- 产品简介
- 购买指南
- 准备工作
- 操作指南
- 管理控制台
- 项目管理
- 数据集成
- 数据集成概述
- 支持的数据源与读写能力
- 集成资源配置与管理
- 实时同步任务配置与运维
- 离线同步任务配置与运维
- 离线同步支持的数据源
- 数据源一览
- 数据源列表
- MySQL 数据源
- TDSQL-C MySQL 数据源
- Oracle 数据源
- SQL Server 数据源
- PostgreSQL 数据源
- TDSQL-PostgreSQL 数据源
- TDSQL MySQL 数据源
- DB2 数据源
- 达梦 DM 数据源
- OceanBase 数据源
- SAP HANA 数据源
- SAP IQ(Sybase) 数据源
- Doris/TCHouse-D 数据源
- StarRocks 数据源
- DLC 数据源
- Iceberg 数据源
- TCHouse-P 数据源
- ClickHouse 数据源
- Greenplum 数据源
- Hive 数据源
- HDFS 数据源
- HBase 数据源
- TBase 数据源
- GBase 数据源
- GaussDB 数据源
- Impala 数据源
- Kudu 数据源
- FTP 数据源
- COS 数据源
- SFTP 数据源
- Rest API 数据源
- Elasticsearch/腾讯云 Elasticsearch 数据源
- Mongo/腾讯云 Mongo 数据源
- Redis 数据源
- Kafka/CKafka 数据源
- CTSDB influxDB 数据源
- TDMQ Pulsar 数据源
- 数据集成离线同步配置与运维
- 数据开发离线同步配置与运维
- 转换节点配置
- 时间参数说明
- 离线节点高级参数
- 离线同步支持的数据源
- 同步任务自动建表能力
- 常见问题
- 数据开发
- 数据资产
- 数据质量
- 数据安全
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- DeleteProjectParamDs
- CreateWorkflowDs
- CreateTaskVersionDs
- RemoveWorkflowDs
- TriggerDsEvent
- DeleteTaskDs
- DescribeBatchOperateTask
- DeleteFilePath
- GetFileInfo
- FindAllFolder
- CreateTaskFolder
- MoveTasksToFolder
- DescribeDsFolderTree
- DeleteFile
- UploadContent
- SubmitSqlTask
- SubmitTaskTestRun
- DeleteResource
- DescribeResourceManagePathTrees
- CreateCustomFunction
- DeleteCustomFunction
- DescribeFunctionKinds
- DescribeFunctionTypes
- DescribeOrganizationalFunctions
- SaveCustomFunction
- SubmitCustomFunction
- CreateDsFolder
- DeleteDsFolder
- DescribeDsParentFolderTree
- ModifyDsFolder
- DeleteResourceFile
- DeleteResourceFiles
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operation and Maintenance APIs
- FreezeTasksByWorkflowIds
- DeleteWorkflowById
- DescribeDependTaskLists
- DescribeWorkflowExecuteById
- DescribeWorkflowTaskCount
- DescribeWorkflowListByProjectId
- DescribeWorkflowInfoById
- UpdateWorkflowOwner
- RunRerunScheduleInstances
- DescribeWorkflowCanvasInfo
- DescribeAllByFolderNew
- DescribeTaskRunHistory
- RunForceSucScheduleInstances
- KillScheduleInstances
- RunTasksByMultiWorkflow
- DescribeTaskByStatusReport
- DescribeStatisticInstanceStatusTrendOps
- DescribeOpsWorkflows
- DescribeSchedulerTaskTypeCnt
- BatchStopWorkflowsByIds
- DescribeInstanceByCycle
- DescribeTaskByCycleReport
- DescribeSchedulerInstanceStatus
- DescribeScheduleInstances
- CreateOpsMakePlan
- DescribeSchedulerTaskCntByStatus
- DescribeSchedulerRunTimeInstanceCntByStatus
- DescribeOpsMakePlanInstances
- DescribeOpsMakePlanTasks
