
DLC Source Table Lake Ingestion Practice

Last updated: 2024-07-31 17:34:58
Use Cases
CDC (Change Data Capture) is an abbreviation for change data capture. It allows incremental changes in the source database to be synchronized in near real-time to other databases or applications. DLC supports using CDC technology to synchronize incremental changes from the source database to native DLC tables, completing the data lake ingestion.
Prerequisites
DLC must be properly enabled, user permissions configured, and managed storage activated.
DLC database must be correctly created.
DLC database data optimization must be properly configured. For detailed configuration, see Enable data optimization.
Ingesting Data into the Lake with InLong
DataInLong can be used to synchronize source data to DLC.
Ingesting Stream Computing Data into the Lake with Oceanus
Source data can be synchronized to DLC via Oceanus.
Ingesting Data into the Lake with Self-Managed Flink
Flink can be used to synchronize source data to DLC. This example demonstrates how to synchronize data from a source Kafka to DLC, completing the data lake ingestion.
Environment Preparation
Required clusters: Kafka 2.4.x, Flink 1.15.x, and Hadoop 3.x.
It is recommended to purchase EMR clusters for Kafka and Flink.
Overall Operation Process
For detailed steps, see the diagram below:

Step 1: Upload Required Jars: Upload the necessary Kafka, DLC connector Jar files, and Hadoop dependency Jars for synchronization.
Step 2: Create Kafka Topic: Create a Kafka topic for production and consumption.
Step 3: Create Target Table in DLC: Create a new target table in DLC data management.
Step 4: Submit Task: Submit the synchronization task in the Flink cluster.
Step 5: Send Message Data and Check Sync Results: Send message data through the Kafka cluster and check the synchronization results on the DLC.
Step 1: Uploading Required Jars
1. Download required Jars.
It is recommended to upload the required Jars that match the version of Flink you are using. For example, if you are using Flink 1.15.x, download the flink-sql-connect-kafka-1.15.x.jar. See the attachments for the relevant files.
Kafka-related dependencies: flink-sql-connect-kafka-1.15.4.jar
DLC-related dependencies: sort-connector-iceberg-dlc-1.6.0.jar
Hadoop 3.x related dependencies: api-util-1.0.0-M20.jar, guava-27.0-jre.jar, hadoop-mapreduce-client-core-3.2.2.jar.
2. Log in to the Flink cluster and upload the prepared Jar files to the flink/ib directory.
Step 2: Creating a Kafka Topic
