- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
大数据场景下,频繁地碎片写入会产生大量的小文件,大量的小文件会严重拖慢性能。数据湖计算 DLC 根据大量的生产实践经验,为您提供高效、简单、灵活的数据优化能力,可应对大数据量下的近实时场景。
说明:
1. Upsert 场景下会产生大量小文件和快照,您需要在写入之前就配置好数据优化,避免因写入后再开启需要大量资源处理历史积压的小文件。
2. 目前数据优化能力仅支持 DLC 原生表。
3. 初次执行数据优化任务可能较慢,这取决于存量数据量大小和所选的引擎资源规格。
4. 建议数据优化引擎和业务引擎分开,避免数据优化作业和业务作业相关占用资源导致业务作业受阻。
通过 DLC 控制台配置数据优化
DLC 数据优化策略也可以配置在数据目录、数据库和数据表,当不单独针对数据库、数据表设置数据优化策略时,将继承上一级数据优化策略。用户在配置数据优化时,需要选择一个引擎,用户执行数据优化任务,如用户当前无数据引擎,可参考 购买独享数据引擎 进行购买。DLC 数据治理支持 Spark SupperSQL 引擎和 Spark 作业引擎。
说明:
1. 如用户选择 Spark 作业引擎作为数据优化资源,DLC 会在该引擎上创建数据优化作业,根据集群的规模不同,创建的优化作业数据也有所不同,如集群规模小于32CU时,将创建一个数据优化作业用于执行所有的优化任务,当集群规模大于32CU时,将创建两个数据优化作业,分作业执行写入优化和数据删除优化。
2. 选择 Spark 作业作为数据优化资源时,需要预留一些资源,当优化任务排队超过50个时,DLC 会拉起临时的数据优化作业,快速消费堆积的优化任务。
数据目录配置步骤
您可以通过 DLC 的数据目录编辑功能,针对数据目录配置数据优化能力。
1. 进入 DLC 控制台 数据管理模块,进入数据目录页面,单击数据优化。

2. 打开数据目录的数据优化页面,配置对应的数据优化资源和策略,确认后数据优化功能会自动应用于该数据目录上。
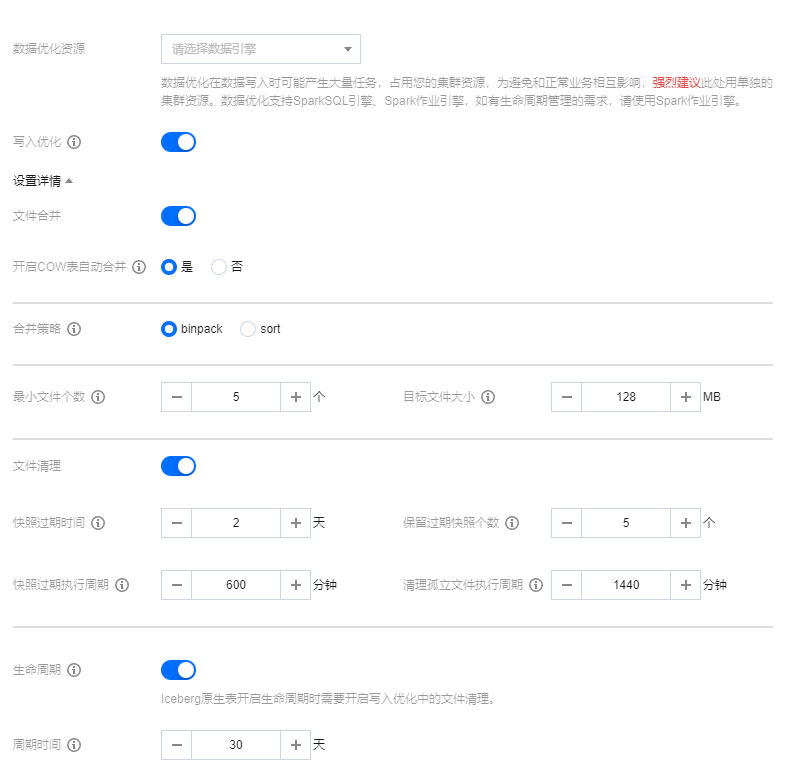
说明:
仅支持针对 DataLakeCatalog 数据目录进行数据优化配置。
数据库配置步骤
如果您要针对某个数据库单独配置数据优化策略,则可以通过 DLC 的数据库编辑能力,针对数据库配置数据优化能力。
1. 进入 DLC 控制台 数据管理模块,进入数据库页面,进入 DataLakeCatalog 下的数据库列表。
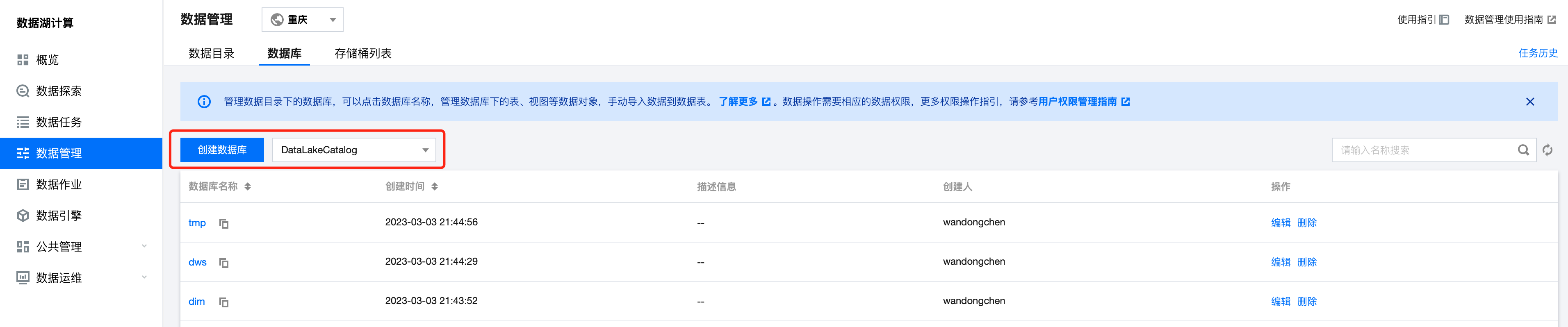
2. 打开数据库页面,点击数据优化配置,确认后数据优化策略会自动作用于该数据库上。
说明:
创建数据库、编辑数据时,默认显示数据优化策略继承上一级的数据目录的数据优化策略,如果要自定义数据优化策略时,需要选择自定义配置并配置数据优化资源和策略。
数据表配置步骤
如果您要针对某个数据表单独配置数据优化策略,则可以通过 DLC 的数据表编辑能力,针对数据表配置数据优化能力。
1. 进入 DLC 控制台 数据管理模块,进入数据库页面,选择数据库后进入数据表列表页面,单击创建原生表。

2. 打开创建原生表页面,配置对应的优化资源,确认后数据优化策略会自动作用于该数据表上。
3. 针对已经创建好的表,可以单击数据优化配置,编辑已存在的数据表的数据优化策略。
说明:
创建数据表、编辑数据表时,默认显示数据优化策略继承上一级的数据表的数据优化策略,如果要自定义数据优化策略时,需要选择自定义配置并配置数据优化资源和策略。
通过属性字段配置数据优化
除了以上可视化方式配置数据优化,您还可以手动指定库和表字段属性来进行配置。例如:
// for table govern policyALTER TABLE`DataLakeCatalog`.`wd_db`.`wd_tb`SETTBLPROPERTIES ('smart-optimizer.inherit' = 'none','smart-optimizer.written.enable' = 'enable')// for database govern policyALTER DATABASE`DataLakeCatalog`.`wd_db`SETDBPROPERTIES ('smart-optimizer.inherit' = 'none','smart-optimizer.written.enable' = 'enable')