- DescribeOpsMakePlans
- KillOpsMakePlanInstances
- BatchDeleteOpsTasks
- DescribeFolderWorkflowList
- DescribeTaskScript
- ModifyTaskInfo
- ModifyTaskLinks
- ModifyTaskScript
- ModifyWorkflowSchedule
- RegisterEvent
- RegisterEventListener
- SetTaskAlarmNew
- SubmitTask
- SubmitWorkflow
- TriggerEvent
- BatchModifyOpsOwners
- BatchStopOpsTasks
- CountOpsInstanceState
- DescribeDependOpsTasks
- DescribeOperateOpsTasks
- DescribeSuccessorOpsTaskInfos
- FreezeOpsTasks
- CreateTask
- ModifyWorkflowInfo
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- CommitRuleGroupTask
- CreateRule
- CreateRuleTemplate
- DeleteRule
- DeleteRuleTemplate
- DescribeDataCheckStat
- DescribeDimensionScore
- DescribeExecStrategy
- DescribeQualityScore
- DescribeQualityScoreTrend
- DescribeRule
- DescribeRuleDimStat
- DescribeRuleExecDetail
- DescribeRuleExecLog
- DescribeRuleExecResults
- DescribeRuleExecStat
- DescribeRuleGroup
- DescribeRuleGroupExecResultsByPage
- DescribeRuleGroupSubscription
- DescribeRuleGroupTable
- DescribeRuleGroupsByPage
- DescribeRuleTemplate
- DescribeRuleTemplates
- DescribeRules
- DescribeRulesByPage
- DescribeTableQualityDetails
- DescribeTableScoreTrend
- DescribeTemplateDimCount
- DescribeTopTableStat
- DescribeTrendStat
- ModifyDimensionWeight
- ModifyExecStrategy
- ModifyMonitorStatus
- ModifyRule
- ModifyRuleGroupSubscription
- ModifyRuleTemplate
- DataInLong APIs
- BatchCreateIntegrationTaskAlarms
- BatchDeleteIntegrationTasks
- BatchForceSuccessIntegrationTaskInstances
- BatchKillIntegrationTaskInstances
- BatchMakeUpIntegrationTasks
- BatchRerunIntegrationTaskInstances
- BatchResumeIntegrationTasks
- BatchStartIntegrationTasks
- BatchStopIntegrationTasks
- BatchSuspendIntegrationTasks
- BatchUpdateIntegrationTasks
- CheckAlarmRegularNameExist
- CheckIntegrationNodeNameExists
- CheckIntegrationTaskNameExists
- CheckTaskNameExist
- CommitIntegrationTask
- CreateHiveTable
- CreateHiveTableByDDL
- CreateIntegrationNode
- CreateIntegrationTask
- CreateTaskAlarmRegular
- DeleteIntegrationNode
- DeleteIntegrationTask
- DeleteOfflineTask
- DeleteTaskAlarmRegular
- DescribeAlarmEvents
- DescribeAlarmReceiver
- DescribeInstanceLastLog
- DescribeInstanceList
- DescribeInstanceLog
- DescribeInstanceLogList
- DescribeIntegrationNode
- DescribeIntegrationStatistics
- DescribeIntegrationStatisticsInstanceTrend
- DescribeIntegrationStatisticsRecordsTrend
- DescribeIntegrationStatisticsTaskStatus
