Data Lake Compute
- Getting Started
- Operation Guide
- Console Operation Introduction
- Data Development and Exploration
- Data Exploration
- Data Query Task
- Resource Management
- Engine Management
- SuperSQL Engine
- Standard Engine
- Resource Group
- Private Connection
- Storage Configuration
- Ops Management
- Insight Management
- System Management
- User and Permission Management
- Monitoring and Alarms
- Development Guide
- System Restraints
- Client Access
- JDBC Access
- Practical Tutorial
- SQL Statement
- SuperSQL Statement
- Unified Statement
- DDL Statement
- ALTER TABLE
- DML Statement
- DQL Statement
- Iceberg Table Statement
- API Documentation
- Making API Requests
- Data Table APIs
- Task APIs
- Metadata APIs
- Service Configuration APIs
- Permission Management APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- General Reference
- Operation Guide on Connecting Third-Party Software to DLC

DLC Source Table Core Capabilities

Last updated: 2024-07-31 17:34:28
Overview
The DLC Native Table (Iceberg) is a user-friendly table format with high performance based on the Iceberg lake format. It simplifies operations, making it easy for users to perform comprehensive data exploration and build applications like Lakehouse. When using DLC Native Table (Iceberg) for the first time, users should follow these five main steps:
1. Enable DLC managed storage.
2. Purchase the engine.
3. Create the database and table. Choose to create either an append or upsert table based on your use case, and include optimization parameters.
4. Configure data optimization. Select a dedicated optimization engine and configure optimization options based on the table type.
5. Import data into the DLC Native Table. DLC supports various data writing methods, such as insert into, merge into, and upsert, as well as multiple import methods, including Spark, Presto, Flink, InLong, and Oceanus.
Iceberg Principle Parsing
The DLC Native Table (Iceberg) uses the Iceberg table format for its underlying storage. In addition to being compatible with the open-source Iceberg capabilities, it enhances performance through separation of storage and computation and improves usability.
The Iceberg table format manages user data by dividing it into data files and metadata files.
Data layer: It consists of a series of data files that store user table data. These data files support Parquet, Avro, and ORC formats, with Parquet being the default format in DLC.
Due to Iceberg's snapshot mechanism, data is not immediately deleted from storage when a user deletes it. Instead, a new delete file is written to record the deleted data. Depending on the use case, delete files are categorized into position delete files and equality delete files.
Position delete files record the information of specific rows that have been deleted within a data file.
Equality delete files record the deletion of specific key values and are typically used in upsert scenarios. Delete file is also a type of data file.
Metadata layer: It consists of a series of manifest files, manifest lists, and metadata files. Manifest files contain metadata for a series of data files, such as file paths, write times, min-max values, and statistics.
A manifest list is composed of manifest files, typically containing the manifest files for a single snapshot.
Metadata files are in JSON format and contain information about a series of manifest list files as well as table metadata, such as table schema, partitions, and all snapshots. Whenever the table status changes, a new metadata file is generated to replace the existing one, with the Iceberg kernel ensuring atomicity for this process.
Use Cases for Native Tables
DLC Native Table (Iceberg) is the recommended format for DLC Lakehouse. It supports two main use cases: Append tables and Upsert tables. Append tables use the V1 format, while Upsert tables use the V2 format.
Append tables: These tables support only Append, Overwrite, and Merge Into write modes.
Upsert tables: Compared to Append tables, these tables also support the Upsert write mode.
The use cases and characteristics of native tables are described in the table below.
Table Type | Use Cases and Recommendations | Characteristics |
Native Table (Iceberg) | 1. Users have needs for scenarios requiring real-time data writing, including append, merge into, and upsert operations. It is not limited to real-time writing using InLong, Oceanus, or self-managed Flink setups. 2. Storage-related Ops that users do not want to manage directly can be left to DLC managed storage. 3. When users prefer do not want to handle the Ops of the Iceberg table format themselves, they can let DLC manage optimization and Ops. 4. Users who want to leverage DLC's automatic data optimization capabilities can continuously optimize data. | 1. Iceberg table format. 2. Managed storage must be enabled before use. 3. Data is stored in DLC's managed storage. 4. There is no need to specify external or location information. 5. Enabling DLC intelligent data optimization is supported. |
For better management and use of DLC Native Table (Iceberg), certain attributes need to be specified when you create this type of table. The attributes are as follows. Users can specify these attribute values when creating a table or modify the table's attribute values later. For detailed instructions, see DLC Native Table Operational Configuration.
