- 产品简介
- 购买指南
- 准备工作
- 操作指南
- 管理控制台
- 项目管理
- 数据集成
- 数据集成概述
- 支持的数据源与读写能力
- 集成资源配置与管理
- 实时同步任务配置与运维
- 离线同步任务配置与运维
- 离线同步支持的数据源
- 数据源一览
- 数据源列表
- MySQL 数据源
- TDSQL-C MySQL 数据源
- Oracle 数据源
- SQL Server 数据源
- PostgreSQL 数据源
- TDSQL-PostgreSQL 数据源
- TDSQL MySQL 数据源
- DB2 数据源
- 达梦 DM 数据源
- OceanBase 数据源
- SAP HANA 数据源
- SAP IQ(Sybase) 数据源
- Doris/TCHouse-D 数据源
- StarRocks 数据源
- DLC 数据源
- Iceberg 数据源
- TCHouse-P 数据源
- ClickHouse 数据源
- Greenplum 数据源
- Hive 数据源
- HDFS 数据源
- HBase 数据源
- TBase 数据源
- GBase 数据源
- GaussDB 数据源
- Impala 数据源
- Kudu 数据源
- FTP 数据源
- COS 数据源
- SFTP 数据源
- Rest API 数据源
- Elasticsearch/腾讯云 Elasticsearch 数据源
- Mongo/腾讯云 Mongo 数据源
- Redis 数据源
- Kafka/CKafka 数据源
- CTSDB influxDB 数据源
- TDMQ Pulsar 数据源
- 数据集成离线同步配置与运维
- 数据开发离线同步配置与运维
- 转换节点配置
- 时间参数说明
- 离线节点高级参数
- 离线同步支持的数据源
- 同步任务自动建表能力
- 常见问题
- 数据开发
- 数据资产
- 数据质量
- 数据安全
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- DeleteProjectParamDs
- CreateWorkflowDs
- CreateTaskVersionDs
- RemoveWorkflowDs
- TriggerDsEvent
- DeleteTaskDs
- DescribeBatchOperateTask
- DeleteFilePath
- GetFileInfo
- FindAllFolder
- CreateTaskFolder
- MoveTasksToFolder
- DescribeDsFolderTree
- DeleteFile
- UploadContent
- SubmitSqlTask
- SubmitTaskTestRun
- DeleteResource
- DescribeResourceManagePathTrees
- CreateCustomFunction
- DeleteCustomFunction
- DescribeFunctionKinds
- DescribeFunctionTypes
- DescribeOrganizationalFunctions
- SaveCustomFunction
- SubmitCustomFunction
- CreateDsFolder
- DeleteDsFolder
- DescribeDsParentFolderTree
- ModifyDsFolder
- DeleteResourceFile
- DeleteResourceFiles
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operation and Maintenance APIs
- FreezeTasksByWorkflowIds
- DeleteWorkflowById
- DescribeDependTaskLists
- DescribeWorkflowExecuteById
- DescribeWorkflowTaskCount
- DescribeWorkflowListByProjectId
- DescribeWorkflowInfoById
- UpdateWorkflowOwner
- RunRerunScheduleInstances
- DescribeWorkflowCanvasInfo
- DescribeAllByFolderNew
- DescribeTaskRunHistory
- RunForceSucScheduleInstances
- KillScheduleInstances
- RunTasksByMultiWorkflow
- DescribeTaskByStatusReport
- DescribeStatisticInstanceStatusTrendOps
- DescribeOpsWorkflows
- DescribeSchedulerTaskTypeCnt
- BatchStopWorkflowsByIds
- DescribeInstanceByCycle
- DescribeTaskByCycleReport
- DescribeSchedulerInstanceStatus
