数据湖计算 DLC 提供的 SQL 编辑器支持使用统一的 SQL 语句进行数据查询,兼容 SparkSQL,您使用标准 SQL 即可完成数据查询任务。
您可以通过数据探索进入 SQL 编辑器,在编辑器内可完成简单的数据管理、多 Session 的数据查询、查询记录管理、下载记录管理。
数据管理
数据管理支持新增数据源、数据库管理及数据表管理。
新建数据目录
目前数据湖计算 DLC 支持管理 COS 及 EMR HIVE 的数据目录。操作步骤如下。
2. 进入数据探索,鼠标移入库表列表上方的图标,单击新建数据目录即可进入新建流程。
详细操作指南可参见 查询其他数据源。 数据库管理
通过 SQL 编辑器,支持对数据库行进创建、删除、查看详情操作。
数据表管理
通过 SQL 编辑器,支持对数据表进行创建、查询、查看详情操作。
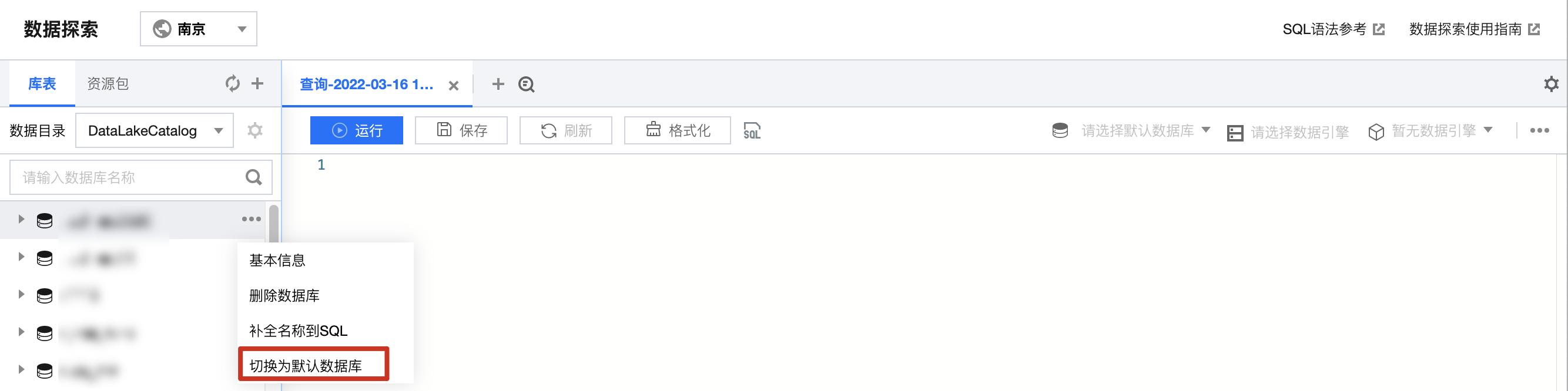
默认数据库切换
使用 SQL 编辑器时,可以指定查询任务的默认数据库,指定后若在查询语句中未申明数据库,则查询将在默认数据库下执行。
2. 进入数据探索,鼠标悬停需指定的数据库名称,单击图标,单击切换为默认数据库即可将该数据库指定为默认数据库。
数据查询
Session 管理
SQL 编辑器支持多个 Session 进行数据查询,每个 Session 内的配置独立(默认数据库、使用的计算引擎、查询记录等),方便用户进行多个任务运行及管理。
