- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
- 产品简介
- 购买指南
- 快速入门
- 操作指南
- 开发指南
- 客户端访问
- 实践教程
- SQL 语法
- SuperSQL 语法
- SuperSQL 语法概览
- 统一语法
- 常用数据类型
- DDL 语法
- CREATE DATABASE
- SHOW DATABASES
- DESCRIBE DATABASE
- ALTER DATABASE
- DROP DATABASE
- CREATE TABLE
- REPLACE TABLE AS SELECT
- SHOW TABLES
- SHOW CREATE TABLE
- SHOW TBLPROPERTIES
- DESCRIBE TABLE
- SHOW COLUMNS IN TABLE
- ALTER TABLE
- ALTER TABLE ADD COLUMNS
- ALTER TABLE ADD COLUMN AFTER/FIRST
- ALTER TABLE DROP COLUMN
- ALTER TABLE ADD PARTATION
- SHOW PARTITIONS
- ALTER TABLE DROP PARTITION
- ALTER TABLE ADD PARTITION FIELD
- ALTER TABLE DROP PARTITION FIELD
- ALTER TABLE ... RENAME COLUMN
- ALTER TABLE SET TBLPROPERTIES
- ALTER TABLE SET LOCATION
- ALTER TABLE ... WRITE ORDERED BY
- ALTER TABLE ... WRITE DISTRIBUTED BY PARTITION
- ALTER TABLE ... SET IDENTIFIER FIELDS
- ALTER TABLE ... DROP IDENTIFIER FIELDS
- MSCK REPAIR TABLE
- ANALYZE TABLES
- DROP TABLE
- EXPLAIN
- CALL STATEMENT
- CREATE VIEW AS
- SHOW VIEWS
- DESCRIBE VIEW
- SHOW CREATE VIEW
- SHOW COLUMNS IN VIEW
- ALTER VIEW
- DROP VIEW
- CREATE FUNCTION
- SHOW FUNCTION
- DROP FUNCTION
- DML 语法
- DQL 语法
- Iceberg 表语法
- 物化视图语法
- SQL 隐式转换
- 函数
- 标准 Spark 语法概览
- 标准 Presto 语法概览
- 保留字
- SuperSQL 语法
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Data Table APIs
- Task APIs
- CreateSparkSessionBatchSQL
- CancelSparkSessionBatchSQL
- CancelTask
- CreateResultDownload
- CreateSparkAppTask
- CreateTask
- CreateTasks
- DeleteSparkApp
- DescribeEngineUsageInfo
- DescribeResultDownload
- DescribeSparkAppTasks
- DescribeTaskResult
- DescribeTasks
- QueryTaskCostDetail
- CreateSparkApp
- DescribeSparkAppJob
- DescribeSparkSessionBatchSqlLog
- ModifySparkApp
- DescribeSparkAppJobs
- ModifySparkAppBatch
- DescribeTaskStatistics
- DescribeQuery
- DescribeJobs
- DescribeJob
- Metadata APIs
- Service Configuration APIs
- CreateCHDFSBindingProduct
- DeleteCHDFSBindingProduct
- DescribeOtherCHDFSBindingList