其中,数据优化的属性值都可以通过ALTER语句进行修改,属性值定义如下:
属性值 | 含义 | 默认值 | 取值说明 |
smart-optimizer.inherit | 是否继承上一级策略 | default | none:不继承 default:继承 |
smart-optimizer.written.enable | 是否开启写入优化 | disable | disable:不开启 enable:开启 |
smart-optimizer.written.advance.compact-enable | (可选)写入优化高级参数,是否开始小文件合并 | enable | disable:不开启 enable:开启 |
smart-optimizer.written.advance.delete-enable | (可选)写入优化高级参数,是否开始数据清理 | enable | disable:不开启 enable:开启 |
smart-optimizer.written.advance.min-input-files | (可选)合并最小输入文件数量 | 5 | 当某个表或分区下的文件数目超过最小文件个数时,平台会自动检查并启动文件优化合并。文件优化合并能有效提高分析查询性能。最小文件个数取值较大时,资源负载越高,最小文件个数取值较小时,执行更灵活,任务会更频繁。建议取值为5。 |
smart-optimizer.written.advance.target-file-size-bytes | (可选)合并目标大小 | 134217728 (128 MB) | 文件优化合并时,会尽可能将文件合并成目标大小,建议取值128M。 |
smart-optimizer.written.advance.retain-last | (可选)快照过期时间,单位天 | 5 | 快照存在时间超过该值时,平台会将该快照标记为过期的快照。快照过期时间取值越长,快照清理的速度越慢,占用存储空间越多。 |
smart-optimizer.written.advance.before-days | (可选)保留过期快照数量 | 2 | 超过保留个数的过期快照将会被清理。保留的过期快照个数越多,存储空间占用越多。建议取值为5。 |
smart-optimizer.written.advance.expired-snapshots-interval-min | (可选)快照过期执行周期 | 600(10 hour) | 平台会周期性扫描快照并过期快照。执行周期越短,快照的过期会更灵敏,但是可能消耗更多资源。 |
smart-optimizer.written.advance.cow-compact-enable | (可选)是否开启COW表(V1表或者V2非Upsert表)合并 | disable | 该配置项开启后,系统会自动针对 COW 表产生文件合并任务。 需注意:COW 表通常数据量都较大,进行文件合并时可能会占用较多的资源,您可根据资源情况及表大小选择是否开启 COW 表文件合并。 |
smart-optimizer.written.advance.strategy | (可选)文件合并策略 | binpack | binpack(默认合并策略):将文件以 append 的方式对满足合并条件的数据文件合并为更大的数据文件。
sort:sort 策略合并时会根据指定的字段进行排序,您可以根据业务场景选择使用频率较高的查询条件字段作为排序字段,合并后可提高查询性能。 |
smart-optimizer.written.advance.sort-order | (可选)当文件合并策略为sort时,配置的sort排序规则 | - | 如果您没有配置排序策略,Upsert 表将选择设置的 upsert 键值(默认取前两个键值)按照 ASC NULLS LAST 的方式排序。如果 COW 表 sort 合并时找不到排序策略,将采用 binpack 默认合并策略。 |