您可以通过单击图标创建 Session,单击 tab 栏进行编辑器界面的切换。 为了方便您的查询使用,常用的 Session 您可以点击保存按钮将 Session 进行保存,同时您可以通过点击图标快速打开您已保存的 Session。
针对已保存的 Session,您可以单击刷新按钮来更新同步已保存的信息,保证查询语句的准确性。
编辑器支持同时运行多个不同的 SQL 语句,单击运行按钮将会把编辑器内所有的 SQL 语句进行运行,同时拆分为多个 SQL 任务。
如需运行部分语句,可选中需运行的语句后单击部分运行。
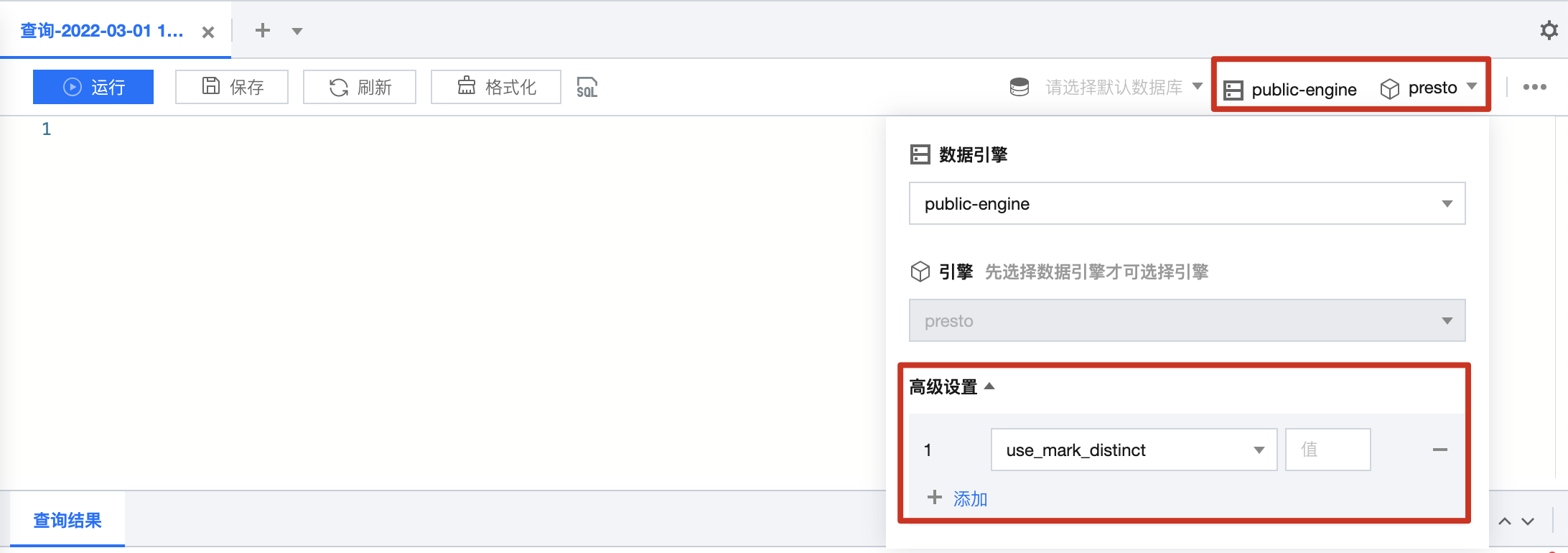
引擎参数配置
选择数据引擎后,支持对数据引擎进行参数配置,选择数据引擎后,在高级设置单击添加即可进行配置。
当前支持配置参数如下:
引擎 | 配置名称 | 初始值 | 配置说明 |
SparkSQL | spark.sql.files.maxRecordsPerFile | 0 | 写入单个文件的最大记录数。 如果该值为零或为负,则没有限制。 |
| spark.sql.autoBroadcastJoinThreshold | 10MB | 配置执行连接时显示所有工作节点的表的最大字节大小。 通过将此值设置为“-1”,可以禁用显示。 |
| spark.sql.shuffle.partitions | 200 | 默认分区数。 |
