- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
数据湖计算 DLC 为您提供敏捷高效的 Serverless 数据湖分析与计算服务,而 DLC 作为分布式计算平台,其查询性能受到多项内外部因素影响,例如:引擎 CU 规模、同时提交排队的任务数量、SQL 编写形式、Spark 参数设置等。数据湖计算 DLC 洞察管理提供了一个可视化的直观界面,帮助您快速了解当前查询性能表现以及影响性能的潜在因素,并获取性能优化建议。
数据湖计算 DLC 提供洞察管理功能包含任务洞察与引擎用量洞察功能,协助用户更好地调整资源或优化任务逻辑。适用的业务场景:
1. 对 Spark 引擎有整体运行状况洞察的诉求,如:引擎下各任务运行时的资源抢占情况,引擎内资源使用情况,引擎执行时长,数据扫描大小,数据shuffle 大小等都有直观的展示与分析。
2. 可以方便自助排查分析任务运行情况的诉求,如:可对众多任务按照耗时筛选排序,快速找到有问题的大任务,定位 Spark 任务运行缓慢或者失败的原因,如资源抢占,shuffle 异常,磁盘不足等情况,都有清晰的定位。
任务洞察
任务洞察是基于任务视角,帮助用户可以快速定位已完成的任务的优化分析与优化建议。
操作步骤
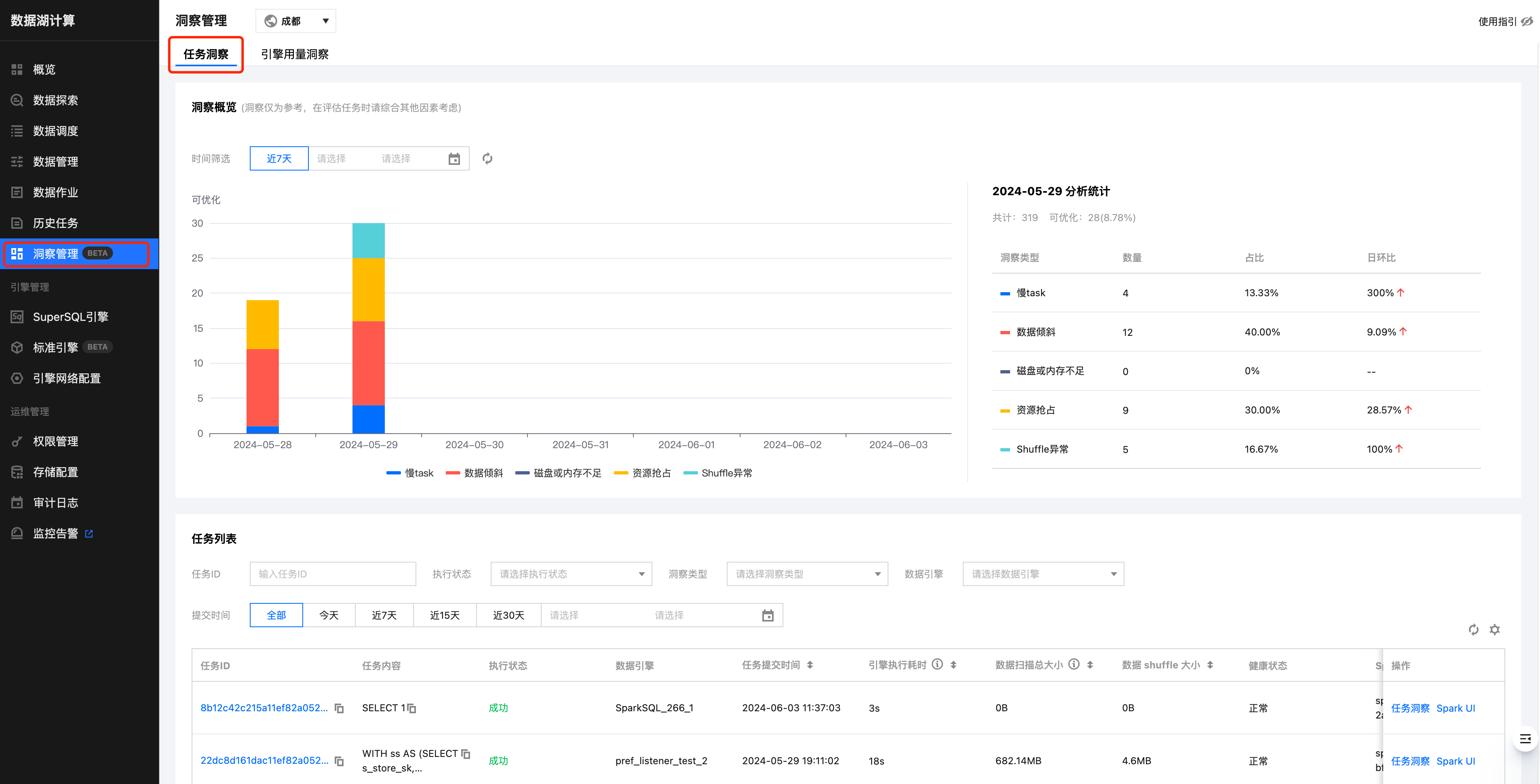
洞察概览
日级别统计洞察出来的待优化的任务分布情况和走势分布,可以对每日的任务有一个更直观的了解。
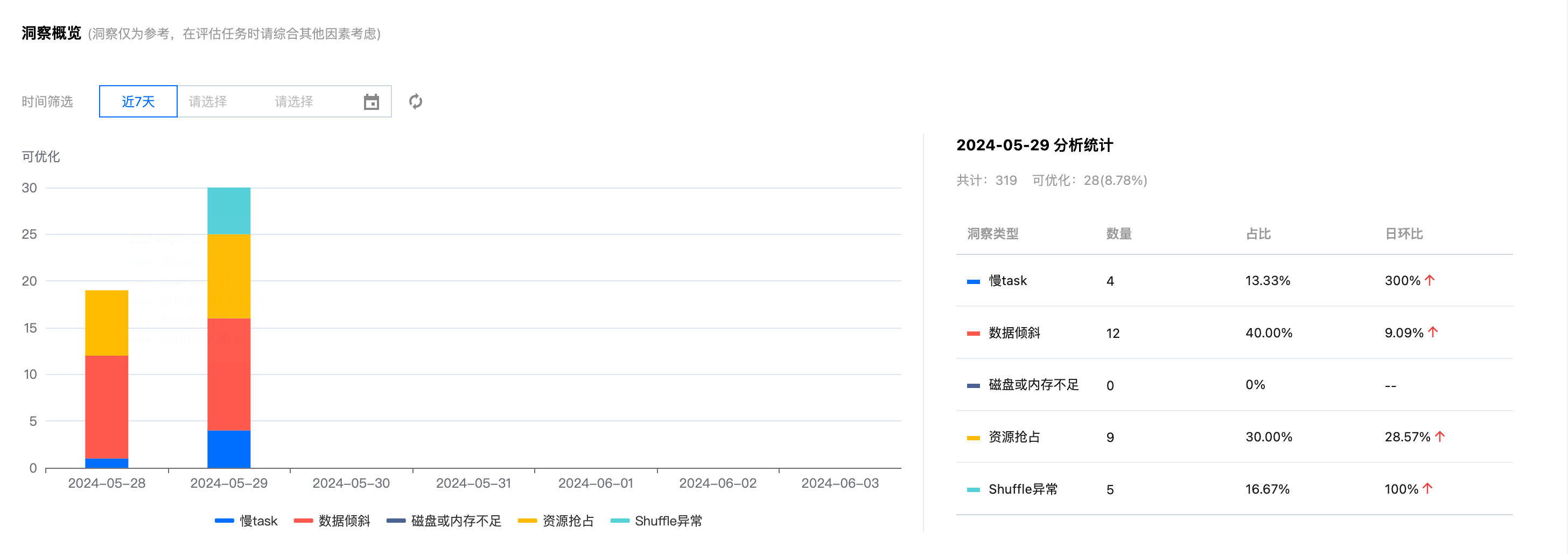
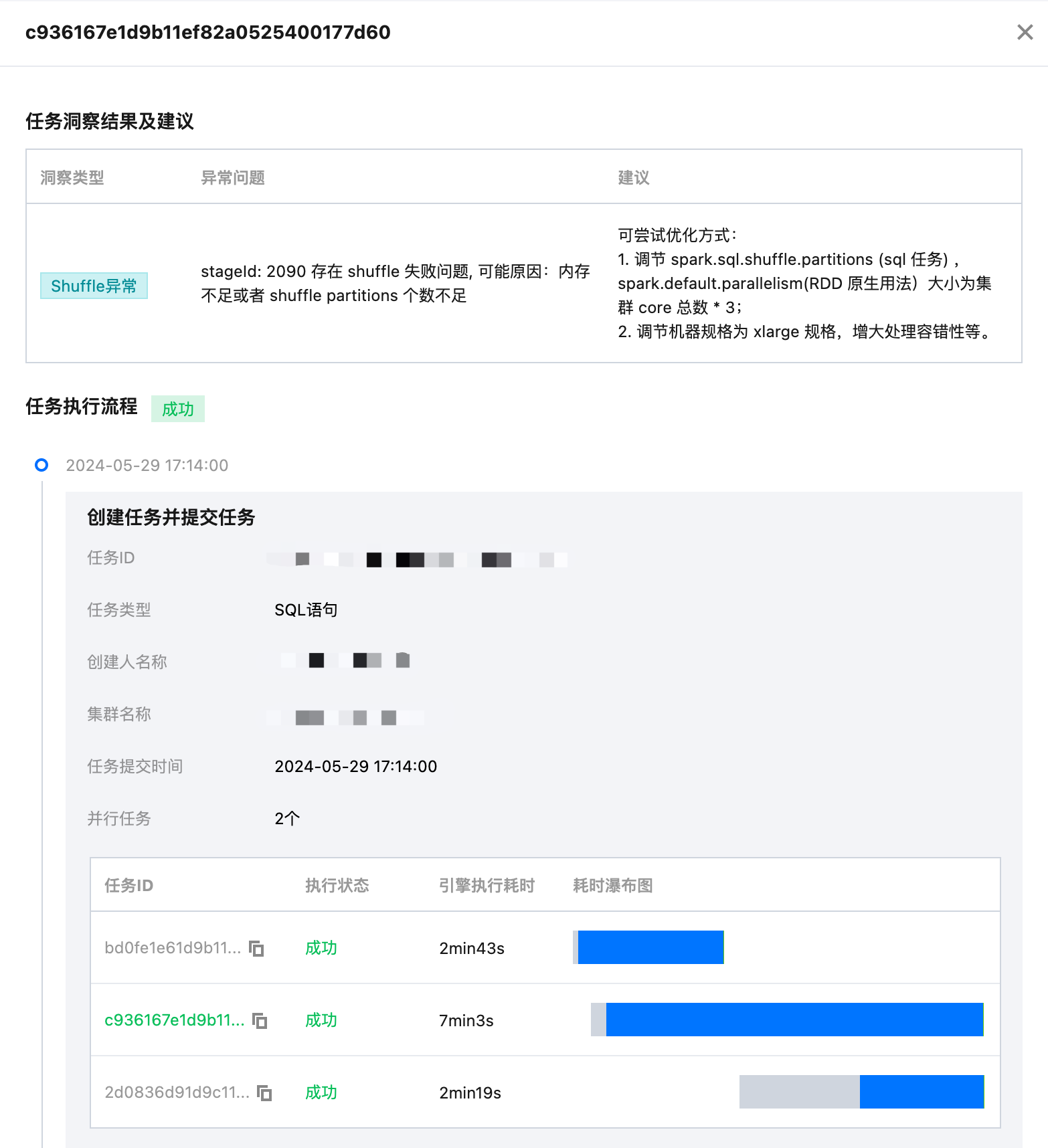
任务洞察
任务洞察功能支持分析每个任务执行过的汇总 metrics 以及洞察出可优化的问题。