- DescribeScheduleInstances
- CreateOpsMakePlan
- DescribeSchedulerTaskCntByStatus
- DescribeSchedulerRunTimeInstanceCntByStatus
- DescribeOpsMakePlanInstances
- DescribeOpsMakePlanTasks
- DescribeOpsMakePlans
- KillOpsMakePlanInstances
- BatchDeleteOpsTasks
- DescribeFolderWorkflowList
- DescribeTaskScript
- ModifyTaskInfo
- ModifyTaskLinks
- ModifyTaskScript
- ModifyWorkflowSchedule
- RegisterEvent
- RegisterEventListener
- SetTaskAlarmNew
- SubmitTask
- SubmitWorkflow
- TriggerEvent
- BatchModifyOpsOwners
- BatchStopOpsTasks
- CountOpsInstanceState
- DescribeDependOpsTasks
- DescribeOperateOpsTasks
- DescribeSuccessorOpsTaskInfos
- FreezeOpsTasks
- CreateTask
- ModifyWorkflowInfo
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- CommitRuleGroupTask
- CreateRule
- CreateRuleTemplate
- DeleteRule
- DeleteRuleTemplate
- DescribeDataCheckStat
- DescribeDimensionScore
- DescribeExecStrategy
- DescribeQualityScore
- DescribeQualityScoreTrend
- DescribeRule
- DescribeRuleDimStat
- DescribeRuleExecDetail
- DescribeRuleExecLog
- DescribeRuleExecResults
- DescribeRuleExecStat
- DescribeRuleGroup
- DescribeRuleGroupExecResultsByPage
- DescribeRuleGroupSubscription
- DescribeRuleGroupTable
- DescribeRuleGroupsByPage
- DescribeRuleTemplate
- DescribeRuleTemplates
- DescribeRules
- DescribeRulesByPage
- DescribeTableQualityDetails
- DescribeTableScoreTrend
- DescribeTemplateDimCount
- DescribeTopTableStat
- DescribeTrendStat
- ModifyDimensionWeight
- ModifyExecStrategy
- ModifyMonitorStatus
- ModifyRule
- ModifyRuleGroupSubscription
- ModifyRuleTemplate
- DataInLong APIs
- BatchCreateIntegrationTaskAlarms
- BatchDeleteIntegrationTasks
- BatchForceSuccessIntegrationTaskInstances
- BatchKillIntegrationTaskInstances
- BatchMakeUpIntegrationTasks
- BatchRerunIntegrationTaskInstances
- BatchResumeIntegrationTasks
- BatchStartIntegrationTasks
- BatchStopIntegrationTasks
- BatchSuspendIntegrationTasks
- BatchUpdateIntegrationTasks
- CheckAlarmRegularNameExist
- CheckIntegrationNodeNameExists
- CheckIntegrationTaskNameExists
- CheckTaskNameExist
- CommitIntegrationTask
- CreateHiveTable
- CreateHiveTableByDDL
- CreateIntegrationNode
- CreateIntegrationTask
- CreateTaskAlarmRegular
- DeleteIntegrationNode
- DeleteIntegrationTask
- DeleteOfflineTask
- DeleteTaskAlarmRegular
