- 产品简介
- 购买指南
- 准备工作
- 操作指南
- 管理控制台
- 项目管理
- 数据集成
- 数据集成概述
- 支持的数据源与读写能力
- 集成资源配置与管理
- 实时同步任务配置与运维
- 离线同步任务配置与运维
- 离线同步支持的数据源
- 数据源一览
- 数据源列表
- MySQL 数据源
- TDSQL-C MySQL 数据源
- Oracle 数据源
- SQL Server 数据源
- PostgreSQL 数据源
- TDSQL-PostgreSQL 数据源
- TDSQL MySQL 数据源
- DB2 数据源
- 达梦 DM 数据源
- OceanBase 数据源
- SAP HANA 数据源
- SAP IQ(Sybase) 数据源
- Doris/TCHouse-D 数据源
- StarRocks 数据源
- DLC 数据源
- Iceberg 数据源
- TCHouse-P 数据源
- ClickHouse 数据源
- Greenplum 数据源
- Hive 数据源
- HDFS 数据源
- HBase 数据源
- TBase 数据源
- GBase 数据源
- GaussDB 数据源
- Impala 数据源
- Kudu 数据源
- FTP 数据源
- COS 数据源
- SFTP 数据源
- Rest API 数据源
- Elasticsearch/腾讯云 Elasticsearch 数据源
- Mongo/腾讯云 Mongo 数据源
- Redis 数据源
- Kafka/CKafka 数据源
- CTSDB influxDB 数据源
- TDMQ Pulsar 数据源
- 数据集成离线同步配置与运维
- 数据开发离线同步配置与运维
- 转换节点配置
- 时间参数说明
- 离线节点高级参数
- 离线同步支持的数据源
- 同步任务自动建表能力
- 常见问题
- 数据开发
- 数据资产
- 数据质量
- 数据安全
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- DeleteProjectParamDs
- CreateWorkflowDs
- CreateTaskVersionDs
- RemoveWorkflowDs
- TriggerDsEvent
- DeleteTaskDs
- DescribeBatchOperateTask
- DeleteFilePath
- GetFileInfo
- FindAllFolder
- CreateTaskFolder
- MoveTasksToFolder
- DescribeDsFolderTree
- DeleteFile
- UploadContent
- SubmitSqlTask
- SubmitTaskTestRun
- DeleteResource
- DescribeResourceManagePathTrees
- CreateCustomFunction
- DeleteCustomFunction
- DescribeFunctionKinds
- DescribeFunctionTypes
- DescribeOrganizationalFunctions
- SaveCustomFunction
- SubmitCustomFunction
- CreateDsFolder
- DeleteDsFolder
- DescribeDsParentFolderTree
- ModifyDsFolder
- DeleteResourceFile
- DeleteResourceFiles
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operation and Maintenance APIs
- FreezeTasksByWorkflowIds
- DeleteWorkflowById
- DescribeDependTaskLists
- DescribeWorkflowExecuteById
- DescribeWorkflowTaskCount
- DescribeWorkflowListByProjectId
- DescribeWorkflowInfoById
- UpdateWorkflowOwner
- RunRerunScheduleInstances
- DescribeWorkflowCanvasInfo
- DescribeAllByFolderNew
- DescribeTaskRunHistory
- RunForceSucScheduleInstances
- KillScheduleInstances
- RunTasksByMultiWorkflow
- DescribeTaskByStatusReport
- DescribeStatisticInstanceStatusTrendOps
- DescribeOpsWorkflows
- DescribeSchedulerTaskTypeCnt
- BatchStopWorkflowsByIds
- DescribeInstanceByCycle
- DescribeTaskByCycleReport
- DescribeSchedulerInstanceStatus
- DescribeScheduleInstances
- CreateOpsMakePlan
- DescribeSchedulerTaskCntByStatus
- DescribeSchedulerRunTimeInstanceCntByStatus