- DescribeIntegrationStatisticsTaskStatusTrend
- DescribeIntegrationTask
- DescribeIntegrationTasks
- DescribeIntegrationVersionNodesInfo
- DescribeOfflineTaskToken
- DescribeRealTimeTaskInstanceNodeInfo
- DescribeRealTimeTaskSpeed
- DescribeRuleTemplatesByPage
- DescribeStreamTaskLogList
- DescribeTaskAlarmRegulations
- DescribeTaskLockStatus
- DryRunDIOfflineTask
- GenHiveTableDDLSql
- GetIntegrationNodeColumnSchema
- GetOfflineDIInstanceList
- GetOfflineInstanceList
- LockIntegrationTask
- ModifyIntegrationNode
- ModifyIntegrationTask
- ModifyTaskAlarmRegular
- ModifyTaskName
- ResumeIntegrationTask
- RobAndLockIntegrationTask
- StartIntegrationTask
- StopIntegrationTask
- SuspendIntegrationTask
- TaskLog
- UnlockIntegrationTask
- CreateOfflineTask
- DescribeRealTimeTaskMetricOverview
- Platform management related APIs
- Data Source Management APIs
- Data Types
- Error Codes
- 服务等级协议
- 相关协议
- 联系我们
- 词汇表
- 产品简介
- 购买指南
- 准备工作
- 操作指南
- 管理控制台
- 项目管理
- 数据集成
- 数据集成概述
- 支持的数据源与读写能力
- 集成资源配置与管理
- 实时同步任务配置与运维
- 离线同步任务配置与运维
- 离线同步支持的数据源
- 数据源一览
- 数据源列表
- MySQL 数据源
- TDSQL-C MySQL 数据源
- Oracle 数据源
- SQL Server 数据源
- PostgreSQL 数据源
- TDSQL-PostgreSQL 数据源
- TDSQL MySQL 数据源
- DB2 数据源
- 达梦 DM 数据源
- OceanBase 数据源
- SAP HANA 数据源
- SAP IQ(Sybase) 数据源
- Doris/TCHouse-D 数据源
- StarRocks 数据源
- DLC 数据源
- Iceberg 数据源
- TCHouse-P 数据源
- ClickHouse 数据源
- Greenplum 数据源
- Hive 数据源
- HDFS 数据源
- HBase 数据源
- TBase 数据源
- GBase 数据源
- GaussDB 数据源
- Impala 数据源
- Kudu 数据源
- FTP 数据源
- COS 数据源
- SFTP 数据源
- Rest API 数据源
- Elasticsearch/腾讯云 Elasticsearch 数据源
- Mongo/腾讯云 Mongo 数据源
- Redis 数据源
- Kafka/CKafka 数据源
- CTSDB influxDB 数据源
- TDMQ Pulsar 数据源
- 数据集成离线同步配置与运维
- 数据开发离线同步配置与运维
- 转换节点配置
- 时间参数说明
- 离线节点高级参数
- 离线同步支持的数据源
- 同步任务自动建表能力
- 常见问题
- 数据开发
- 数据资产
- 数据质量
- 数据安全
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- DeleteProjectParamDs
- CreateWorkflowDs
- CreateTaskVersionDs
- RemoveWorkflowDs
- TriggerDsEvent
- DeleteTaskDs
- DescribeBatchOperateTask
- DeleteFilePath
- GetFileInfo
- FindAllFolder
- CreateTaskFolder
- MoveTasksToFolder
- DescribeDsFolderTree
- DeleteFile
- UploadContent
- SubmitSqlTask
- SubmitTaskTestRun
- DeleteResource
- DescribeResourceManagePathTrees
- CreateCustomFunction
- DeleteCustomFunction
- DescribeFunctionKinds
- DescribeFunctionTypes
- DescribeOrganizationalFunctions
- SaveCustomFunction
- SubmitCustomFunction
- CreateDsFolder
- DeleteDsFolder
- DescribeDsParentFolderTree
- ModifyDsFolder
- DeleteResourceFile