当任务执行完成后,用户只需要确认需要洞察的任务,在操作栏点击“任务洞察”即可查看。

根据当前任务的实际执行情况,DLC 任务洞察将结合数据分析及算法规则,给出相应的调优建议。
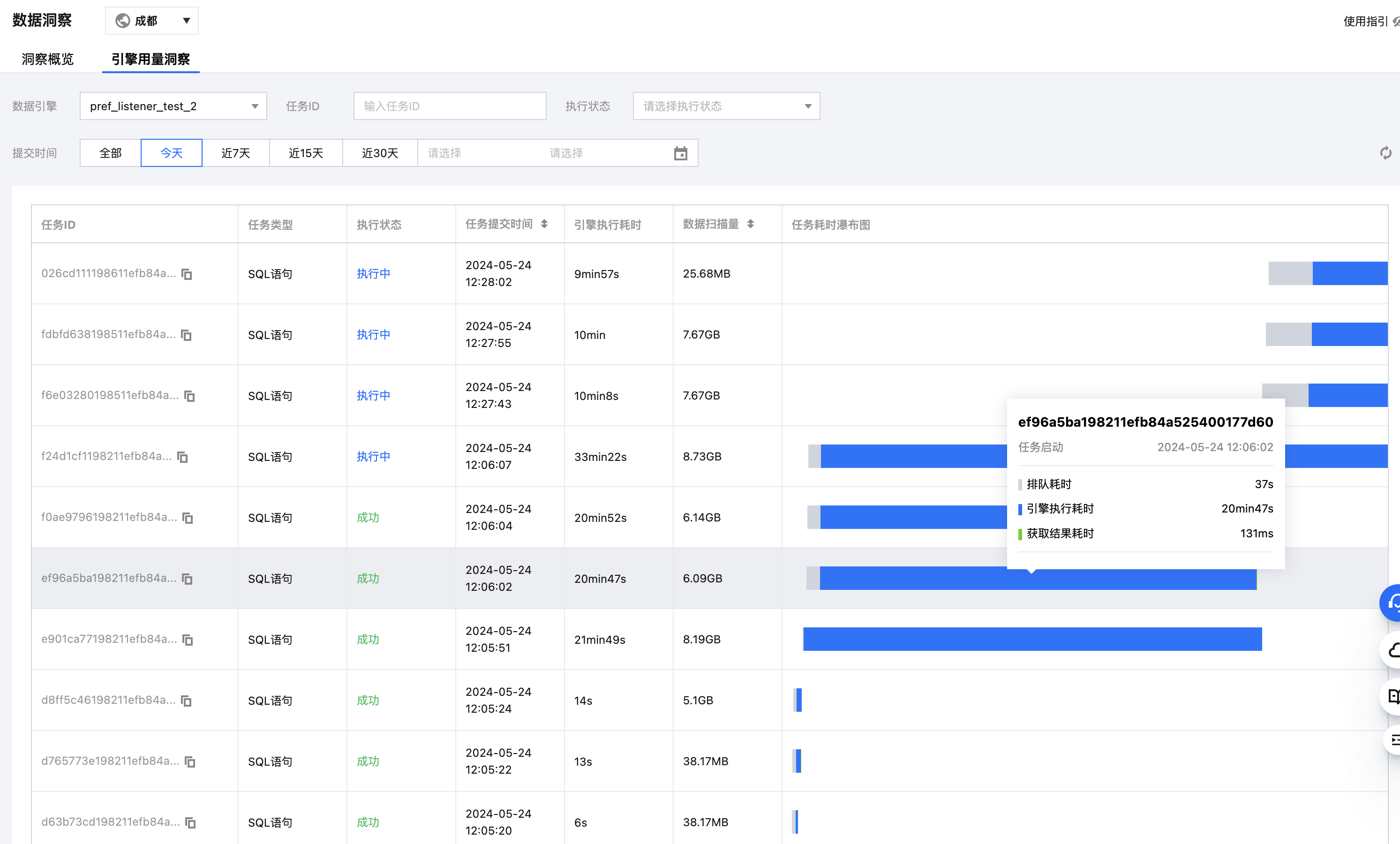
引擎用量洞察
当集群资源紧张时,会出现任务提交到了引擎,却在引擎内排队的情况,但用户无法感知,可能会继续提交任务,导致任务阻塞情况严重。
引擎用量洞察以引擎为维度,把引擎下的所有任务从提交到引擎内执行情况的分布情况统一展示出来,帮助客户可以快速分析引擎的使用大致情况。
注意:实时的引擎执行耗时和数据扫描量数据目前只有 sparkSQL 引擎才有,Spark作业引擎需要等待洞察完成后,才有排队耗时及引擎内执行耗时。
如何开启洞察功能
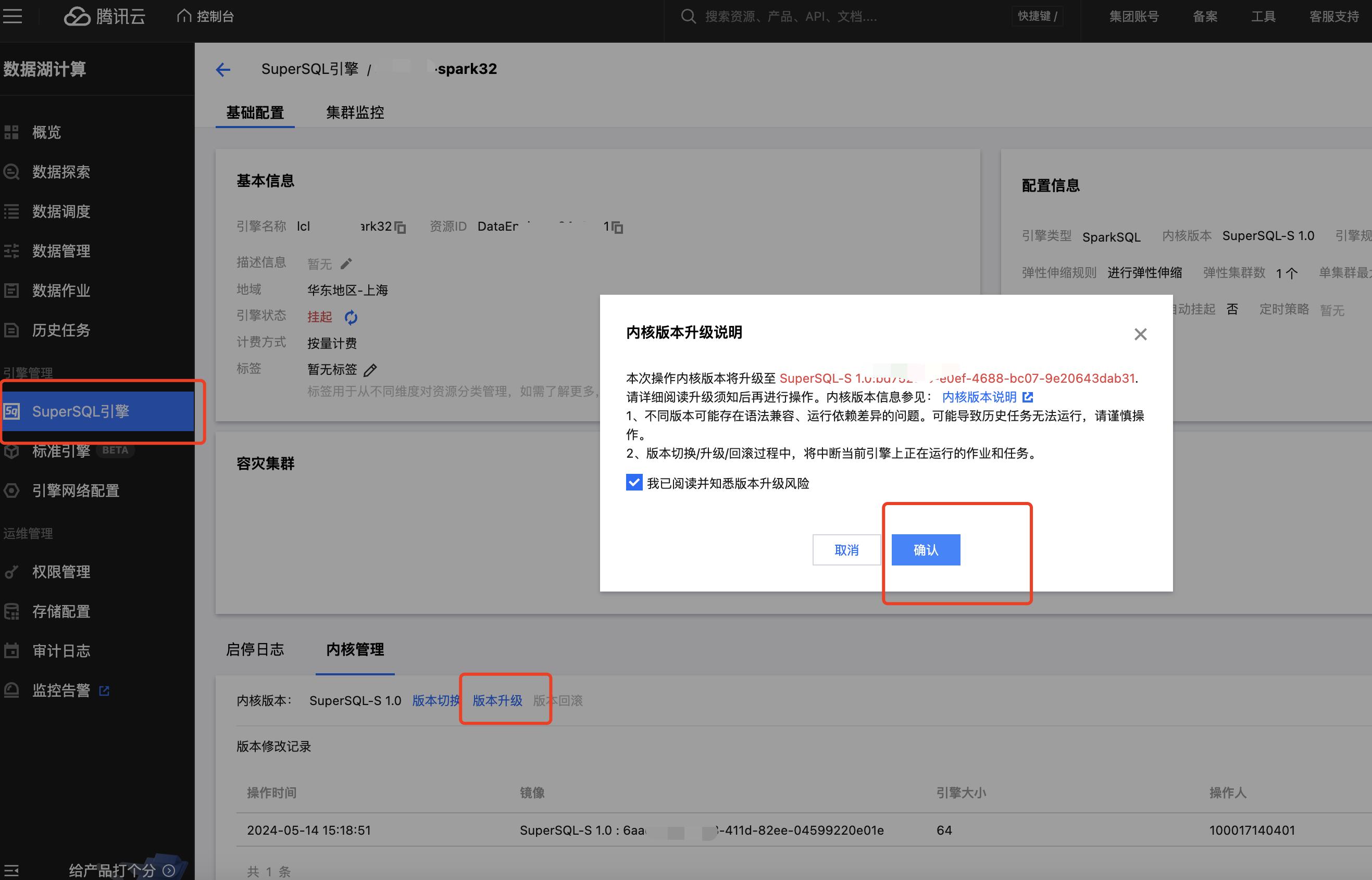