- DescribeOpsMakePlanInstances
- DescribeOpsMakePlanTasks
- DescribeOpsMakePlans
- KillOpsMakePlanInstances
- BatchDeleteOpsTasks
- DescribeFolderWorkflowList
- DescribeTaskScript
- ModifyTaskInfo
- ModifyTaskLinks
- ModifyTaskScript
- ModifyWorkflowSchedule
- RegisterEvent
- RegisterEventListener
- SetTaskAlarmNew
- SubmitTask
- SubmitWorkflow
- TriggerEvent
- BatchModifyOpsOwners
- BatchStopOpsTasks
- CountOpsInstanceState
- DescribeDependOpsTasks
- DescribeOperateOpsTasks
- DescribeSuccessorOpsTaskInfos
- FreezeOpsTasks
- CreateTask
- ModifyWorkflowInfo
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- CommitRuleGroupTask
- CreateRule
- CreateRuleTemplate
- DeleteRule
- DeleteRuleTemplate
- DescribeDataCheckStat
- DescribeDimensionScore
- DescribeExecStrategy
- DescribeQualityScore
- DescribeQualityScoreTrend
- DescribeRule
- DescribeRuleDimStat
- DescribeRuleExecDetail
- DescribeRuleExecLog
- DescribeRuleExecResults
- DescribeRuleExecStat
- DescribeRuleGroup
- DescribeRuleGroupExecResultsByPage
- DescribeRuleGroupSubscription
- DescribeRuleGroupTable
- DescribeRuleGroupsByPage
- DescribeRuleTemplate
- DescribeRuleTemplates
- DescribeRules
- DescribeRulesByPage
- DescribeTableQualityDetails
- DescribeTableScoreTrend
- DescribeTemplateDimCount
- DescribeTopTableStat
- DescribeTrendStat
- ModifyDimensionWeight
- ModifyExecStrategy
- ModifyMonitorStatus
- ModifyRule
- ModifyRuleGroupSubscription
- ModifyRuleTemplate
- DataInLong APIs
- BatchCreateIntegrationTaskAlarms
- BatchDeleteIntegrationTasks
- BatchForceSuccessIntegrationTaskInstances
- BatchKillIntegrationTaskInstances
- BatchMakeUpIntegrationTasks
- BatchRerunIntegrationTaskInstances
- BatchResumeIntegrationTasks
- BatchStartIntegrationTasks
- BatchStopIntegrationTasks
- BatchSuspendIntegrationTasks
- BatchUpdateIntegrationTasks
- CheckAlarmRegularNameExist
- CheckIntegrationNodeNameExists
- CheckIntegrationTaskNameExists
- CheckTaskNameExist
- CommitIntegrationTask
- CreateHiveTable
- CreateHiveTableByDDL
- CreateIntegrationNode
- CreateIntegrationTask
- CreateTaskAlarmRegular
- DeleteIntegrationNode
- DeleteIntegrationTask
- DeleteOfflineTask
- DeleteTaskAlarmRegular
- DescribeAlarmEvents
- DescribeAlarmReceiver
- DescribeInstanceLastLog
- DescribeInstanceList
- DescribeInstanceLog
- DescribeInstanceLogList
- DescribeIntegrationNode
- DescribeIntegrationStatistics