- DeleteResourceFiles
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operation and Maintenance APIs
- FreezeTasksByWorkflowIds
- DeleteWorkflowById
- DescribeDependTaskLists
- DescribeWorkflowExecuteById
- DescribeWorkflowTaskCount
- DescribeWorkflowListByProjectId
- DescribeWorkflowInfoById
- UpdateWorkflowOwner
- RunRerunScheduleInstances
- DescribeWorkflowCanvasInfo
- DescribeAllByFolderNew
- DescribeTaskRunHistory
- RunForceSucScheduleInstances
- KillScheduleInstances
- RunTasksByMultiWorkflow
- DescribeTaskByStatusReport
- DescribeStatisticInstanceStatusTrendOps
- DescribeOpsWorkflows
- DescribeSchedulerTaskTypeCnt
- BatchStopWorkflowsByIds
- DescribeInstanceByCycle
- DescribeTaskByCycleReport
- DescribeSchedulerInstanceStatus
- DescribeScheduleInstances
- CreateOpsMakePlan
- DescribeSchedulerTaskCntByStatus
- DescribeSchedulerRunTimeInstanceCntByStatus
- DescribeOpsMakePlanInstances
- DescribeOpsMakePlanTasks
- DescribeOpsMakePlans
- KillOpsMakePlanInstances
- BatchDeleteOpsTasks
- DescribeFolderWorkflowList
- DescribeTaskScript
- ModifyTaskInfo
- ModifyTaskLinks
- ModifyTaskScript
- ModifyWorkflowSchedule
- RegisterEvent
- RegisterEventListener
- SetTaskAlarmNew
- SubmitTask
- SubmitWorkflow
- TriggerEvent
- BatchModifyOpsOwners
- BatchStopOpsTasks
- CountOpsInstanceState
- DescribeDependOpsTasks
- DescribeOperateOpsTasks
- DescribeSuccessorOpsTaskInfos
- FreezeOpsTasks
- CreateTask
- ModifyWorkflowInfo
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- CommitRuleGroupTask
- CreateRule
- CreateRuleTemplate
- DeleteRule
- DeleteRuleTemplate
- DescribeDataCheckStat
- DescribeDimensionScore
- DescribeExecStrategy
- DescribeQualityScore
- DescribeQualityScoreTrend
- DescribeRule
- DescribeRuleDimStat
- DescribeRuleExecDetail
- DescribeRuleExecLog
- DescribeRuleExecResults
- DescribeRuleExecStat
- DescribeRuleGroup
- DescribeRuleGroupExecResultsByPage
- DescribeRuleGroupSubscription
- DescribeRuleGroupTable
- DescribeRuleGroupsByPage
- DescribeRuleTemplate
- DescribeRuleTemplates
- DescribeRules
- DescribeRulesByPage
- DescribeTableQualityDetails
- DescribeTableScoreTrend
- DescribeTemplateDimCount
- DescribeTopTableStat
- DescribeTrendStat
- ModifyDimensionWeight
- ModifyExecStrategy
- ModifyMonitorStatus
- ModifyRule
- ModifyRuleGroupSubscription
- ModifyRuleTemplate
- DataInLong APIs
- BatchCreateIntegrationTaskAlarms
- BatchDeleteIntegrationTasks
- BatchForceSuccessIntegrationTaskInstances
- BatchKillIntegrationTaskInstances