Attribute Values | Meaning | Configuration Guide |
format-version | Iceberg table version: Valid values are 1 and 2, with a default of 1. | If the user's write scenario includes upsert, this value must be set to 2. |
write.upsert.enabled | Whether to enable upsert: The value is true; if not set, it will not be enabled. | If the user's write scenario includes upsert, this must be set to true. |
write.update.mode | Update Mode | Set to merge-on-read (MOR) for MOR tables; the default is copy-on-write (COW). |
write.merge.mode | Merge Mode | Set to merge-on-read (MOR) for MOR tables; the default is copy-on-write (COW). |
write.parquet.bloom-filter-enabled.column.{col} | Enable bloom: Set to true to enable it; it is disabled by default. | In upsert scenarios, this must be enabled and configured according to the primary keys from the upstream data. If there are multiple primary keys in the upstream, use up to the first two. Enabling this can improve MOR query performance and small file merging efficiency. |
write.distribution-mode | Write Mode | The recommended value is hash. When the value is hash, data will be automatically repartitioned upon writing. However, the drawback is that this may impact write performance. |
write.metadata.delete-after-commit.enabled | Enable automatic metadata file cleanup. | It is strongly recommended to set this to true. With this setting enabled, old metadata files will be automatically cleaned up during snapshot creation to prevent the buildup of excess metadata files. |
write.metadata.previous-versions-max | Set the default quantity of retained metadata files. | The default value is 100. In certain special cases, users can adjust this value as needed. This setting should be used with write.metadata.delete-after-commit.enabled. |
write.metadata.metrics.default | Set the column metrics mode. | The value must be set to full. |
Core Capabilities of Native Tables
Managed Storage
DLC Native Table (Iceberg) uses a managed data storage mode. When using native tables (Iceberg), users must first enable managed storage and import data into the storage space managed by DLC. By using DLC managed storage, users will gain the following benefits.
Enhanced Data Security: Iceberg table data is divided into metadata and data files. If any of these files are damaged, it can cause exceptions for querying the entire table (unlike Hive, where only the corrupted file's data may be inaccessible). Storing data in DLC can help prevent users from accidentally damaging files due to a lack of understanding of Iceberg.
Performance: DLC managed storage uses CHDFS by default and offers significantly better performance compared to standard COS.
Reduced Storage Ops: By using managed storage, users no longer need to set up and maintain Cloud Object Storage themselves, and this can reduce the Ops burden associated with storage.
Data Optimization: With the managed storage mode of DLC Native Table (Iceberg), DLC provides continuous optimization for the native tables.
ACID Transactions
Writing of Iceberg allows deleting and inserting within a single operation and is not partially visible to users so that it can offer atomic write operations.
Iceberg uses optimistic concurrency control to ensure that data writes do not cause inconsistencies. Users can only see data that has been successfully committed in the read view.
Iceberg uses snapshot mechanisms and serializable isolation levels to ensure that reads and writes are isolated.
Iceberg ensures that transactions are durable; once a transaction is successfully committed, it is permanent.
Writing
The writing process follows optimistic concurrency control. Writers assume that the current table version will not change before they commit their updates. They update, delete, or add data and create a new version of the metadata file. When the current version is replaced with the new version, Iceberg verifies that the updates are based on the current snapshot.
If not, it indicates a write conflict, meaning that another writer has already updated the current metadata. In this case, the write operation must be updated again based on the current metadata version. The entire submission and replacement process is ensured to be atomic by the metadata lock.
Reading
Reading and writing of Iceberg are independent processes. Readers can only see snapshots that have been successfully committed. By accessing the version's metadata file, readers obtain snapshot information to read the current table data. Since metadata files are not updated until write operations are complete, this ensures that data is always read from completed operations and never from ongoing write operations.
Conflict Parameter Configuration
When write concurrency increases, DLC managed tables (Iceberg) may encounter write conflicts. To reduce the frequency of conflicts, users can make reasonable adjustments to their businesses in the following ways.
Go to the setting of the table structure for merging, such as partitioning, to reasonably plan the write scope of jobs. This reduces the write time of tasks and, to some extent, lowers the probability of concurrent conflicts.
