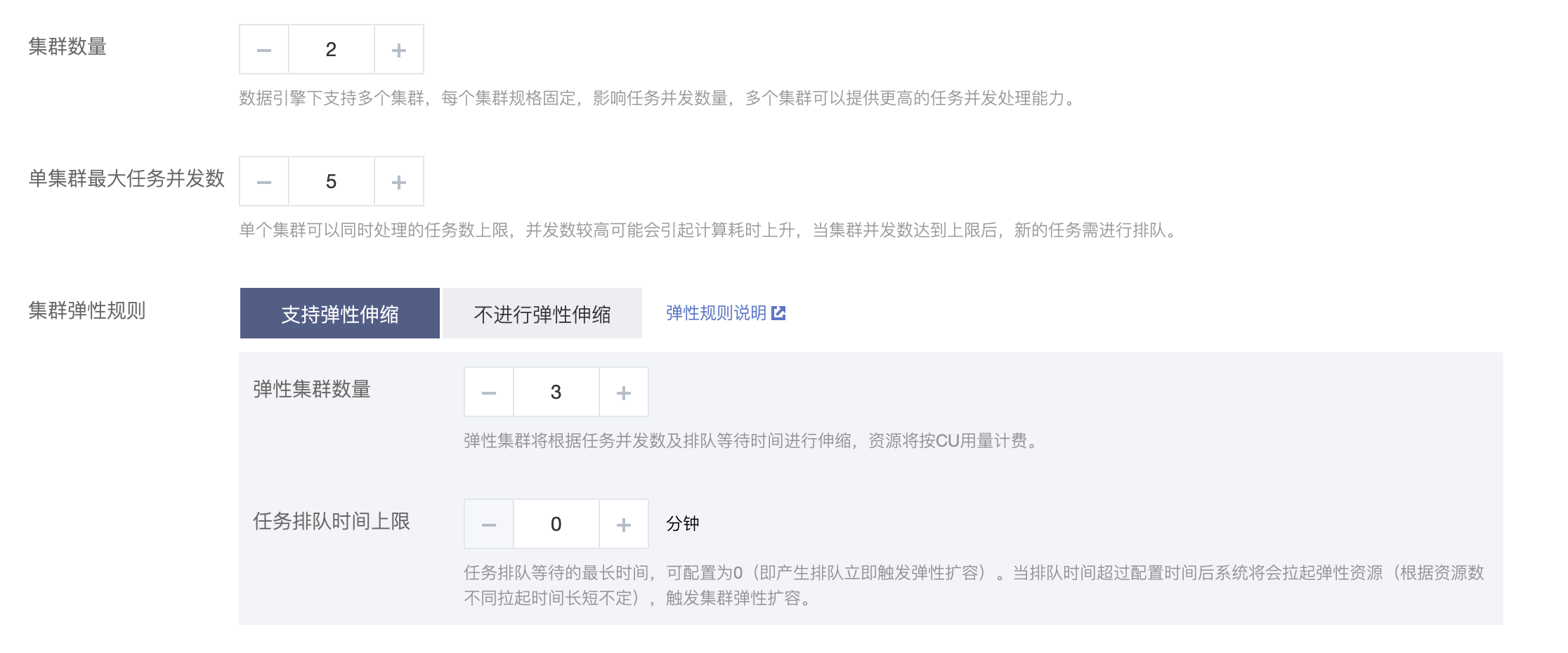
基本规则:当弹性集群数据大于0时,才会产生引擎扩缩容
扩容规则:当数据引擎目前存在的排队任务>空闲的并发容量,任务排队时间超过任务排队时间上限,且没有正在初始化的集群时,系统将会按照配置规则对数据引擎进行扩容。
缩容规则:当数据引擎目前的集群数>常驻的集群数目时,集群整体平均负载低于20%且有集群处于闲置状态时,系统将会对数据引擎进行缩容。
如下图所示:购买时配置了集群数为2个、弹性集群数为3个、任务排队时间上限为5分钟。集群任务高并发时,排队任务超过2个且排队时间超过5分钟,则系统将对数据引擎进行扩容,缓解任务排队情况。扩容成功一段时间后,集群任务排队情况得到缓解,存在集群闲置且负载低,系统将对数据引擎进行缩容。
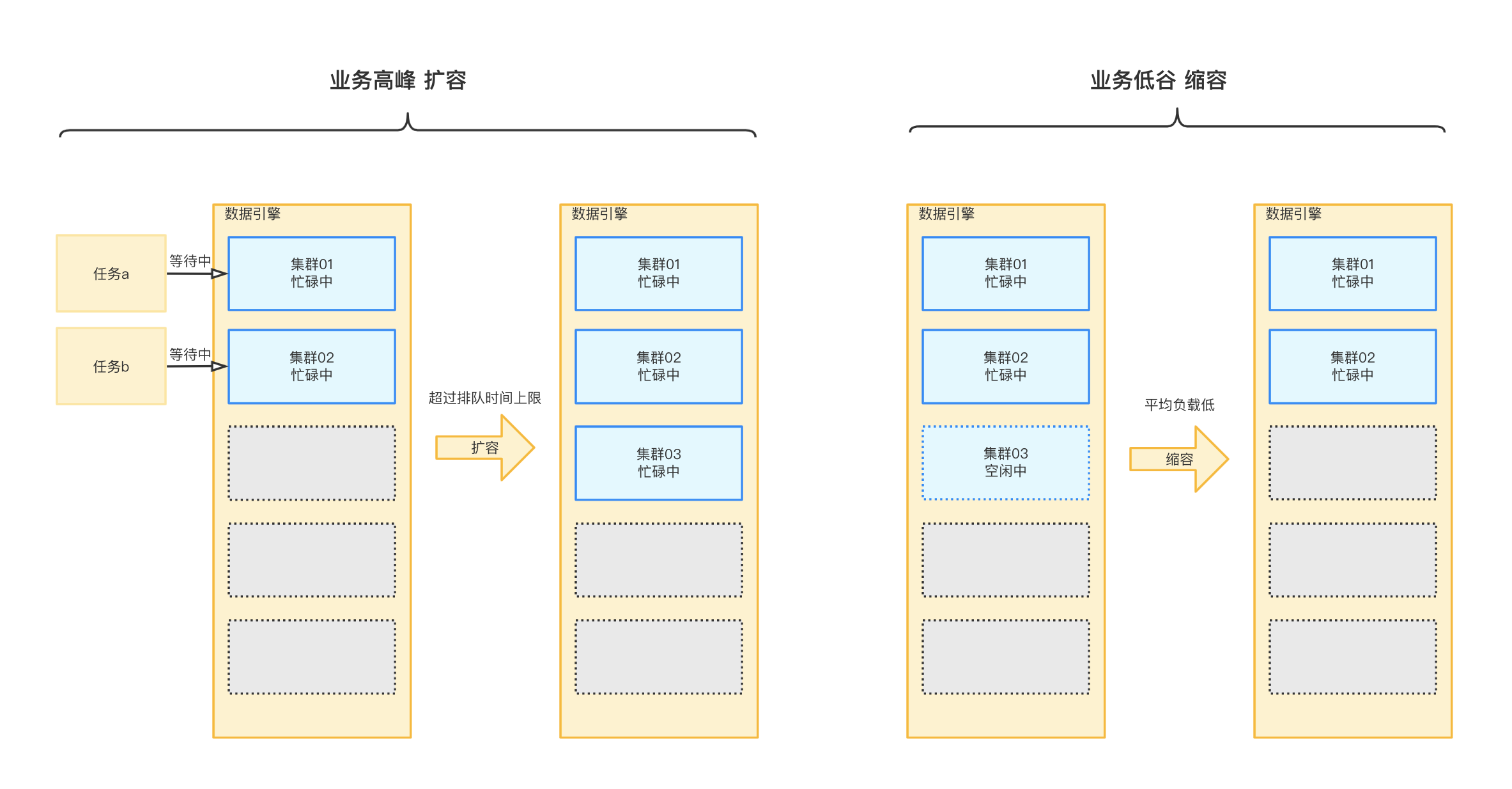
弹性扩缩容情况下,数据引擎的集群数量不会少于配置的集群数,不会大于配置的集群数和弹性集群数总和。
例如:购买时配置了集群数为2个,弹性集群数为3个,则弹性扩容后,集群数不会超过5个,弹性缩容后,集群数不会少于2个。
注意
按量付费集群若无需使用,可对集群进行挂起操作,避免资源浪费。
引擎运行状态
集群根据当前运行情况,分为启动中、运行、暂停、暂停中、变配中、隔离、隔离中、恢复中八个状态。
启动中:该集群资源正在被拉起,按量计费的独享引擎此时不计费。启动中的集群无法被数据计算选中使用。
运行:该集群正在运行,可被数据计算选中使用。
暂停:该集群暂停使用,无法被数据计算选中使用。
暂停中:该集群正在切换为暂停状态,会影响正在运行的任务,无法被数据计算选中使用。
变配中:该集群正在进行配置变更,配置变更期间将无法被数据计算使用。
隔离:由于账号欠费导致的集群被隔离,无法被数据计算选中使用。
隔离中:由于账号欠费导致,集群正在切换为隔离状态,会影响正在运行的任务,无法被数据计算选中使用。
恢复中:账号通过充值不再欠费后,集群由隔离状态恢复到运行状态的过程,无法被数据计算选中使用。

 是
是
 否
否
本页内容是否解决了您的问题?