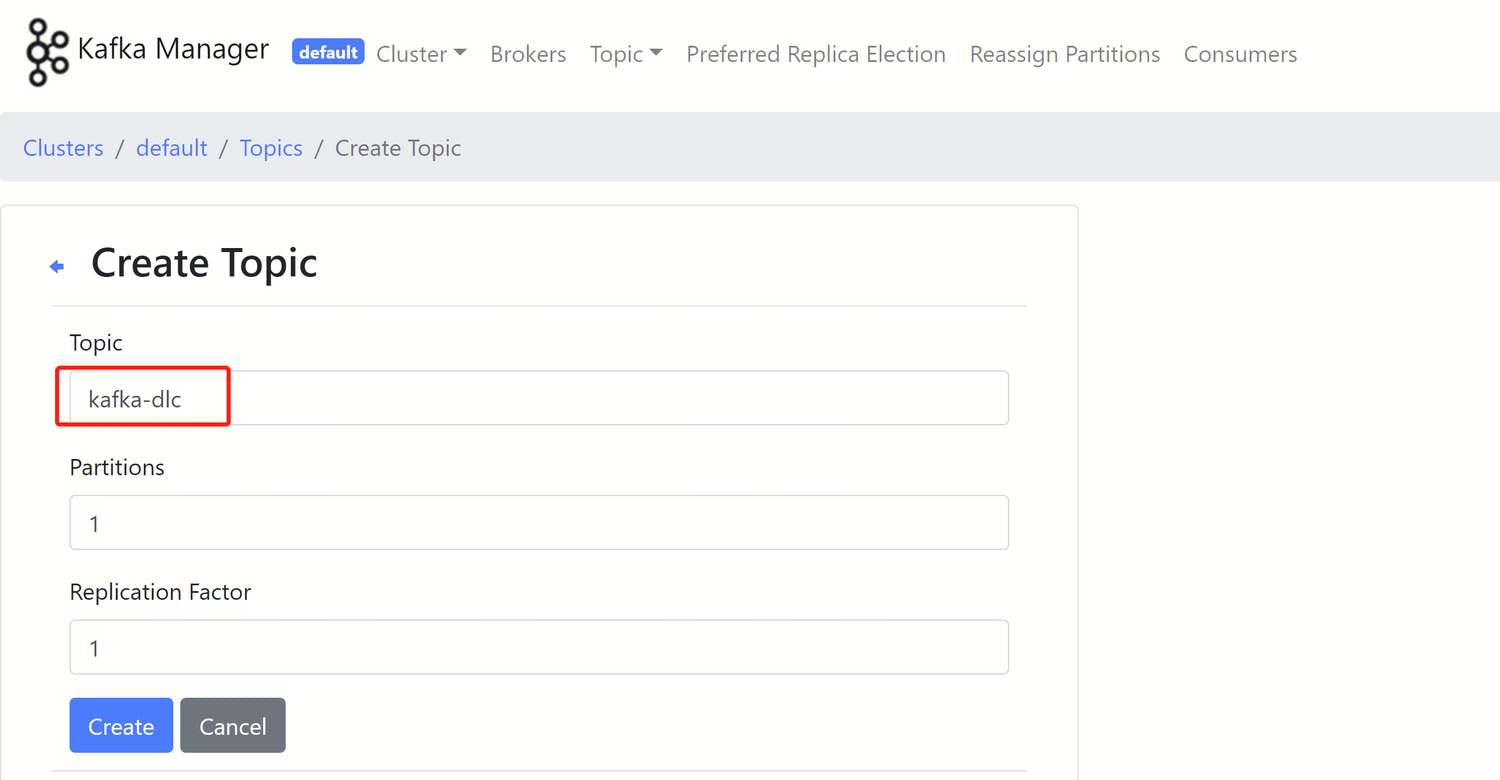
Log in to Kafka Manager, click on default cluster, then click on Topic > Create.
Topic name: For this example, enter kafka_dlc
Number of partitions: 1
Number of replicas: 1
Alternatively, log in to the Kafka cluster instance and use the following command in the kafka/bin directory to create the Topic.
./kafka-topics.sh --bootstrap-server ip:port --create --topic kafka-dlc
Step 3: Creating a New Target Table in DLC
Step 4: Submitting the Task
There are two ways to synchronize data, i.e. using Flink: Flink SQL Write Mode and Flink Stream API. Both synchronization methods will be introduced below.
Before submitting the task, you need to create a directory to save checkpoint data. Use the following command to create the data management.
Create the hdfs /flink/checkpoints directory:
hadoop fs -mkdir /flinkhadoop fs -mkdir /flink/checkpoints
Flink SQL Synchronization Mode
1. Create a new Maven project named "flink-demo" in IntelliJ IDEA.
2. Add the necessary dependencies in pom. For details on the dependencies, see Complete Sample Code Reference > Example 1.
3. Java synchronization code: The core code is shown in the steps below. For detailed code, see Complete Sample Code Reference > Example 2.
Create execution environment and configure checkpoint:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(60000);env.getCheckpointConfig().setCheckpointStorage("hdfs:///flink/checkpoints");env.getCheckpointConfig().setCheckpointTimeout(60000);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
Execute Source SQL:
tEnv.executeSql(sourceSql);
Execute Synchronization SQL:
tEnv.executeSql(sql)
4. Use IntelliJ IDEA to compile and package the flink-demo project. The JAR file flink-demo-1.0-SNAPSHOT.jar will be generated in the project's target folder.
5. Log in to one of the instances in the Flink cluster and upload flink-demo-1.0-SNAPSHOT.jar to the /data/jars/ directory (create the directory if it does not exist).
6. Log in to one of the instances in the Flink cluster and execute the following command in the flink/bin directory to submit the synchronization task.
./flink run --class com.tencent.dlc.iceberg.flink.AppendIceberg /data/jars/flink-demo-1.0-SNAPSHOT.jar
Flink Stream API Synchronization Mode
1. Create a new Maven project named "flink-demo" in IntelliJ IDEA.
2. Add the necessary dependencies in pom: Complete sample code reference > Example 3.
3. Java synchronization code: The core code is shown in the steps below. For detailed code, see Complete sample code reference > Example 4.