- DescribeAlarmEvents
- DescribeAlarmReceiver
- DescribeInstanceLastLog
- DescribeInstanceList
- DescribeInstanceLog
- DescribeInstanceLogList
- DescribeIntegrationNode
- DescribeIntegrationStatistics
- DescribeIntegrationStatisticsInstanceTrend
- DescribeIntegrationStatisticsRecordsTrend
- DescribeIntegrationStatisticsTaskStatus
- DescribeIntegrationStatisticsTaskStatusTrend
- DescribeIntegrationTask
- DescribeIntegrationTasks
- DescribeIntegrationVersionNodesInfo
- DescribeOfflineTaskToken
- DescribeRealTimeTaskInstanceNodeInfo
- DescribeRealTimeTaskSpeed
- DescribeRuleTemplatesByPage
- DescribeStreamTaskLogList
- DescribeTaskAlarmRegulations
- DescribeTaskLockStatus
- DryRunDIOfflineTask
- GenHiveTableDDLSql
- GetIntegrationNodeColumnSchema
- GetOfflineDIInstanceList
- GetOfflineInstanceList
- LockIntegrationTask
- ModifyIntegrationNode
- ModifyIntegrationTask
- ModifyTaskAlarmRegular
- ModifyTaskName
- ResumeIntegrationTask
- RobAndLockIntegrationTask
- StartIntegrationTask
- StopIntegrationTask
- SuspendIntegrationTask
- TaskLog
- UnlockIntegrationTask
- CreateOfflineTask
- DescribeRealTimeTaskMetricOverview
- Platform management related APIs
- Data Source Management APIs
- Data Types
- Error Codes
- 服务等级协议
- 相关协议
- 联系我们
- 词汇表
- 产品简介
- 购买指南
- 准备工作
- 操作指南
- 管理控制台
- 项目管理
- 数据集成
- 数据集成概述
- 支持的数据源与读写能力
- 集成资源配置与管理
- 实时同步任务配置与运维
- 离线同步任务配置与运维
- 离线同步支持的数据源
- 数据源一览
- 数据源列表
- MySQL 数据源
- TDSQL-C MySQL 数据源
- Oracle 数据源
- SQL Server 数据源
- PostgreSQL 数据源
- TDSQL-PostgreSQL 数据源
- TDSQL MySQL 数据源
- DB2 数据源
- 达梦 DM 数据源
- OceanBase 数据源
- SAP HANA 数据源
- SAP IQ(Sybase) 数据源
- Doris/TCHouse-D 数据源
- StarRocks 数据源
- DLC 数据源
- Iceberg 数据源
- TCHouse-P 数据源
- ClickHouse 数据源
- Greenplum 数据源
- Hive 数据源
- HDFS 数据源
- HBase 数据源
- TBase 数据源
- GBase 数据源
- GaussDB 数据源
- Impala 数据源
- Kudu 数据源
- FTP 数据源
- COS 数据源
- SFTP 数据源
- Rest API 数据源
- Elasticsearch/腾讯云 Elasticsearch 数据源
- Mongo/腾讯云 Mongo 数据源
- Redis 数据源
- Kafka/CKafka 数据源
- CTSDB influxDB 数据源
- TDMQ Pulsar 数据源
- 数据集成离线同步配置与运维
- 数据开发离线同步配置与运维
- 转换节点配置
- 时间参数说明
- 离线节点高级参数
- 离线同步支持的数据源
- 同步任务自动建表能力
- 常见问题
- 数据开发
- 数据资产
- 数据质量
- 数据安全
- API 文档
- History
- Introduction
- API Category
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- DeleteProjectParamDs
- CreateWorkflowDs
- CreateTaskVersionDs
- RemoveWorkflowDs
- TriggerDsEvent