- CreateStoreLocation
- DescribeStoreLocation
- ModifyDataEngineDescription
- RollbackDataEngineImage
- SwitchDataEngine
- SwitchDataEngineImage
- UpgradeDataEngineImage
- DeleteThirdPartyAccessUser
- DescribeDataEngineImageVersions
- DescribeSubUserAccessPolicy
- DescribeThirdPartyAccessUser
- RegisterThirdPartyAccessUser
- RestartDataEngine
- UpdateUserDataEngineConfig
- UpdateDataEngineConfig
- Permission Management APIs
- AddUsersToWorkGroup
- AttachUserPolicy
- AttachWorkGroupPolicy
- BindWorkGroupsToUser
- CreateUser
- CreateWorkGroup
- DeleteUser
- DeleteUsersFromWorkGroup
- DeleteWorkGroup
- DescribeUserInfo
- DescribeUserRoles
- DescribeUserType
- DescribeUsers
- DescribeWorkGroupInfo
- DescribeWorkGroups
- DetachUserPolicy
- DetachWorkGroupPolicy
- ModifyUser
- ModifyUserType
- ModifyWorkGroup
- UnbindWorkGroupsFromUser
- UpdateRowFilter
- CheckGrantedPermission
- Database APIs
- Data Source Connection APIs
- Data Optimization APIs
- Data Engine APIs
- Data Types
- Error Codes
- 通用类参考
- DLC 政策
- 服务等级协议
- 联系我们
概述
DLC 原生表(Iceberg)是基于 Iceberg 湖格式打造的性能强、易用性高、操作使用简单的表格式,用户可在该基础上完整数据探索,建设 Lakehouse 等应用。用户首次在使用 DLC 原生表(Iceberg)时需要按照如下5个主要步骤进行:
1. 开通 DLC 托管存储。
2. 购买引擎。
3. 创建数据库表。结合使用场景,选择创建 append 或者 upsert 表,并携带优化参数。
4. 配置数据优化。结合表类型,选择独立的优化引擎,配置优化选项。
5. 导入数据到 DLC 原生表。DLC 支持多种数据写入,如 insert into/merge into/upsert,支持多种导入方式,如 spark/presto/flink/inlong/oceanus。
Iceberg 原理解析
DLC 原生表(Iceberg)采用 Iceberg 表格式作为底层存储,在兼容开源 Iceberg 能力的基础上,还做了存算分离性能、易用性增强。
Iceberg 表格式通过划分数据文件和元数据文件管理用户的数据。
数据层(data layer):由一系列 data file 组成,用于存放用户表的数据,data file 支持 parquet、avro、orc 格式,DLC 中默认为 parquet 格式。
由于 iceberg 的快照机制,用户在删除数据时,并不会立即将数据从存储上删除,而是写入新的 delete file,用于记录被删除的数据,根据使用的不同,delete file 分为 position delete file 和 equality delete file。
position delete 是位置删除文件,记录某个 data file 的某一行被删除的信息。
equality delete 为等值删除文件,记录某个 key 的值被删除,通常用在 upsert 写入场景。delete file 也属于 data file 的一种类型。
元数据层(metadata layer):由一系列的 manifest、manifest list、metadata 文件组成,manifest file 包含一系列的 data file 的元信息,如文件路径、写入时间、min-max 值、统计值等信息。