- DescribeIntegrationStatisticsInstanceTrend
- DescribeIntegrationStatisticsRecordsTrend
- DescribeIntegrationStatisticsTaskStatus
- DescribeIntegrationStatisticsTaskStatusTrend
- DescribeIntegrationTask
- DescribeIntegrationTasks
- DescribeIntegrationVersionNodesInfo
- DescribeOfflineTaskToken
- DescribeRealTimeTaskInstanceNodeInfo
- DescribeRealTimeTaskSpeed
- DescribeRuleTemplatesByPage
- DescribeStreamTaskLogList
- DescribeTaskAlarmRegulations
- DescribeTaskLockStatus
- DryRunDIOfflineTask
- GenHiveTableDDLSql
- GetIntegrationNodeColumnSchema
- GetOfflineDIInstanceList
- GetOfflineInstanceList
- LockIntegrationTask
- ModifyIntegrationNode
- ModifyIntegrationTask
- ModifyTaskAlarmRegular
- ModifyTaskName
- ResumeIntegrationTask
- RobAndLockIntegrationTask
- StartIntegrationTask
- StopIntegrationTask
- SuspendIntegrationTask
- TaskLog
- UnlockIntegrationTask
- CreateOfflineTask
- DescribeRealTimeTaskMetricOverview
- Platform management related APIs
- Data Source Management APIs
- Data Types
- Error Codes
- 服务等级协议
- 相关协议
- 联系我们
- 词汇表
- 产品简介
- 购买指南
- 准备工作
- 操作指南
- 管理控制台
- 项目管理
- 数据集成
- 数据集成概述
- 支持的数据源与读写能力
- 集成资源配置与管理
- 实时同步任务配置与运维
- 离线同步任务配置与运维
- 离线同步支持的数据源
- 数据源一览
- 数据源列表
- MySQL 数据源
- TDSQL-C MySQL 数据源
- Oracle 数据源
- SQL Server 数据源
- PostgreSQL 数据源
- TDSQL-PostgreSQL 数据源
- TDSQL MySQL 数据源
- DB2 数据源
- 达梦 DM 数据源
- OceanBase 数据源
- SAP HANA 数据源
- SAP IQ(Sybase) 数据源
- Doris/TCHouse-D 数据源
- StarRocks 数据源
- DLC 数据源
- Iceberg 数据源
- TCHouse-P 数据源
- ClickHouse 数据源
- Greenplum 数据源
- Hive 数据源
- HDFS 数据源
- HBase 数据源
- TBase 数据源
- GBase 数据源
- GaussDB 数据源
- Impala 数据源
- Kudu 数据源
- FTP 数据源
- COS 数据源
- SFTP 数据源
- Rest API 数据源
- Elasticsearch/腾讯云 Elasticsearch 数据源
- Mongo/腾讯云 Mongo 数据源
- Redis 数据源
- Kafka/CKafka 数据源
- CTSDB influxDB 数据源
- TDMQ Pulsar 数据源
- 数据集成离线同步配置与运维
- 数据开发离线同步配置与运维
- 转换节点配置
- 时间参数说明
- 离线节点高级参数
- 离线同步支持的数据源
- 同步任务自动建表能力
- 常见问题
- 数据开发
- 数据资产
- 数据质量
- 数据安全
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- DeleteProjectParamDs
- CreateWorkflowDs
- CreateTaskVersionDs
- RemoveWorkflowDs
- TriggerDsEvent
- DeleteTaskDs
- DescribeBatchOperateTask
- DeleteFilePath
- GetFileInfo
- FindAllFolder
- CreateTaskFolder
- MoveTasksToFolder
- DescribeDsFolderTree
- DeleteFile
- UploadContent
- SubmitSqlTask
- SubmitTaskTestRun
- DeleteResource
- DescribeResourceManagePathTrees
- CreateCustomFunction
- DeleteCustomFunction
- DescribeFunctionKinds
- DescribeFunctionTypes