- DeleteTaskDs
- DescribeBatchOperateTask
- DeleteFilePath
- GetFileInfo
- FindAllFolder
- CreateTaskFolder
- MoveTasksToFolder
- DescribeDsFolderTree
- DeleteFile
- UploadContent
- SubmitSqlTask
- SubmitTaskTestRun
- DeleteResource
- DescribeResourceManagePathTrees
- CreateCustomFunction
- DeleteCustomFunction
- DescribeFunctionKinds
- DescribeFunctionTypes
- DescribeOrganizationalFunctions
- SaveCustomFunction
- SubmitCustomFunction
- CreateDsFolder
- DeleteDsFolder
- DescribeDsParentFolderTree
- ModifyDsFolder
- DeleteResourceFile
- DeleteResourceFiles
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operation and Maintenance APIs
- FreezeTasksByWorkflowIds
- DeleteWorkflowById
- DescribeDependTaskLists
- DescribeWorkflowExecuteById
- DescribeWorkflowTaskCount
- DescribeWorkflowListByProjectId
- DescribeWorkflowInfoById
- UpdateWorkflowOwner
- RunRerunScheduleInstances
- DescribeWorkflowCanvasInfo
- DescribeAllByFolderNew
- DescribeTaskRunHistory
- RunForceSucScheduleInstances
- KillScheduleInstances
- RunTasksByMultiWorkflow
- DescribeTaskByStatusReport
- DescribeStatisticInstanceStatusTrendOps
- DescribeOpsWorkflows
- DescribeSchedulerTaskTypeCnt
- BatchStopWorkflowsByIds
- DescribeInstanceByCycle
- DescribeTaskByCycleReport
- DescribeSchedulerInstanceStatus
- DescribeScheduleInstances
- CreateOpsMakePlan
- DescribeSchedulerTaskCntByStatus
- DescribeSchedulerRunTimeInstanceCntByStatus
- DescribeOpsMakePlanInstances
- DescribeOpsMakePlanTasks
- DescribeOpsMakePlans
- KillOpsMakePlanInstances
- BatchDeleteOpsTasks
- DescribeFolderWorkflowList
- DescribeTaskScript
- ModifyTaskInfo
- ModifyTaskLinks
- ModifyTaskScript
- ModifyWorkflowSchedule
- RegisterEvent
- RegisterEventListener
- SetTaskAlarmNew
- SubmitTask
- SubmitWorkflow
- TriggerEvent
- BatchModifyOpsOwners
- BatchStopOpsTasks
- CountOpsInstanceState
- DescribeDependOpsTasks
- DescribeOperateOpsTasks
- DescribeSuccessorOpsTaskInfos
- FreezeOpsTasks
- CreateTask
- ModifyWorkflowInfo
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- CommitRuleGroupTask
- CreateRule
- CreateRuleTemplate
- DeleteRule
- DeleteRuleTemplate
- DescribeDataCheckStat
- DescribeDimensionScore
- DescribeExecStrategy
- DescribeQualityScore
- DescribeQualityScoreTrend
- DescribeRule
- DescribeRuleDimStat
- DescribeRuleExecDetail