manifest list 由 manifest file组成,通常一个 manifest list 包含一个快照的 manifest file。
metadata file 为 json 格式,包含一些列的 manifest list 文件信息和表的元信息,如表 schema、分区、所有快照等。每当表状态发生变化时,都会产生一个新的 metadata file 覆盖原有 metadata 文件,且该过程有 Iceberg 内核的原子性保证。
原生表使用场景
DLC 原生表(iceberg)作为 DLC lakehouse 主推格式,从使用场景上,可分为 Append 场景表和 Upsert 表,Append 场景表采用的V1格式,Upsert 表采用的V2格式。
Append 场景表:该场景表仅支持 Append,Overwrite,Merge into 方式写入。
Upsert 场景表:相比 Append,写入能力相比多一种 Upsert 写入模式。
原生表使用场景及特点汇总如下表描述。
表类型 | 使用场景及建议 | 特点 |
原生表(iceberg) | 1. 用户有实时写入需求,包括 append/merge into/upsert 场景需求,不限于 inlong/oceans/自建flink 实时写入。 2. 用户不想直接管理存储相关的运维,交给 DLC 存储托管。 3. 用户不想对 Iceberg 表格式进行运维,交给 DLC 进行调优和运维。 4. 希望使用 DLC 提供的自动数据优化能力,持续对数据进行优化。 | 1. Iceberg 表格式。 2. 使用前需要开通托管存储。 3. 数据存储存储在 DLC 提供的托管存储上。 4. 不需要指定 external、location 等信息。 5. 支持开启 DLC 智能数据优化。 |
为更好的管理和使用 DLC 原生表(Iceberg),您创建该类型的表时需要携带一些属性,这些属性参考如下。用户在创建表时可以携带上这些属性值,也可以修改表的属性值,详细的操作请参见 DLC 原生表操作配置。
属性值 | 含义 | 配置指导 |
format-version | iceberg 表版本,取值范围1、2,默认取值为1 | 如果用户写入场景有 upsert,该值必须设置为2 |
write.upsert.enabled | 是否开启 upsert,取值为true;不设置则为不开启 | 如果用户写入场景有 upsert,必须设置为 true |
write.update.mode | 更新模式 | merge-on-read 指定为 MOR 表,缺省为 COW |
write.merge.mode | merge 模式 | merge-on-read 指定为 MOR 表,缺省为 COW |
write.parquet.bloom-filter-enabled.column.{col} | 开启 bloom,取值为 true 表示开启,缺省不开启 | upsert 场景必须开启,需要根据上游的主键进行配置;如上游有多个主键,最多取前两个;开启后可提升 MOR 查询和小文件合并性能 |
write.distribution-mode | 写实模式 | 建议取值为 hash,当取值为 hash 时,当数据写入时会自行进行 repartition,缺点是影响部分写入性能 |
write.metadata.delete-after-commit.enabled | 开始 metadata 文件自动清理 | 强烈建议设置为 true,开启后 iceberg 在产生快照时会自动清理历史的 metadata 文件,可避免大量的 metadata 文件堆积 |
write.metadata.previous-versions-max | 设置默认保留的 metadata 文件数量 | 默认值为100,在某些特殊的情况下,用户可适当调整该值,需要配合 write.metadata.delete-after-commit.enabled 一起使用 |
write.metadata.metrics.default | 设置列 metrices 模型 | 必须取值为 full |
原生表核心能力
存储托管
DLC 原生表(Iceberg)采用了存储数据托管模式,用户在使用原生表(Iceberg)时,需要先开通托管存储,将数据导入到 DLC 托管的存储空间。用户采用 DLC 存储托管,将获得如下收益。