- DescribeOrganizationalFunctions
- SaveCustomFunction
- SubmitCustomFunction
- CreateDsFolder
- DeleteDsFolder
- DescribeDsParentFolderTree
- ModifyDsFolder
- DeleteResourceFile
- DeleteResourceFiles
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operation and Maintenance APIs
- FreezeTasksByWorkflowIds
- DeleteWorkflowById
- DescribeDependTaskLists
- DescribeWorkflowExecuteById
- DescribeWorkflowTaskCount
- DescribeWorkflowListByProjectId
- DescribeWorkflowInfoById
- UpdateWorkflowOwner
- RunRerunScheduleInstances
- DescribeWorkflowCanvasInfo
- DescribeAllByFolderNew
- DescribeTaskRunHistory
- RunForceSucScheduleInstances
- KillScheduleInstances
- RunTasksByMultiWorkflow
- DescribeTaskByStatusReport
- DescribeStatisticInstanceStatusTrendOps
- DescribeOpsWorkflows
- DescribeSchedulerTaskTypeCnt
- BatchStopWorkflowsByIds
- DescribeInstanceByCycle
- DescribeTaskByCycleReport
- DescribeSchedulerInstanceStatus
- DescribeScheduleInstances
- CreateOpsMakePlan
- DescribeSchedulerTaskCntByStatus
- DescribeSchedulerRunTimeInstanceCntByStatus
- DescribeOpsMakePlanInstances
- DescribeOpsMakePlanTasks
- DescribeOpsMakePlans
- KillOpsMakePlanInstances
- BatchDeleteOpsTasks
- DescribeFolderWorkflowList
- DescribeTaskScript
- ModifyTaskInfo
- ModifyTaskLinks
- ModifyTaskScript
- ModifyWorkflowSchedule
- RegisterEvent
- RegisterEventListener
- SetTaskAlarmNew
- SubmitTask
- SubmitWorkflow
- TriggerEvent
- BatchModifyOpsOwners
- BatchStopOpsTasks
- CountOpsInstanceState
- DescribeDependOpsTasks
- DescribeOperateOpsTasks
- DescribeSuccessorOpsTaskInfos
- FreezeOpsTasks
- CreateTask
- ModifyWorkflowInfo
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- CommitRuleGroupTask
- CreateRule
- CreateRuleTemplate
- DeleteRule
- DeleteRuleTemplate
- DescribeDataCheckStat
- DescribeDimensionScore
- DescribeExecStrategy
- DescribeQualityScore
- DescribeQualityScoreTrend
- DescribeRule
- DescribeRuleDimStat
- DescribeRuleExecDetail
- DescribeRuleExecLog
- DescribeRuleExecResults
- DescribeRuleExecStat
- DescribeRuleGroup
- DescribeRuleGroupExecResultsByPage
- DescribeRuleGroupSubscription
- DescribeRuleGroupTable
- DescribeRuleGroupsByPage
- DescribeRuleTemplate
- DescribeRuleTemplates
- DescribeRules
- DescribeRulesByPage
- DescribeTableQualityDetails
- DescribeTableScoreTrend
- DescribeTemplateDimCount
- DescribeTopTableStat
- DescribeTrendStat
- ModifyDimensionWeight
- ModifyExecStrategy