Merge jobs to a certain extent to reduce the level of write concurrency.
DLC also supports a series of conflict retry parameters and increases the success rate of retry operations to some extent, thereby reducing the impact on business operations. The meanings of parameters and configuration guidance are as follows.
Attribute values | Default System values | Meanings | Configuration guide |
commit.retry.num-retries | 4 | Number of retries after a submission failure | When retries occur, you can try increasing the number of attempts. |
commit.retry.min-wait-ms | 100 | Minimum time for waiting before retrying, in milliseconds | If conflicts are very frequent and persist even after waiting for a while, you can try to adjust this value to increase the interval between retries. |
commit.retry.max-wait-ms | 60000(1 min) | Maximum time for waiting before retrying, in milliseconds | Adjust this value with commit.retry.min-wait-ms. |
commit.retry.total-timeout-ms | 1800000(30 min) | Timeout for the process of submitting the entire retry | - |
Hidden Partitioning
DLC Native Table (Iceberg) hidden partitioning hides the partition information. Developers only need to specify the partition policy when creating the table. Iceberg maintains the logical relationship between table fields and data files according to this policy. During writing and querying, there is no need to be concerned about the partition layout. Iceberg finds the partition information based on the partitioning policy and records it in the metadata during data writing. When querying, it uses the metadata to filter out files that do not need to be scanned. The partition policies provided by DLC Native Table (Iceberg) are shown in the table below.
Transformation policy | Description | Types of original fields | Types after transformation |
identity | No transformation | All types | Being consistent with the original type |
bucket[ N, col] | Hash bucketing | int, long, decimal, date, time, timestamp, timestamptz, string, uuid, fixed, binary | int |
truncate[ col] | Fixed-length truncation | int, long, decimal, string | Being consistent with the original type |
year | Extract year information from fields | date, timestamp, timestamptz | int |
month | Extract month information from fields | date, timestamp, timestamptz | int |
day | Extract day information from fields | date, timestamp, timestamptz | int |
hour | Extract hour information from fields | timestamp, timestamptz | int |
Process of Querying and Storing Metadata
DLC Native Table (Iceberg) allows you to call stored procedure statements to query information about various types of tables, such as file merges and snapshot expiration. The table below provides some common query methods.
Scenes | CALL statements | Execution engine |
Querying history | select * from DataLakeCatalog.db.sample$history | DLC spark SQL engine, presto engine |
Querying snapshot | select * from DataLakeCatalog.db.sample$snapshots | DLC spark SQL engine, presto engine |
Querying data files | select * from DataLakeCatalog.db.sample$files | DLC spark SQL engine, presto engine |
Querying manifests | select * from DataLakeCatalog.db.sample$manifests | DLC spark SQL engine, presto engine |
Querying partitions | select * from DataLakeCatalog.db.sample$partitions | DLC spark SQL engine, presto engine |
Rollback of the specific snapshot | CALL DataLakeCatalog. system.rollback_to_snapshot('db.sample', 1) | DLC spark SQL engine |
Rolling back to a specific point in time | CALL DataLakeCatalog. system.rollback_to_timestamp('db.sample', TIMESTAMP '2021-06-30 00:00:00.000') | DLC spark SQL engine |
Setting the current snapshot | CALL DataLakeCatalog. system.set_current_snapshot('db.sample', 1) | DLC spark SQL engine |
Merging files | CALL DataLakeCatalog. system.rewrite_data_files(table => 'db.sample', strategy => 'sort', sort_order => 'id DESC NULLS LAST,name ASC NULLS FIRST') | DLC spark SQL engine |
Expiration of snapshots | CALL DataLakeCatalog. system.expire_snapshots('db.sample', TIMESTAMP '2021-06-30 00:00:00.000', 100) | DLC spark SQL engine |
Removing orphan files | CALL DataLakeCatalog. system.remove_orphan_files(table => 'db.sample', dry_run => true) | DLC spark SQL engine |
Ewriting metadata | CALL DataLakeCatalog. system.rewrite_manifests('db.sample') | DLC spark SQL engine |
Data Optimization
Optimization Policies
DLC Native Table (Iceberg) provides optimization policies with inheritance capabilities, allowing users to configure these policies on the data management, database, and data table. For detailed configuration instructions, see Enable Data Optimization.