smart-optimizer.written.advance.remove-orphan-interval-min | (可选)移除孤立文件执行周期 | 1440(24 hour) | 平台会周期性扫描并清理孤立文件。执行周期越短,清理孤立文件会更灵敏,但是可 能消耗更多资源。 |
优化建议
DLC 后端定期统计原生表的各个指标项,并根据这些指标项结合最佳实践,给出原生表的优化建议。优化建议共分为4个优化建议项,包含表使用场景基本配置、数据优化建议及数据存储分布项建议。
优化建议检查项 | 子检查项 | 含义 | 业务场景 | 优化建议 |
表基本属性配置检查 | 是否开启元数据治理 | 检查是否开启元数据治理,防止表频繁写入引起元数据metadata数量膨胀 | append/merger into/upsert | 建议开启 |
| 是否设置 bloom filter | 检查是否设置 bloom filter,在开启 bloom filter 表后,针对 MOR 表并快速过滤 deletes 文件,能加快 MOR 表查询和 deletes 文件合并 | upsert | 必须开启 |
| 是否配置 metrics 关键属性 | 检查是否 metrics 在设置为 full,该属性开启后,会记录全部的 metrtics 信息,避免应表 location 过长导致 metrics 信息记录不全 | append/merger into/upsert | 必须开启 |
数据优化配置检查 | 小文件合并 | 检查是否开启小文件合并 | merge into/upsert | 必须开启 |
| 快照过期 | 检查是否开启快照过期 | append/merge into/upsert | 建议开启 |
| 移除孤立文件 | 检查是否开启移除孤立文件 | append/merge into/upsert | 建议开启 |
近期治理任务检查项 | 近期治理任务检查项 | 如表开启了数据治理,系统统计数据治理任务的执行情况,当出现连续多个任务执行超时或者失败时,将判断为需要优化 | append/merger into/upsert | 建议开启 |
数据存储分布 | 平均文件大小 | 采集快照的summary信息,计算平均文件大小,当平均文件大小小于10M时将判断为需要优化 | append/merger into/upsert | 建议开启 |
| MetaData 元文件大小 | 采集表 metadata.json 元文件大小,当该文件大小超过10M将判定为需要优化 | append/merger into/upsert | 建议开启 |
| 表快照数量 | 采集表快照数量,当表快照数量超过1000个将判定为需要优化 | append/merger into/upsert | 建议开启 |
表属性基本配置项优化建议
检查并配置元数据治理方法
Step1 检查方法
通过 show TBLPROPERTIES 查看表属性,检查是否配置 “write.metadata.delete-after-commit.enabled”,“write.metadata.previous-versions-max”。
Step2 配置方法
如果 Step1检查结果为未配置,可通过如下 Alter table DDL 进行配置,参考方法如下。
ALTER TABLE`DataLakeCatalog`.`axitest`.`upsert_case`SETTBLPROPERTIES('write.metadata.delete-after-commit.enabled' = 'true','write.metadata.previous-versions-max' = '100');
说明:
开启元数据自动治理,需要将属性 “write.metadata.delete-after-commit.enabled” 设置为 true。可根据实际情况设置保留的历史 metadata 的个数,如 “write.metadata.previous-versions-max” 设置为100,则最多保留历史100个 metadata。
检查并设置 bloom filter 方法
Step1 检查方法
通过 show TBLPROPERTIES 查看表属性,检查是否设置了 “write.parquet.bloom-filter-enabled.column.{column}” 为 true。
Step2 设置方法
如果 Step1检查结果为未配置,可通过如下 Alter table DDL 进行配置,参考方法如下。
ALTER TABLE`DataLakeCatalog`.`axitest`.`upsert_case`SETTBLPROPERTIES('write.parquet.bloom-filter-enabled.column.id' = 'true');
说明:
建议在 upsert 场景开启 bloom,且根据 upsert 主键进行设置,如有多个主键,建议针对前两个主键字段设置。
在更新 bloom 字段后,如上游有 inlong/oceans/flink 写入时,要重启上游导入作业。
检查并配置表关键属性 metrics
Step1 检查方法
通过 show TBLPROPERTIES 查看表属性,检查 “write.metadata.metrics.default” 是否配置为 “full”。
Step2 配置方法
如果 Step1检查结果为未配置,可通过如下 Alter table DDL 进行配置,参考方法如下。
ALTER TABLE`DataLakeCatalog`.`axitest`.`upsert_case`SETTBLPROPERTIES('write.metadata.metrics.default' = 'full');
数据优化配置优化建议
Step1 检查方法
通过 SQL 检查
通过 DLC 控制台可视化检查
Step2 配置方法
根据指导开启数据优化。
近期数据治理优化任务项优化建议
检查数据治理是否正常
Step1 检查方法
进入 DLC 控制台 数据管理模块,进入数据库页面,选择数据库后进入数据表列表页面,点击数据表名称,进入优化监控,选择优化任务中的本日优化,检查最近三小时有运行失败的任务,如存在则是本项检查不通过。选择失败的任务,查看详情中的运行结果。
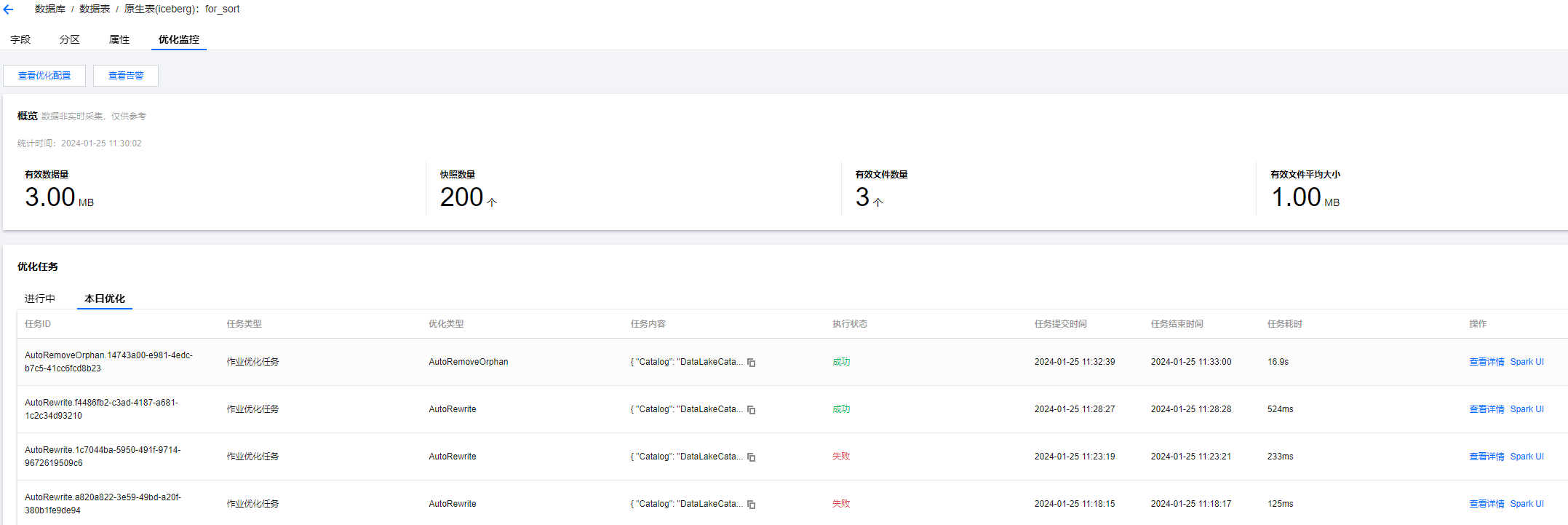
Step2 修复方法
场景数据优化任务运行失败原因及处理方法汇总。
1. 数据治理配置错误导致运行失败。
开启了 sort 合并策略,但是配置排序规则配置错误,或者配置了不存在的排序规则。
配置为进行数据治理的引擎发生了变化,导致治理任务运行时找不到合适的引擎。
2. 任务运行超时。
说明:
近期数据优化任务运行情况检查在修复后,需要等待三个小时后观察是否恢复。
数据存储分布项优化建议
说明:
该场景检查不通过通常是数据量较大,建议先手动处理后在考虑添加到数据优化治理。
建议用效率更高效的 spark 作业引擎处理。
进行手动小文件合并处理时,target-file-size-bytes 参数根据业务场景配置,upsert 写入建议不超过134217728,即128M,append/merge into 写入建议不超过536870912,即512M。
采用 spark 作业引擎执行快照过期时,可调大 max_concurrent_deletes 参数。
数据文件平均大小检查不通过处理方法
Step1 原因汇总
数据文件平均大小过小,通常出现在如下几个情况:
表分区划分过细,导致每个分区只有少量数据。
表进行 Insert into/overwrite 方式写入时,上游的数据分散,如上游数据也是分区表,且分区内数据量少。
表进行 merge into 写入 MOR 表,但是没有进行小文件合并。
表进行 upsert 写入,但是没有进行小文件合并。
Step2 修复方法
参考如下 SQL,手动执行小文件合并。
CALL `DataLakeCatalog`.`system`.`rewrite_data_files`(`table` => 'test_db.test_tb',`options` => map('delete-file-threshold','10','max-concurrent-file-group-rewrites', --根据实际资源情况而定,并发度越高,采用的资源越多,文件合并越快'5','partial-progress.enabled','true','partial-progress.max-commits','10','max-file-group-size-bytes','10737418240','min-input-files','30','target-file-size-bytes','134217728'))
MetaData 元文件大小检查不通过处理方法
Step1 原因汇总
MetaData 元文件过大,通常是数据文件数量过多引起的,大部分是如下几个原因导致:
表长期进行 append 写入,且每次写入的文件分散量大。
表属性为 MOR 表,长期进行 merge into 写入,但没有开启小文件合并。
表长期没有进行快照过期,表维护大量的历史快照数据文件。
表分区较大,且每个分区的文件都较小数量多。
Step2 修复方法
参考手动执行小文件合并。
参考如下 SQL,手动执行过期快照 SQL,将历史快照清理。
--采用spark 作业引擎过期快照参考CALL `DataLakeCatalog`.`system`.`expire_snapshots`(`table` => 'test_db.test_tb',`retain_last` => 5,`stream_results` => true,`older_than` => TIMESTAMP '2024-01-10 13:02:40.407', --过期时间根据表实际快照为准`max_concurrent_deletes` => 50);--采用spark sql引擎过期快照参考CALL `DataLakeCatalog`.`system`.`expire_snapshots`(`table` => 'test_db.test_tb',`retain_last` => 5,`stream_results` => true,`delete_by_executor` => true,`older_than` => TIMESTAMP '2024-01-10 13:02:40.407', --过期时间根据表实际快照为准`max_concurrent_deletes` => 4)
结合业务场景,将写入的文件进行一定程度聚合,避免写入的文件较分散。
如数据为 insert into/insert overwrite 写入,可通过如下两种方式自动添加一个 repartition 操作。
1. 下面两个参数都为 true 时生效。仅该情况下,可以使用上文的参数控制 repartition 后自动适配分区数或分区大小。
spark.sql.adaptive.enabled:该参数需为 true,集群创建默认为 true。
spark.sql.adaptive.insert.repartition:该参数需为 true,集群创建默认为 false。
2. 指定下面参数生效。这种情况下 repartition 后的分区数即 spark.sql.adaptive.insert.repartition.forceNum 指定的值。
spark.sql.adaptive.insert.repartition.forceNum:该参数指定了具体需要分区的值,集群创建时默认为空。
快照数量检查检查不通过处理方法
Step1 原因汇总
长期没有进行快照过期。
upsert 写入 checkpoint 周期不合理,产生大量的快照。
Step2 修复方法
参考快照过期 SQL,进行快照过期。
调整 flink 写入 checkpoint 周期,DLC 原生表 upsert 写入 checkpoint 周期建议设置在3 - 5min。

 是
是
 否
否
本页内容是否解决了您的问题?