1. Log in to the Data Lake Compute console and select the service region. You need to have the Tencent Cloud admin or financial collaborator permission.
2. Click Data engine on the left sidebar to enter the data engine management page.
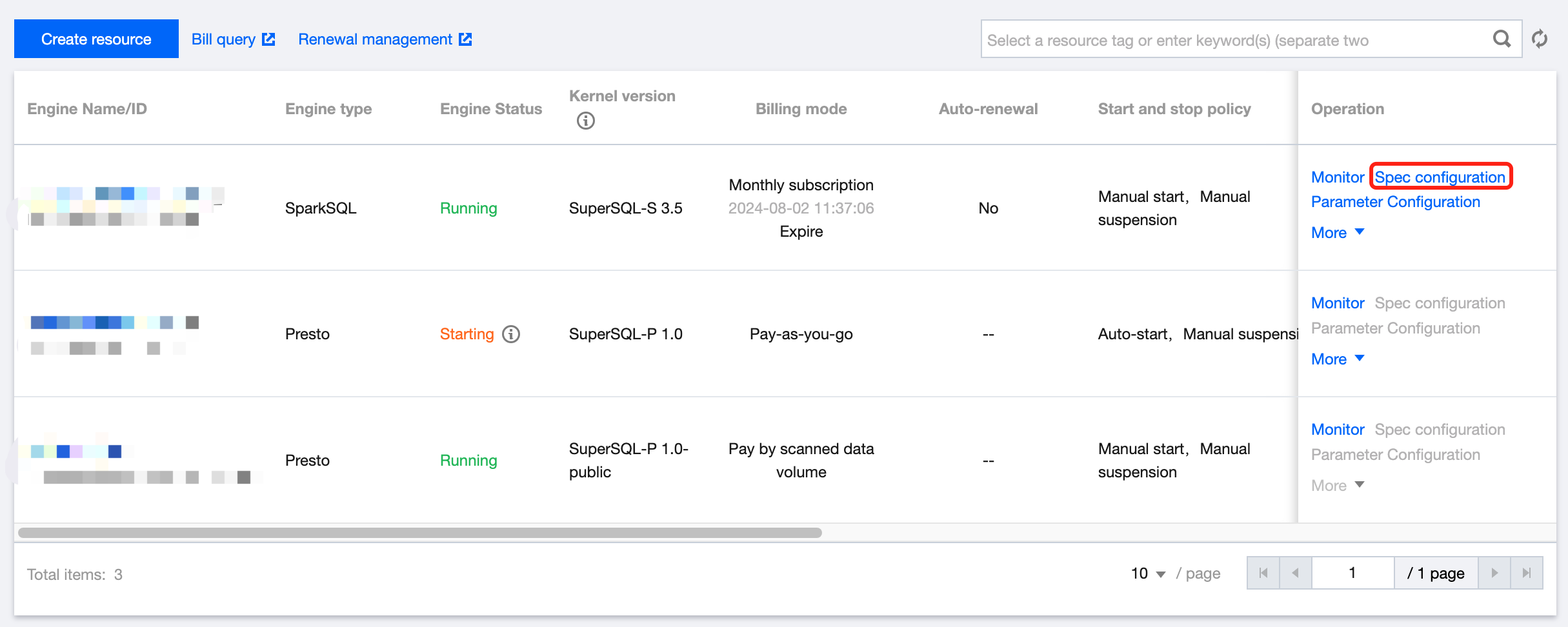
3. Find the target private engine and click Specconfiguration on the right to enter the configuration modification page, where you can modify the cluster specification and elastic scaling policy.
4. After making changes, click Save to submit the order and make the payment.
Option 2. Data engine details
1. Log in to the Data Lake Compute console and select the service region. You need to have the Tencent Cloud admin or financial collaborator permission.