Policy for Optimizing the Configuration of the Data Management: All native tables (Iceberg) in all databases under this data management will by default inherit and use the policy for optimizing the configuration of the data management.
Policy for Optimizing the Configuration of the Database: All native tables (Iceberg) within this database will by default inherit and use the policy for optimizing the configuration of the database.
Policy for Optimizing the Configuration of the Data Table: This configuration only applies to the specified native table (Iceberg).
By using the above combination of configurations, users can implement customized optimization policies for specific databases and tables or policies for disabling certain tables.
DLC also provides advanced parameter configurations for optimization policies. If users are familiar with Iceberg, they can customize advanced parameters based on their specific scenarios, as shown in the figure below.
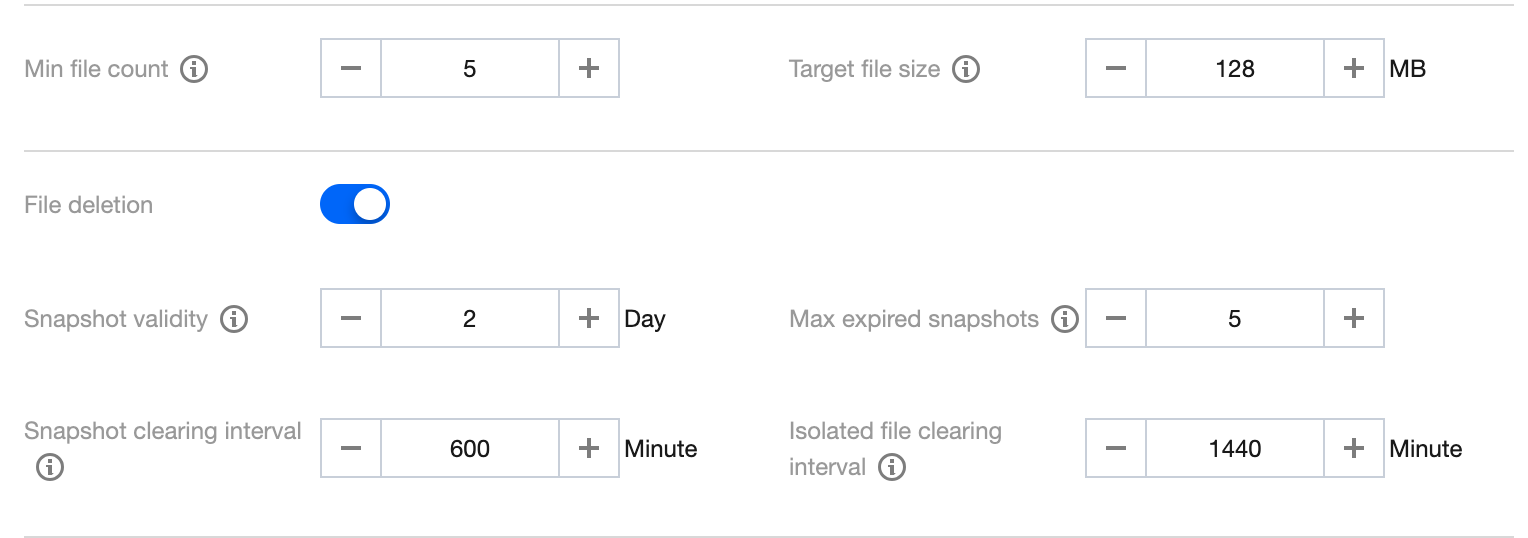
DLC has set default values for advanced parameters. DLC will try to merge files to a size of 128 MB. The snapshot expiration time is 2 days. Five expired snapshots will be saved, and the snapshot expiration and orphan file cleanup tasks run every 600 minutes and 1440 minutes respectively.
For upsert write scenarios, DLC also provides default merge thresholds. These parameters are managed by DLC, and small file merging is triggered if new data written within a span of over 5 minutes meets any of the specified conditions, as shown in the table.
