Standard Engine Parameter Configuration
마지막 업데이트 시간:2025-03-12 18:03:39
Standard Engine Parameter Configuration
마지막 업데이트 시간: 2025-03-12 18:03:39
Spark parameters are used to configure and optimize settings for Apache Spark applications.
In a self-built Spark, these parameters can be set through command line options, configuration files, or programmatically.
In the DLC standard engine, you can set Spark parameters on the engine, which will take effect when users submit Spark jobs or submit interactive SQL using custom configurations.
Note:
1. The standard engine dimension configuration only takes effect for Spark jobs and Batch SQL tasks.
2. Only after the engine dimension configuration is added will the new tasks take effect.
Setting Standard Spark Engine Parameters
1. Enter the standard engine feature.
2. Select the engine that needs to be configured on the list page.
3. Click Parameter Configuration , and the engine parameter side window pops up.
4. In "Parameter Configuration", click Add , add the target configuration and then click Confirm .

Resource Group Dimension Parameters
Parameters of Resource Group for SQL Analysis Only Scenario
Adding Parameters When a Resource Group Is Created
When a resource group is created, select SQL analysis only and add parameters in the Parameter Management at the bottom.
Note:
1. Static parameters can only take effect after the resource group restarts, while dynamic parameters do not require a restart of the resource group to take effect.
2. For details on dynamic parameters and static parameters, see the official website of Spark.
3. The configuration of resource group for SQL analysis only scenario takes effect only when SQL tasks are run using that resource group.

Modifying Resource Group Parameters
1. In Standard Engine List Page , select the engine to be modified and click Enter .
2. On the resource group management page, select a resource group for SQL analysis only scenario and click the Details button.

3. On the details page, click Edit in the parameter management panel to add parameters or modify and delete added parameters. Similarly, static parameters can only take effect after the resource group is restarted, while dynamic parameters do not require a restart of the resource group to take effect.
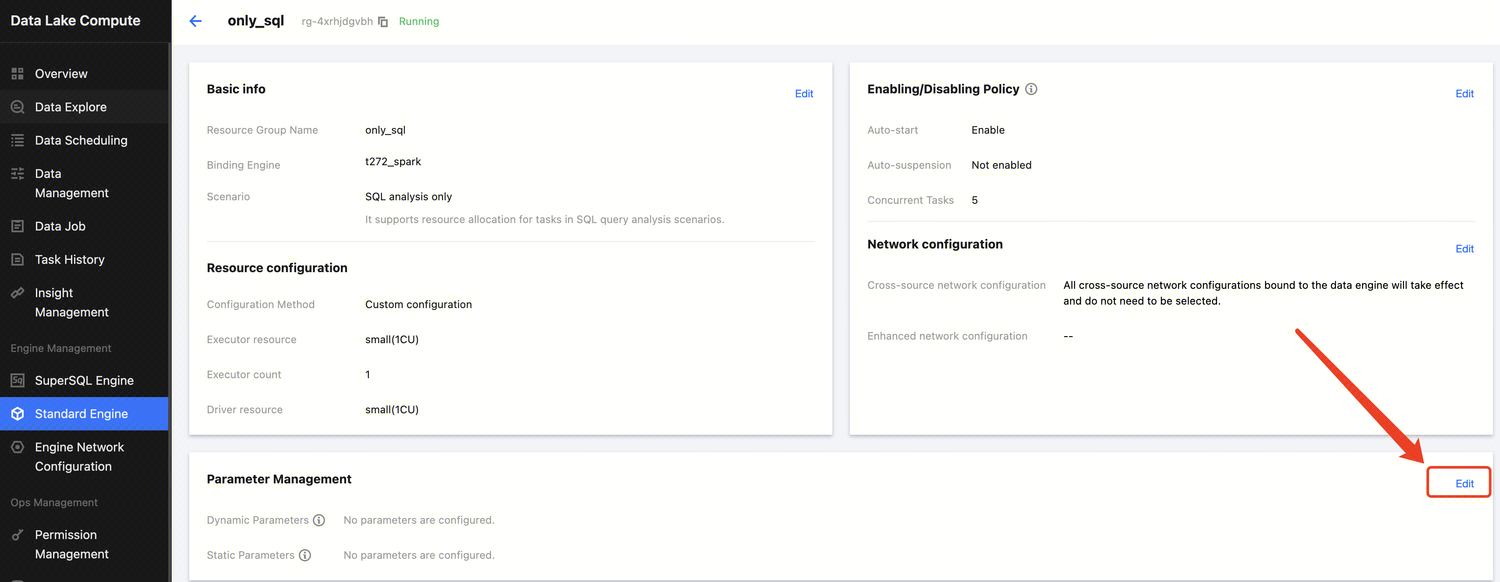
4. After the modification is completed, click Save. Then you can choose Restart Now, or you can choose Not Restart and Save Only and then restart the resource group at an appropriate time later to make the configuration take effect.

Resource Group Parameters for AI (Machine Learning) Scenario
Note:
1. Currently, only the Spark MLlib-type AI resource groups support adding configurations.
2. Currently, only static configurations can be added, which only take effect on new notebook sessions and do not take effect on existing sessions.
3. The AI Resource Group feature is a whitelist feature. To ensure that it meets your usage scenarios, please submit a ticket contact us for assessment and enablement.
4. This resource group only supports Standard Spark engine Standard-S version 1.1.
Adding Parameters When an AI Resource Group Is Created
As shown in the figure below, select the Spark MLlib type when the AI resource group is created, and choose to add parameters in the Parameter Management panel at the bottom.