Create the execution environment StreamTableEnvironment and configure checkpoint:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(60000);env.getCheckpointConfig().setCheckpointStorage("hdfs:///data/checkpoints");env.getCheckpointConfig().setCheckpointTimeout(60000);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
Get the Kafka input stream:
KafkaToDLC dlcSink = new KafkaToDLC();DataStream<RowData> dataStreamSource = dlcSink.buildInputStream(env);
Configure Sink:
FlinkSink.forRowData(dataStreamSource).table(table).tableLoader(tableLoader).equalityFieldColumns(equalityColumns).metric(params.get(INLONG_METRIC.key()), params.get(INLONG_AUDIT.key())).action(actionsProvider).tableOptions(Configuration.fromMap(options))// It is false by default, which appends data. If it is set to be true, the data will be overwritten..overwrite(false).append();
Execute Synchronization SQL:
env.execute("DataStream Api Write Data To Iceberg");
4. Use IntelliJ IDEA to compile and package the flink-demo project. The JAR packet, flink-demo-1.0-SNAPSHOT.jar, will be generated in the project's target folder.
5. Log in to one of the instances in the Flink cluster and upload flink-demo-1.0-SNAPSHOT.jar to the /data/jars/ directory (create the directory if it does not exist).
6. Log in to one of the instances in the Flink cluster and execute the following command in the flink/bin directory to submit the task.
./flink run --class com.tencent.dlc.iceberg.flink.AppendIceberg /data/jars/flink-demo-1.0-SNAPSHOT.jar
Step 5: Send Message Data and Query Synchronization Results
1. Log in to the Kafka cluster instance, navigate to the kafka/bin directory, and use the following command to send message data.
./kafka-console-producer.sh --broker-list 122.152.227.141:9092 --topic kafka-dlc
The data information is as follows:
{"id":1,"name":"Zhangsan","age":18}{"id":2,"name":"Lisi","age":19}{"id":3,"name":"Wangwu","age":20}{"id":4,"name":"Lily","age":21}{"id":5,"name":"Lucy","age":22}{"id":6,"name":"Huahua","age":23}{"id":7,"name":"Wawa","age":24}{"id":8,"name":"Mei","age":25}{"id":9,"name":"Joi","age":26}{"id":10,"name":"Qi","age":27}{"id":11,"name":"Ky","age":28}{"id":12,"name":"Mark","age":29}
2. Query synchronization results
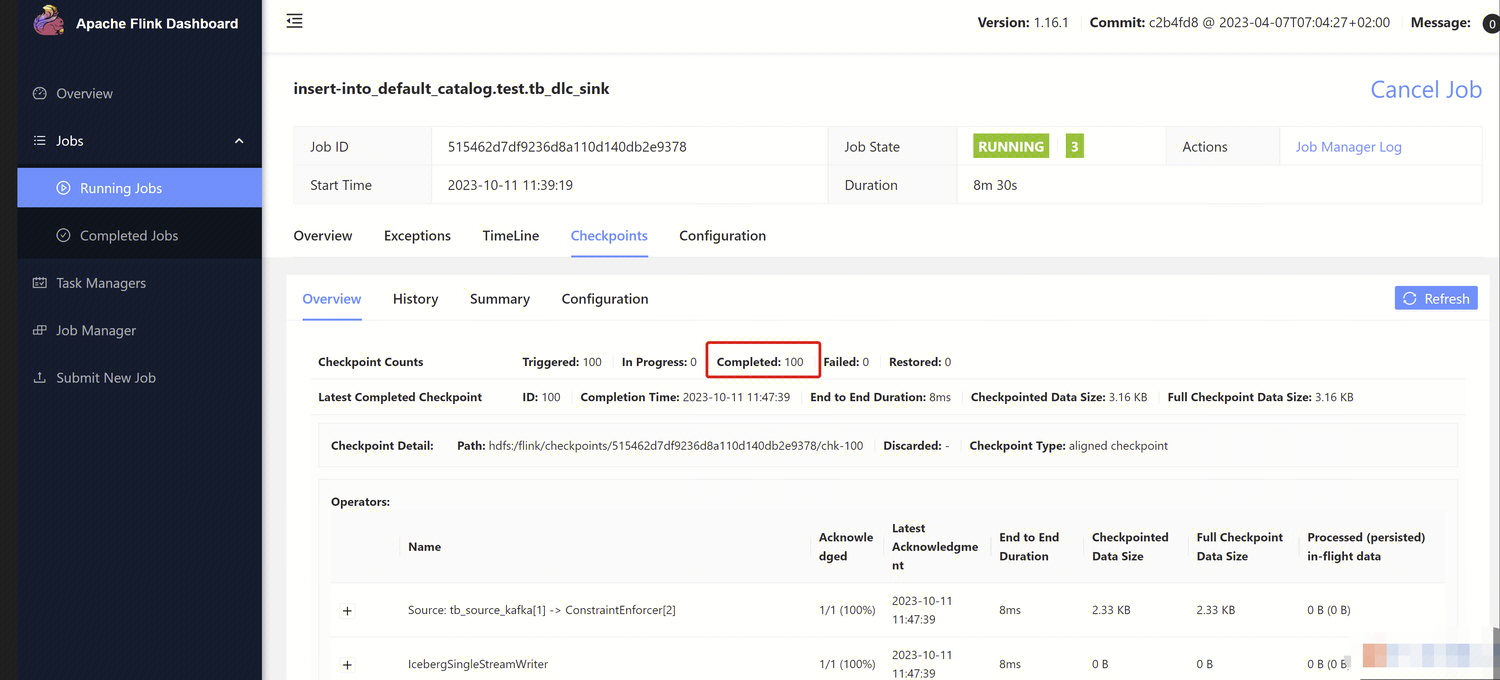
Open the Flink Dashboard, and click on Running Job > Run Job > Checkpoint > Overview to view the Job synchronization results.
3. Log in to the DLC Console, click on Data Exploration to query the target table data.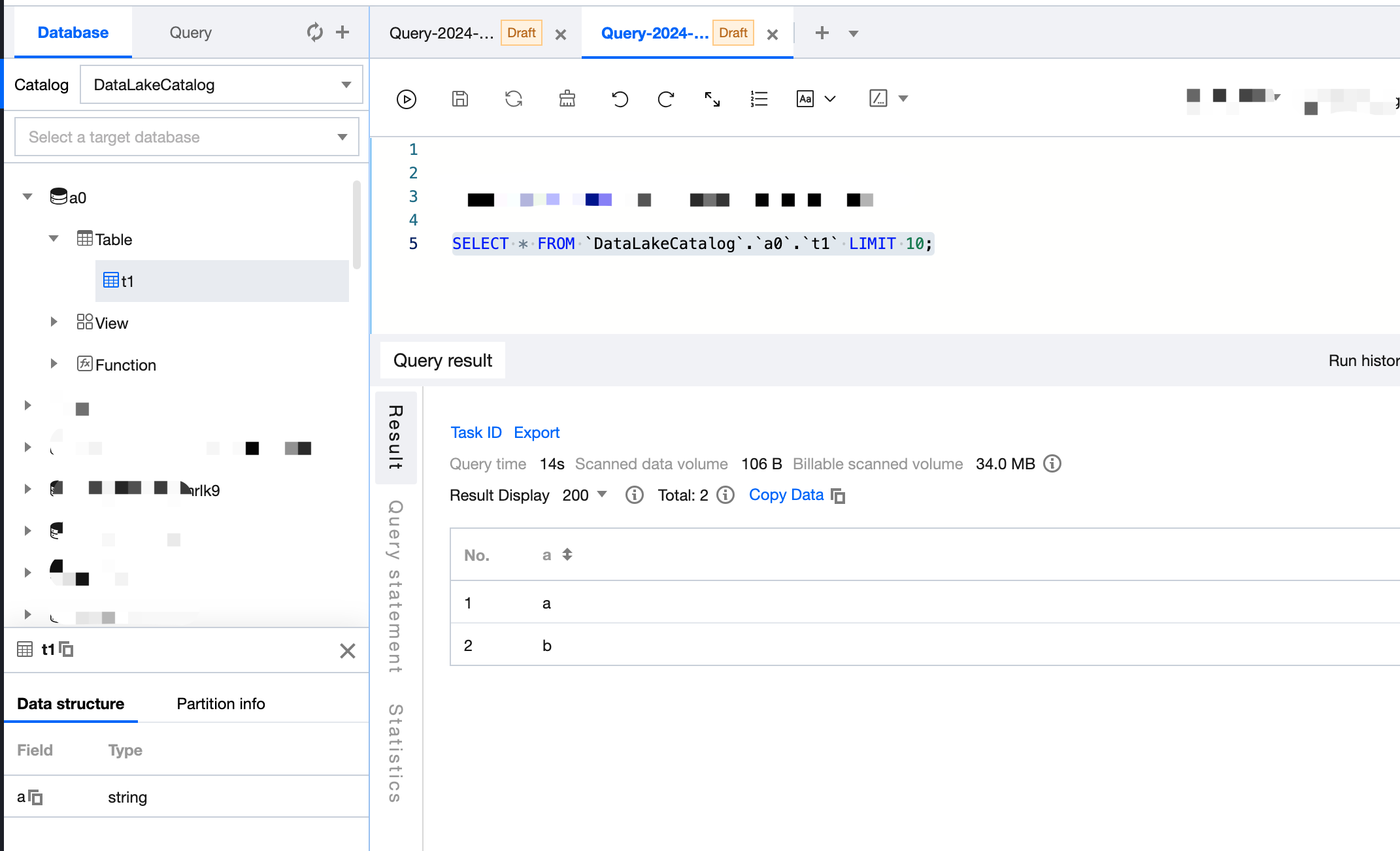
Complete Sample Code Reference Example
Note:
Data marked with “****” in the examples should be replaced with actual data used during development.