数据更安全:Iceberg 表数据分为元数据和数据两个部分,一点某系文件被破坏,将导致整个表查询异常(相比于 Hive 可能是损坏的文件数据不能查询),存储托管在 DLC 可减少用户在不理解 Iceberg 的情况下对某些文件进行破坏。
性能:DLC 存储托管默认采用 chdfs 作为存储,相比于普通 COS,性能有较大的提升。
减少存储方面的运维:用户采用存储托管后,可不用再开通及运维对象存储,能减少存储的运维。
数据优化:DLC 元生表(Iceberg)采用存储托管模式,DLC 提供的数据优化能针对元生表持续优化。
ACID 事务
Iceberg 写入支持在单个操作中删除和新增,且不会部分对用户可见,从而提供原子性写入操作。
Iceberg 使用乐观并发锁来确保写入数据不会导致数据不一致,用户只能看到读视图中已经提交成功的数据。
Iceberg 使用快照机制和可序列化隔离级确保读取和写入是隔离的。
Iceberg 确保事务是持久化的,一旦移交成功就是永久性的。
写入
写入过程遵循乐观并发控制,写入者首先假设当前表版本在提交更新之前不会发生变更,对表数据进行更新/删除/新增,并创建新版本的元数据文件,之后尝试替换当前版本的元数据文件到新版本上来,但是在替换过程中,Iceberg 会检查当前的更新是否是基于当前版本的快照进行的,
如果不是则表示发生了写冲突,有其他写入者先更新了当前 metadata,此时写入必须基于当前的 metadata 版本从新更新,之后再次提交更新,整个提交替换过程由元数据锁保证操作的原子性。
读取
Iceberg 读取和写入是独立的过程,读者始终只能看到已经提交成功的快照,通过获取版本的 metadata 文件,获取的快照信息,从而读取当前表的数据,由于在未完成写入时,并不会更新 metadata 文件,从而确保始终从已经完成的操作中读取数据,无法从正在写入的操作中获取数据。
冲突参数配置
DLC 托管表(Iceberg)在写入并发变高时将会触发写入冲突,为降低冲突频率,用户可从如下方面对业务进行合理的调整。
进入合并的表结构设置,如分区,合理规划作业写入范围,减少任务写入时间,在一定程度上降低并发冲突概率。
作业进行一定程度的合并,减小写入并发量。
DLC 还支持一些列冲突并发重试的参数设置,在一定程度可提供重试操作的成功率,减小对业务的影响,参数含义及配置指导如下。
属性值 | 系统默认值 | 含义 | 配置指导 |
commit.retry.num-retries | 4 | 提交失败后的重试次数 | 发生重试时,可尝试提大次数 |
commit.retry.min-wait-ms | 100 | 重试前的最小等待时间,单位为毫秒 | 当时冲突十分频繁,如等待一段时间后依然冲突,可尝试调整该值,加大重试之间的间隔 |
commit.retry.max-wait-ms | 60000(1 min) | 重试前的最大等待时间,单位为毫秒 | 结合commit.retry.min-wait-ms一起调整使用 |
commit.retry.total-timeout-ms | 1800000(30 min) | 整个重试提交的超时时间 | - |
隐藏式分区
DLC 原生表(Iceberg)隐藏分区是将分区信息隐藏起来,开发人员只需要在建表的时候指定分区策略,Iceberg 会根据分区策略维护表字段与数据文件之间的逻辑关系,在写入和查询时无需关注分区布局,Iceberg 在写入数据是根据分区策略找到分区信息,并将其记录在元数据中,查询时也会更具元数据记录过滤到不需要扫描的文件。DLC 原生表(Iceberg)提供的分区策略如下表所示。
转换策略 | 描述 | 原始字段类型 | 转换后类型 |
identity | 不转换 | 所有类型 | 与原类型一致 |
bucket[N, col] | hash分桶 | int, long, decimal, date, time, timestamp, timestamptz, string, uuid, fixed, binary | int |
truncate[col] | 截取固定长度 | int, long, decimal, string | 与原类型一致 |
year | 提取字段 year 信息 | date, timestamp, timestamptz | int |
month | 提取字段 mouth 信息 | date, timestamp, timestamptz | int |
day | 提取字段 day 信息 | date, timestamp, timestamptz | int |