2. Click Data engine on the left sidebar to enter the data engine management page.
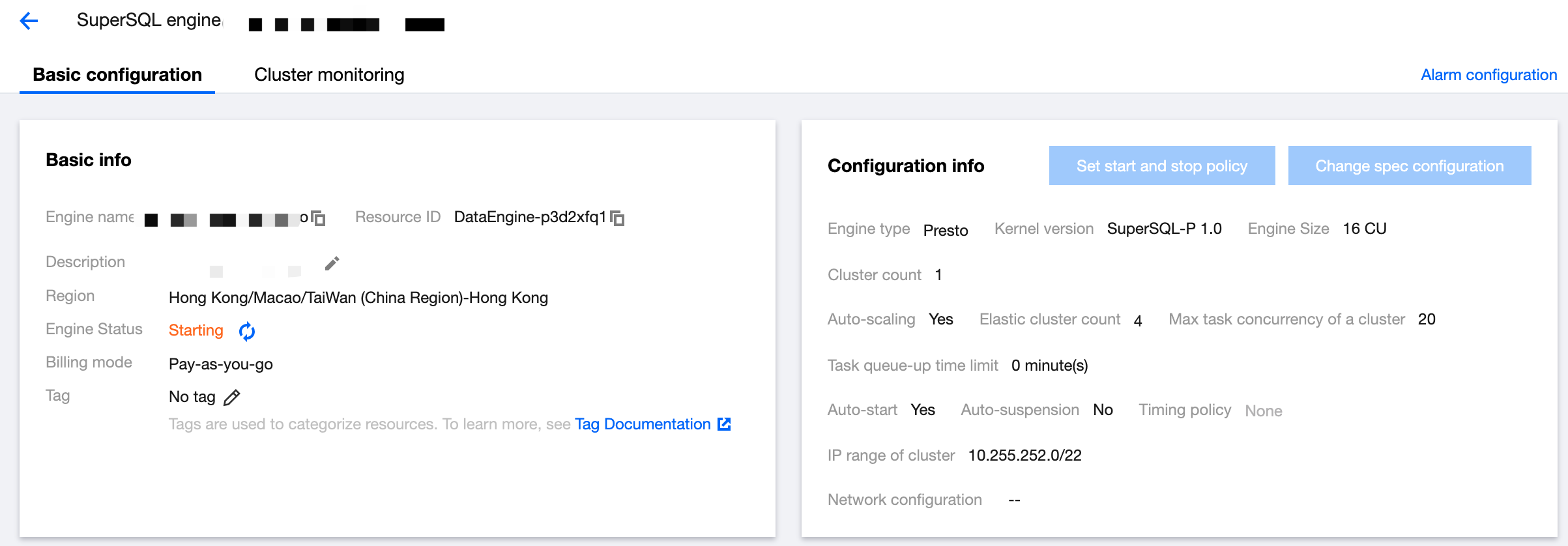
3. Find the target private engine and click the cluster name to enter the cluster details page, where you can modify the cluster specification and elastic scaling policy.
4. Adjust the parameters as needed and click Save.
Modifying the private engine information
1. Log in to the Data Lake Compute console and select the service region. You need to have the Tencent Cloud admin permission.
2. Click Data engine on the left sidebar to enter the data engine management page.
3. Find the target private engine and click the cluster name to enter the cluster details page, where you can modify the cluster description, automatic start policy, and suspension policy.
4. Adjust the parameters as needed and click Save.
Suspension policy: Configure the suspension method of a pay-as-you-go data engine. Automatic suspension and scheduled suspension are supported. A suspended pay-as-you-go data engine will not incur fees.
Auto-suspension: The data engine will be automatically switched to the Suspended status after it has been idle for 15 minutes.
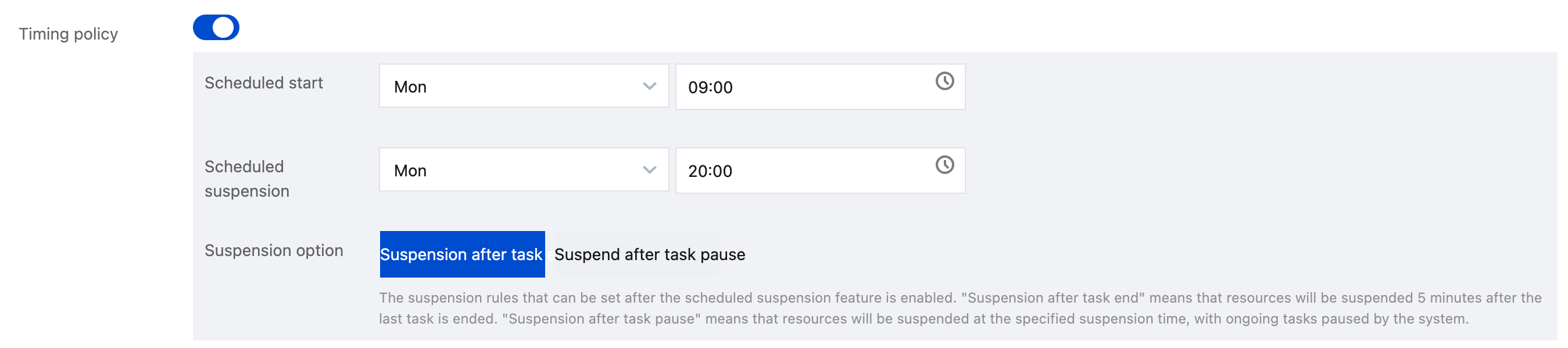
Timing policy: You can configure scheduled start and suspension policies by week. The system will start or suspend clusters regularly as configured.
Suspension after task end: After the specified time elapses, if a task is running, the system will automatically suspend the data engine within five minutes after the task ends.
Suspension after task pause: After the specified time elapses, if a task is running, the system will pause the task and suspend the data engine immediately.