- ModifyMonitorStatus
- ModifyRule
- ModifyRuleGroupSubscription
- ModifyRuleTemplate
- DataInLong APIs
- BatchCreateIntegrationTaskAlarms
- BatchDeleteIntegrationTasks
- BatchForceSuccessIntegrationTaskInstances
- BatchKillIntegrationTaskInstances
- BatchMakeUpIntegrationTasks
- BatchRerunIntegrationTaskInstances
- BatchResumeIntegrationTasks
- BatchStartIntegrationTasks
- BatchStopIntegrationTasks
- BatchSuspendIntegrationTasks
- BatchUpdateIntegrationTasks
- CheckAlarmRegularNameExist
- CheckIntegrationNodeNameExists
- CheckIntegrationTaskNameExists
- CheckTaskNameExist
- CommitIntegrationTask
- CreateHiveTable
- CreateHiveTableByDDL
- CreateIntegrationNode
- CreateIntegrationTask
- CreateTaskAlarmRegular
- DeleteIntegrationNode
- DeleteIntegrationTask
- DeleteOfflineTask
- DeleteTaskAlarmRegular
- DescribeAlarmEvents
- DescribeAlarmReceiver
- DescribeInstanceLastLog
- DescribeInstanceList
- DescribeInstanceLog
- DescribeInstanceLogList
- DescribeIntegrationNode
- DescribeIntegrationStatistics
- DescribeIntegrationStatisticsInstanceTrend
- DescribeIntegrationStatisticsRecordsTrend
- DescribeIntegrationStatisticsTaskStatus
- DescribeIntegrationStatisticsTaskStatusTrend
- DescribeIntegrationTask
- DescribeIntegrationTasks
- DescribeIntegrationVersionNodesInfo
- DescribeOfflineTaskToken
- DescribeRealTimeTaskInstanceNodeInfo
- DescribeRealTimeTaskSpeed
- DescribeRuleTemplatesByPage
- DescribeStreamTaskLogList
- DescribeTaskAlarmRegulations
- DescribeTaskLockStatus
- DryRunDIOfflineTask
- GenHiveTableDDLSql
- GetIntegrationNodeColumnSchema
- GetOfflineDIInstanceList
- GetOfflineInstanceList
- LockIntegrationTask
- ModifyIntegrationNode
- ModifyIntegrationTask
- ModifyTaskAlarmRegular
- ModifyTaskName
- ResumeIntegrationTask
- RobAndLockIntegrationTask
- StartIntegrationTask
- StopIntegrationTask
- SuspendIntegrationTask
- TaskLog
- UnlockIntegrationTask
- CreateOfflineTask
- DescribeRealTimeTaskMetricOverview
- Platform management related APIs
- Data Source Management APIs
- Data Types
- Error Codes
- 服务等级协议
- 相关协议
- 联系我们
- 词汇表
进入数据管理页面
1. 登录 数据开发治理平台 WeData 控制台。
2. 单击左侧菜单中的项目列表,找到需要操作数据管理功能的目标项目。
3. 选择项目后,单击进入数据开发模块。
4. 单击左侧菜单中的数据管理。
数据管理概览
当前 WeData 数据管理支持 EMR、DLC 引擎中系统源的 Hive 与 DLC 数据库表创建。
注意:
在项目管理页面绑定存算引擎后,才可以在数据管理目录中显示数据源。
数据管理目录
目录树用于展示数据源中所有数据库表的层次结构和关系,可以通过此功能实现以下作用:
快速定位目标表。通过目录树功能,用户可以快速定位到目标表所在的位置,提高了操作效率,减少了操作时间和出错的可能性。