hour | 提取字段 hour 信息 | timestamp, timestamptz | int |
元数据查询和存储过程
DLC 原生表(Iceberg)可调用存储过程语句查询各类型表信息,如文件合并、快照过期等,如下表格提供部分常用的查询方法。
场景 | CALL 语句 | 执行引擎 |
查询 history | select * from DataLakeCatalog.db.sample$history | DLC spark SQL 引擎、presto 引擎 |
查询快照 | select * from DataLakeCatalog.db.sample$snapshots | DLC spark SQL 引擎、presto 引擎 |
查询 data 文件 | select * from DataLakeCatalog.db.sample$files | DLC spark SQL 引擎、presto 引擎 |
查询manifests | select * from DataLakeCatalog.db.sample$manifests | DLC spark SQL 引擎、presto 引擎 |
查询分区 | select * from DataLakeCatalog.db.sample$partitions | DLC spark SQL 引擎、presto 引擎 |
回滚指定快照 | CALL DataLakeCatalog. system.rollback_to_snapshot('db.sample', 1) | DLC spark SQL 引擎 |
回滚到某个时间点 | CALL DataLakeCatalog. system.rollback_to_timestamp('db.sample', TIMESTAMP '2021-06-30 00:00:00.000') | DLC spark SQL 引擎 |
设置当前快照 | CALL DataLakeCatalog. system.set_current_snapshot('db.sample', 1) | DLC spark SQL 引擎 |
合并文件 | CALL DataLakeCatalog. system.rewrite_data_files(table => 'db.sample', strategy => 'sort', sort_order => 'id DESC NULLS LAST,name ASC NULLS FIRST') | DLC spark SQL 引擎 |
快照过期 | CALL DataLakeCatalog. system.expire_snapshots('db.sample', TIMESTAMP '2021-06-30 00:00:00.000', 100) | DLC spark SQL 引擎 |
移除孤立文件 | CALL DataLakeCatalog. system.remove_orphan_files(table => 'db.sample', dry_run => true) | DLC spark SQL 引擎 |
重新元数据 | CALL DataLakeCatalog. system.rewrite_manifests('db.sample') | DLC spark SQL 引擎 |
数据优化
优化策略
数据目录配置优化策略:该数据目录下的所有库下的所有的原生表(Iceberg)默认复用该数据目录优化策略。
数据库配置优化策略:该数据库下的所有原生表(Iceberg)默认复用该数据库优化策略。
数据表配置优化策略:该配置仅针对配置的原生表(Iceberg)生效。
用户通过上面的组合配置,可实现针对某库某表定制化优化策略,或者某些表关闭策略。
DLC 针对优化策略还提供高级参数配置,如用户对Iceberg熟悉可根据实际场景定制化高级参数,如下图所示。
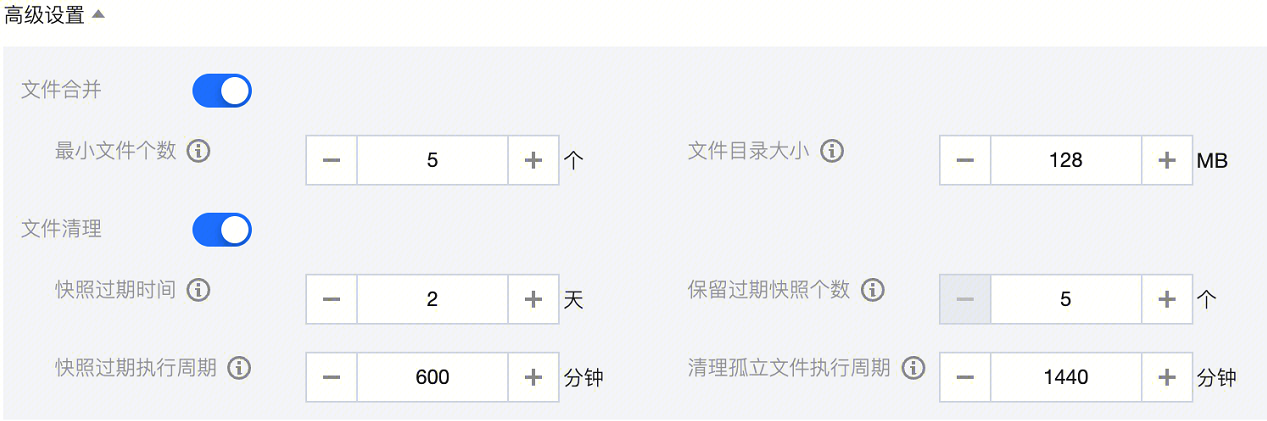
DLC 针对高级参数设置了默认值。DLC 会将文件尽可能合并到128M大小,快照过期时间为2天,保留过期的5个快照,快照过期和清理孤立文件的执行周期分别为600分钟和1440分钟。
针对 upsert 写入场景,DLC 默认还提供合并阈值,该部分参数由 DLC 提供,在超过5min的时间新写入的数据满足其中一个条件将会触发小文件合并,如表所示。
参数 | 含义 | 取值 |
AddDataFileSize | 写入新增数据文件数量 | 20 |
AddDeleteFileSize | 写入新增Delete文件数据量 | 20 |