- DescribeRuleExecLog
- DescribeRuleExecResults
- DescribeRuleExecStat
- DescribeRuleGroup
- DescribeRuleGroupExecResultsByPage
- DescribeRuleGroupSubscription
- DescribeRuleGroupTable
- DescribeRuleGroupsByPage
- DescribeRuleTemplate
- DescribeRuleTemplates
- DescribeRules
- DescribeRulesByPage
- DescribeTableQualityDetails
- DescribeTableScoreTrend
- DescribeTemplateDimCount
- DescribeTopTableStat
- DescribeTrendStat
- ModifyDimensionWeight
- ModifyExecStrategy
- ModifyMonitorStatus
- ModifyRule
- ModifyRuleGroupSubscription
- ModifyRuleTemplate
- DataInLong APIs
- BatchCreateIntegrationTaskAlarms
- BatchDeleteIntegrationTasks
- BatchForceSuccessIntegrationTaskInstances
- BatchKillIntegrationTaskInstances
- BatchMakeUpIntegrationTasks
- BatchRerunIntegrationTaskInstances
- BatchResumeIntegrationTasks
- BatchStartIntegrationTasks
- BatchStopIntegrationTasks
- BatchSuspendIntegrationTasks
- BatchUpdateIntegrationTasks
- CheckAlarmRegularNameExist
- CheckIntegrationNodeNameExists
- CheckIntegrationTaskNameExists
- CheckTaskNameExist
- CommitIntegrationTask
- CreateHiveTable
- CreateHiveTableByDDL
- CreateIntegrationNode
- CreateIntegrationTask
- CreateTaskAlarmRegular
- DeleteIntegrationNode
- DeleteIntegrationTask
- DeleteOfflineTask
- DeleteTaskAlarmRegular
- DescribeAlarmEvents
- DescribeAlarmReceiver
- DescribeInstanceLastLog
- DescribeInstanceList
- DescribeInstanceLog
- DescribeInstanceLogList
- DescribeIntegrationNode
- DescribeIntegrationStatistics
- DescribeIntegrationStatisticsInstanceTrend
- DescribeIntegrationStatisticsRecordsTrend
- DescribeIntegrationStatisticsTaskStatus
- DescribeIntegrationStatisticsTaskStatusTrend
- DescribeIntegrationTask
- DescribeIntegrationTasks
- DescribeIntegrationVersionNodesInfo
- DescribeOfflineTaskToken
- DescribeRealTimeTaskInstanceNodeInfo
- DescribeRealTimeTaskSpeed
- DescribeRuleTemplatesByPage
- DescribeStreamTaskLogList
- DescribeTaskAlarmRegulations
- DescribeTaskLockStatus
- DryRunDIOfflineTask
- GenHiveTableDDLSql
- GetIntegrationNodeColumnSchema
- GetOfflineDIInstanceList
- GetOfflineInstanceList
- LockIntegrationTask
- ModifyIntegrationNode
- ModifyIntegrationTask
- ModifyTaskAlarmRegular
- ModifyTaskName
- ResumeIntegrationTask
- RobAndLockIntegrationTask
- StartIntegrationTask
- StopIntegrationTask