Example 1
<properties><flink.version>1.15.4</flink.version><cos.lakefs.plugin.version>1.0</cos.lakefs.plugin.version></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>com.qcloud.cos</groupId><artifactId>lakefs-cloud-plugin</artifactId><version>${cos.lakefs.plugin.version}</version><exclusions><exclusion><groupId>com.tencentcloudapi</groupId><artifactId>tencentcloud-sdk-java</artifactId></exclusion></exclusions></dependency></dependencies>
Example 2
public class AppendIceberg {public static void main(String[] args) {// Create execution environment and configure the checkpointStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(60000);env.getCheckpointConfig().setCheckpointStorage("hdfs:///flink/checkpoints");env.getCheckpointConfig().setCheckpointTimeout(60000);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);// Create the input tableString sourceSql = "CREATE TABLE tb_kafka_sr ( \\n"+ " id INT, \\n"+ " name STRING, \\n"+ " age INT \\n"+ ") WITH ( \\n"+ " 'connector' = 'kafka', \\n"+ " 'topic' = 'kafka_dlc', \\n"+ " 'properties.bootstrap.servers' = '10.0.126.***:9092', \\n" // kafka connection ip and port+ " 'properties.group.id' = 'test-group', \\n"+ " 'scan.startup.mode' = 'earliest-offset', \\n" // start from the earliest offset+ " 'format' = 'json' \\n"+ ");";tEnv.executeSql(sourceSql);// Create the output tableString sinkSql = "CREATE TABLE tb_dlc_sk ( \\n"+ " id INT PRIMARY KEY NOT ENFORCED, \\n"+ " name STRING,\\n"+ " age INT\\n"+ ") WITH (\\n"+ " 'qcloud.dlc.managed.account.uid' = '1000***79117',\\n" //User Uid+ " 'qcloud.dlc.secret-id' = 'AKIDwjQvBHCsKYXL3***pMdkeMsBH8lAJEt',\\n" // User SecretId+ " 'qcloud.dlc.region' = 'ap-***',\\n" // Database and table region information+ " 'qcloud.dlc.user.appid' = 'AKIDwjQvBHCsKYXL3***pMdkeMsBH8lAJEt',\\n" // User SecretId+ " 'qcloud.dlc.secret-key' = 'kFWYQ5WklaCYgbLtD***cyAD7sUyNiVP',\\n" // User SecretKey+ " 'connector' = 'iceberg-inlong', \\n"+ " 'catalog-database' = 'test_***', \\n" // Target database+ " 'catalog-table' = 'kafka_dlc', \\n" // Target data table+ " 'default-database' = 'test_***', \\n" //Default database+ " 'catalog-name' = 'HYBRIS', \\n"+ " 'catalog-impl' = 'org.apache.inlong.sort.iceberg.catalog.hybris.DlcWrappedHybrisCatalog', \\n"+ " 'uri' = 'dlc.tencentcloudapi.com', \\n"+ " 'fs.cosn.credentials.provider' = 'org.apache.hadoop.fs.auth.DlcCloudCredentialsProvider', \\n"+ " 'qcloud.dlc.endpoint' = 'dlc.tencentcloudapi.com', \\n"+ " 'fs.lakefs.impl' = 'org.apache.hadoop.fs.CosFileSystem', \\n"+ " 'fs.cosn.impl' = 'org.apache.hadoop.fs.CosFileSystem', \\n"+ " 'fs.cosn.userinfo.region' = 'ap-guangzhou', \\n" // Region information for the COS in use+ " 'fs.cosn.userinfo.secretId' = 'AKIDwjQvBHCsKYXL3***pMdkeMsBH8lAJEt', \\n" // User SecretId+ " 'fs.cosn.userinfo.secretKey' = 'kFWYQ5WklaCYgbLtD***cyAD7sUyNiVP', \\n" // User SecretKey+ " 'service.endpoint' = 'dlc.tencentcloudapi.com', \\n"+ " 'service.secret.id' = 'AKIDwjQvBHCsKYXL3***pMdkeMsBH8lAJEt', \\n" // User SecretId+ " 'service.secret.key' = 'kFWYQ5WklaCYgbLtD***cyAD7sUyNiVP', \\n" // User SecretKey+ " 'service.region' = 'ap-***', \\n" // Database and table region information+ " 'user.appid' = '1305424723', \\n"+ " 'request.identity.token' = '1000***79117', \\n"+ " 'qcloud.dlc.jdbc.url'='jdbc:dlc:dlc.internal.tencentcloudapi.com?task_type=SparkSQLTask&database_name=test_***&datasource_connection_name=DataLakeCatalog®ion=ap-***&data_engine_name=flink-***' \\n"+ ");";tEnv.executeSql(sinkSql);// Execute computation and output resultsString sql = "insert into tb_dlc_sk select * from tb_kafka_sr";tEnv.executeSql(sql);}}