AddPositionDeletes | 写入新增Position Deletes记录数量 | 1000 |
AddEqualityDeletes | 写入新增Equality Deletes记录数量 | 1000 |
优化引擎
DLC 数据优化通过执行存储过程完成对数据的优化,因此需要数据引擎用于执行存储过程。当前 DLC 支持使用 Spark SQL 引擎作为优化引擎,在使用时需注意如下几点:
数据优化的 Spark SQL 引擎与业务引擎分开使用,可避免数据优化任务与业务任务相互抢占资源,导致任务大量排队和业务受阻。
生产场景建议优化资源64CU起,除非量特性表,如果小于10张表且单表数据量超过2G,建议资源开启弹性,防止突发流量,建议采用包年包月集群,防止提交任务时集群不可用导致优化任务失败。
参数定义
数据库、数据表数据优化参数设置在库表属性上,用户可以通过创建库、表时携带数据优化参数(DLC 原生表提供的可视化创建库表用户可配置数据优化);用户也可通过 ALTER DATABASE/TABLE 对表数据进行表更,修改数据优化参数详细的操作请参见 DLC 原生表操作配置。
属性值 | 含义 | 默认值 | 取值说明 |
smart-optimizer.inherit | 是否继承上一级策略 | default | none:不继承;default:继承 |
smart-optimizer.written.enable | 是否开启写入优化 | disable | disable:不开启;enable:开启。默认不开启 |
smart-optimizer.written.advance.compact-enable | (可选)写入优化高级参数,是否开始小文件合并 | enable | disable:不开启;enable:开启。 |
smart-optimizer.written.advance.delete-enable | (可选)写入优化高级参数,是否开始数据清理 | enable | disable:不开启;enable:开启。 |
smart-optimizer.written.advance.min-input-files | (可选)合并最小输入文件数量 | 5 | 当某个表或分区下的文件数目超过最小文件个数时,平台会自动检查并启动文件优化合并。文件优化合并能有效提高分析查询性能。最小文件个数取值较大时,资源负载越高,最小文件个数取值较小时,执行更灵活,任务会更频繁。建议取值为5。 |
smart-optimizer.written.advance.target-file-size-bytes | (可选)合并目标大小 | 134217728 (128 MB) | 文件优化合并时,会尽可能将文件合并成目标大小,建议取值128M。 |
smart-optimizer.written.advance.before-days | (可选)快照过期时间,单位天 | 2 | 快照存在时间超过该值时,平台会将该快照标记为过期的快照。快照过期时间取值越长,快照清理的速度越慢,占用存储空间越多。 |
smart-optimizer.written.advance.retain-last | (可选)保留过期快照数量 | 5 | 超过保留个数的过期快照将会被清理。保留的过期快照个数越多,存储空间占用越多。建议取值为5。 |
smart-optimizer.written.advance.expired-snapshots-interval-min | (可选)快照过期执行周期 | 600(10 hour) | 平台会周期性扫描快照并过期快照。执行周期越短,快照的过期会更灵敏,但是可能消耗更多资源。 |
smart-optimizer.written.advance.remove-orphan-interval-min | (可选)移除孤立文件执行周期 | 1440(24 hour) | 平台会周期性扫描并清理孤立文件。执行周期越短,清理孤立文件会更灵敏,但是可能消耗更多资源。 |
优化类型
当前 DLC 提供写入优化和数据清理两种类型,写入优化对用户写入的小文件进行合并更大的文件,从而提供查询效率;数据清理则是清理历史过期快照的存储空间,节约存储成本。
写入优化
小文件合并:将业务侧写入的小文件合并为更大的文件,提升文件查询效率;处理写入的deletes文件和data文件合并,提升MOR查询效率。
数据清理
快照过期:执行删除过期的快照信息,释放历史数据占据的存储空间。
移除孤立文件:执行移除孤立文件,释放无效文件占据的存储空间。