Modifying AI Resource Group Parameters
1. In Standard Engine List Page , select the engine to be modified and click Enter.
2. On the resource group management page, select a Spark MLlib resource group and click Details.
3. On the details page, click Edit in the parameter management panel to add parameters or modify and delete the added parameters. Note that the modified parameters only take effect on the notebook session pulled after modification, and do not take effect on the existing sessions.

Data Exploration Parameters
Note:
1. Currently, only the resource group for SQL analysis only scenario supports adding parameters on the Data Explore page.
2. Note that only dynamic Spark configurations take effect in the subsequent executions against SQL, and static parameters cannot take effect.
3. The parameter configuration at the data exploration level is of higher priority than that at the engine level and resource group level.
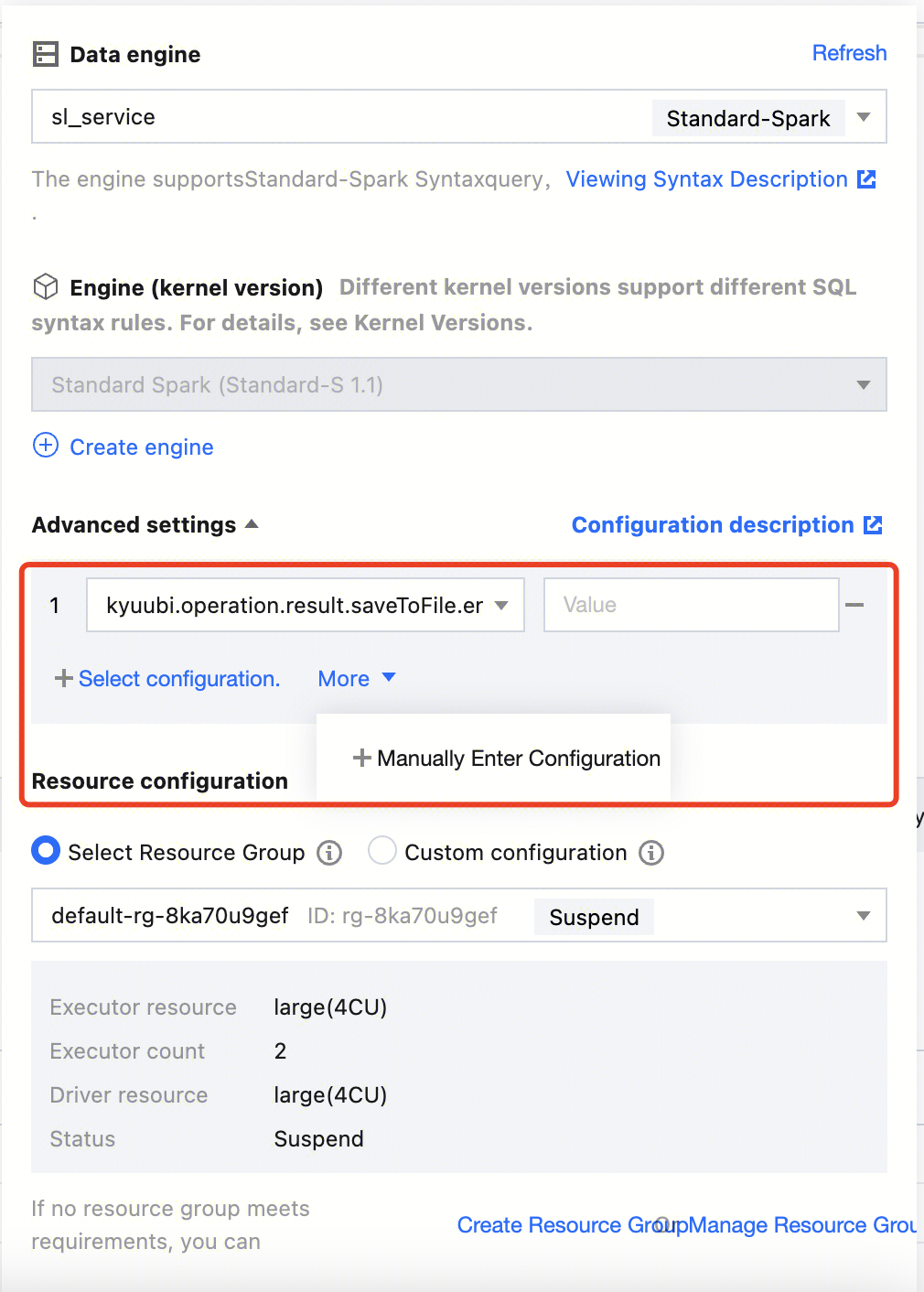
As shown in the figure below, on the Data Explore page, select the Standard-Spark engine for Data engine, select the option Select Resource Group for Resource configuration, and click Advanced settings on the page to add configurations.

As shown in the figure below, you can select a built-in configuration or enter the configuration manually.
Spark Job Parameters
Note:
1. Modifications to job parameters only take effect in the jobs that are launched subsequently and will not take effect in the running jobs.
2. The priority of job parameters is higher than that of engine-level parameters.
Adding Parameters When a Job Is Created

Editing Parameters of an Existing Job
1. Click Data Job,select an existing job and click Edit.

2. On the Edit job page, modify the job parameters and click Save after the modification.

피드백