- BatchMakeUpIntegrationTasks
- BatchRerunIntegrationTaskInstances
- BatchResumeIntegrationTasks
- BatchStartIntegrationTasks
- BatchStopIntegrationTasks
- BatchSuspendIntegrationTasks
- BatchUpdateIntegrationTasks
- CheckAlarmRegularNameExist
- CheckIntegrationNodeNameExists
- CheckIntegrationTaskNameExists
- CheckTaskNameExist
- CommitIntegrationTask
- CreateHiveTable
- CreateHiveTableByDDL
- CreateIntegrationNode
- CreateIntegrationTask
- CreateTaskAlarmRegular
- DeleteIntegrationNode
- DeleteIntegrationTask
- DeleteOfflineTask
- DeleteTaskAlarmRegular
- DescribeAlarmEvents
- DescribeAlarmReceiver
- DescribeInstanceLastLog
- DescribeInstanceList
- DescribeInstanceLog
- DescribeInstanceLogList
- DescribeIntegrationNode
- DescribeIntegrationStatistics
- DescribeIntegrationStatisticsInstanceTrend
- DescribeIntegrationStatisticsRecordsTrend
- DescribeIntegrationStatisticsTaskStatus
- DescribeIntegrationStatisticsTaskStatusTrend
- DescribeIntegrationTask
- DescribeIntegrationTasks
- DescribeIntegrationVersionNodesInfo
- DescribeOfflineTaskToken
- DescribeRealTimeTaskInstanceNodeInfo
- DescribeRealTimeTaskSpeed
- DescribeRuleTemplatesByPage
- DescribeStreamTaskLogList
- DescribeTaskAlarmRegulations
- DescribeTaskLockStatus
- DryRunDIOfflineTask
- GenHiveTableDDLSql
- GetIntegrationNodeColumnSchema
- GetOfflineDIInstanceList
- GetOfflineInstanceList
- LockIntegrationTask
- ModifyIntegrationNode
- ModifyIntegrationTask
- ModifyTaskAlarmRegular
- ModifyTaskName
- ResumeIntegrationTask
- RobAndLockIntegrationTask
- StartIntegrationTask
- StopIntegrationTask
- SuspendIntegrationTask
- TaskLog
- UnlockIntegrationTask
- CreateOfflineTask
- DescribeRealTimeTaskMetricOverview
- Platform management related APIs
- Data Source Management APIs
- Data Types
- Error Codes
- 服务等级协议
- 相关协议
- 联系我们
- 词汇表
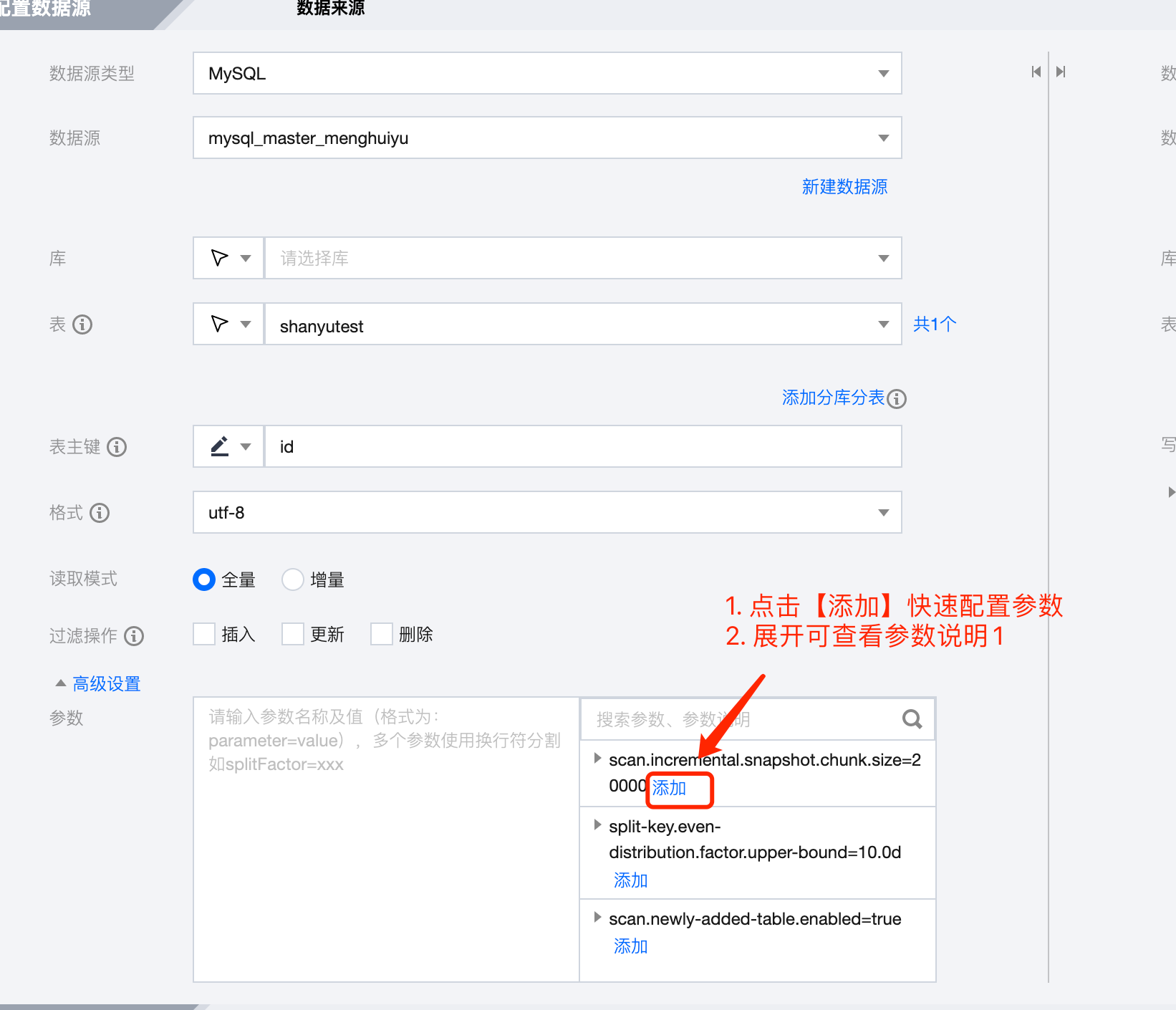
参数说明
离线类型 | 读/写 | 配置内容 | 适用场景 | 描述 |
MySQL | 读 | splitFactor=5 | 单表 | - |
TDSQL MySQL | 读 | splitFactor=5 | 单表 | - |
Doris | 读 | query_timeout=604800 | 单表 | 查询的超时时间,以秒为单位 |
| | exec_mem_limit=4294967296 | 单表 | 设置执行内存限制,用于限制查询执行过程中的内存使用 |
| | parallel_fragment_exec_instance_num=8 | 单表 | 指定并行片段执行的实例数 |
Hive | 读 | mapreduce.job.queuename=root.default | 单表 | 用于指定作业(job)提交到哪个队列(queue)中执行 |
| | hive.execution.engine=mr | 单表 | Hive 中的一个配置参数,用于指定 Hive 查询的执行引擎,当前默认 mr,无需修改。 |
| | 注意: 设置高级参数时,mapreduce.job.queuename=root.default 和 hive.execution.engine=mr 两个参数需要一起使用,使用单个参数无法生效。 | | |