Example 3
<properties><flink.version>1.15.4</flink.version></properties><dependencies><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.22</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.inlong</groupId><artifactId>sort-connector-iceberg-dlc</artifactId><version>1.6.0</version><scope>system</scope><systemPath>${project.basedir}/lib/sort-connector-iceberg-dlc-1.6.0.jar</systemPath></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>${kafka-version}</version><scope>provided</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.25</version></dependency></dependencies>
Example 4
public class KafkaToDLC {public static void main(String[] args) throws Exception {final MultipleParameterTool params = MultipleParameterTool.fromArgs(args);final Map<String, String> options = setOptions();//1. Create the execution environment StreamTableEnvironment and configure the checkpointStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(60000);env.getCheckpointConfig().setCheckpointStorage("hdfs:///data/checkpoints");env.getCheckpointConfig().setCheckpointTimeout(60000);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);env.getConfig().setGlobalJobParameters(params);//2. Get input streamKafkaToDLC dlcSink = new KafkaToDLC();DataStream<RowData> dataStreamSource = dlcSink.buildInputStream(env);//3. Create Hadoop configuration and Catalog configurationCatalogLoader catalogLoader = FlinkDynamicTableFactory.createCatalogLoader(options);TableLoader tableLoader = TableLoader.fromCatalog(catalogLoader,TableIdentifier.of(params.get(CATALOG_DATABASE.key()), params.get(CATALOG_TABLE.key())));tableLoader.open();Table table = tableLoader.loadTable();ActionsProvider actionsProvider = FlinkDynamicTableFactory.createActionLoader(Thread.currentThread().getContextClassLoader(), options);//4. Create SchemaSchema schema = Schema.newBuilder().column("id", DataTypeUtils.toInternalDataType(new IntType(false))).column("name", DataTypeUtils.toInternalDataType(new VarCharType())).column("age", DataTypeUtils.toInternalDataType(new DateType(false))).primaryKey("id").build();List<String> equalityColumns = schema.getPrimaryKey().get().getColumnNames();//5. Configure SlinkFlinkSink.forRowData(dataStreamSource)//This .table can be omitted; just specify the corresponding path for the tableLoader..table(table).tableLoader(tableLoader).equalityFieldColumns(equalityColumns).metric(params.get(INLONG_METRIC.key()), params.get(INLONG_AUDIT.key())).action(actionsProvider).tableOptions(Configuration.fromMap(options))//It is false by default, which appends data. If it is set to be true, the data will be overwritten..overwrite(false).append();//6. Execute synchronizationenv.execute("DataStream Api Write Data To Iceberg");}private static Map<String, String> setOptions() {Map<String, String> options = new HashMap<>();options.put("qcloud.dlc.managed.account.uid", "1000***79117"); //User Uidoptions.put("qcloud.dlc.secret-id", "AKIDwjQvBHCsKYXL3***pMdkeMsBH8lAJEt"); // User SecretIdoptions.put("qcloud.dlc.region", "ap-***"); // Database and table region informationoptions.put("qcloud.dlc.user.appid", "AKIDwjQvBHCsKYXL3***pMdkeMsBH8lAJEt"); // User