| spark.sql.sources.partitionOverwriteMode | static | 该值为 static 时,在执行覆盖写操作之前,会删除所有符合条件的分区。 举例说明:分区表中有一个“2022-01”的分区,当使用 INSERT OVERWRITE 语句向表中写入“2022-02”这个分区的数据时,会把“2021-01”的分区数据也覆盖掉。 当该值为 dynamic 时,不会提前删除分区,而是在运行时覆盖那些有数据写入的分区。 |
| spark.sql.files.maxPartitionBytes | 128MB | 读取文件时要打包到单个分区中的最大字节数。 |
Presto | use_mark_distinct | true | 决定引擎在执行 distinct 函数时是否进行数据重分布。 如果查询中多次调用 distinct 函数,推荐将该参数设置为 false。 |
| USEHIVEFUNCTION | true | 执行查询时是否使用 Hive 函数;如需使用 presto 原生函数,请将参数设置为 false。 |
| query_max_execution_time | - | 用于设置查询超时,在查询执行的时间超过设置的时间后,查询会被终止。单位支持 d-天,h-小时,m-分钟,s-秒,ms-毫秒(举例:1d 代表1天,3m 代表3分钟)。 |
| dlc.query.execution.mode | async | 引擎查询执行模式,默认为 async 模式, 该模式任务会完成全量查询计算,并将结果保存到 COS,再返回给用户,允许用户在查询完成后下载查询结果。 用户也可以将该值改为 sync,在 sync 模式下,查询不一定会执行全量计算,部分结果可用后,会直接由引擎返回给用户,不再保存到 COS。因此用户可获得更低查询延迟和耗时, 但结果只在系统中保存30s。推荐不需要从 COS 下载完整查询结果,但期望更低查询延迟和耗时时使用该模式,例如查询探索阶段、BI 结果展示。 |
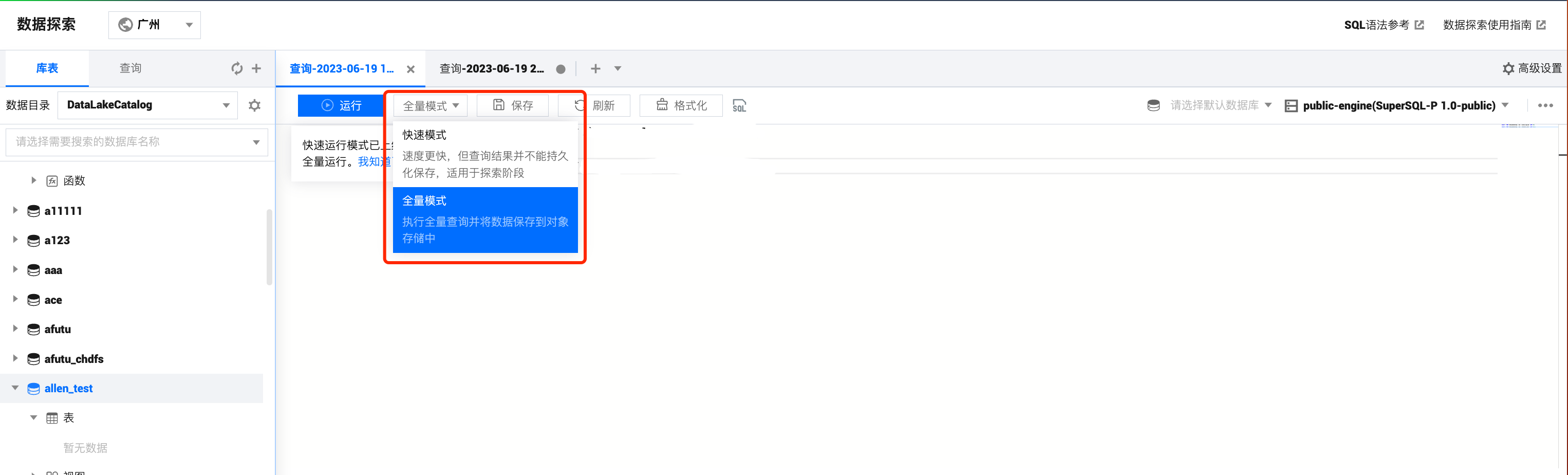
Presto 运行模式
当用户选择的引擎为 Presto 引擎时,数据探索运行支持用户选择“快速模式”运行或“全量模式”运行
1. 快速查询:速度更快,但查询结果并不能持久化保存,适用于探索阶段。
2. 全量模式:执行全量查询并将数据保存到对象存储中。
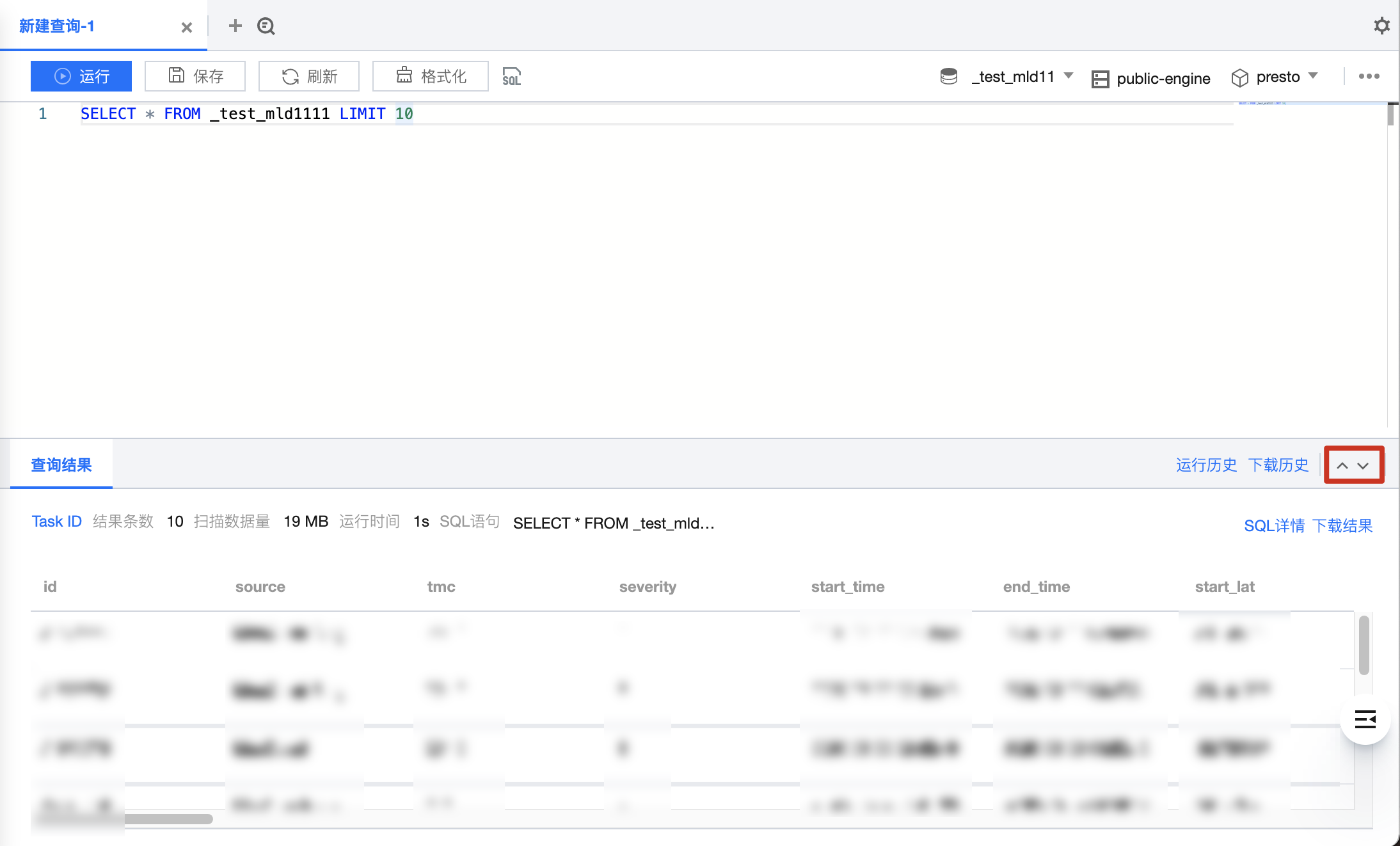
查询结果
通过 SQL 编辑器可直接查看查询结果,可以通过单击图表展开或收起查询结果的展示高度。
控制台单个任务最多会返回1000条结果,如需更多结果可使用 API。
查询结果在未指定 COS 存储路径情况下支持下载到本地。
历史运行查询
每个 Session 可保存3个月内的运行历史,支持查看近24小时的查询结果。可通过运行历史快速查找过去执行的任务信息。
下载历史管理
每个 Session 的下载任务可在下载历史中查看,可查询下载任务状态及相关参数信息。