展示数据库表之间的关系。通过目录树功能,用户可以清晰地看到数据库表之间的层次结构和关系,便于分析和理解数据库表之间的关联和依赖。
管理和维护数仓。通过目录树功能,用户可以按数仓分层对数据库进行分类和管理,便于对数据库进行维护和调整,例如,删除或更改表名、字段等操作。
方便的搜索功能。通过目录树的搜索框功能,用户可以方便地浏览和搜索数据库表,并跳转到目标表进行操作。
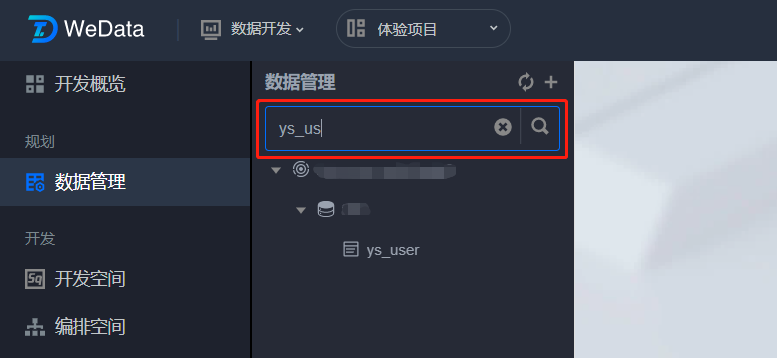
库表搜索
搜索功能是用于帮助用户快速定位和浏览目标数据库表或数据集,它可以为用户提供清晰的层次结构视图和快速搜索功能,让用户轻松地找到所需数据,从而提高数据管理和查询的效率。
在搜索窗口输入数据库或数据表名称,库表目录即可搜索到对应名称的库表结构。搜索功能支持模糊检索。
刷新目录
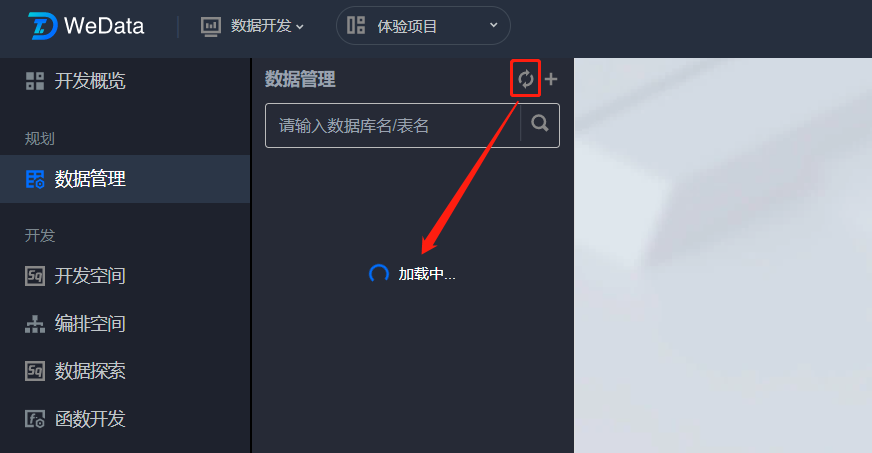
目录树的刷新功能是用于重新加载数据源、数据库与数据表,以便更新目录树中显示的内容。可以帮助用户更新和同步数据源中的最新数据,保证用户获取到最新的数据表信息。
数据库管理
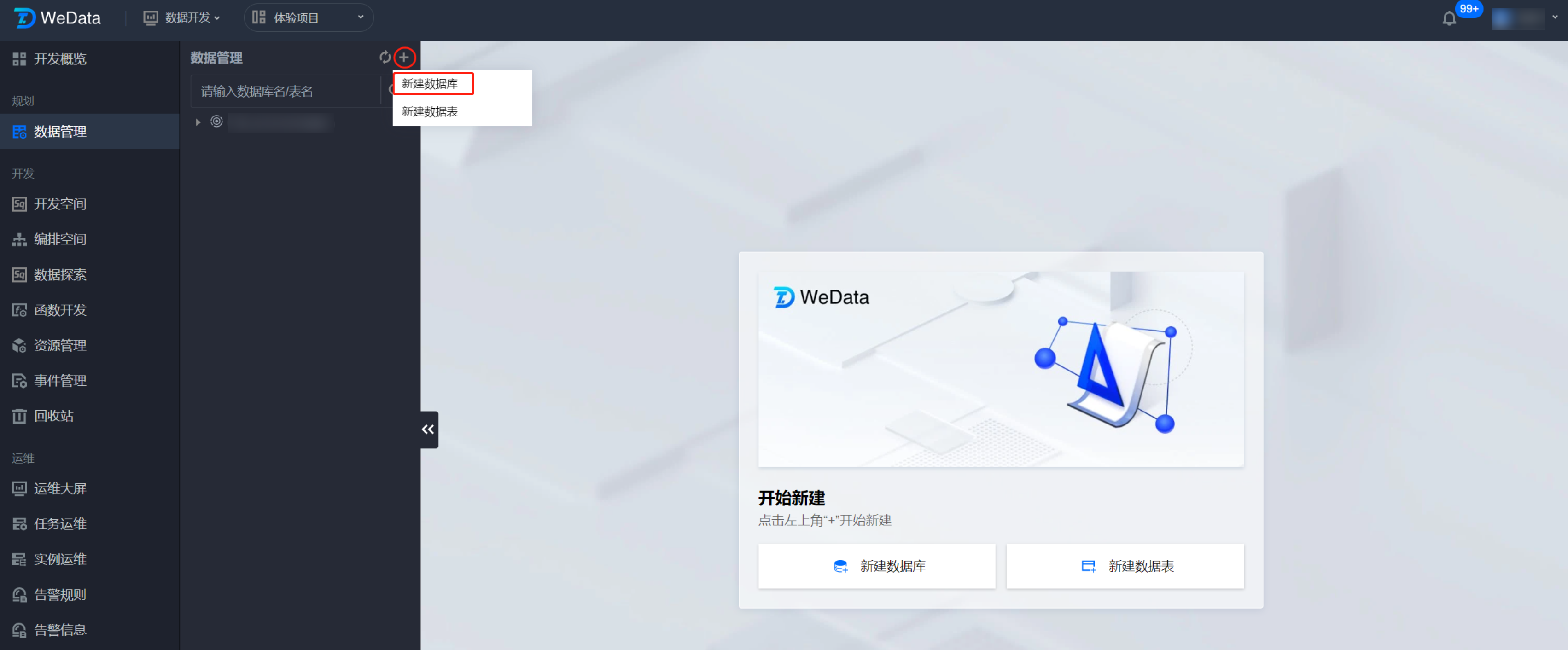
新建数据库
根据绑定的数据源不同,可以在 Hive 或 DLC 数据源下创建数据库。
在数据管理目录中,单击新建数据库,根据提示选择数据源类型、数据源,自定义数据库名及描述信息(选填),配置完成后即可在对应数据源中将数据库创建出来。
Hive 数据库
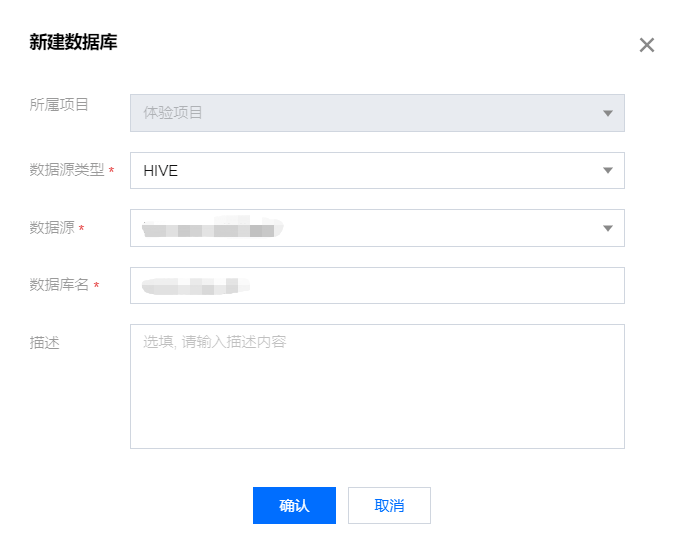
Hive 建库信息:
信息 | 描述 |
数据源类型 | 选择 Hive 类型。 |
数据源 | 选择 Hive 类型数据源。 |
数据库名 | 自定义 Hive 数据库名称。 |
描述 | 选填,自定义描述内容。 |
DLC 数据库
如果是在 DLC 数据源下创建数据库,可以为数据库配置事件策略与治理规则。
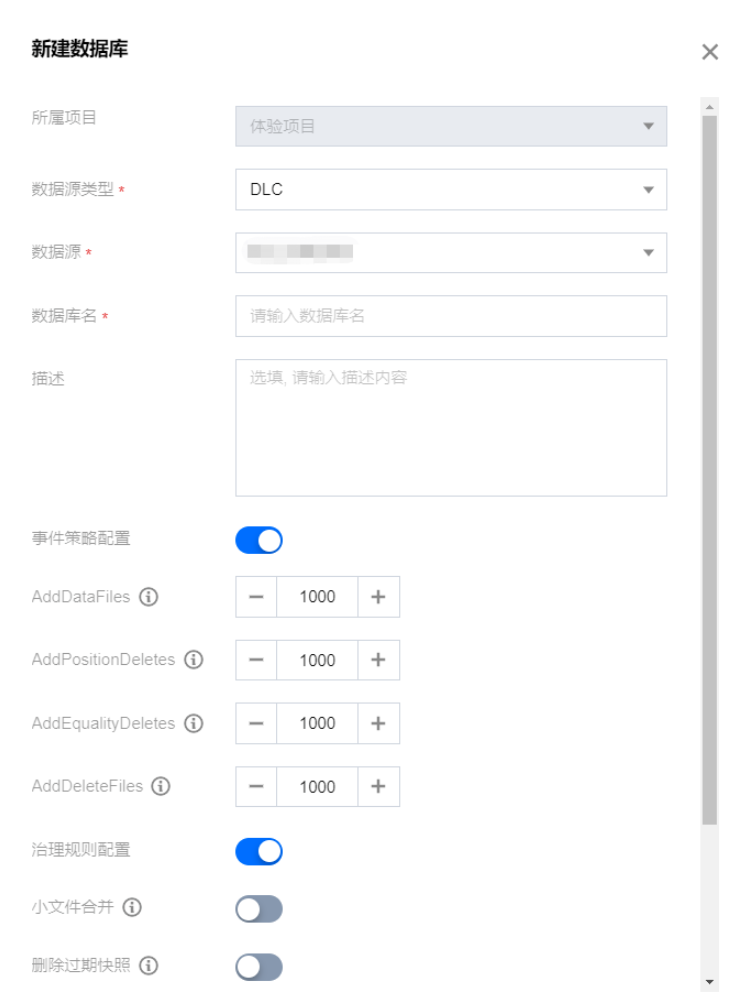
DLC 建库信息:
信息 | 描述 | |
基本信息配置 | 数据源类型 | 选择 DLC 类型。 |
| 数据源 | 选择 DLC 类型数据源。 |
| 数据库名 | 自定义 DLC 数据库名称。 |
| 描述 | 选填,自定义描述内容。 |
事件策略配置 | AddDataFiles | 设置增加的文件数量最大值,超过该值将触发小文件合并。 |
| AddPositionDeletes | 增加的 Position delete 最大数值,超过该值将触发小文件合并。 |
| AddEqualityDeletes | 增加的 Equality delete 最大数值,超过该值将触发小文件合并。 |
| AddDeleteFiles | 增加的 delete file 数量,过期快照的 AddDataFiles+AddDeleteFiles 的总和大于阈值 AddDataFiles+AddDeleteFiles 时,将从该快照处删除快照。 |
治理规则配置 | 小文件合并 | 启用后大量小于阈值的数据文件将被合并为更大的文件,减少文件数量,提升查询性能。 |
| 删除过期快照 | 启用后将自动清理过期的历史快照信息,减少元数据/数据文件数量,节约存储空间,提升查询速度。 |
| 删除孤立文件 | 启用后将自动定期清理无效的数据文件,节约存储空间。 |
| 元数据合并 | 启用后将自动合并元数据 manifests 文件,减少 manifests 文件数量,提高数据查询效率。 |
删除数据库
在数据管理目录树中将光标移动到需要删除的数据库,单击
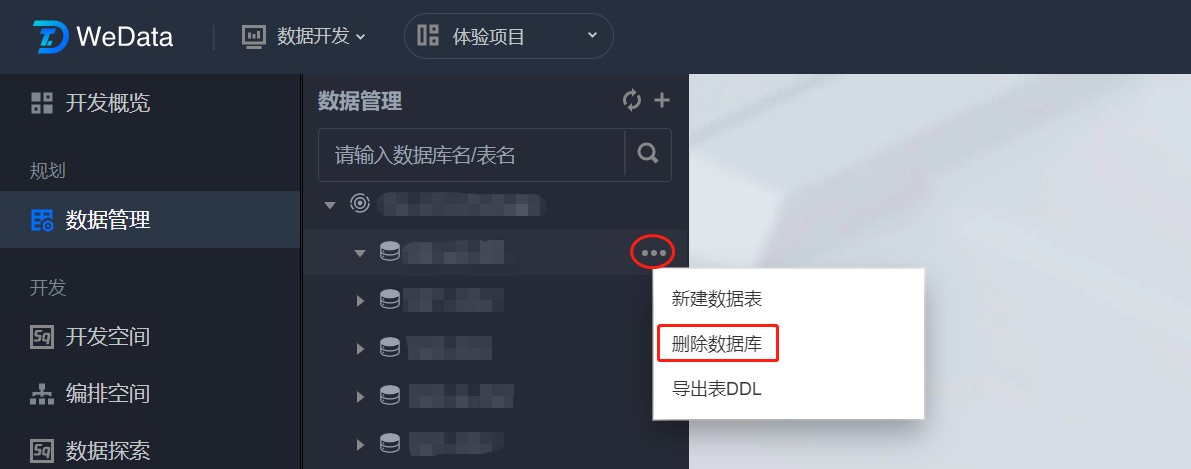
注意:
删除库后无法恢复,请谨慎删除。
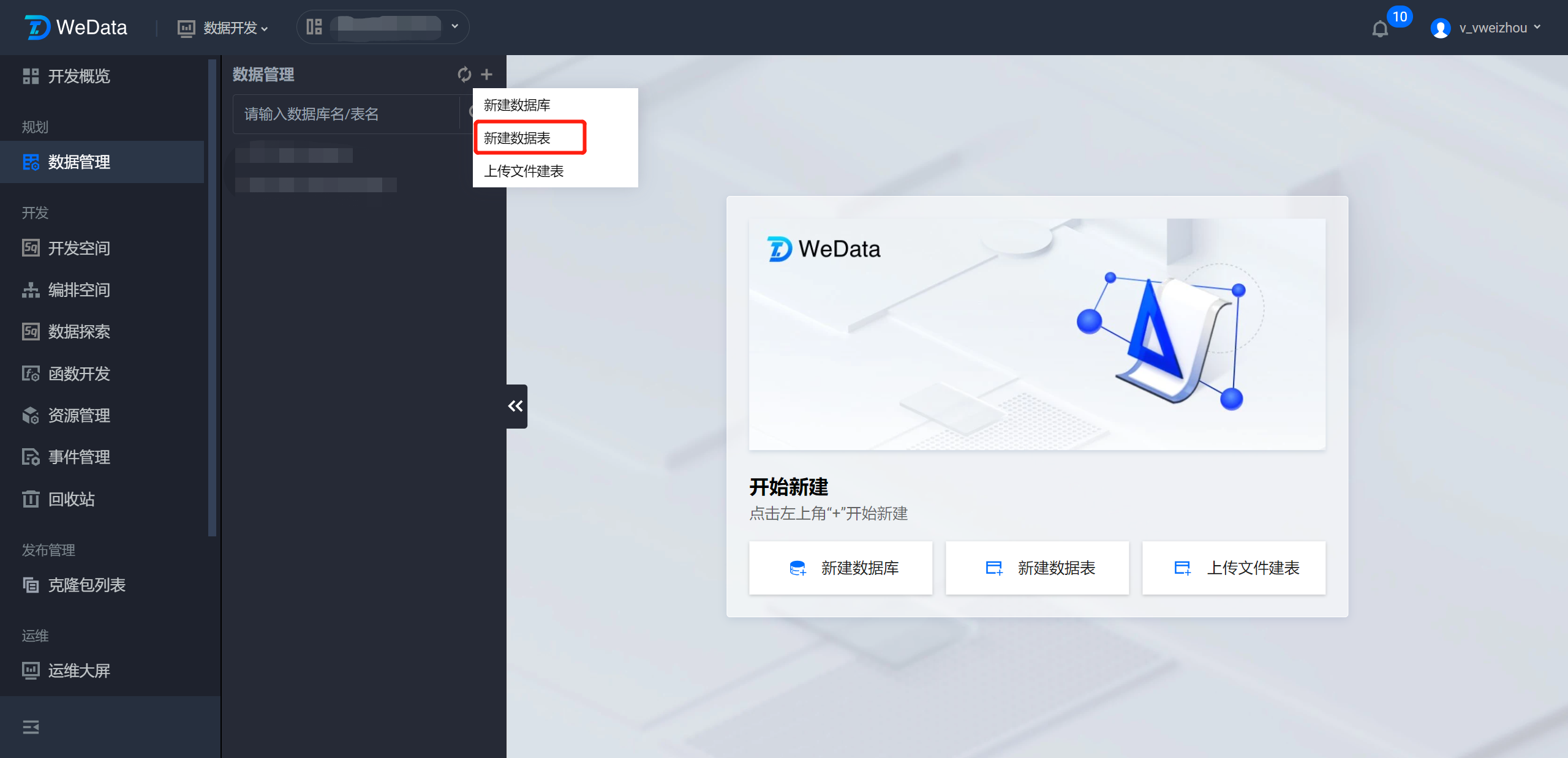
数据表管理
注意:
在创建数据表之前,先要完成数据库创建。
在数据管理目录中,单击新建数据表,在弹窗中根据提示选择数据源类型、数据源、数据库,自定义数据表名,配置完成后单击确定即可进入数据表的基本属性与字段设计页面。
Hive 数据表
1. 使用 EMR 作为存算引擎时,可以在数据管理中的 Hive 数据源下创建 Hive 数据表。
注意:
需要 EMR 的集群中启动 Hive 服务。如果 Hive 开启了 ranger,需要确保 ranger 的用户名和密码正确。暂时尚未提供字段的修改和添加功能。
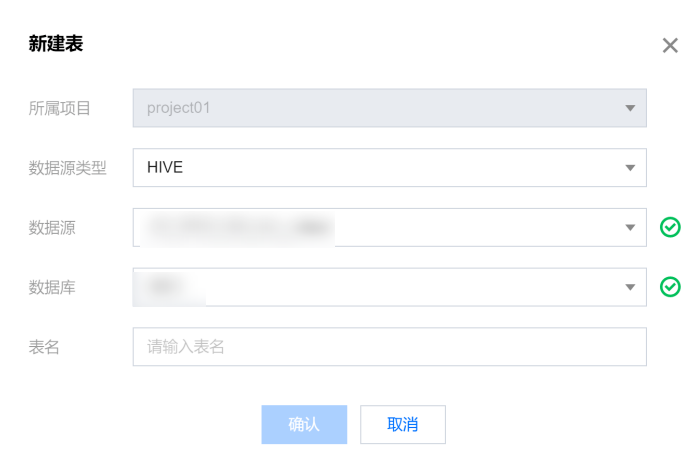
2. 将新建表弹框中的基本信息填写完成后,即可进入数据表设计页面,需要配置表基本属性与字段信息。
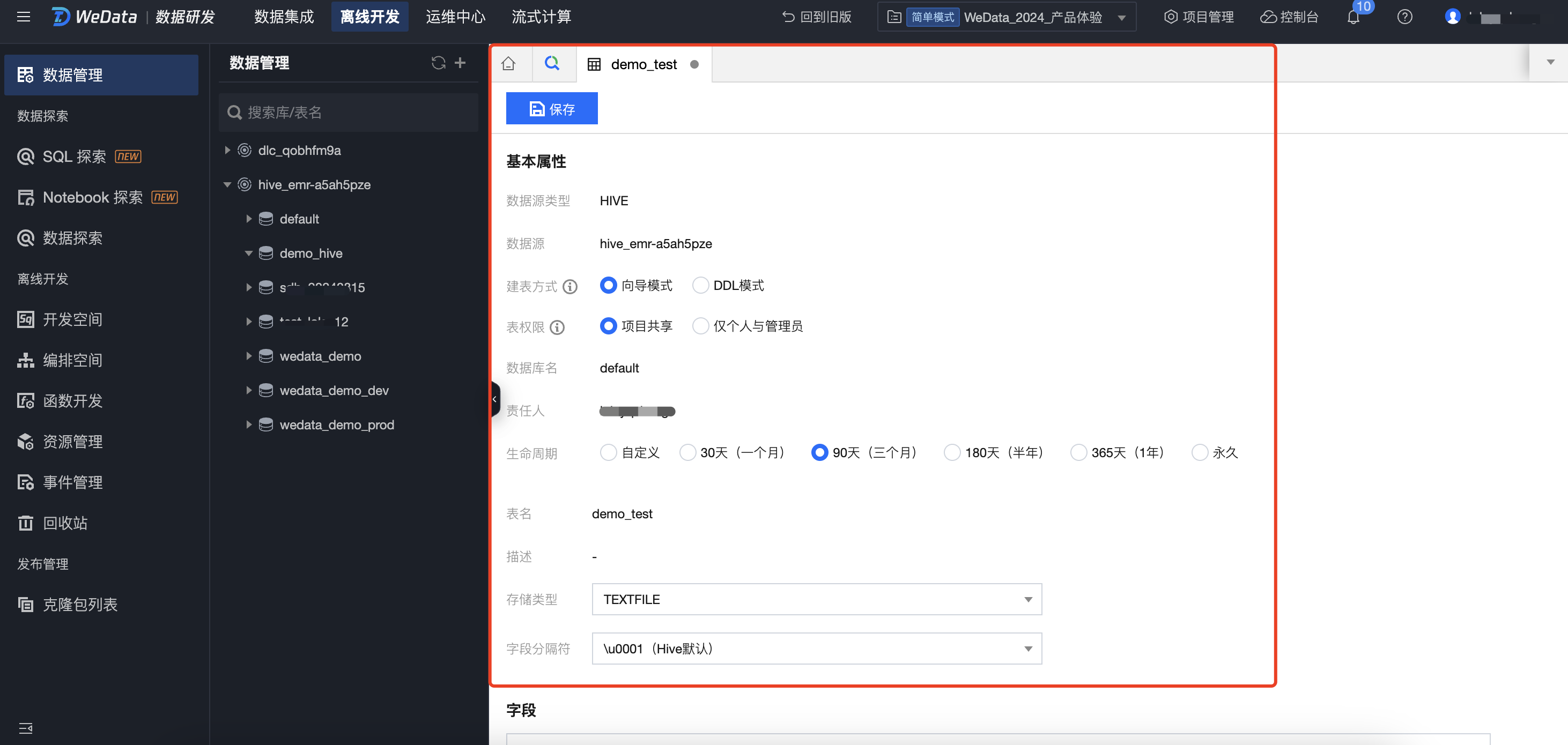
3. Hive 建表配置:
信息 | 描述 |
建表方式 | 向导模式 使用传统的手动添加字段,插入字段后自定义字段名、字段中文名、字段英文名、列类型、是否分区、描述。 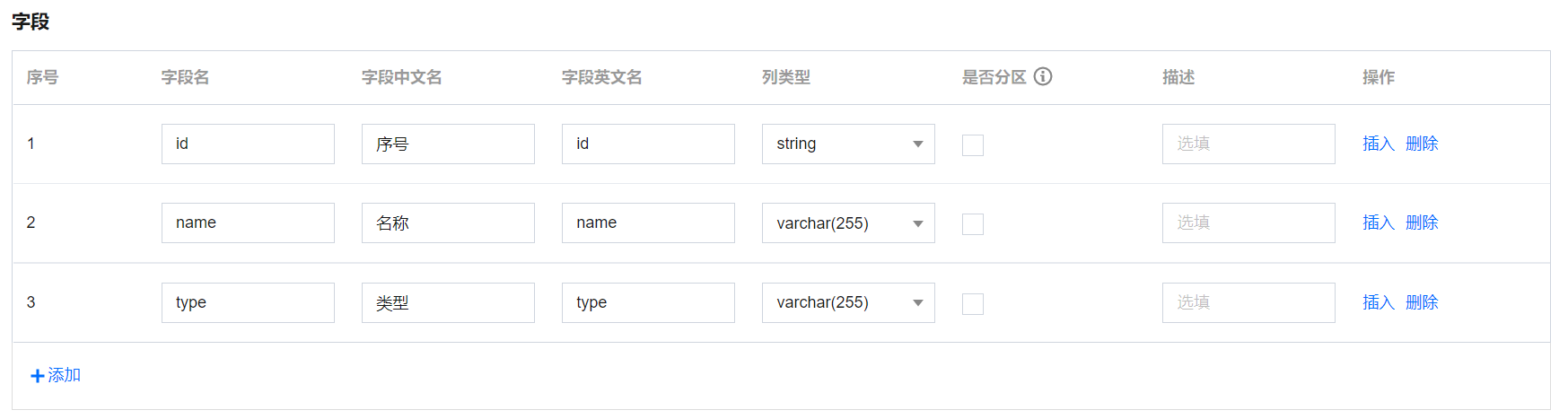 DDL 模式 使用 SQL 建表语句创建数据表,新建表仅支持 CREATE TABLE 语句,编辑表仅支持 ALTER TABLE ADD / REPLACE COLUMNS 语句。例:
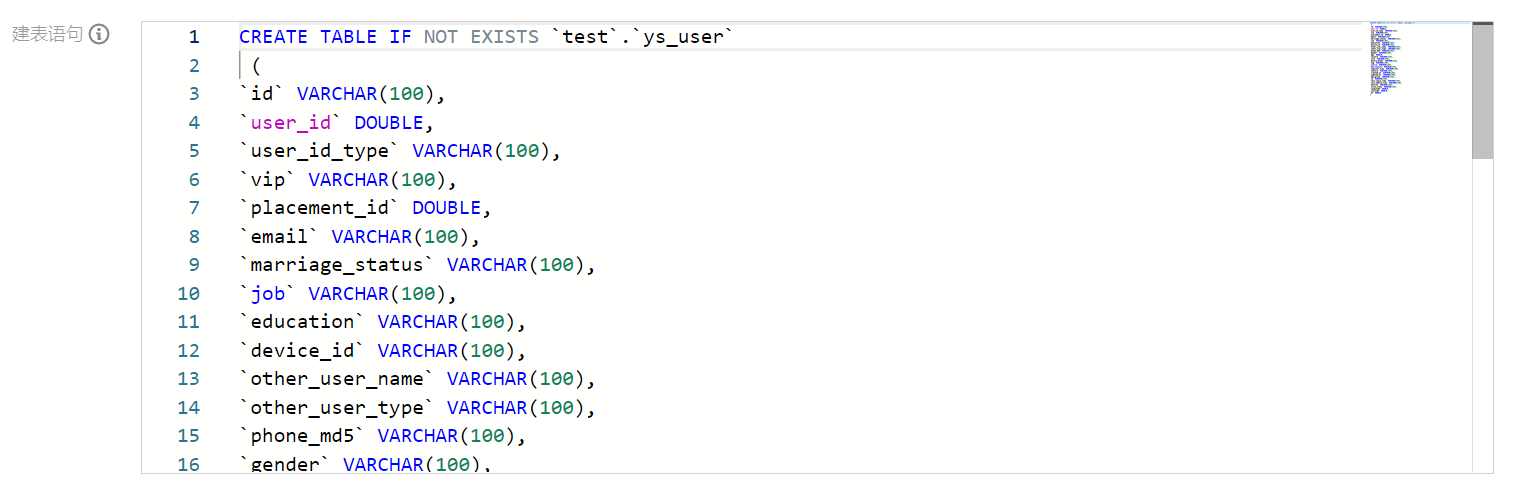 注意: DDL 建表过程中,需要保证建表语句的表名部分与新建数据表时输入的名称一致。 |