SecretIdoptions.put("qcloud.dlc.secret-key", "kFWYQ5WklaCYgbLtD***cyAD7sUyNiVP"); // User SecretKeyoptions.put("connector", "iceberg-inlong");options.put("catalog-database", "test_***"); // Target databaseoptions.put("catalog-table", "kafka_dlc"); // Target data table> options.put("default-database", "test_***"); //Default databaseoptions.put("catalog-name", "HYBRIS");options.put("catalog-impl", "org.apache.inlong.sort.iceberg.catalog.hybris.DlcWrappedHybrisCatalog");options.put("uri", "dlc.tencentcloudapi.com");options.put("fs.cosn.credentials.provider", "org.apache.hadoop.fs.auth.DlcCloudCredentialsProvider");options.put("qcloud.dlc.endpoint", "dlc.tencentcloudapi.com");options.put("fs.lakefs.impl", "org.apache.hadoop.fs.CosFileSystem");options.put("fs.cosn.impl", "org.apache.hadoop.fs.CosFileSystem");options.put("fs.cosn.userinfo.region", "ap-guangzhou"); // Region information for the COS in useoptions.put("fs.cosn.userinfo.secretId", "AKIDwjQvBHCsKYXL3***pMdkeMsBH8lAJEt"); // User SecretIdoptions.put("fs.cosn.userinfo.secretKey", "kFWYQ5WklaCYgbLtD***cyAD7sUyNiVP"); // User SecretKeyoptions.put("service.endpoint", "dlc.tencentcloudapi.com");options.put("service.secret.id", "AKIDwjQvBHCsKYXL3***pMdkeMsBH8lAJEt"); // User SecretIdoptions.put("service.secret.key", "kFWYQ5WklaCYgbLtD***cyAD7sUyNiVP"); // User SecretKeyoptions.put("service.region", "ap-***"); // Database and table region informationoptions.put("user.appid", "1305***23");options.put("request.identity.token", "1000***79117");options.put("qcloud.dlc.jdbc.url","jdbc:dlc:dlc.internal.tencentcloudapi.com?task_type,SparkSQLTask&database_name,test_***&datasource_connection_name,DataLakeCatalog®ion,ap-***&data_engine_name,flink-***");return options;}/*** Create the input stream** @param env* @return*/private DataStream<RowData> buildInputStream(StreamExecutionEnvironment env) {//1. Configure the execution environmentEnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();StreamTableEnvironment sTableEnv = StreamTableEnvironment.create(env, settings);org.apache.flink.table.api.Table table = null;//2. Execute SQL to get the data input streamtry {sTableEnv.executeSql(createTableSql()).print();table = sTableEnv.sqlQuery(transformSql());DataStream<Row> rowStream = sTableEnv.toChangelogStream(table);DataStream<RowData> rowDataDataStream = rowStream.map(new MapFunction<Row, RowData>() {@Overridepublic RowData map(Row rows) throws Exception {GenericRowData rowData = new GenericRowData(3);rowData.setField(0, rows.getField(0));rowData.setField(1, (String) rows.getField(1));rowData.setField(2, rows.getField(2));return rowData;}});return rowDataDataStream;} catch (Exception e) {throw new RuntimeException("kafka to dlc transform sql execute error.", e);}}private String createTableSql() {String tableSql = "CREATE TABLE tb_kafka_sr ( \\n"+ " id INT, \\n"+ " name STRING, \\n"+ " age INT \\n"+ ") WITH ( \\n"+ " 'connector' = 'kafka', \\n"+ " 'topic' = 'kafka_dlc', \\n"+ " 'properties.bootstrap.servers' = '10.0.126.30:9092', \\n"+ " 'properties.group.id' = 'test-group-10001', \\n"+ " 'scan.startup.mode' = 'earliest-offset', \\n"+ " 'format' = 'json' \\n"+ ");";return tableSql;}private String transformSql() {String transformSQL = "select * from tb_kafka_sr";return transformSQL;}}
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No
Feedback