存量 spark 引擎升级 SuperSQL 引擎内核镜像
新购引擎或者 2024.7.18 号后购买的引擎已经自动开启洞察,可跳过本步骤:
进入 SuperSQL 引擎列表页 ,选择需要洞察的引擎名称→内核管理→点击版本升级(默认升级到最新内核)

洞察重点指标概览
指标名称 | 名称描述 |
资源抢占 | sql 开始执行的 task 延迟时间>stage提交时间 1 分钟,或延迟时长超过总运行时长的20% |
shuffle 异常 | stage 执行出现 shuffle 相关错误栈信息 |
慢 task | stage 中 task 时长 > stage 里其他 task 平均时长的 2 倍 |
数据倾斜 | task shuffle 数据 > task 平均 shuffle 数据大小的 2 倍 |
磁盘或内存不足 | stage 执行错误栈信息中包含了 oom 或者 磁盘不足的信息 或者 cos 带宽限制报错 |
引擎执行时间 | 反映了在 Spark 引擎执行的第一个task时间(任务第一次抢占cpu开始执行的时间) |
CU 消耗 | 体现任务真正消耗资源的情况,统计方式是统计所有 spark task executor runtime 累加值,因为每个 Spark 任务都是多 CU 并行执行,由于CU消耗时长是串行叠加的,所以会大于引擎内执行时长 |
数据扫描大小 | spark 每个 stage 的 input bytes 大小汇总 |
输出总大小 | spark 每个 stage 的 output bytes 大小汇总 |
影响数据大小和行数 | 当更新表,影响了多少大小的表数据和行数 |
并行任务 | 展示任务并行执行的情况,方便分析被影响到的任务(最多200条) |

 是
是
 否
否
本页内容是否解决了您的问题?