Parameter | Meaning | Value |
AddDataFileSize | Number of newly written data files | 20 |
AddDeleteFileSize | Amount of newly written Delete file data | 20 |
AddPositionDeletes | Number of newly written Position Delete records | 1000 |
AddEqualityDeletes | Number of newly written Equality Delete records | 1000 |
Optimization Engine
DLC data optimization is performed by executing stored procedures, so a data engine is required to run these procedures. Currently, DLC supports using the Spark SQL engine as the optimization engine. When it is being used, please note the following points:
The Spark SQL engine for data optimization should be used separately from the business engine, and this can prevent data optimization tasks and business tasks from competing for resources and leading to significant queuing and business disruptions.
For production scenarios, it is recommended to allocate at least 64 CU for optimization resources. For special tables with fewer than 10 tables and individual table data exceeding 2 GB, it is advised to enable auto scaling of resources to handle sudden traffic spikes. Additionally, using a monthly subscription cluster is recommended to prevent optimization task failures due to unavailability of clusters when tasks are submitted.
Parameter Definitions
Settings for optimizing parameters for databases and tables are on their database and table attributes. Users can specify these data optimization parameters when creating databases and tables (DLC Native Table provides a visual interface for configuring data optimization during creation). Additionally, users can modify data optimization parameters using the ALTER DATABASE/TABLE commands. For detailed instructions, see DLC Native Table Operation Configuration..
Attribute value | Meaning | Default value | Value Description |
smart-optimizer.inherit | Whether to inherit the upper level policy | default | none: Do not inherit it; default: Inherit it |
smart-optimizer.written.enable | Whether to enable write optimization | disable | disable: No; enable: Yes. It is not enabled by default. |
smart-optimizer.written.advance.compact-enable | (Optional) Advanced write optimization parameter: whether to enable small file merging | enable | disable: No; enable: Yes. |
smart-optimizer.written.advance.delete-enable | (Optional) Advanced write optimization parameter: whether to enable data cleanup | enable | disable: No; enable: Yes. |
smart-optimizer.written.advance.min-input-files | (Optional) Minimum number of files for merging | 5 | When the number of files under a table or partition exceeds this minimum number, the platform will automatically check them and start file optimization merging. File optimization merge can significantly improve analysis and query performance. A larger minimum file number increases resource load, while a smaller one allows for more flexible execution and more frequent tasks. A value of 5 is recommended. |
smart-optimizer.written.advance.target-file-size-bytes | (Optional) Target size after merging | 134217728 (128 MB) | During file optimization merging, files will be merged to this target size as much as possible. The recommended value is 128 MB. |
smart-optimizer.written.advance.before-days | (Optional) Snapshot expiration time (in days) | 2 | When the existence time of a snapshot exceeds this value, the platform will mark the snapshot as expired. The longer the snapshot expiration time, the slower the snapshot cleanup and more storage space will be occupied. |
smart-optimizer.written.advance.retain-last | (Optional) Quantity of expired snapshots to retain | 5 | If the number of expired snapshots is bigger than that of those to be saved, the redundant expired snapshots will be cleaned up. The more expired snapshots are saved, the more storage space is used. A value of 5 is recommended. |
smart-optimizer.written.advance.expired-snapshots-interval-min | (Optional) Snapshot expiration execution cycle | 600(10 hours) | The platform periodically scans and expires snapshots. A shorter execution cycle makes snapshot expiration more responsive but may consume more resources. |
smart-optimizer.written.advance.remove-orphan-interval-min | (Optional) Execution cycle for removing orphan files | 1440(24 hours) | The platform periodically scans and cleans up orphan files. A shorter execution cycle makes orphan file cleanup more responsive but may consume more resources. |
Optimization Types
Currently, DLC provides two types of optimization: write optimization and data cleanup. Write optimization merges small files written by users into larger files to improve query efficiency. Data cleanup removes storage space occupied by historical expired snapshots, saving storage costs.
Write Optimization
Small File Merging: Merges small files written from the business side into larger files to improve file query efficiency; processes and merges deleted files and data files to enhance MOR query efficiency.
Data cleanup
Snapshot expiration: Delete expired snapshot information to free up storage space occupied by historical data.
Remove orphan files: Delete orphan files to free up storage space occupied by invalid files.
Depending on the user's usage scenario, there are certain differences among optimization types, as shown below.