- SuspendIntegrationTask
- TaskLog
- UnlockIntegrationTask
- CreateOfflineTask
- DescribeRealTimeTaskMetricOverview
- Platform management related APIs
- Data Source Management APIs
- Data Types
- Error Codes
- 服务等级协议
- 相关协议
- 联系我们
- 词汇表
支持版本
目前支持 DM 7、8 版本。
使用限制
说明:
支持读取视图表。
DM 离线单表读取节点配置
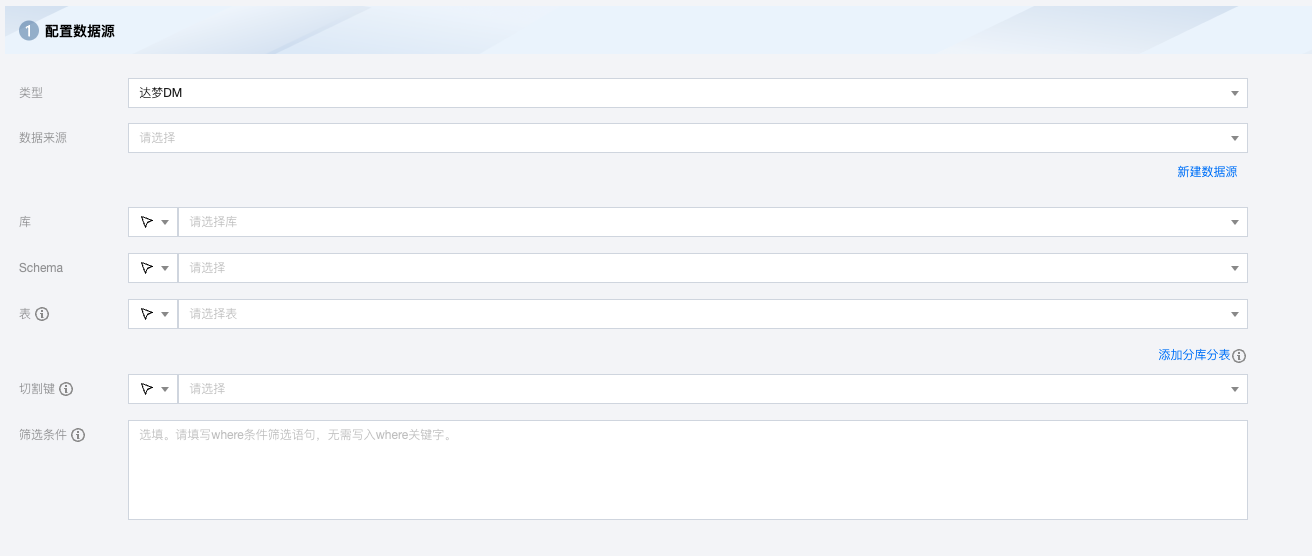
参数 | 说明 |
数据来源 | 可用的 DM 数据源。 |
库 | 支持选择、或者手动输入需读取的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
Schema | 支持选择、或者手动输入需读取的 Schema 名称。 |
添加分库分表 | 可创建多个数据源并添加对应的表对象。 注意: 分库分表情况下选择的多个表对象需保证 Schema 信息一致(包括字段名称、字段类型)。数据字段模块内系统默认展示第一个数据源的第一张表的元数据字段信息,若多表间字段不一致可能会导致运行失败。 |
表 | 支持选择、或者手动输入需读取的表名称。 |
切割键 | 您可以将源数据表中某一列作为切割键,建议使用主键或有索引的列作为切割键,仅支持类型为整型的字段。
读取数据时,根据配置的字段进行数据分片,实现并发读取,可以提升数据同步效率。 |
筛选条件(选填) | 根据数据类型填写对应筛选语句,该语句会作为将要同步数据的筛选条件。
DM 根据指定的 where 条件拼接 SQL,并根据该 SQL 进行数据抽取。例如,在测试时,可以将 where 条件指定为 limit 10。在实际业务场景中,通常会选择当天的数据进行同步,将 where 条件指定为 gmt_create > $bizdate。 where 条件可以有效地进行业务增量同步。 where 条件为空,视作同步全表所有的信息。 |
DM 离线单表写入节点配置
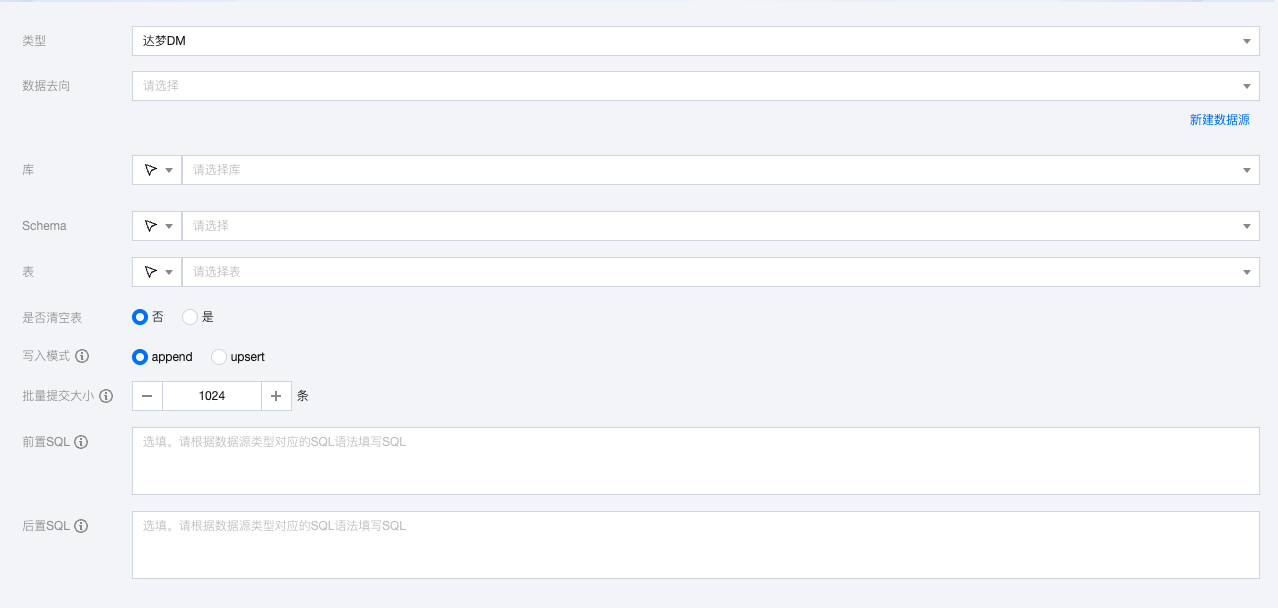
参数 | 说明 |
数据去向 | 需要写入的 DM 数据源。 |
库 | 支持选择、或者手动输入需写入的库名称 默认将数据源绑定的数据库作为默认库,其他数据库需手动输入库名称。 当数据源网络不联通导致无法直接拉取库信息时,可手动输入数据库名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
Schema | 支持选择、或者手动输入需读取的 Schema 名称。 |
表 | 支持选择、或者手动输入需写入的表名称 当数据源网络不联通导致无法直接拉取表信息时,可手动输入表名称。在数据集成网络连通的情况下,仍可进行数据同步。 |
是否清空表 | 在写入该 DM 数据表前可以手动选择是否清空该数据表。 |
写入模式 | append:追加写入。 upsert:根据设置主键字段进行数据更新写入。 |
批量提交大小 | 一次性批量提交的记录数大小,该值可以极大减少数据同步系统与 DM 的网络交互次数,并提升整体吞吐量。如果该值设置过大,会导致数据同步运行进程 OOM 异常。 |
前置 SQL(选填) | 执行同步任务之前执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,执行前清空表中的旧数据(truncate table tablename)。 |
后置 SQL(选填) | 执行同步任务之后执行的 SQL 语句,根据数据源类型对应的正确 SQL 语法填写 SQL,例如,加上某一个时间戳 alter table tablename add colname timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP。 |
数据类型转换支持
读取
DM 数据类型 | 内部类型 |
BIGINT、INTEGER、SMALLINT、TINYINT | Long |
NUMERIC、DECIMAL、DOUBLE、FLOAT、REAL | Double |
CHAR、VARCHAR、LONGVARCHAR、CLOB | String |
TIME、DATE、TIMESTAMP | Date |
BIT、BOOLEAN | Boolean |
BINARY、VARBINARY、BLOB、LONGVARBINARY | Bytes |
写入
内部类型 | DM 数据类型 |
Long | BIGINT、INTEGER、SMALLINT、TINYINT |
Double | DECIMAL、NUMERIC、DOUBLE、FLOAT、REAL |
String | CHAR、VARCHAR、CLOB、LONGVARCHAR |
Date | DATE、TIME、TIMESTAMP |
Boolean | BOOLEAN、BIT |
Bytes | BINARY、VARBINARY、BLOB、LONGVARBINARY |

 是
是
 否
否
本页内容是否解决了您的问题?