根据用户的使用场景,在优化类型上有一定差异,如下所示。
优化类型 | 建议开启场景 |
写入优化 | upsert 写场景:必须开启 merge into 写场景:必须开启 append 写入场景:按需开启 |
数据清理 | upsert 写场景:必须开启 merge into 写入场景:必须开启 append 写入场景:建议开启,并结合高级参数及历史数据回溯需求配置合理的过期删除时间 |
DLC 的写入优化不仅完成小文件的合并,还可以提供手动构建索引,用户需要提供索引的字段及规则,之后 DLC 将产生对应的存储过程执行语句,从而完成索引的构建。该能在 upsert 场景和结合小文件合并同时进行,完成小文件合并的时候即可完成索引构建,大大提高索引构建能力。
优化任务
DLC 优化任务产生有时间和事件两种方式。
时间触发
时间触发是优化高级参数配置的执行时间,周期性地触发检查是否需要优化,如对应治理项满足条件后,将会产生对应的治理任务。当前时间触发的周期至少是60min,通常用在清理快照和移除孤立文件。
时间触发针对小文件合并类型的优化任务仍然有效,当时触发周期默认为60min。
V1表(需后端开启)情况,每60min触发一次小文件合并。
V2表情况,防止表写入慢,长时间达不到事件触发条件,当时间触发V2进行小文件合并时,需要满足上一次小文件合并时间间隔超过1小时。
当快照过期和移除孤立文件任务执行失败或者超时时,在下一个检查周期会再次执行,检查周期为60min。
事件触发
事件触发发生了表 Upsert 写入场景,主要是 DLC 数据优化服务后台会监控用户表数据的 Upsert 表写入的情况,当写的达到对应的条件时,触发产生治理任务。事件触发用在小文件并场景,特别是 flink upsert 实时写入场景,数据写入快,频繁产生小文件合并任务。
如数据文件阈值20,deletes 文件阈值20,则写入20个文件或者20个 deletes 文件,并同时满足相同任务类型之间的产生的间隔默认最小时间5min时,就会触发产生小文件合并。
生命周期
DLC 原生表的生命周期(Lifecycle),指表(分区)数据从最后一次更新的时间算起,在经过指定的时间后没有变动,则此表(分区)将被自动回收。DLC 元数据表的生命周期执行时,只是产生新的快覆盖过期的数据,并不会立即将数据从存储空间上移除,数据真正从存储上移除需要依赖于元数据表数据清理(快照过期和移除孤立文件),因此生命周期需要和数据清理一起使用。
注意:
生命周期目前处于邀测阶段,如需要开通,欢迎 联系我们。
生命周期移除分区时只是从当前快照中逻辑移除该分区,但是被移除的文件并不会立即从存储系统中删除,被移除的文件只有等到快照过期才会从存储系统上删除。
参数定义
数据库、数据表生命周期参数设置在库表属性上,用户可以通过创建库、表时携带生命周期参数(DLC 原生表提供的可视化创建库表用户可配置生命周期);用户也可通过 ALTER DATABASE/TABLE 对表数据进行表更改,修改生命周期参数详细的操作请参见 DLC 原生表操作配置。
属性值 | 含义 | 默认值 | 取值说明 |
smart-optimizer.lifecycle.enable | 是否开启生命周期 | disable | disable:不开启;enable:开启。默认不开启 |
smart-optimizer.lifecycle.expiration | 生命周期实现周期,单位:天 | 30 | 当 smart-optimizer.lifecycle.enable 取值为 enable 时生效,需大于1 |
结合 WeData 管理原生表生命周期
如果用户分区表的按照天分区,如分区值为yyyy-MM-dd或者yyyyMMdd的分区值,可配合WeData完成数据生命周期管理。
数据导入
DLC 原生表(Iceberg)支持多种方式的数据导入,根据数据源不同,可参考如下方式进行导入。
数据位置 | 导入建议 |
数据在用户自己的 COS 桶上 | 通过在 DLC 建立外部表,之后通过 Insert into/overwrite 的方式导入 |
数据在用户本地(或者其他执行机上) | 用户需要将数据上传到用户自己的 COS 桶上,之后建立 DLC 外部表,通过 insert into/overwrite 的方式导入 |
数据在用户 mysql | |
数据在用户自建 hive 上 | 用户通过建立联邦 hive 数据目录,之后通过 insert into/overwrite 的方式导入 |

 是
是
 否
否
本页内容是否解决了您的问题?