Optimization types | Recommended scenes for enabling |
Write optimization | Upsert write scenarios: It must be enabled. Merge into write scenarios: It must be enabled. Append write scenarios: It can be enabled as needed. |
Data cleanup | Upsert write scenarios: It must be enabled. Merge into write scenarios: It must be enabled. Append write scenarios: It is recommended to enable it and configure a reasonable time for deletion upon expiration based on advanced parameters and the need for rolling back historical data. |
DLC's write optimization not only merges small files but also allows for manual index creation. Users need to provide the fields and rules for the index, after which DLC will generate the corresponding stored procedure execution statements to complete the index creation. This can be done concurrently with small file merging in upsert scenarios, so that index creation is completed when small file merging is done, greatly improving index creation efficiency.
This feature is currently in the testing phase. If you need to use it, please Contact Us for configuration.
Optimization Tasks
DLC optimization tasks are triggered in two ways: by time and by events.
Time Triggering
Time triggers are based on the execution schedule of advanced optimization parameters. They periodically check if optimization is needed, and if the conditions for the corresponding governance item are met, a governance task is generated. The current minimum cycle for time triggers is 60 minutes, typically used for snapshot cleanup and orphan file removal.
Time triggers are still effective for tasks of optimizing small file merging, with a default trigger cycle of 60 minutes.
For V1 tables (requires activation of the backend), small file merging is triggered every 60 minutes.
For V2 tables; to prevent slow table writes and not meeting EventTriggering conditions for a long time, the V2 time trigger will start merging small files providing that it is more than 1 hour later since the last merging of small files.
If snapshot expiration or orphan file removal tasks fail or time out, they will be re-executed in the next check cycle which will start every 60 minutes.
EventTriggering
EventTriggering occurs in the scenarios where table upsert is written. The DLC data optimization service backend monitors the upsert writes to user tables, and when certain conditions are met, it triggers governance tasks. EventTriggering is used in small file merging scenarios, especially for real-time Flink upsert writes, as fast data writes frequently generate small file merge tasks.
For example, if the data file threshold is 20 and the deletes file threshold is 20, 20 files or 20 deletes files will be written. Meanwhile, if the minimum interval between the same task types is 5 minutes (by default), the merging of small files will be triggered.
Lifecycle
The lifecycle of a DLC Native Table refers to the time from the last update of the table (partition) data. If there is no change after the specified time, the table (partition) will be automatically possessed. When the lifecycle of a DLC metadata table is executed, it only generates new snapshots to overwrite expired data instead of immediately removing the data from storage. The actual removal of data from storage depends on metadata table data cleanup (snapshot expiration and orphan file removal). Therefore, the lifecycle needs to be used in conjunction with data cleanup.
Note:
The lifecycle feature is offering test invitations. If you need activate it, please Contact Us.
When a partition is removed by the lifecycle, it is logically removed from the current snapshot. However, the removed files are not immediately deleted from the storage system. They will only be deleted from the storage system when the snapshot expires.
Parameter Definitions
Database and table lifecycle parameters are set on their database and table attributes. Users can carry lifecycle parameters when creating databases and tables (DLC Native Table provides a visual interface for configuring lifecycle). Users can also modify lifecycle parameters using the ALTER DATABASE/TABLE command. For detailed instructions, see DLC Native Table Operation Configuration.
Attribute Values | Meaning | Default Values | Value description |
smart-optimizer.lifecycle.enable | Enable Lifecycle | disable | disable: No; enable: Yes. It is not enabled by default. |
smart-optimizer.lifecycle.expiration | Lifecycle execution cycle, unit: day | 30 | It can take effect when smart-optimizer.lifecycle.enable is set to enable, and it must be greater than 1. |
Integrating WeData to Manage Native Table Lifecycle
If user partition tables are partitioned by day, such as partition values yyyy-MM-dd or yyyyMMdd, WeData can be used to manage the data lifecycle.
Data Import
DLC Native Table (Iceberg) supports multiple data import methods. According to different data sources, see the following methods for importing data.
Data location | Import recommendation |
Data on the user's own COS bucket | Establish an external table in DLC, then import data using Insert into/overwrite. |
Data is on user's local system (or other executors). | Users need to upload data to their own COS buckets, then establish an external table in DLC and import data using insert into/overwrite. |
Data is on user's MySQL. | Users can import data using Flink/InLong/Oceanus. For detailed data lake operations, see DLC native tables (Iceberg) Lake Ingestion Practice. |
Data is on user's self-built hive. | Users establish a Land Bond Hive data management, then import data using insert into/overwrite. |
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No