With the partition catalog feature, you can store data with different characteristics in different catalogs. In this way, when exploring data, you can filter data by partition through the where condition. This greatly reduces the scanned data volume and improves the query efficiency.
Note:
Partitions in the same table should adopt the same data type and format.
Internal tables in Data Lake Compute are implemented as implicit partitions, so you don't need to care about the partition catalog structure.
Creating a Partition Table
Specify the partition field through the PARTITIONED BY parameter in the table creation statement.
Example: Creating the test_part partition table
CREATE EXTERNAL TABLE IF NOT EXISTS `DataLakeCatalog`.`test_a_db`.`test_part`(
`_c0` int,
`_c1` int,
`_c2` string,
`dt` string
) USING PARQUET PARTITIONED BY (dt) LOCATION 'cosn://testbucket/data/';
Adding a Partition
Adding a partition through ALTER TABLE ADD PARTITION
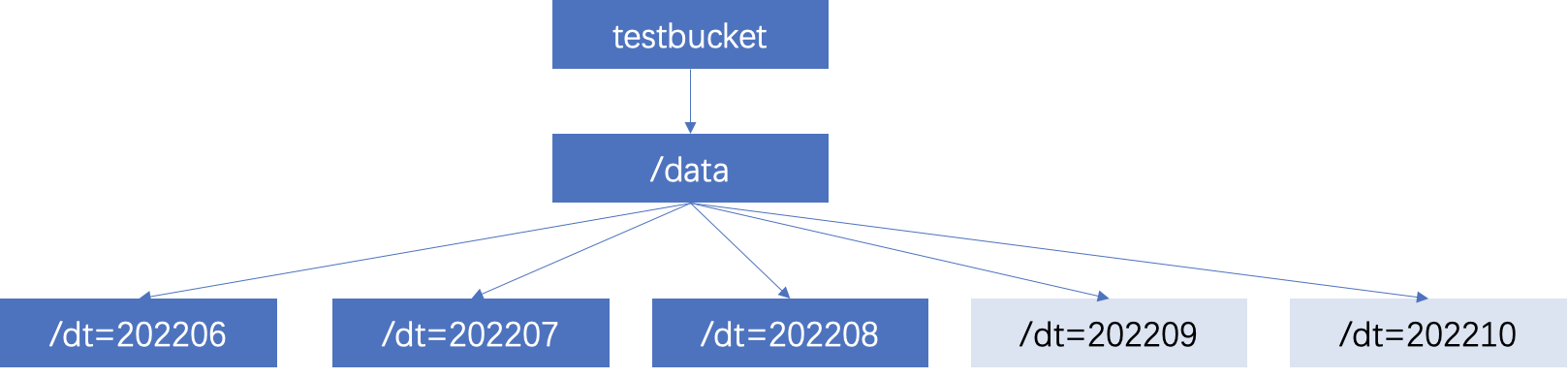
If your data partition catalog uses the Hive partitioning rule (partition column name=partition column value), the rule can be used to add partitions. The catalog is organized as follows:
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part`add PARTITION (dt ='202206')
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part`add PARTITION (dt ='202207')
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part`add PARTITION (dt ='202208')
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part`add PARTITION (dt ='202209')
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part`add PARTITION (dt ='202210')
Adding a partition by specifying the location through ALTER TABLE
If your data adopts a general COS catalog (not in the "partition column name=partition column value" format), you can specify a catalog when adding a partition.
Sample SQL:
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part`add PARTITION (dt ='202211')LOCATION='cosn://testbucket/data2/202211'
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part`add PARTITION (dt ='202212')LOCATION='cosn://testbucket/data2/202212'
Automatically adding a partition through MSCK REPAIR TABLE
Use the MSCK REPAIR TABLE statement to scan the data catalog specified during table creation. If there is a new partition catalog, the system will automatically add the partitions to the metadata of the data table.
Sample SQL: