- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
前言
为了提升任务执行效率,DLC 引擎在计算过程中有许多优化措施,例如数据治理、Iceberg 索引、缓存等。正确使用不仅可以减少不必要的扫描费用,甚至可以提升几倍甚至几十倍的效率。下面提供一些不同层面的优化思路。
优化 SQL 语句
场景:SQL 语句本身不合理,导致执行效率不高。
优化 JOIN 语句
当查询涉及 JOIN 多个表时, Presto 引擎会优先完成查询右侧的表的 JOIN 操作,通常来说,先完成小表的 JOIN,再用结果集和大表进行 JOIN,执行效率会更高,因此 JOIN 的顺序会直接影响查询的性能,DLC presto 会自动收集内表的统计数据, 利用 CBO 对查询中的表进行重排序。
对于外表,通常用户可以通过analyze语句完成统计数据的收集,或者手动指定 JOIN 的顺序。如需手动指定请按表的大小顺序,将小表放在右侧,大表放在左侧, 如表A > B > C, 例如:select * from A Join B Join C。需要注意的是,这不能保证所有场景下都能提升效率,实际上这取决于 JOIN 后的数据量大小。
优化 GROUP BY 语句
合理安排 GROUP BY 语句中字段顺序对性能有一定提升,请根据聚合字段的基数从高到低进行排序,例如:
//高效的写法SELECT id,gender,COUNT(*) FROM table_name GROUP BY id, gender;//低效的写法SELECT id,gender,COUNT(*) FROM table_name GROUP BY gender, id;
另一种优化方式是,尽可能地使用数字代替具体分组字段。这些数字是 SELECT 关键字后的列名的位置,例如上面的 SQL 可以用以下方式代替:
SELECT id,gender,COUNT(*) FROM table_name GROUP BY 1, 2;
使用近似聚合函数
对于允许有少量误差的查询场景,使用这一些近似聚合函数对查询性能有大幅提升。
例如,Presto 可以使用 APPROX_DISTINCT()函数代替 COUNT(distinct x),Spark 中对应函数为 APPROX_COUNT_DISTINCT。该方案缺点是近似聚合函数有大概2.3%的误差。
使用 REGEXP_LIKE 代替多个 LIKE
当 SQL 中有多个 LIKE 语句时,通常可以使用正则表达式来代替多个 LIKE,这样可以大幅提升执行效率。例如:
SELECT COUNT(*) FROM table_name WHERE field_name LIKE '%guangzhou%' OR LIKE '%beijing%' OR LIKE '%chengdu%' OR LIKE '%shanghai%'
可以优化成:
SELECT COUNT(*) FROM table_name WHERE regexp_like(field_name, 'guangzhou|beijing|chengdu|shanghai')
数据治理
数据治理适用场景
场景:实时写入。Flink CDC 实时写入通常采用 upsert 的方式写入,该流程在写入过程中会产生大量的小文件,当小文件堆积到一定程度后会导致数据查询变慢,甚至超时无法查询。
可以通过以下方式查看表文件数量和快照信息。
SELECT COUNT(*) FROM [catalog_name.][db_name.]table_name$files;SELECT COUNT(*) FROM [catalog_name.][db_name.]table_name$snapshots;
例如:
SELECT COUNT(*) FROM `DataLakeCatalog`.`db1`.`tb1$files`;SELECT COUNT(*) FROM `DataLakeCatalog`.`db1`.`tb1$snapshots`;
数据治理效果
开启数据治理后,查询效率得到显著提升,例如下表对比了合并文件前后的查询耗时,该实验采用16CU presto,数据量为14M,文件数量2921,平均每个文件0.6KB。
执行语句 | 是否合并文件 | 文件数量 | 记录条数 | 查询耗时 | 效果 |
SELECT count(*) FROM tb | 否 | 2921个 | 7895条 | 32s | 速度快93% |
| SELECT count(*) FROM tb | 是 | 1个 | 7895条 | 2s |
分区
分区能够根据时间、地域等具有不同特征的列值将相关数据分类存储,这有助于大幅减少扫描量,提升查询效率。关于 DLC 外表分区更多详情信息,请参考一分钟入门分区表。下表展示了在数据量为66.6GB,数据记录为14亿条,数据格式为 orc 的单表中,分区和不分区时查询耗时和扫描量的效果对比。其中
dt是含有1837个分区的分区字段。查询语句 | 未分区 | 分区 | 耗时对比 | 扫描量对比 | ||
| | | 耗时 | 扫描量 | 耗时 | 扫描量 |
SELECT count(*) FROM tb WHERE dt='2001-01-08' | 2.6s | 235.9MB | 480ms | 16.5 KB | 快81% | 少99.9% |
SELECT count(*) FROM tb WHERE dt<'2022-01-08' AND dt>'2001-07-08' | 3.8s | 401.6MB | 2.2s | 2.8MB | 快42% | 少99.3% |
从上表中可以看出,分区可以有效地降低查询延时和扫描量,但过度分区可能适得其反。如下表所示。
查询语句 | 未分区 | 分区 | 耗时对比 | 扫描量对比 | ||
| | | 耗时 | 扫描量 | 耗时 | 扫描量 |
SELECT count(*) FROM tb | 4s | 24MB | 15s | 34.5MB | 慢73% | 多30% |
建议您在 SQL 语句中通过 WHERE 关键字来过滤分区。
缓存
在如今分布式计算和存算分离的趋势下,通过网络访问元数据以及海量数据将会受到网络 IO 的限制。DLC 默认开启以下缓存技术大幅降低响应延时,无需您介入管理。
Alluxio :是一种数据编排技术 。它提供缓存,将数据从存储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。Alluxio 内存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。
RaptorX:是Presto的一个连接器。它像 Presto 一样运行在存储之上,提供亚秒级延迟。 目标是为 OLAP 和交互式用例提供统一、廉价、快速且可扩展的解决方案。
结果缓存:Result Cache,对于重复的同一查询进行缓存,极大提高速度和效率
DLC Presto 引擎默认支持 RaptorX 和 Alluxio 分级缓存,在短时间内相同任务场景中可以有效地降低延时。Spark、Presto引擎均支持结果缓存。
下表是在总数据量 为1TB的 Parquet 文件中的 TPCH 测试数据,本次测试选用16CU Presto。因为测试的是缓存功能,所以主要从 TPCH 中选择 IO 占用比较大的 SQL ,涉及的表主要有 lineitem、orders、customer 等表,涉及的 SQL 为 Q1、Q4、Q6、Q12、Q14、Q15、Q17、Q19 以及 Q20。其中横坐标表示SQL语句,纵坐标表示运行时间(单位秒)。
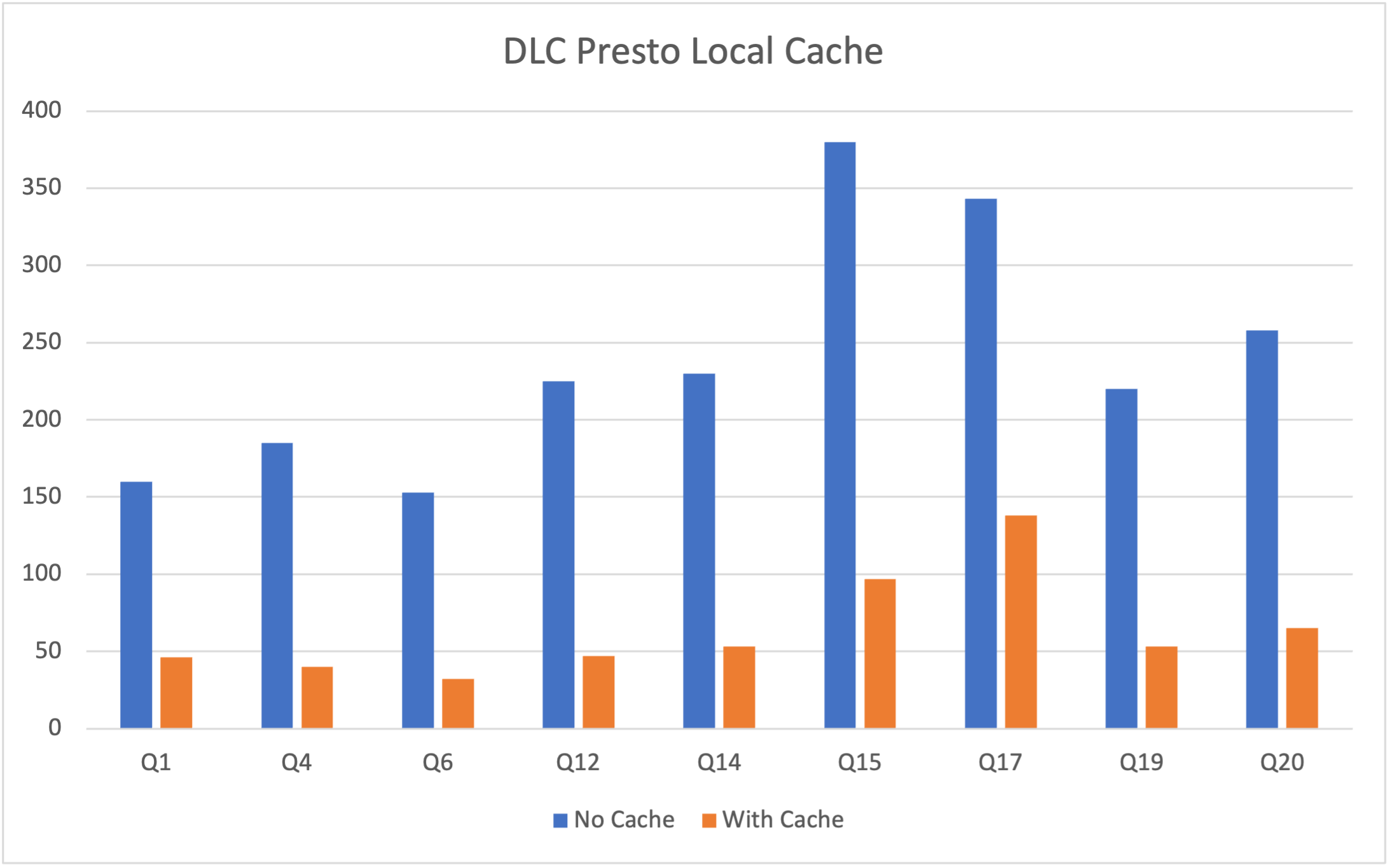
需要注意的是,DLC Presto 引擎会根据数据访问频率动态加载缓存,所以引擎启动后首次执行任务无法命中缓存,这导致首次执行仍受网络 IO 限制,但随着执行次数增加,该限制明显得到缓解。如下表展示了 presto 16cu 集群三次查询的性能比较。
查询语句 | 查询 | 耗时 | 数据扫描量 |
SELECT * FROM table_namewhere udid='xxx'; | 第一次查询 | 3.2s | 40.66MB |
| 第二次查询 | 2.5s | 40.66MB |
| 第三次查询 | 1.6s | 40.66MB |
您可以在DLC控制台 数据探索 功能中查看执行的SQL任务的缓存命中情况。
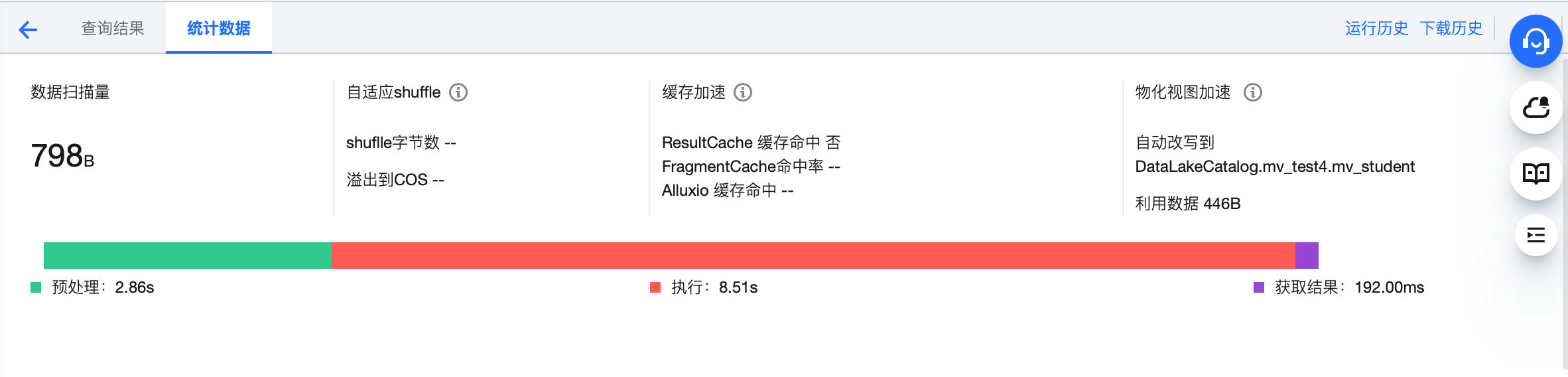
索引
创建表后根据业务使用频率在 insert 前建立索引,WRITE ORDERED BY 后的索引字段。
alter table `DataLakeCatalog`.`dbname`.`tablename` WRITE ORDERED BY udid;
下表展示了 presto 16cu 集群在外表和内表(加索引)上查询性能比较
表类型 | 查询 | 耗时 | 数据扫描量 |
外表 | 第一次查询 | 16.5s | 2.42GB |
| 第二次查询 | 15.3s | 2.42GB |
| 第三次查询 | 14.3s | 2.42GB |
内表(索引) | 第一次查询 | 3.2s | 40.66MB |
| 第二次查询 | 2.5s | 40.66MB |
| 第三次查询 | 1.6s | 40.66MB |
从表中可以看出,内表+索引的建表方式相对于外表,在时间和扫描量上均会大幅减小,并且由于缓存加速,执行时间也会随着执行次数的增加而减少。
同步查询和异步查询
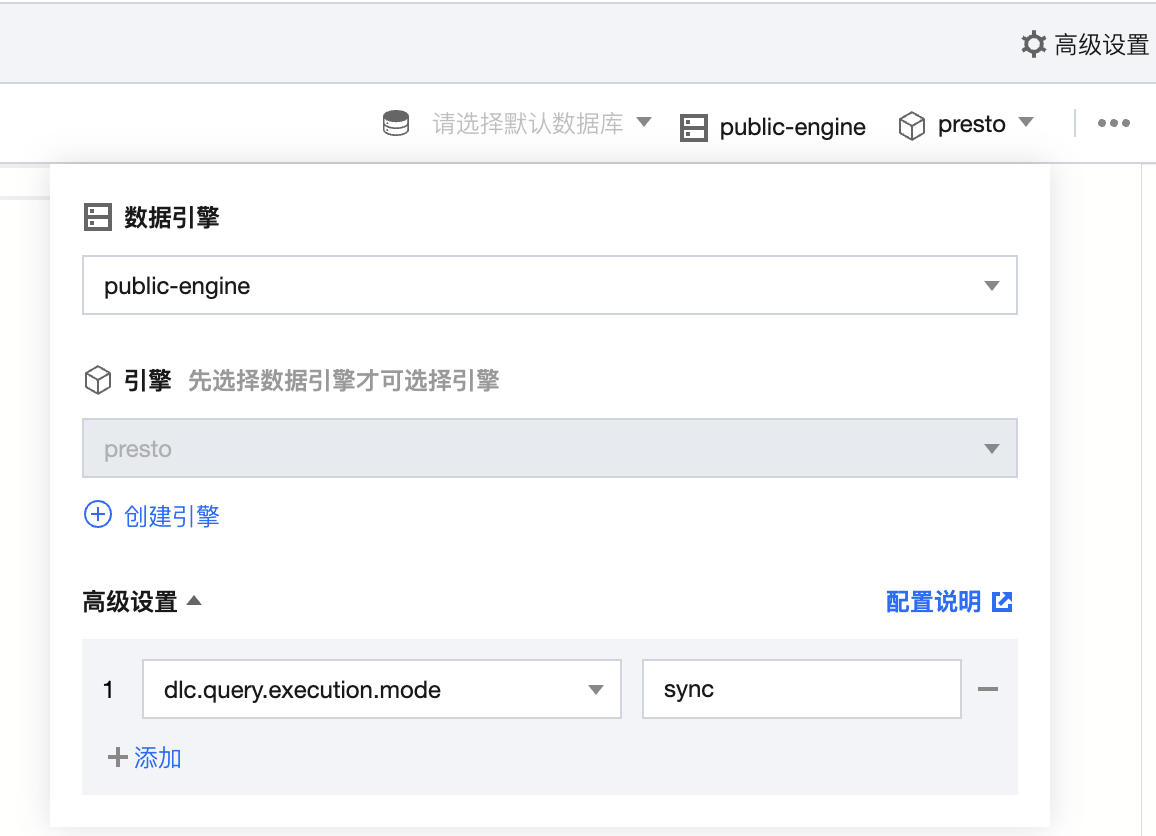
DLC 针对于 BI 场景进行了特别的优化,可以通过配置引擎参数dlc.query.execution.mode来开启同步模式或者异步模式(只支持 presto 引擎)。取值介绍如下。
async(默认):该模式任务会完成全量查询计算,并将结果保存到 COS,再返回给用户,允许用户在查询完成后下载查询结果。
sync:该模式下,查询不一定会执行全量计算,部分结果可用后,会直接由引擎返回给用户,不再保存到 COS。因此用户可获得更低查询延迟和耗时, 但结果只在系统中保存30s。推荐不需要从 COS 下载完整查询结果,但期望更低查询延迟和耗时时使用该模式,例如查询探索阶段、BI 结果展示。
配置方式:选择数据引擎后,支持对数据引擎进行参数配置,选择数据引擎后,在高级设置单击添加即可进行配置。
资源瓶颈
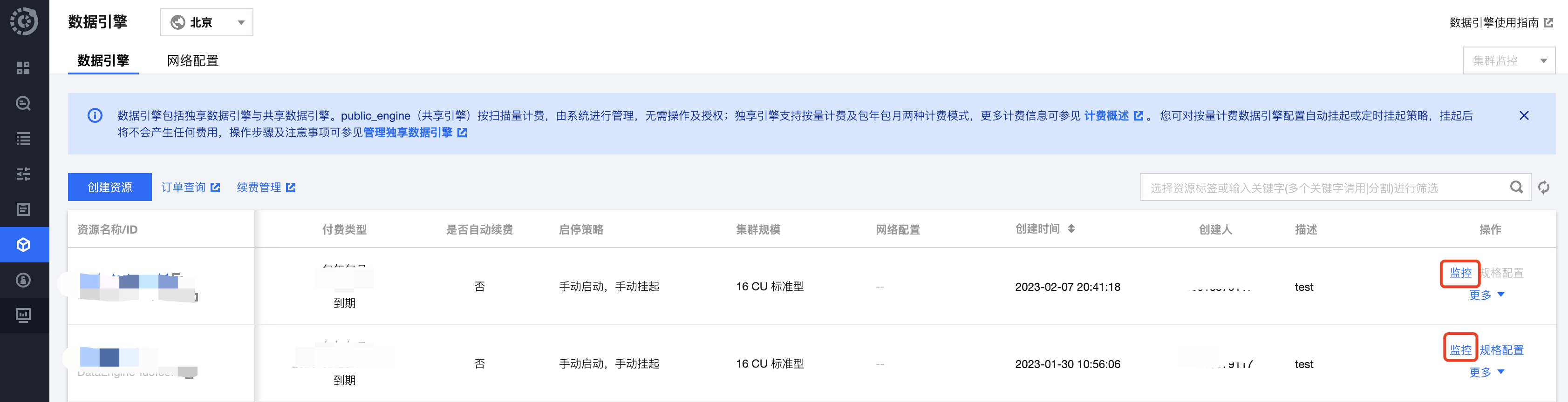
1. 打开左侧数据引擎标签页。
2. 单击相应引擎的右侧监控按钮。
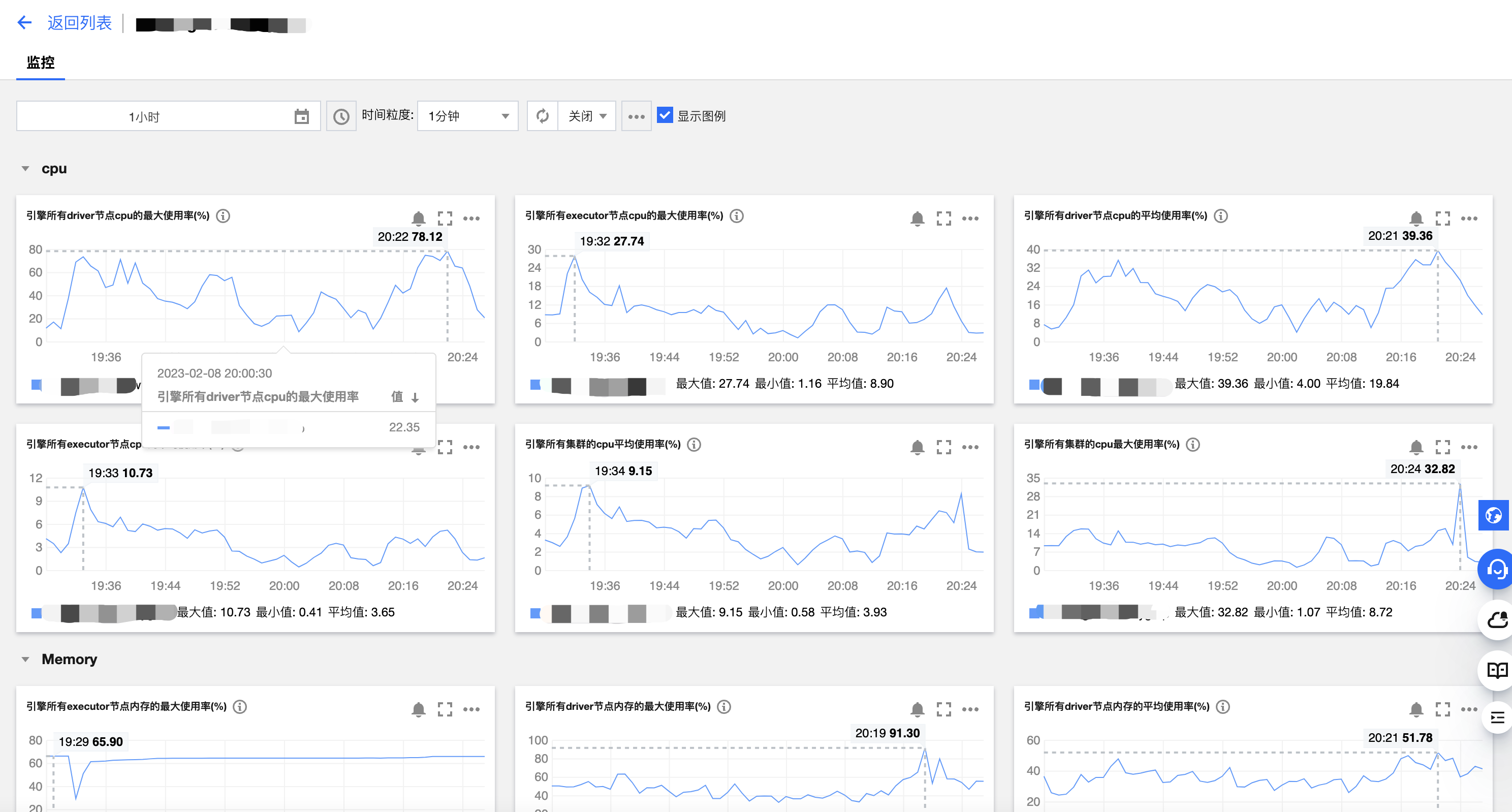
3. 跳转到腾讯云可观测平台,可以查看到所有监控指标,如下图所示。详细操作以及监控指标请参考数据引擎监控。同时您也可以针对每个指标进行告警配置,详细介绍请参考 监控告警配置。
其他因素
自适应 shuffle
为了提高稳定性,DLC 默认开启自适应 shuffle,这是一套即能支持有限本地磁盘的常规 shuffle,又能保证在大shuffle和数据倾斜等场景下的稳定性。自适应 shuffle 带来的优势:
1. 降低存储成本:集群节点的磁盘挂载量进一步降低,一般规模集群每节点只要50G、大规模集群也不超200G。
2. 稳定性:对于 shuffle 数据量剧增或数据倾斜场景任务执行的稳定性不会再因本地磁盘限制而失败。
尽管自适应shuffle带来存储成本的降低和稳定性提升,但在某些场景下,如资源不足时,会带来约15%的延时。
集群冷启动
DLC 支持自动或者手动挂起集群,挂起后不再产生费用,所以在集群启动后,首次执行任务可能存在“正在排队”的提示,这是因为集群冷启动中正在拉起资源。如果您频繁提交任务,建议购买包年包月集群,该类型集群不存在冷启动,能在任何时间快速执行任务。

 是
是
 否
否
本页内容是否解决了您的问题?