Enable suspension policy management
It supports the configuration of start & suspend policies for the exclusive data engine of billing by volume, which facilitates management and cost control.
Note:
If the pay-as-you-go data engine is not suspended, charges will be generated. If the data engine is not needed, suspend it in time.
Startup policy: Supports automatic start, manual start, and scheduled start of the data engine.
Automatic start: After the configuration, if the data engine is in the suspended state and a task is submitted to the data engine, the data engine will automatically start.
Manual start: After the configuration, if the data engine is in the suspended state, you need to manually start the data engine before processing data tasks.
Periodic startup: You can configure a weekly periodic startup policy. The system periodically starts the cluster based on the configuration rules.
Suspension policy: Supports the suspension mode of the data engine for charging by volume, including automatic suspension and scheduled suspension. Pay-as-you-go data engines do not incur any costs when suspended.
Automatic suspension: After the configuration, the data engine automatically switches to the suspended state 10 minutes after there is no task, and the triggering time can be configured.
Periodic policy - You can configure weekly periodic start and suspension policies. The system starts and suspends the cluster periodically based on the configuration rules.
Suspend after Completion: If a task is being executed by the data engine within the specified time, the data engine automatically suspends the task within 5 minutes after the task is completed.
Suspend after Automatic pause: If a task is being executed on the data engine within the specified time, the system suspends the task and immediately suspends the data engine.
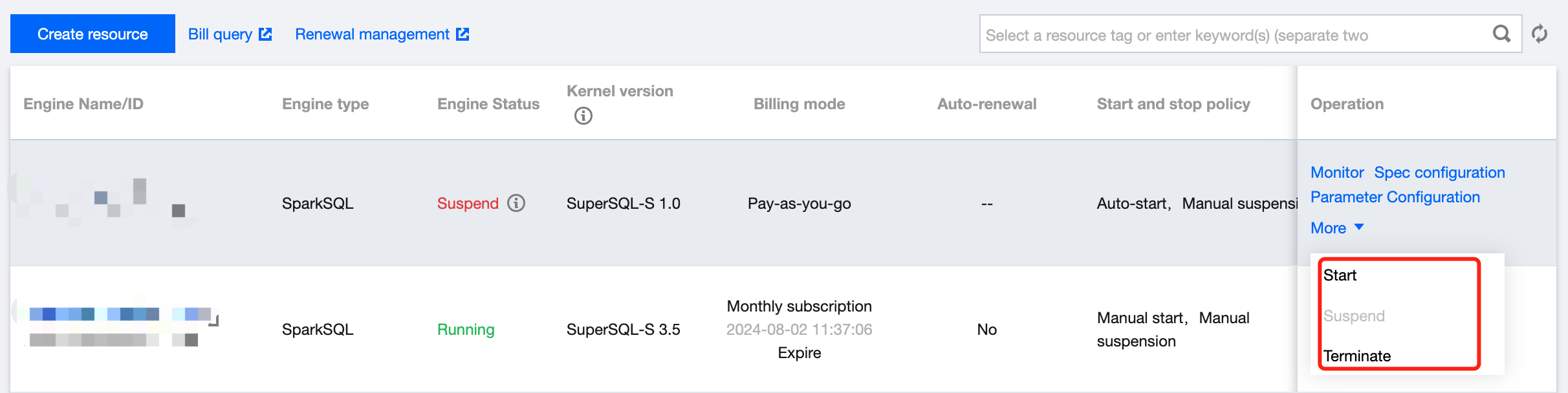
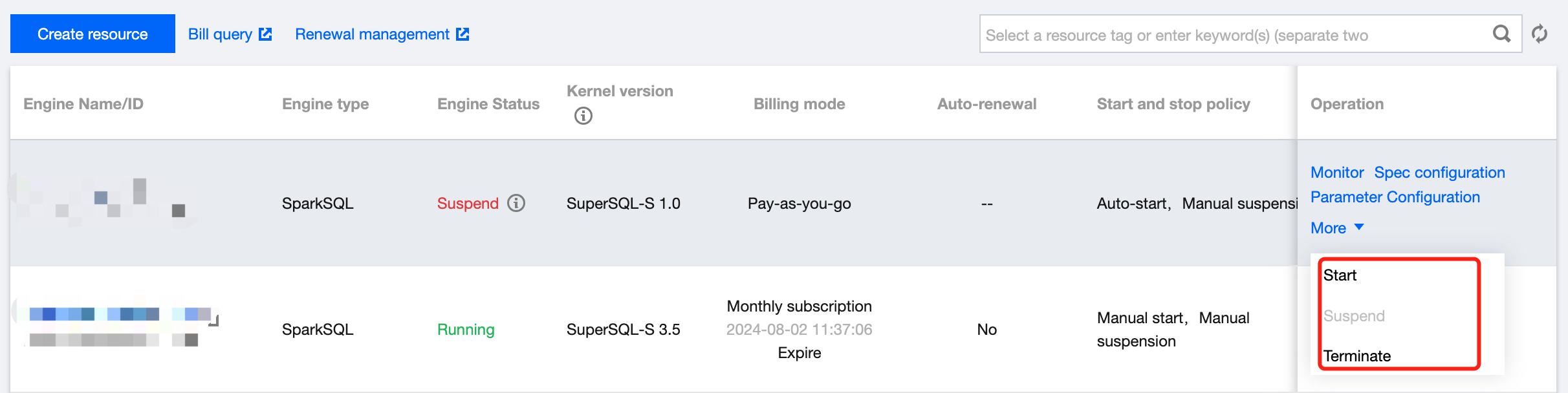
Manually suspending/starting a private engine
Note:
Monthly subscribed resources are resident and cannot be suspended.