表权限 | 项目共享 将数据表权限归属于当前项目,项目内所有成员均会获得数据表权限,包括编辑、查询、删除等操作。 仅个人与管理员 将数据表权限归属于创建者个人与当前项目的管理员。 (说明:数据权限生效时间预计需要30秒左右) |
生命周期 | EMR-Hive 表不支持配置生命周期,当前配置不生效,请知晓(会在后续迭代中去掉该配置项)。 |
存储类型 | 支持选择四种类型的存储方式: TEXTFILE:是一种文本格式的存储类型,存储的是纯文本文件,每一行代表一个记录。 PARQUET:是一种列式存储格式,它将数据分成行和列,并按列存储到磁盘上。它在某些场景下比行式存储更快,而且支持基于列的压缩。 ORC:是一种优化的列存储格式,可用于存储和处理大规模数据。它使用更高级的压缩算法和索引技术,能够提高处理速度和查询效率。 CSV:是一种常见的文本格式,以逗号作为字段之间的分隔符,并在每个字段值周围用引号进行标记。 |
字段分隔符 | 将数据表中的每个字段分离,以便在程序或系统中进行读取和处理。支持五种字段分隔符类型:\\u0001(Hive 默认)、|(竖线)、(空格)、;(分号)、,(逗号)、\\t(制表符) |
字段配置 | 一个字段包含字段名、字段描述、列类型、是否分区等配置信息。 分区字段说明:字段不能全选为分区字段,至少要有一个非分区字段。分区字段不支持array、map、decimal类型。 |
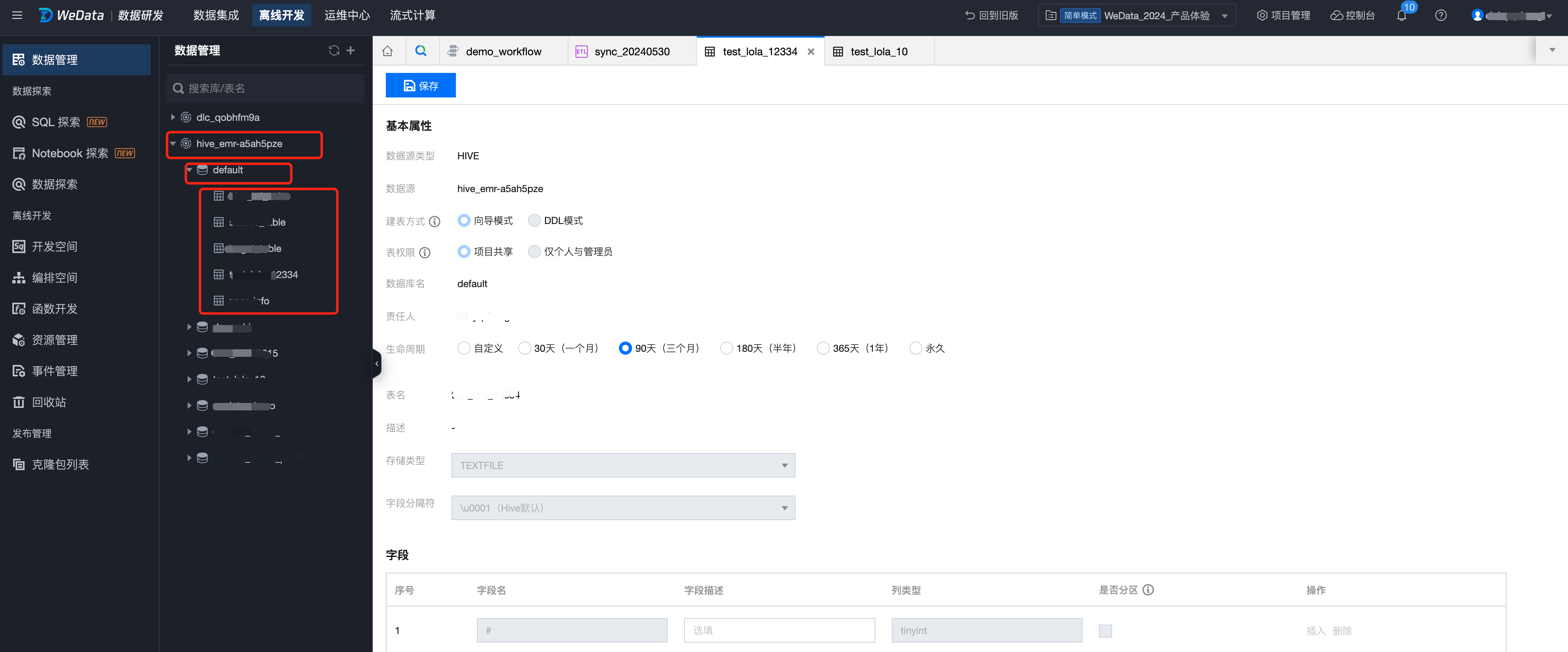
4. 将数据表基本属性与字段配置完成后,单击左上角保存即可完成数据表创建,在左侧数据管理目录中可以看到创建完成的数据表。
DLC 数据表
1. 使用 DLC 作为存算引擎时,可以在数据管理中的 DLC 数据源下创建 DLC 数据表。
注意:
当前 DLC 建表只支持可视化建表,DDL 建表尚未支持,请直接在数据开发的 SQL 语句中创建。
2. 将新建表弹框中的基本信息填写完成后,即可进入数据表设计页面,需要配置数据表格式、字段信息、参数属性。
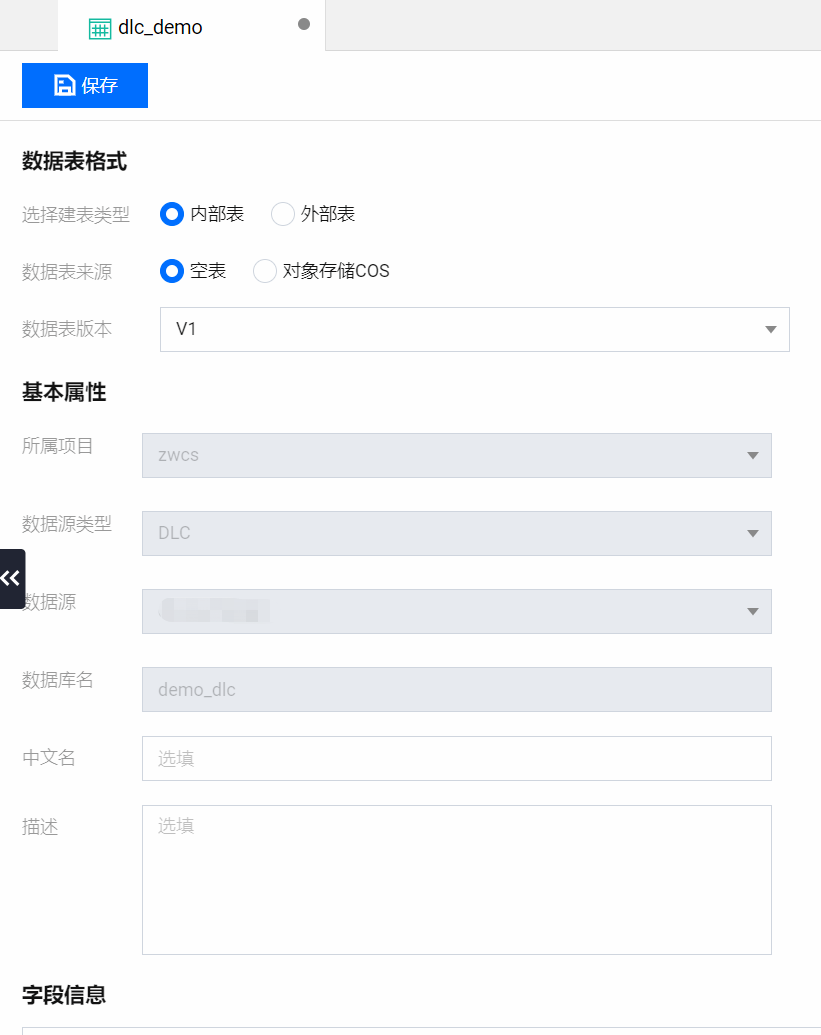
3. DLC 建表配置:
信息 | 描述 | |
数据表格式 | 选择建表类型 | 可选择创建内部表或外部表。 |
| 数据表来源 | 创建内部表时指定创建空表或对象存储 COS。 |
| 存储路径 | 对象存储 COS 与外部表需要填写 location 全路径。 |
| 数据格式 | 数据格式包括:CSV、JSON、PARQUET、ORC、AVRO。 |
| 数据表版本 | 选择 V1 或 V2 的数据表版本。 |
| upsert | 选择 V2 的数据表版本时,可以选择是否使用 upsert 写入。 |
基本属性 | 中文名 | 自定义表中文名。 |
| 描述 | 自定义描述信息。 |
字段信息 | 字段名 | 设计表字段名称。 |
| 字段类型 | 支持 DLC 数据表字段类型。 |
| 描述 | 自定义字段描述信息。 |
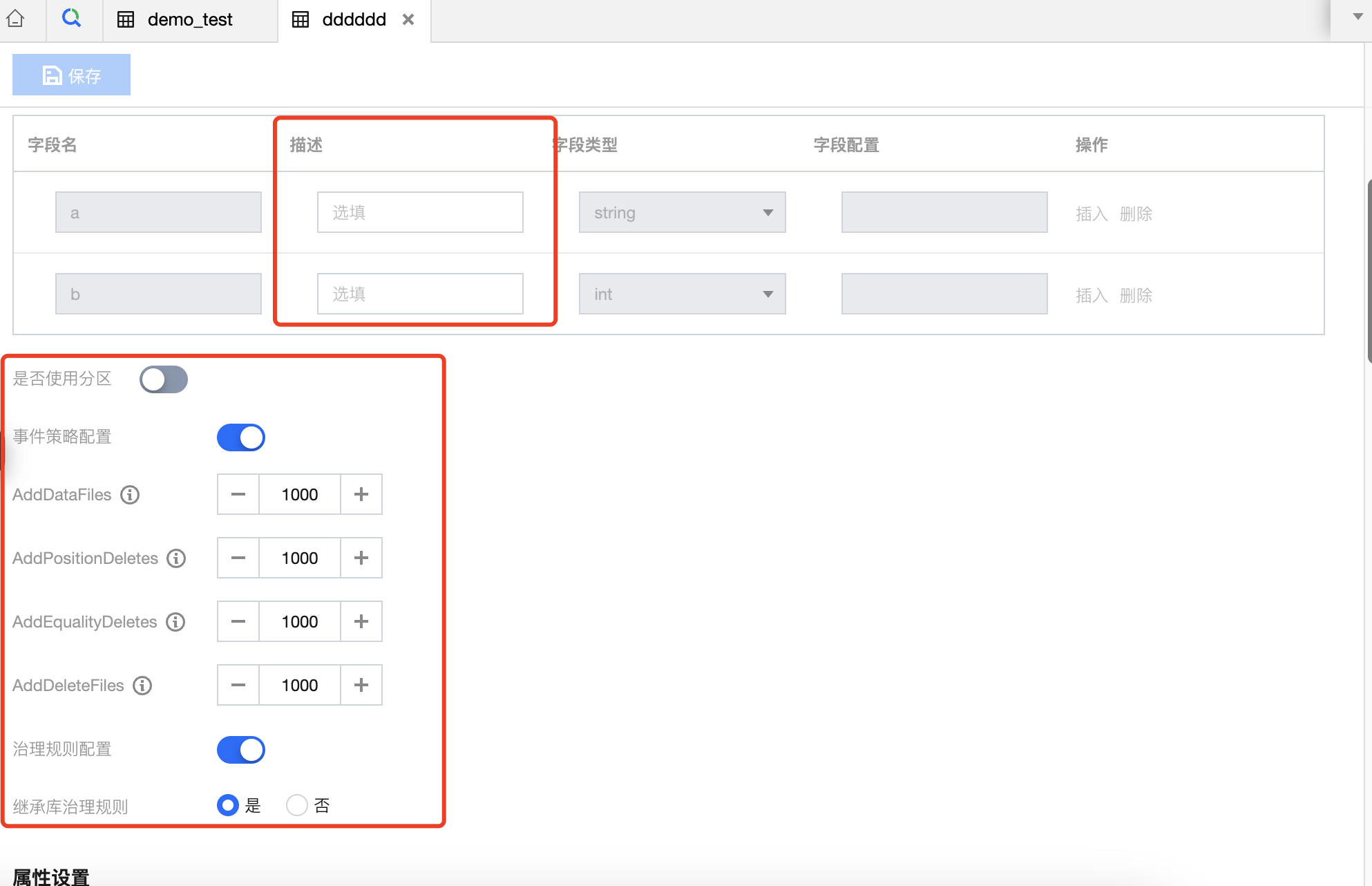
| 是否使用分区 | 设计分区,包括分区字段、转换策略与策略参数。 |
| 事件策略配置 | AddDataFiles:设置增加的文件数量最大值,超过该值将触发小文件合并。 |
| | AddPositionDeletes:增加的 Position delete 最大数值,超过该值将触发小文件合并。 |
| | AddEqualityDeletes:增加的 Equality delete 最大数值,超过该值将触发小文件合并。 |
| | AddDeleteFiles:增加的 delete file 数量,过期快照的 AddDataFiles + AddDeleteFiles 的总和大于阈值 AddDataFiles + AddDeleteFiles 时,将从该快照处删除快照。 |
| 治理规则配置 | 支持开启数据表治理规则,治理规则配置项可以选择继承当前数据表创建时所选数据库的治理规则,或为数据表自定义治理规则。包括以下治理规则: 小文件合并:启用后大量小于阈值的数据文件将被合并为更大的文件,减少文件数量,提升查询性能。 删除过期快照:启用后将自动清理过期的历史快照信息,减少元数据/数据文件数量,节约存储空间,提升查询速度。 删除孤立文件:启用后将自动定期清理无效的数据文件,节约存储空间。 元数据合并:启用后将自动合并元数据 manifests 文件,减少 manifests 文件数量,提高数据查询效率。 |
属性设置 | 参数配置 | 支持自定义数据表参数配置,例如 format-version、write.upsert.enabled。 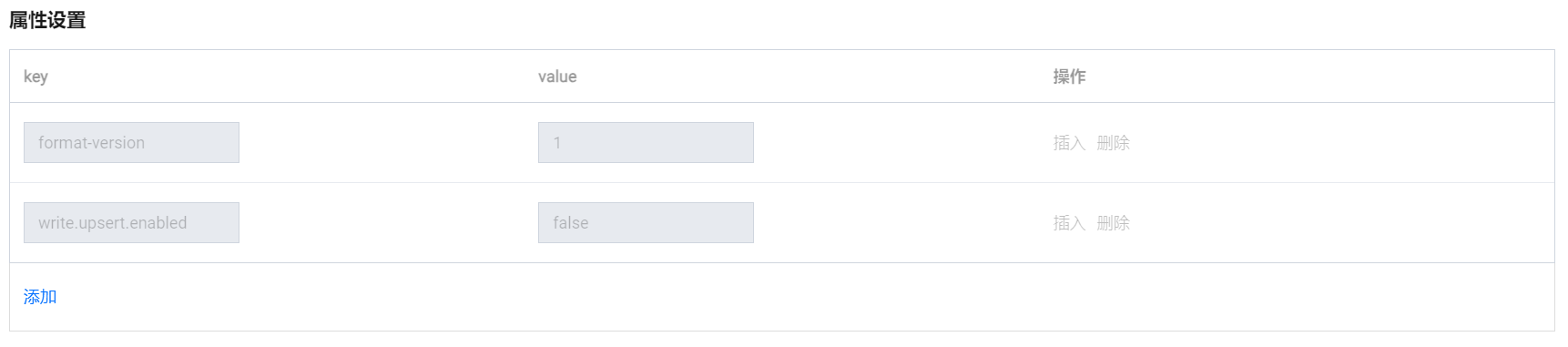 |
上传数据表
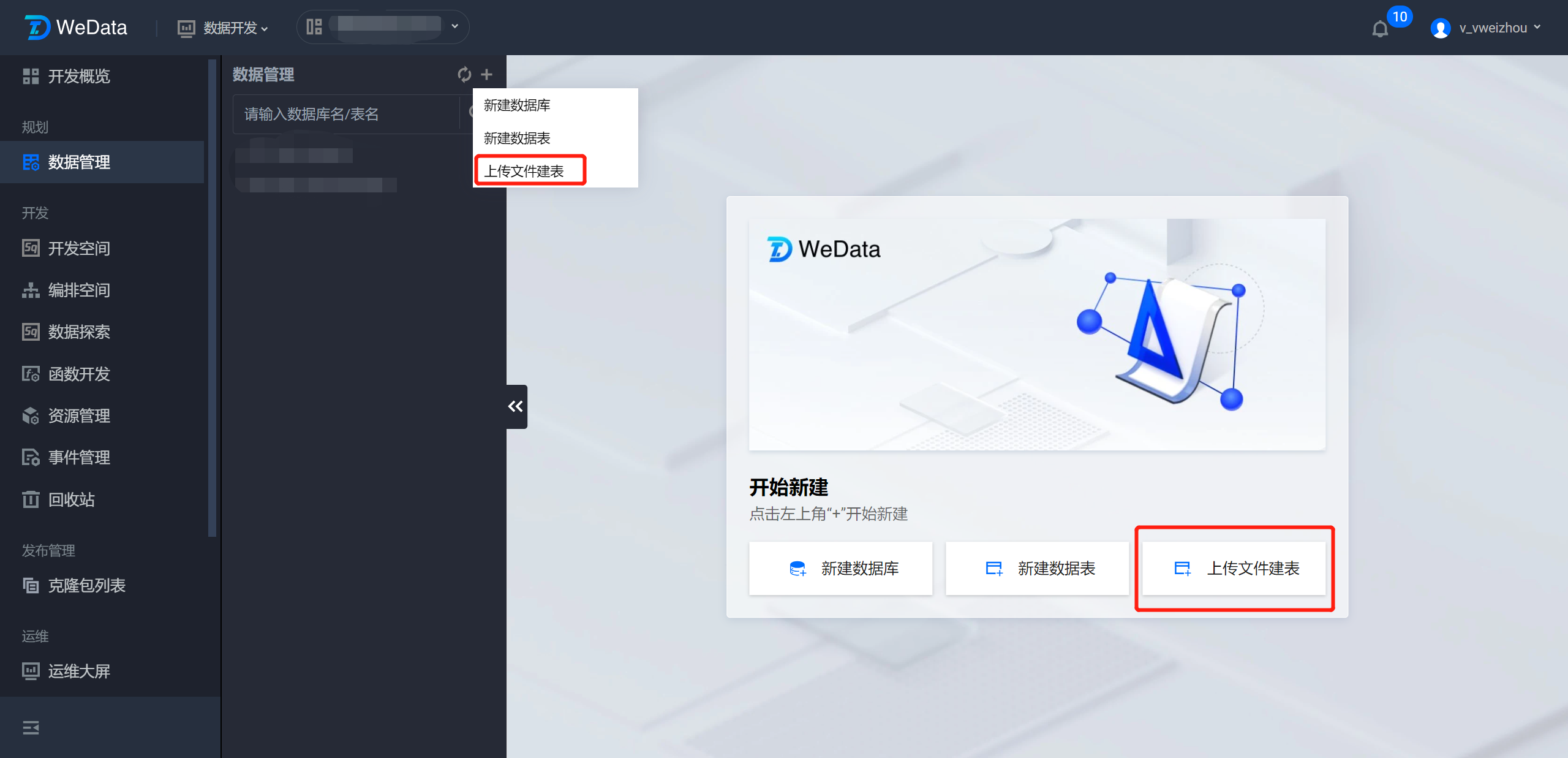
1. 在数据管理目录或数据管理主界面中,单击上传文件建表,目前只支持 Hive 类型数据表上传创建。
上传示例:
注意:
1. 目前提供 CSV、TSV 文件的上传,文件最大100 M。
2. 需要在 WeData 项目中绑定 EMR 集群,有对应的 Hive 服务。
3. 如果在项目管理中配置了 ranger,需要 ranger 的用户名和密码正确。
4. COS 桶设置的 EMR_QCSRole 角色对 COS 的访问权限要放开,不然导数据会报 COS 路径有问题。
2. 在弹窗中根据提示选择数据源类型、数据源、数据库、存储桶、自定义数据表名以及选择上传的建表资源。
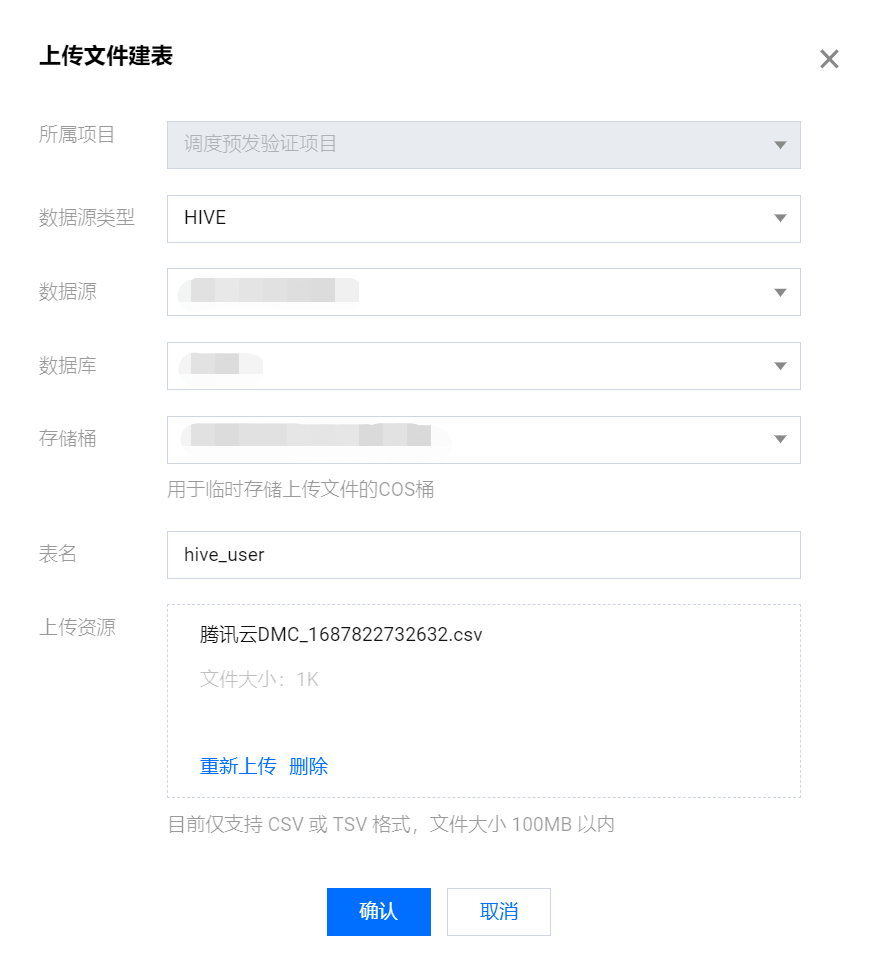
3. 上传文件配置:
信息 | 描述 |
数据源类型 | 支持 Hive 类型数据源。 |
数据源 | 选择对应数据源类型下的 WeData 数据源。 |
数据库 | 显示当前项目绑定的 Hive 数据库,根据数据源类型联动。支持按照库名称进行搜索。 |
存储桶 | 用于临时存储上传文件的 COS 桶。 |
表名 | 默认自动带入去掉后缀名的上传文件名,可自定义名称。 |
上传资源 | 单击上传或拖拽上传,提供上传进度条。上传格式为:CSV 或 TSV 格式。 |
4. 这里以 CSV 文件为例,数据格式如下:
5. 弹窗信息配置完成后,单击确定即可进入建表页面。
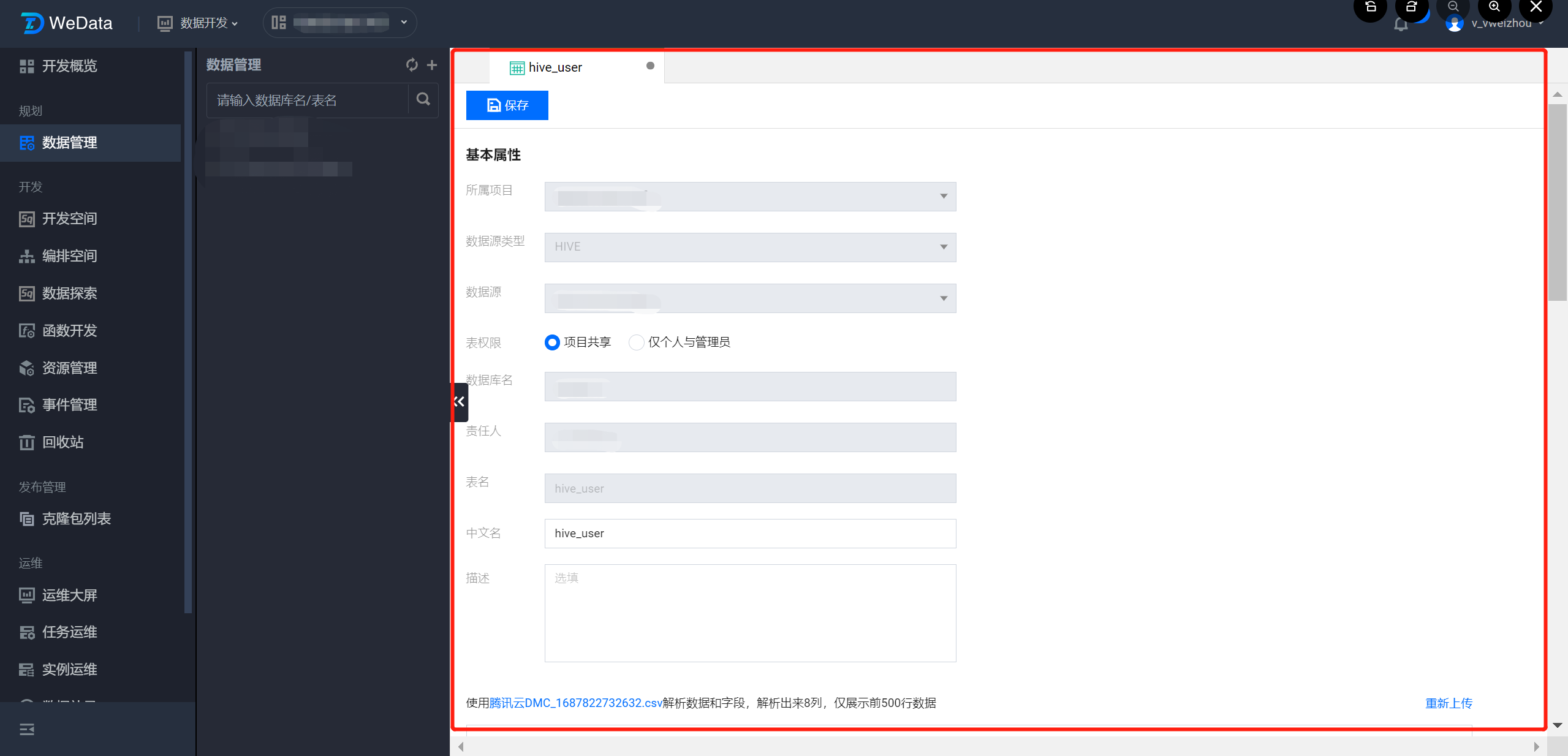
6. 在建表页面中,可以设置数据表权限、表中文名与表描述信息。解析后的上传文件会在页面中提供字段、数据预览,并支持对文件格式、列分隔符、列引号、首行字段确认、文件编码方式、字段属性进行配置。
信息 | 描述 | |
基础属性 | 表权限 | 选择当前数据表创建后的权限归属,在项目内共享或仅个人与管理员可使用。 |
| 中文名 | 默认自动带入去掉后缀名的文件名,可自定义。 |
| 描述 | 自定义数据表描述信息。 |
文件属性 | 数据预览 | 文件解析后仅展示前500行数据,单击重新上传会弹出文件上传弹框用于重新上传建表文件。 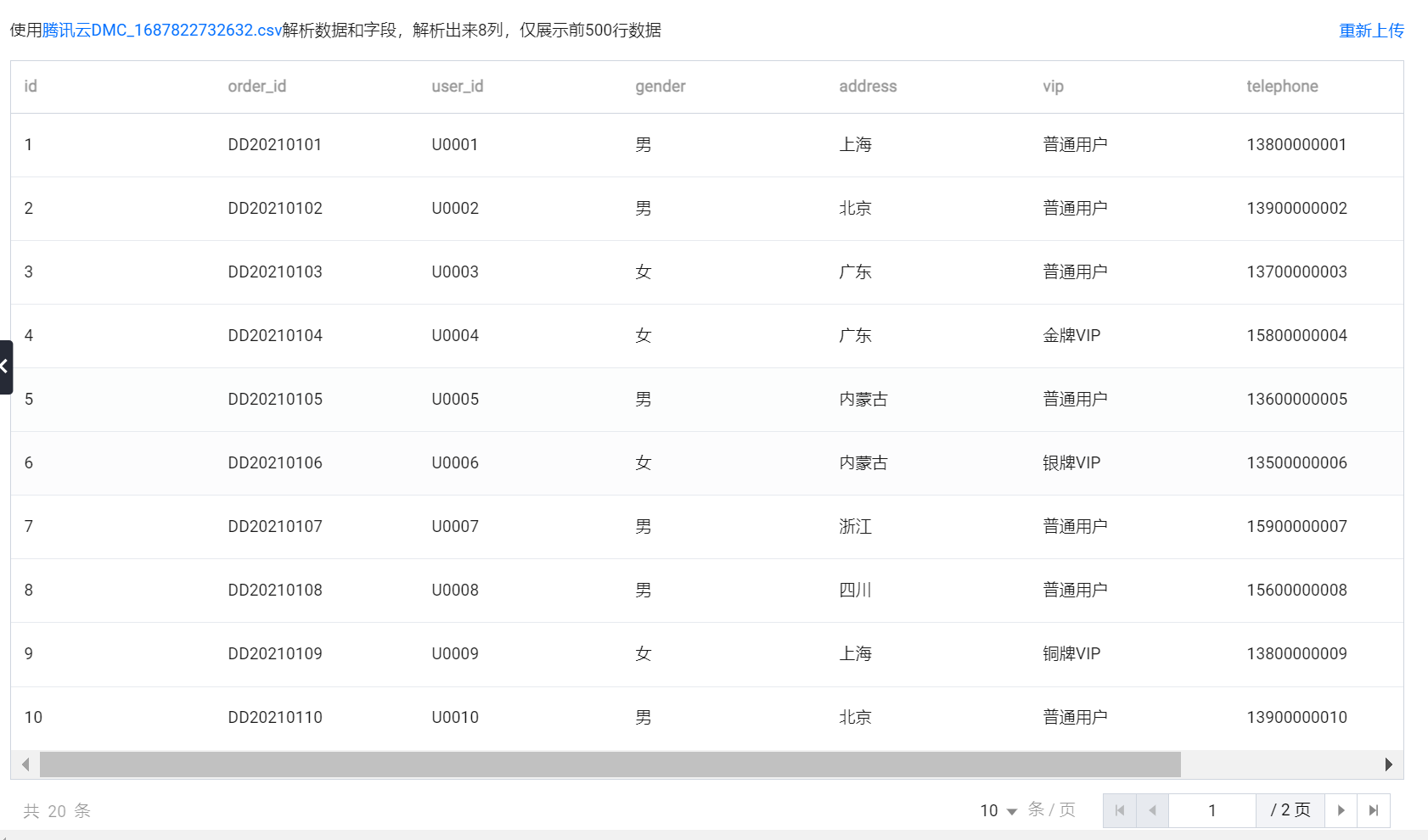 |
| 文件格式 | 下拉选择,支持 CSV、TSV。 |
| 列分隔符 | 用户可以自定义输入,输入单个字符或者类似于 \\u0001 的 Unicode 转义序列。 CSV 默认使用:,(逗号) TSV 默认使用:\\t(制表符) |
| 列引号 | 默认双引号,用户可以切换单引号。 |
| 文件首行是字段名 | 默认否,可以切换为是。 |
| 文件编码方式 | 默认 UTF-8,用户可以选择 UTF-8、GBK、ISO-8859-1。 |
字段属性 | 字段名 | 根据文件首行是字段名属性解析字段名。当文件内数据首行非字段名的情况下,用 column_1、column_2、column_3......column_x 来顺序填充字段名。支持用户可自定义修改字段名。 |
| 字段中文名 | 自定义字段中文名。 |
| 字段英文名 | 自定义字段英文名。 |
| 列类型 | 根据数据源类型选择对应数据源支持的字段类型。 |
| 描述 | 自定义字段描述信息。 |
7. 在页面中将建表信息配置完成后,单击页面左上角保存,即可生成数据表。
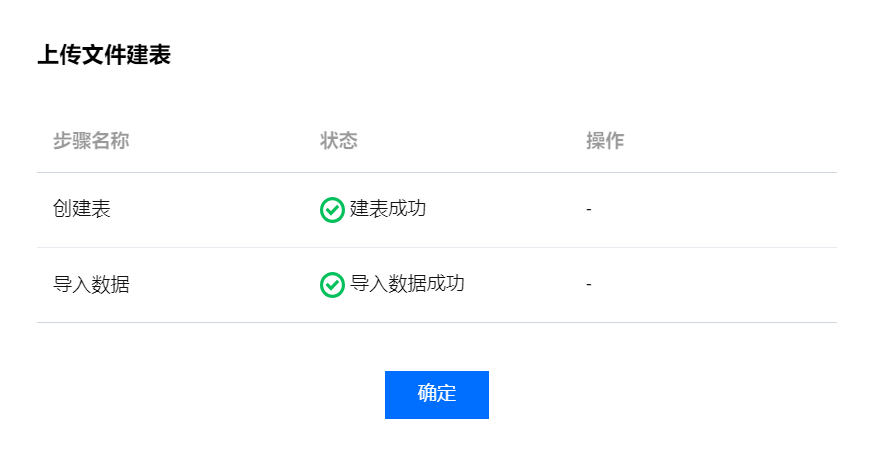
8. 相应的数据表生成进度可以在保存后的进度弹框内查看。当创建步骤运行成功后,数据表即可成功生成。
编辑数据表
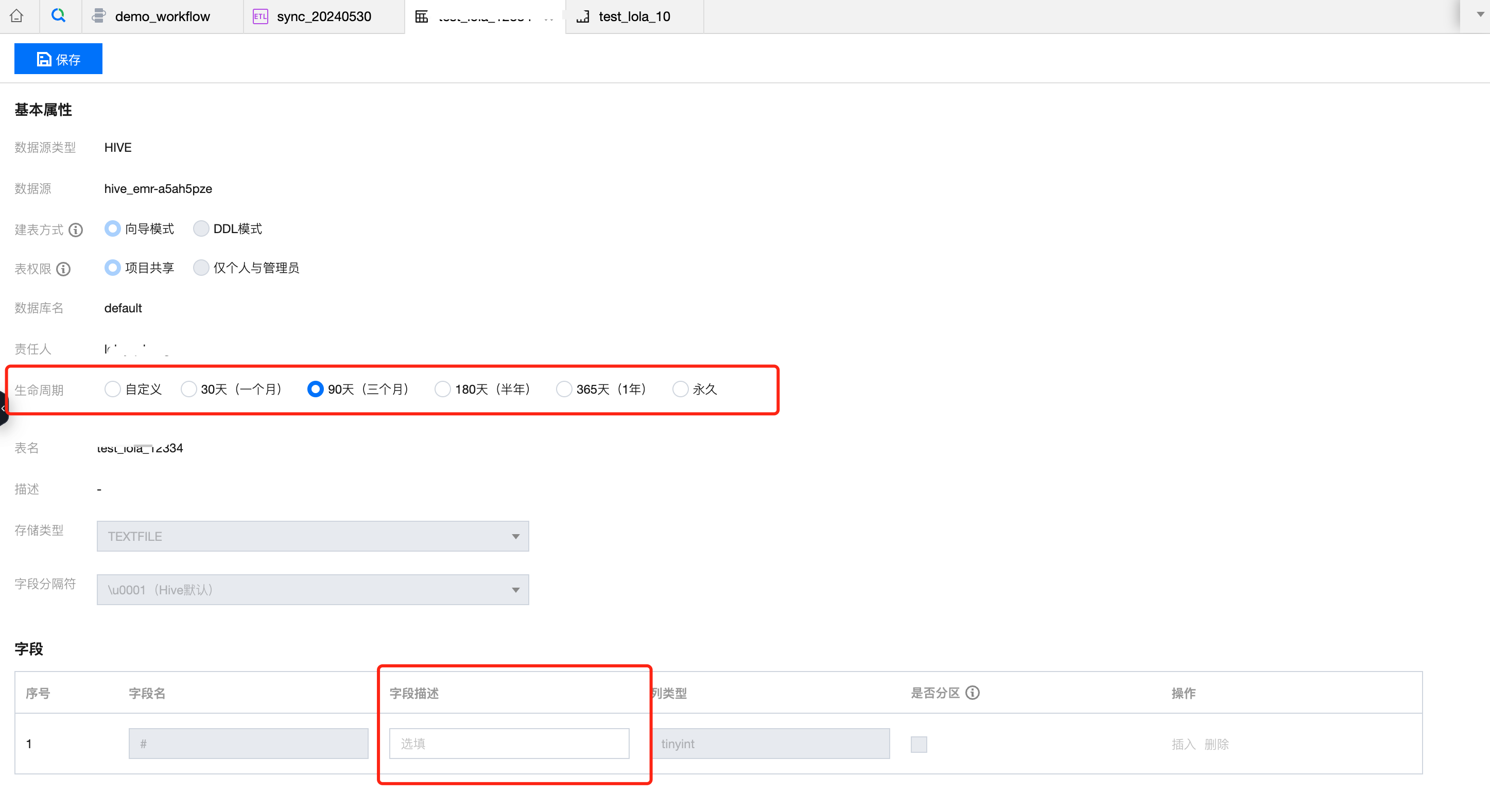
1. 在数据管理目录树中将光标移动到需要编辑的数据表,双击鼠标左键即可打开对应数据表的编辑页面,页面中可以编辑数据表的部分参数。
Hive 可编辑内容包括生命周期、字段描述。
2. DLC 可编辑内容包括表字段描述、事件策略配置、治理规则配置。
3. 数据表编辑修改后,单击保存即可完成数据表编辑操作。
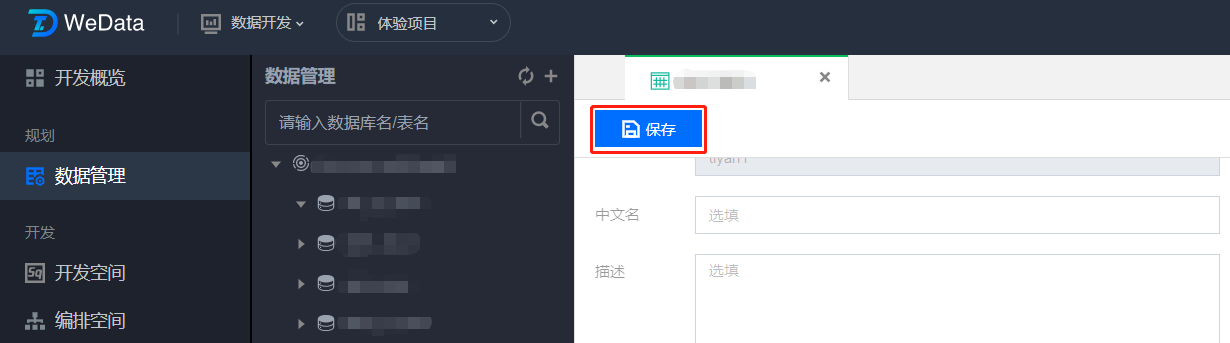
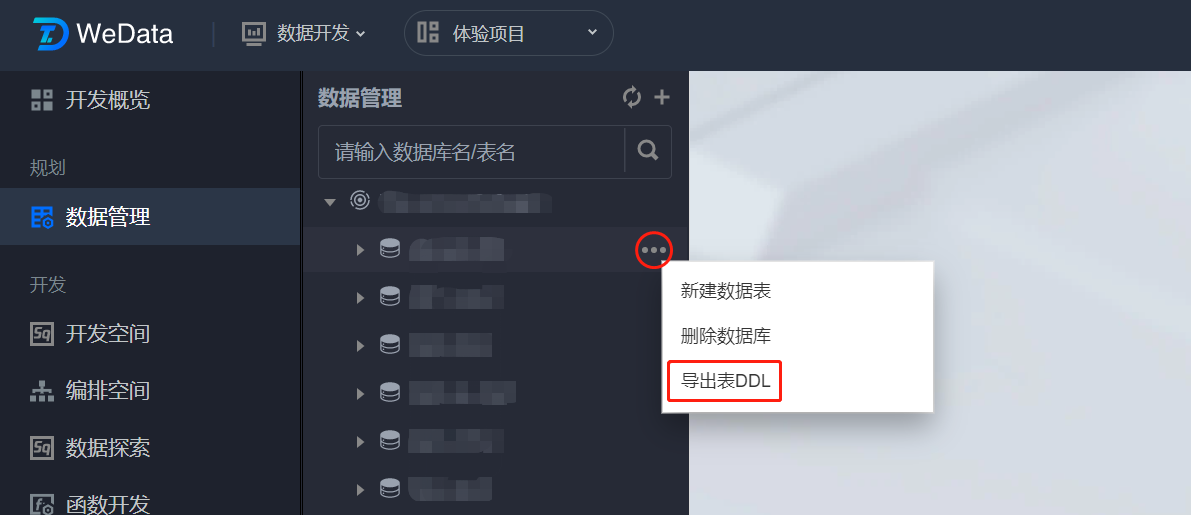
导出表 DDL
1. 在数据管理目录树中将光标移动到需要导出表 DDL 的数据表所在数据库,单击
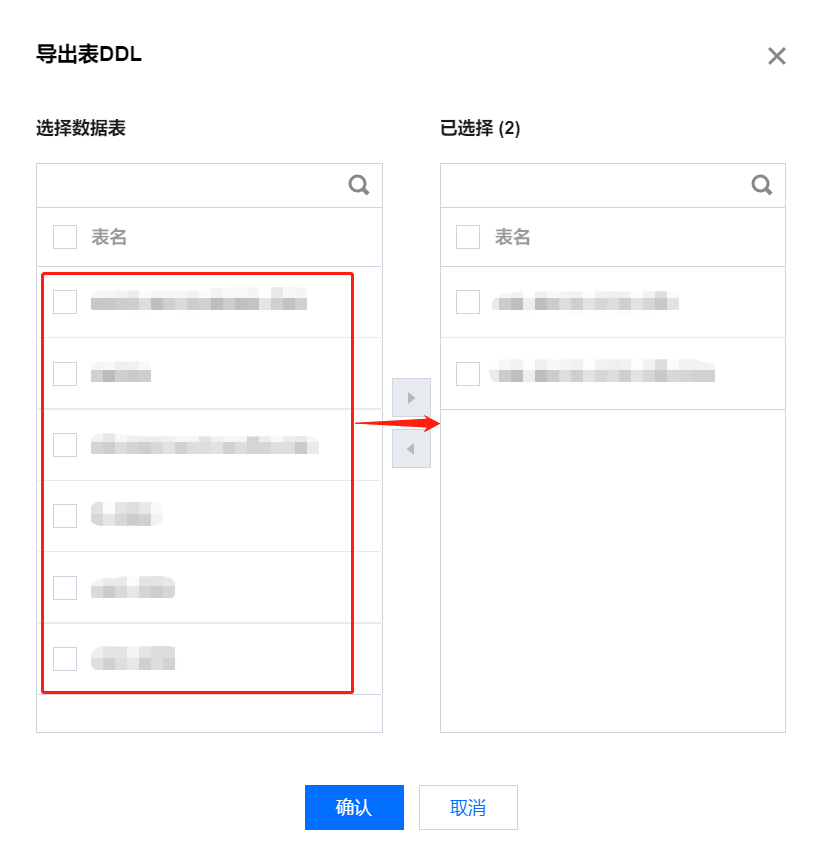
2. 选择需要导出表 DDL 的数据表。
删除数据表
1. 在数据管理目录树中将光标移动到需要删除的数据表,单击
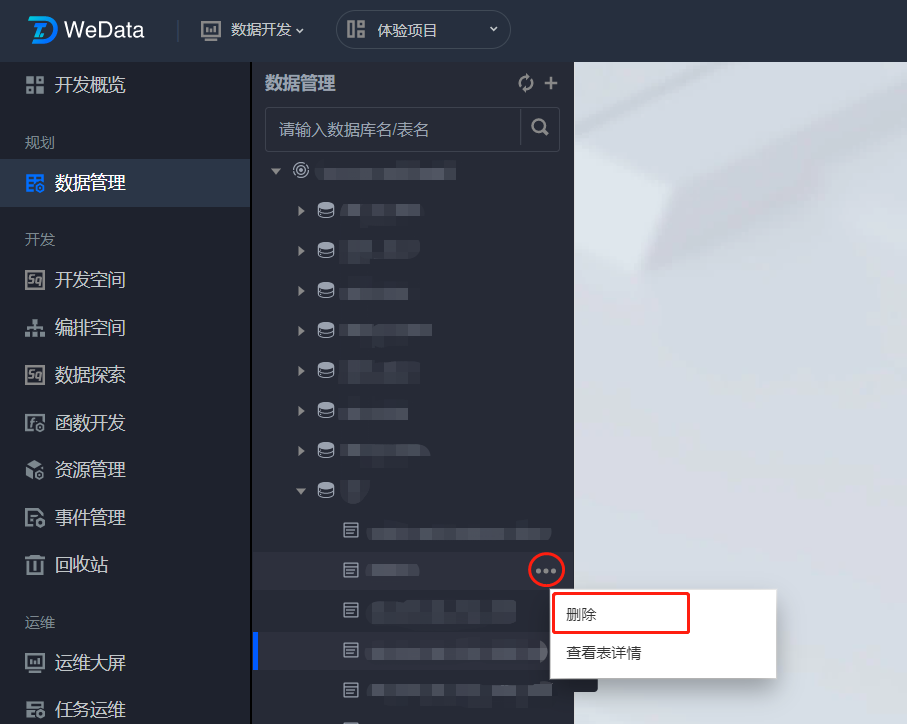
查看表详情
在数据管理目录树中将光标移动到需要查看详情的数据表,单击
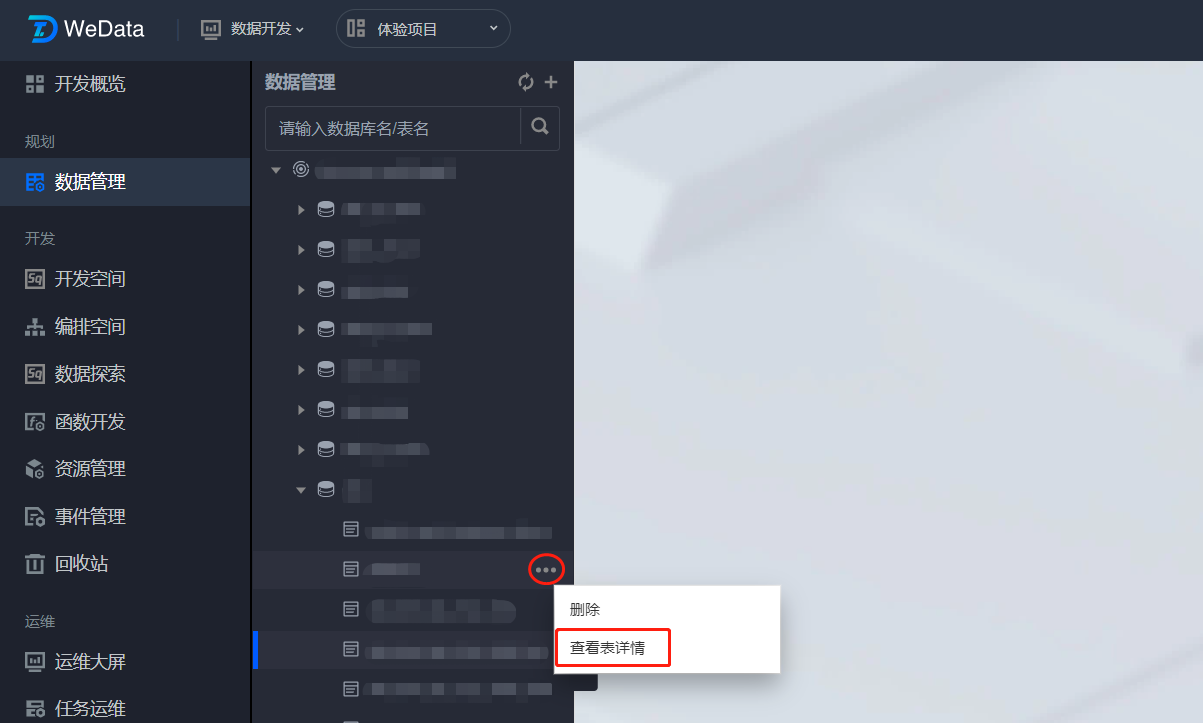
表信息
表详情信息:
信息 | 描述 | |
基本信息 | 数据类型 | 数据表所属的存储和计算引擎类型。 |
| 数据库名 | 数据表所属的数据库的名称。 |
| 表名 | 数据表的标识名称。 |
| 责任人 | 数据表的责任人。 |
| 中文名 | 数据表的中文名称。 |
| 描述 | 用户自定义的描述信息。 |
存储信息 | 表大小 | 当前数据表中的数据已占用物理存储的空间大小。 |
| 生命周期 | 当前数据表的生命周期,用于控制其有效使用时间,提升数据治理过程中整体的安全性与节省存算资源。 |
| 创建时间 | 当前数据表的创建日期时间。 |
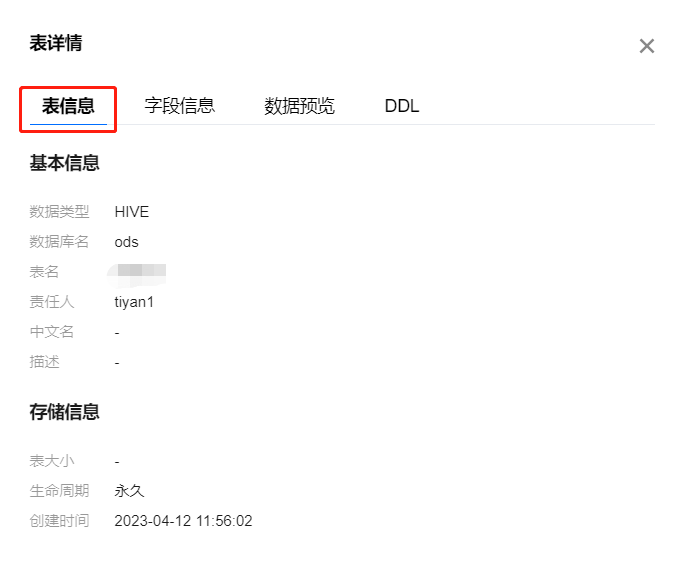
字段信息
显示当前数据表的字段元数据信息,包括字段序号、字段名、字段中文名、字段英文名、列类型、是否分区、描述等信息。
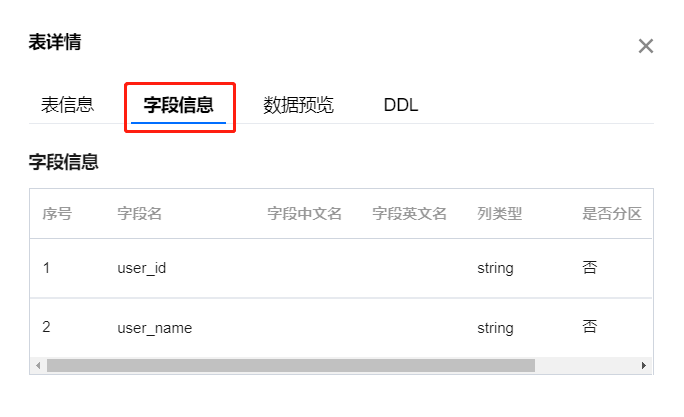
数据预览
抓取当前数据表中的部分真实数据作为预览数据进行展示,帮助用户快速了解数据表中的数据,并提供数据清洗和数据分析所需的参考。
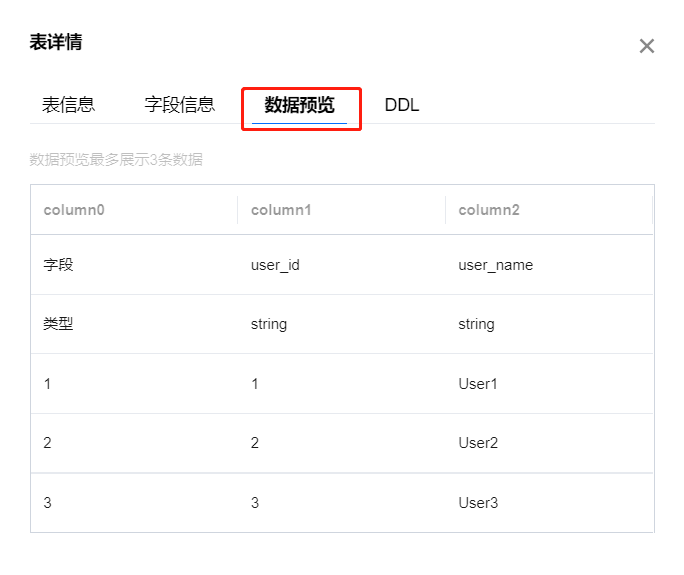
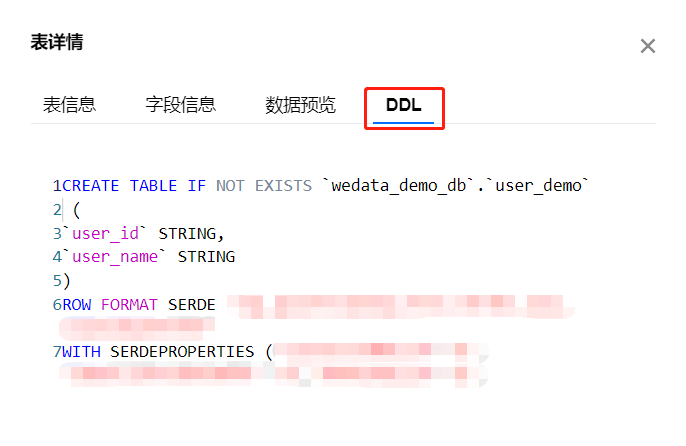
DDL
通过查看数据表的 DDL,可以了解数据表的名称、列名、数据类型、约束条件等重要信息,从而更好地理解数据表的结构和特征。

 是
是
 否
否
本页内容是否解决了您的问题?