DLC | 读 | fs.cosn.trsf.fs.ofs.data.transfer.thread.count=8 | 单表 | DLC 并发写入,支持参数 none|hash|range 参数说明: 1. none:存在主键则根据主键进行并发写入,否则单并发写入 2. ash:存在分区字段,根据分区字段并发写入,否则根据参数 none 的策略写入 3. range:暂不支持,策略和 none 一致 |
| | fs.cosn.trsf.fs.ofs.prev.read.block.count=4 | 单表 | DLC 开启小文件合并,也可以在 DLC 控制台开启 该参数默认为false,整库同步界面有选项开启,单表同步需要手动配置该参数 |
Mongodb | 读 | batchSize=1000 | 单表 | 批量读取的条数 |
COS | 写 | splitFileSize=134217728 | 单表 | 单文件切分大小 针对 hive on cos 不生效 支持 text、orc、parquet 类型的文件 |
| | hadoopConfig={} | 单表 | 支持添加配置到 hadoopConfig 中 |
HDFS | 写 | splitFileSize=134217728 | 单表 | 单文件切分大小 hive on hdfs 不生效 支持 text、orc、parquet 类型的文件 |
Hive | 写 | compress=none/snappy/lz4/bzip2/gzip/deflate | 单表 | 默认为 none。只对 textfile 格式有效,对 orc/parquet 无效(orc/parquet 需要在建表语句指定压缩) |
| | format=orc/parquet | 单表 | hdfs 临时文件的格式,默认为 orc,跟最终 hive 表格式无关 |
| | partition=static | 单表 | 静态分区模式。适用于单分区写入,更节省内存 |
Doris | 写 | sameNameWildcardColumn=true | 单表 | mysql-doris 配置* 支持同名字段映射 |
| 写 | loadProps={"format":"csv","column_separator":"\\\\x01","row_delimiter":"\\\\x03"} | 单表 | CSV 格式写入。相对默认的 JSON 格式写入性能更高。需要配合行分隔符 \\\\x03 一起使用。 |
DLC | 写 | fs.cosn.trsf.fs.ofs.data.transfer.thread.count=8 | 单表 | DLC 并发写入,支持参数 none|hash|range 参数说明: 1. none:存在主键则根据主键进行并发写入,否者单并发写入 2. hash:存在分区字段,根据分区字段并发写入,否则根据参数 none 的策略写入 3. range:暂不支持,策略和 none 一致 |
| | fs.cosn.trsf.fs.ofs.prev.read.block.count=4 | 单表 | DLC 开启小文件合并,也可以在 DLC 控制台开启 该参数默认为false,整库同步界面有选项开启,单表同步需要手动配置该参数 |
Mongodb | 写 | replaceKey=id | 单表 | 写入模式为覆盖写入时,用来作为更新的业务主键 |
| | batchSize=2000 | 单表 | 批量写入的条数,若不设置,默认为1000 |
Elasticsearch | 写 | compression=true | 单表 | HTTP 请求,开启压缩 |
| | multiThread=true | 单表 | HTTP 请求,是否有多线程 |
| | ignoreWriterError | 单表 | 忽略写入错误,不重试,继续写入 |
| | ignoreParseError=false | 单表 | 忽略解析数据格式错误,继续写入 |
| | alias | 单表 | Elasticsearch 的别名类似于数据库的视图机制,为索引 my_index 创建一个别名 my_index_alias,对 my_index_alias 的操作与 my_index 的操作一致。配置alias表示在数据导入完成后,为指定的索引创建别名。 |
| | aliasMode=append | 单表 | 数据导入完成后增加别名的模式,包括 append(增加模式)和exclusive(只留这一个),append 表示追加当前索引至别名 alias映射中(一个别名对应多个索引),exclusive 表示首先删除别名 alias,再添加当前索引至别名 alias 映射中(一个别名对应一个索引)。后续会转换别名为实际的索引名称,别名可以用来进行索引迁移和多个索引的查询统一,并可以用来实现视图的功能。 |
| | nullToDate=null | 单表 | null 值转 date 类型,填充 null |
Kafka | 写 | kafkaConfig={} | 单表 | 支持 Kafka Producer 配置项 |
元数据字段 | 读/写 | 配置内容 |
Kafka | 读 | __key__ 表示消息的 key
__value__ 表示消息的完整内容
__partition__ 表示当前消息所在分区
__headers__ 表示当前消息 headers 信息
__offset__ 表示当前消息的偏移量
__timestamp__ 表示当前消息的时间戳
|
Elasticsearch | 读 | _id 支持获取 _id 信息 |
配置方式

 是
是
 否
否
本页内容是否解决了您的问题?