1. Log in to the Data Lake Compute console and select the service region. You need to have the Tencent Cloud admin permission.
2. Click Data engine on the left sidebar to enter the data engine management page.
3. Find the target private engine, click More, and select Start or Suspend in the drop-down list.
Terminating a private engine
You can terminate a data engine that is no longer needed. A monthly subscribed data engine will be returned automatically after termination. For more information, see Refund.
Note:
Note that a pay-as-you-go data engine cannot be recovered once terminated. Proceed with caution.
1. Log in to the Data Lake Compute console and select the service region. You need to have the Tencent Cloud admin permission.
2. Click Data engine on the left sidebar to enter the data engine management page.
3. Find the target private engine (only suspended clusters can be terminated), click More, and select Terminate in the drop-down list.
4. Confirm the termination.
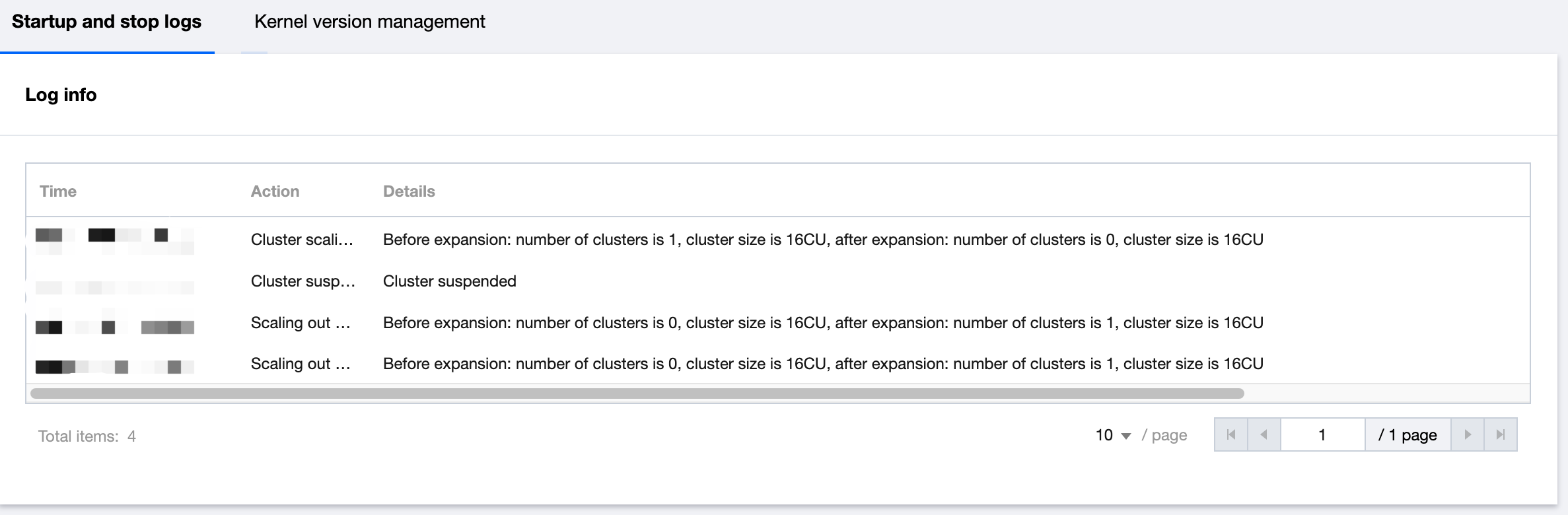
Cluster running logs
Data Lake Compute provides running logs within 14 days for private engines to help you stay informed of the start, suspension, and scaling of clusters. Cluster logs mainly include the following content:
Start time: The time when the cluster starts working.
Suspension time: The time when the cluster stops working.
Scale-out record: The time of the cluster scale-out and the number of added clusters.
Scale-in record: The time of the cluster scale-in and the number of removed clusters.